



-
ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
-
ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
-
ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如:
“请问如果借款没还怎么办。”
"合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。"
两段文本的相似度计算为0.9960
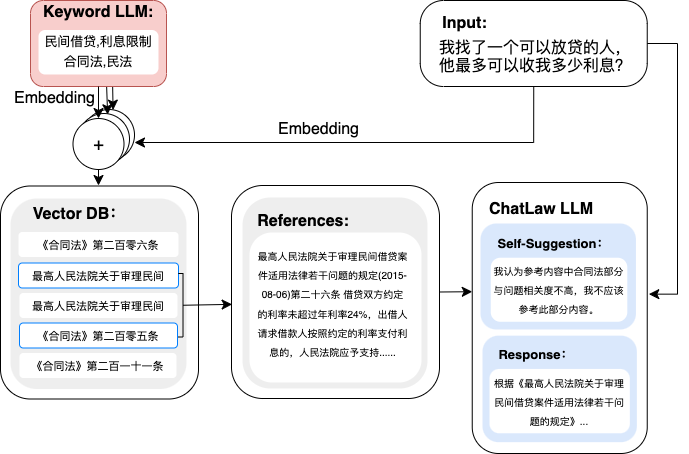
ChatGPT浪潮下,人工智能的不断扩展和发展为LLM的扩散提供了肥沃的土壤,目前医疗、教育、金融领域已逐渐有了各自的模型,但法律领域迟迟没有明显进展。
为了促进LLM在法律甚至其他垂直应用落地的开放研究,本项目开源了中文法律大模型,并针对LLM和知识库的结合问题给出了法律场景下合理的解决方案。
ChatLaw法律大模型目前开源的仅供学术参考的版本底座为姜子牙-13B、Anima-33B,我们使用大量法律新闻、法律论坛、法条、司法解释、法律咨询、法考题、判决文书等原始文本来构造对话数据。
