Hanjung Kim, Jaehyun Kang, Miran Heo, Sukjun Hwang, Seoung Wug Oh, Seon Joo Kim
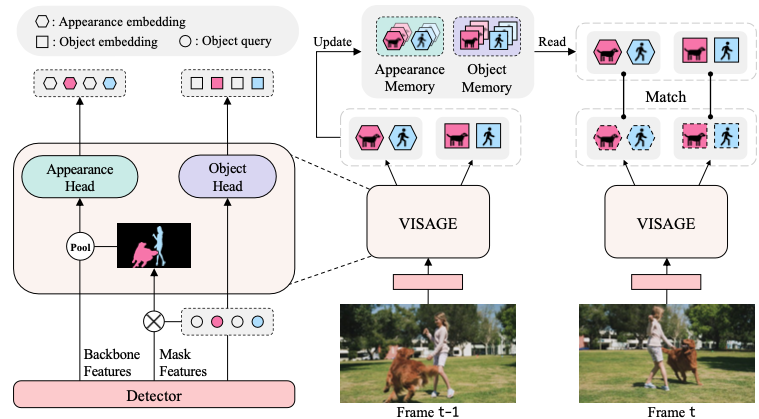
- Video Instance Segmentation by leveraging an appearance information.
- Support major video instance segmentation datasets: YouTubeVIS 2019/2021/2022, Occluded VIS (OVIS).
See installation instructions.
For dataset preparation instructions, refer to Preparing Datasets for VISAGE.
We provide a script train_net_video.py, that is made to train all the configs provided in VISAGE.
To train a model with "train_net_video.py", first setup the corresponding datasets following datasets/README.md, then download the COCO pre-trained instance segmentation weights (R50, Swin-L) and put them in the current working directory. Once these are set up, run:
python train_net_video.py --num-gpus 4 \
--config-file configs/youtubevis_2019/visage_R50_bs16.yaml
To evaluate a model's performance, use
python train_net_video.py \
--config-file configs/youtubevis_2019/visage_R50_bs16.yaml \
--eval-only MODEL.WEIGHTS /path/to/checkpoint_file
| Name | Backbone | AP | AP50 | AP75 | AR1 | AR10 | Link |
|---|---|---|---|---|---|---|---|
| VISAGE | ResNet-50 | 55.1 | 78.1 | 60.6 | 51.0 | 62.3 | model |
| Name | Backbone | AP | AP50 | AP75 | AR1 | AR10 | Link |
|---|---|---|---|---|---|---|---|
| VISAGE | ResNet-50 | 51.6 | 73.8 | 56.1 | 43.6 | 59.3 | model |
| Name | Backbone | AP | AP50 | AP75 | AR1 | AR10 | Link |
|---|---|---|---|---|---|---|---|
| VISAGE | ResNet-50 | 36.2 | 60.3 | 35.3 | 17.0 | 40.3 | model |
The majority of VISAGE is licensed under a Apache-2.0 License. However portions of the project are available under separate license terms: Detectron2(Apache-2.0 License), IFC(Apache-2.0 License), Mask2Former(MIT License), Deformable-DETR(Apache-2.0 License), MinVIS(Nvidia Source Code License-NC),and VITA(Apache-2.0 License).
@misc{kim2024visage,
title={VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement},
author={Hanjung Kim and Jaehyun Kang and Miran Heo and Sukjun Hwang and Seoung Wug Oh and Seon Joo Kim},
year={2024},
eprint={2312.04885},
archivePrefix={arXiv},
primaryClass={cs.CV}
}This repo is largely based on Mask2Former (https://github.com/facebookresearch/Mask2Former) and MinVIS (https://github.com/NVlabs/MinVIS) and VITA (https://github.com/sukjunhwang/VITA).