Image segmentation on a subset of CamVid dataset using VGG-16 Feature Extractor followed by FCN-8 decoder
The dataset images and annotations. The images contain the video frames while the annotations contain the pixel-wise label maps. Each label map has the shape (height, width , 1) with each point in this space denoting the corresponding pixel's class. Classes are in the range [0, 11] (i.e. 12 classes) and the pixel labels correspond to these classes:
| Value | Class Name |
|---|---|
| 0 | sky |
| 1 | building |
| 2 | column/pole |
| 3 | road |
| 4 | side walk |
| 5 | vegetation |
| 6 | traffic light |
| 7 | fence |
| 8 | vehicle |
| 9 | pedestrian |
| 10 | byciclist |
| 11 | void |
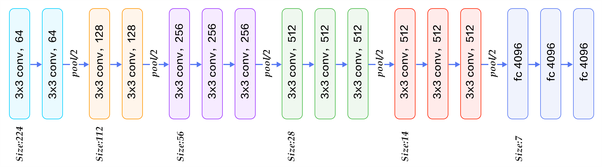
The backbone used is VGG-16, without the fully connected layers, initialized with pretrained weights. The architecture of a VGG-16 network is as follows:
FCN-8 is a fully convolutional network which upsamples the feature extracted by encoder and creates a pixel-wise labelmap
Metrics used are IoU and Dice Score.
A smoothing factor can be added in both numerator and denominator to avoid 0 division