基于姜子牙-13B的模型是第一版模型,得益于姜子牙的优秀中文能力和我们对数据清洗、数据增强过程的严格要求,我们在逻辑简单的法律任务上表现优异,但涉及到复杂逻辑的法律推理任务时往往表现不佳。
随后基于Anima-33B,我们增加了训练数据,做成了ChatLaw-33B,发现逻辑推理能力大幅提升,由此可见,大参数的中文LLM是至关重要的。
我们的技术报告在这里: arXiv: ChatLaw
基于可商用的模型训练而成的版本会作为我们后续产品内部接入的版本,对外不开源,可以在这里进行开源版本模型的试用
我们的数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。详细的参考数据在ChatLaw训练数据demo,以下是数据样例:
| question | answer | Subject |
|---|---|---|
| 如果一个人故意驾车向人群冲撞,但没有造成重大损失,会被怎样处罚? | 依据刑法条文第一百一十四条,如果一个人故意以危险方法危害公共安全,但尚未造成严重后果,将被处三年以上十年以下有期徒刑。因此,如果这个人故意驾车向人群冲撞,但没有造成重大损失,将被处以三年以上十年以下有期徒刑。 | 法律咨询 |
| 如果一个邮政工作人员私自开拆了一个邮件,但只是为了查看其中的收件人地址,而并未泄露邮件内容,是否构成什么罪行? | 构成私自开拆、隐匿、毁弃邮件、电报罪。本罪客观方面有两个特点:一是必须有私自开拆、隐匿、毁弃邮件、电报的行为。所谓私自开拆,是指非法擅自开拆他人邮件、电报,使封缄失效的行为,合法行为不在此限;二是必须有利用职务之便的行为,才能构成本罪。即使只是查看收件人地址也违反了邮政工作人员的职责,属于利用职务之便的行为,因此构成本罪。 | 法律概念 |
| 如果某个工人每天工作10小时,那么每周工作时间超过了规定吗? | 根据《劳动法》第三十六条,每日工作时间不得超过8小时,因此每周工 作时间将超过44小时,超过了规定。 | 法律咨询 |
| 甲公司注册资金为120万元,主营建材,乙厂为生产瓷砖的合伙企业。甲公司为稳定货源,决定投资30万元入伙乙厂。对此项投资的效力,下列表述哪一项是正确的? A)须经甲公司股东会全体通过方为有效\nB)须经甲公司董事会全体通过方为有效 C)须经乙厂全体合伙人同意方为有效 D)无效 |
按照最新《公司法》的规定,本题无答案。《公司法》第15条规定,公司可以向其他企业投资;但是,除法律另有规定外,不得成为对所投资企业的债务承担连带责任的出资人...... | 法律选择题 |
如何合理地评估垂直领域大模型的性能一直是一个问题,因为测试数据和真实场景存在差异,我们暂时没有完美的思路。我们只是收集了十余年的国家司法考试题目,整理出了一个包含2000个问题及其标准答案的测试数据集,用以衡量模型处理法律选择题的能力: 评测数据demo。
然而,我们发现各个模型的准确率普遍偏低。在这种情况下,仅对准确率进行比较并无多大意义。因此,我们借鉴英雄联盟的ELO匹配机制,做了一个模型对抗的ELO机制,以便更有效地评估各模型处理法律选择题的能力。以下分别是ELO分数和胜率图
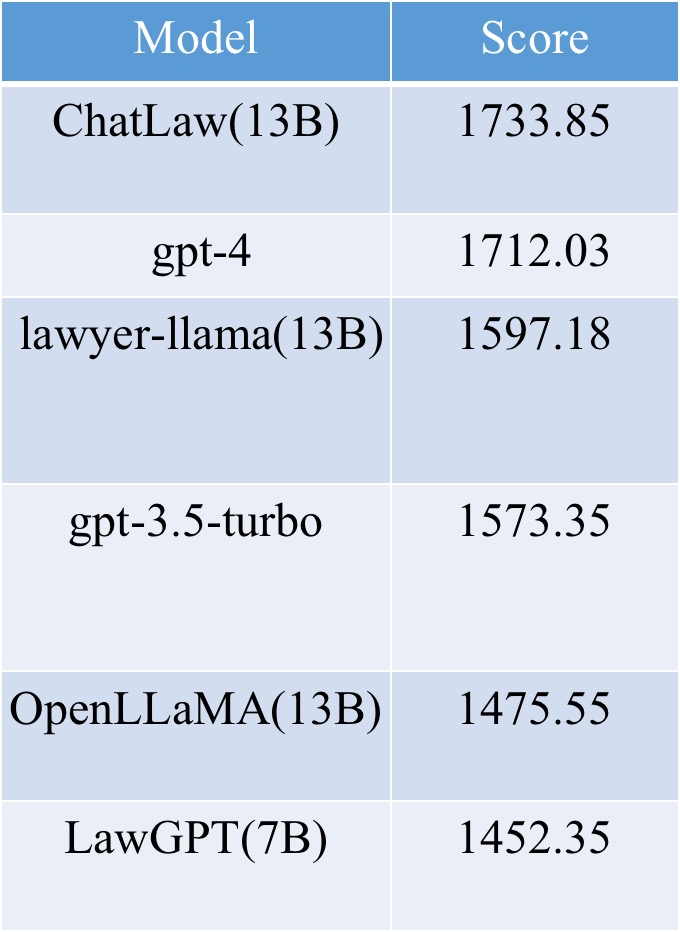
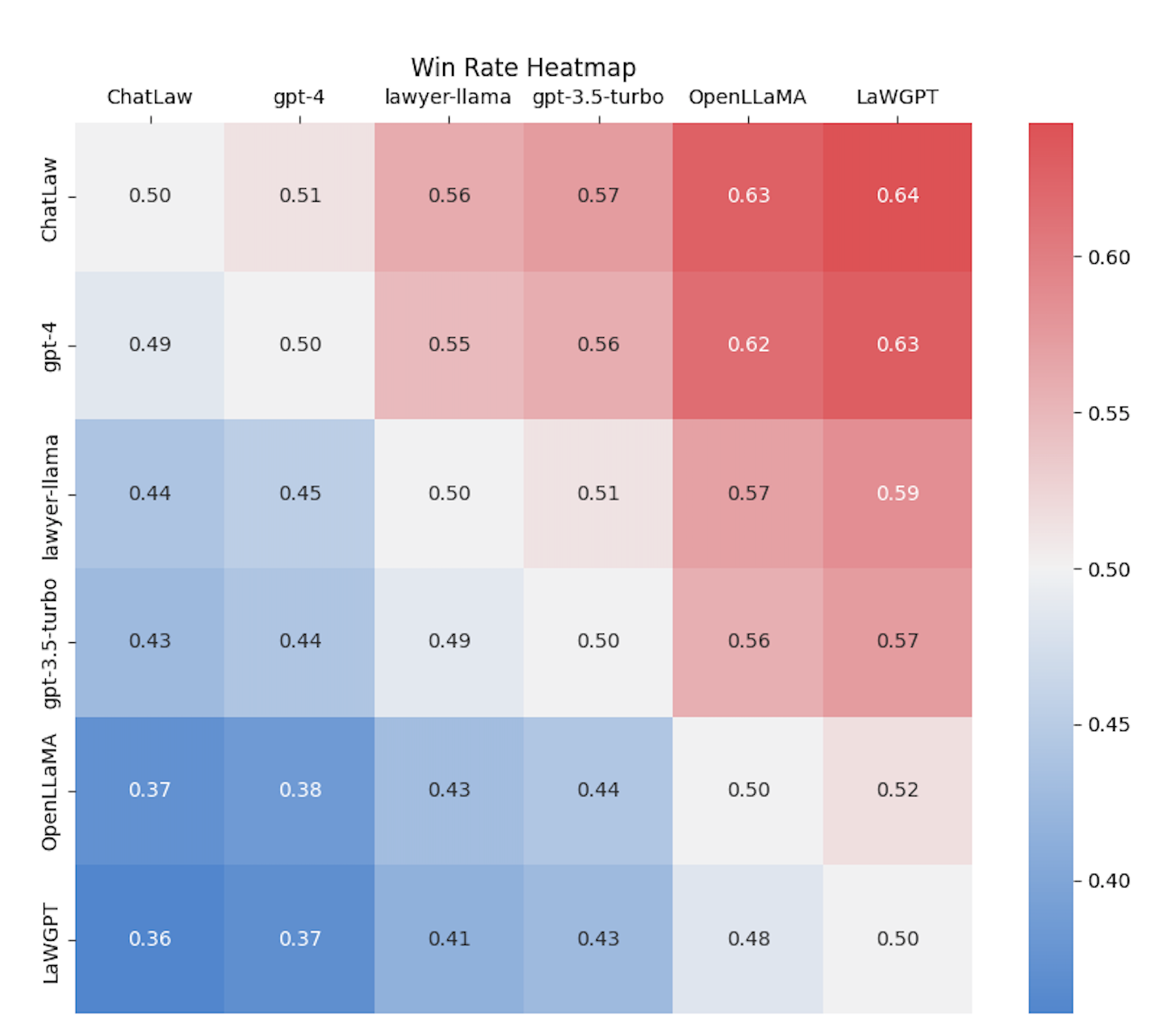
有以下结论:(1)引入法律相关的问答和法规条文的数据,能在一定程度上提升模型在选择题上的表现;(2)加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升。例如,ChatLaw模型之所以能胜过GPT-4,是因为我们使用了大量选择题作为训练数据;(3)法律选择题需要进行复杂的逻辑推理,因此,参数量更大的模型通常表现更优。
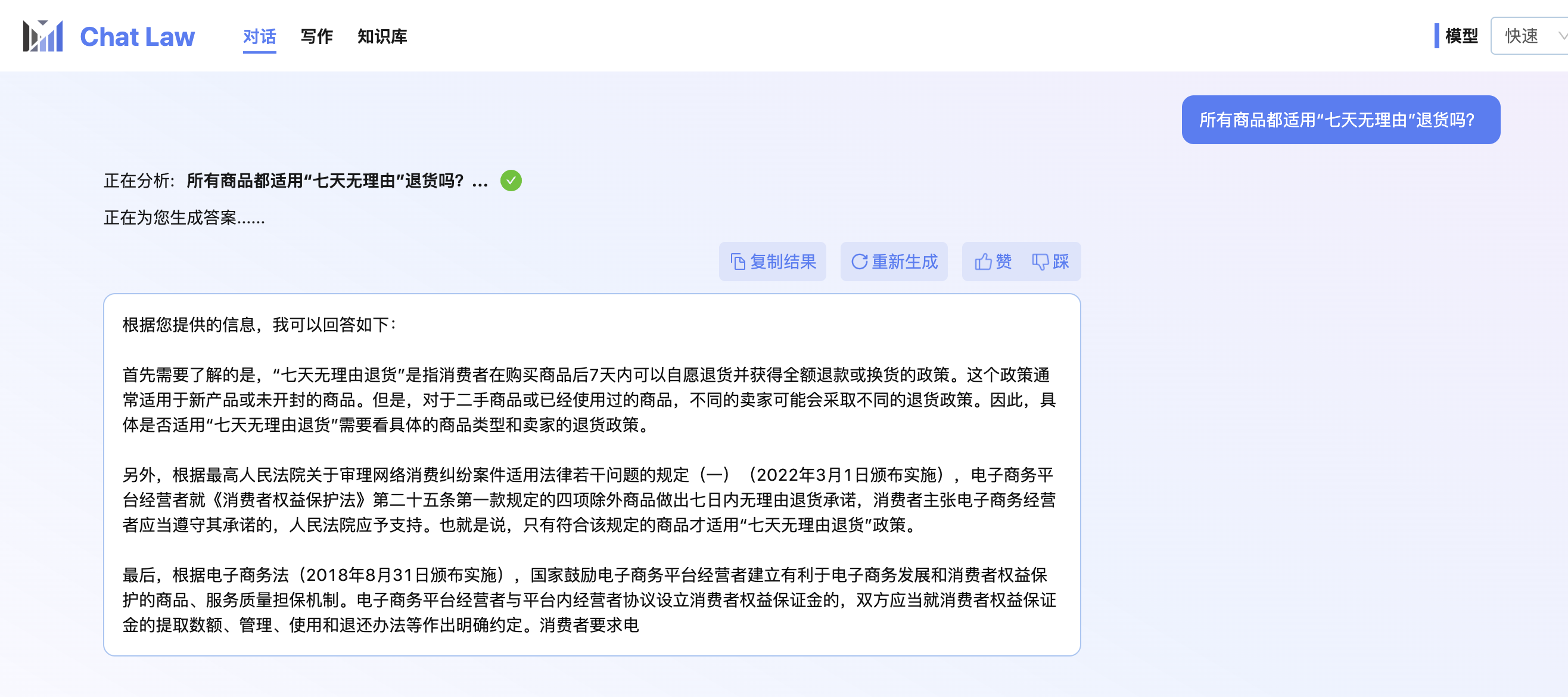
注意: 下面的测试图中加入了法条检索模块,因此会有更好的效果。目前由于在线体验网站压力过大,服务器资源不足,我们关闭了法条检索模块。
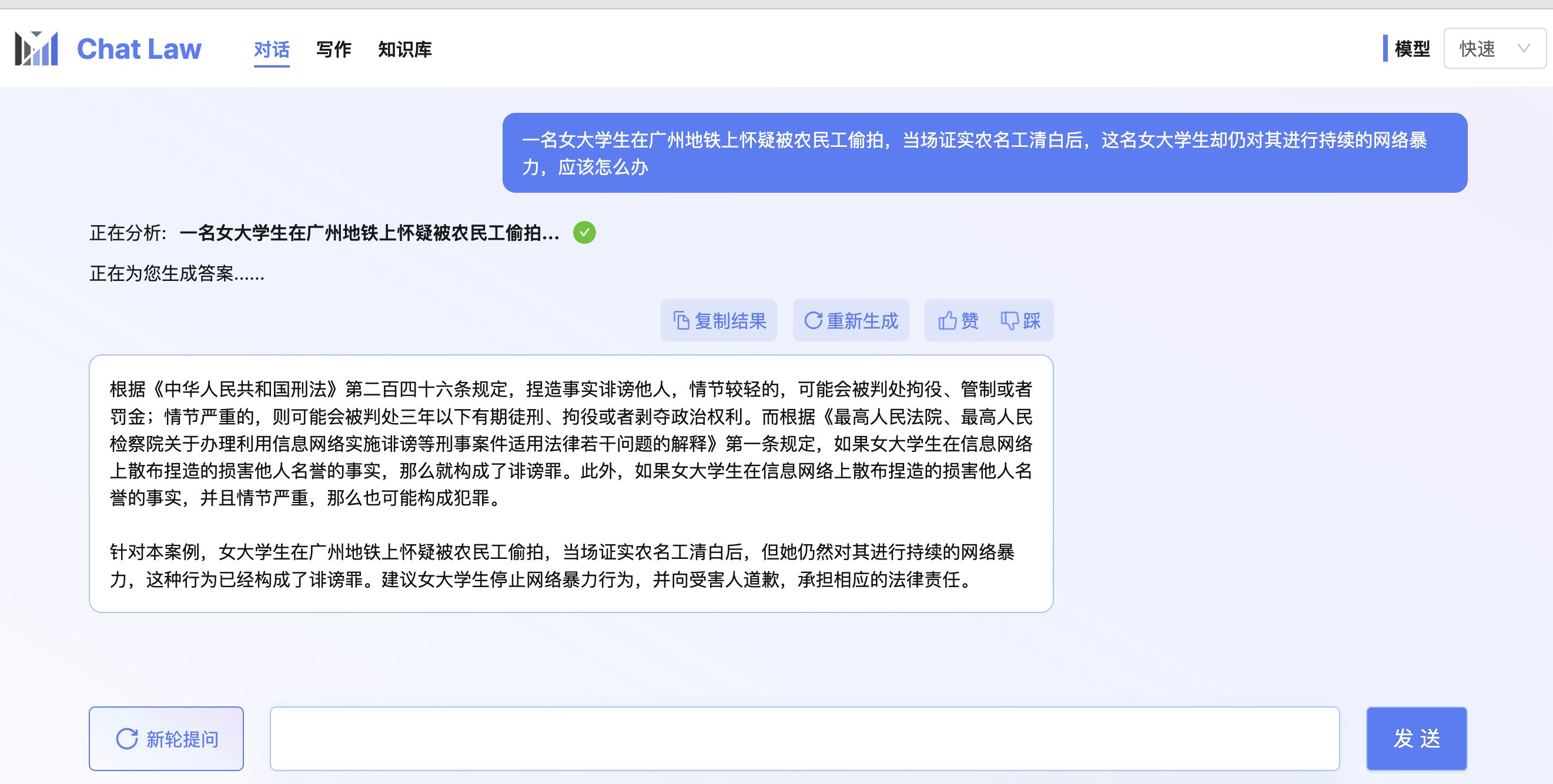
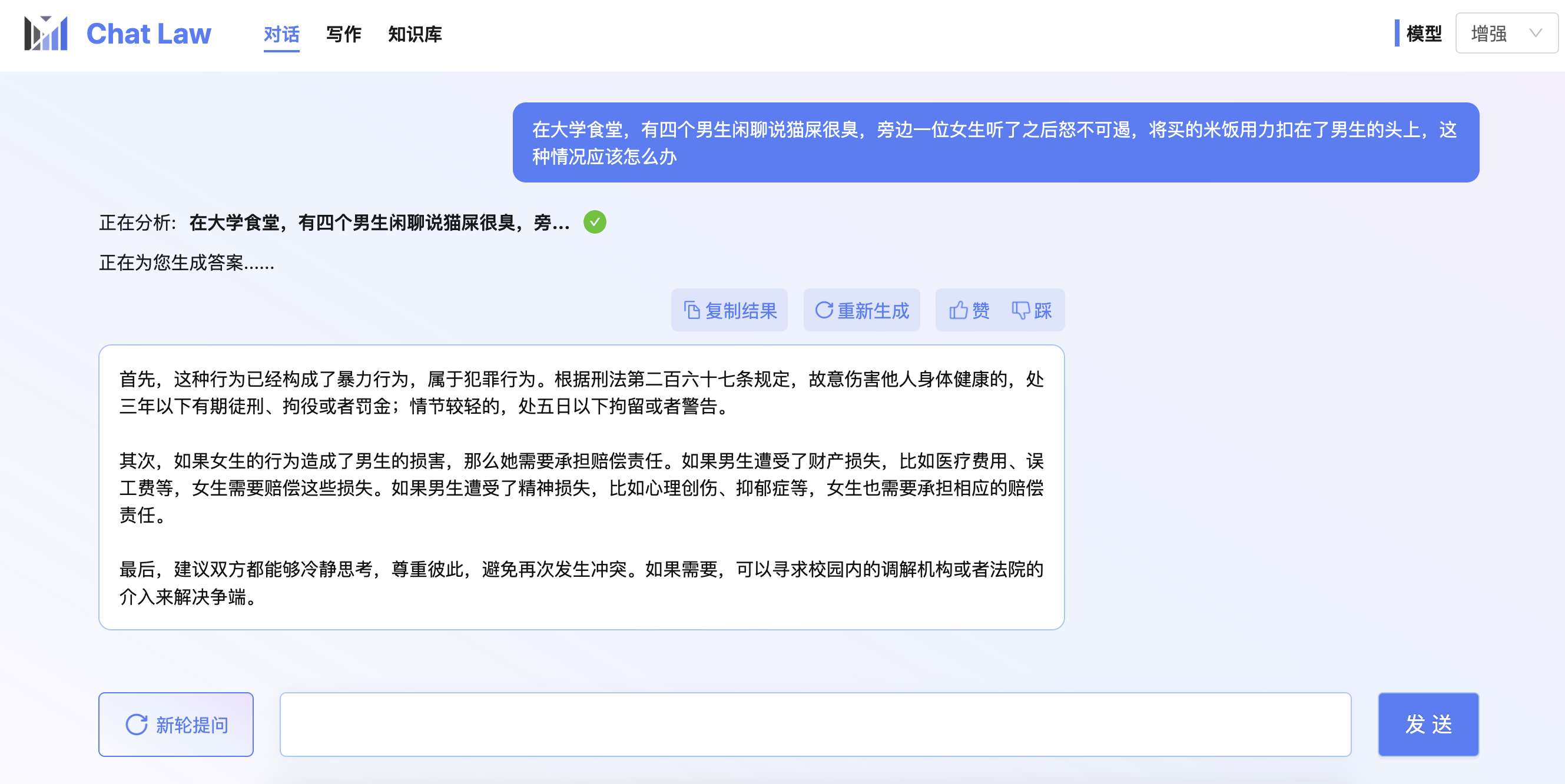
-
提升逻辑推理能力,训练30B以上的中文模型底座:在ChatLaw的迭代过程中,我们发现和医疗、教育、金融等垂直领域不同的是,法律场景的真实问答通常涉及很复杂的逻辑推理,这要求模型自身有很强的逻辑能力,预计只有模型参数量达到30B以上才可以。
-
安全可信,减少幻觉:法律是一个严肃的场景,我们在优化模型回复内容的法条、司法解释的准确性上做了很多努力,现在的ChatLaw和向量库结合的方式还可以进一步优化,另外我们和ChatExcel团队师兄深度结合,在学术领域研究LLM的幻觉问题,预计两个月后会有突破性进展,从而大幅减轻幻觉现象。
-
私有数据模型:我们一方面会继续扩大模型的基础法律能力,另一方面会探索B/G端的定制化私有需求,欢迎探讨合作
欢迎加入我们官方交流群:
由于LLaMA权重的许可限制,该模型不能用于商业用途,请严格遵守LLaMA的使用政策。考虑到LLaMA权重的许可证限制,我们无法直接发布完整的模型权重。
欢迎引用我们:
@misc{cui2023chatlaw,
title={ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases},
author={Jiaxi Cui and Zongjian Li and Yang Yan and Bohua Chen and Li Yuan},
year={2023},
eprint={2306.16092},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{ChatLaw,
author={Jiaxi Cui and Zongjian Li and Yang Yan and Bohua Chen and Li Yuan},
title={ChatLaw},
year={2023},
publisher={GitHub},
journal={GitHub repository},
howpublished={\url{https://github.com/PKU-YuanGroup/ChatLaw}},
}