本项目已停止维护。 目前知乎api的follower和followee接口更新了检测方式,请求无法返回成功结果。 建议的解决方式:请fork后,修改crawl_usr方法的代码,不使用api,而抓取整个页面,再解析DOM树,从元素中抽取数据。(可能更容易被检测到爬虫,需要减小频率)
请在顶层目录新建一个setting.json文件,然后启动zhihu_spider,读取代码在__main__那里
{
"phone": 你的知乎账号,
"password": 密码
}
这是本人学习性质的课程作业,仅供非商业用途(牢饭警告)。
可以多开几个线程爬的,但是速度已经很可观了,所以没有额外写,请尊重爬取网站。
同时向使用到的开源项目作者致谢!
开发加上爬取时间一共花了三四个星期,爬下了356万知乎用户,222万个回答,120万个问题,
其中,用户和用户回答分别爬取 (用户和回答api调用一次获取20个,但问题只能一次得一个,相同时间得到的问题要少很多)
| 数据类型 | 条数 | 文件大小 |
|---|---|---|
| 用户 | 3,555,056 | 1180.844MB |
| 回答 | 2,219,886 | 448.313MB |
| 用户关注 | 5,215,201 | 1351.875MB |
| 话题关注 | 12,097,062 | 1765.984MB |
| 问题 | 1,195,172 | 191.766MB |
| 话题 | 84,252 | 6.516MB |
.
├── README.md
├── analysis.ipynb 数据分析
├── analysis.py 部分分析代码
├── cache 缓存文件夹,存放验证码图片等
├── crawler.py 爬虫封装
├── db.py mysql封装,**需要重新填入自己的账号密码**
├── encrypt.js 用于Login时加密FormData,**需要事先配置好NodeJs环境**
├── res 资源文件
│ ├── canger02_W03.ttf 画图时使用的字体
│ ├── stopwords_zhihu.txt 停用词
│ └── 刘看山.png WordCloud的mask图片
├── proxy 代理客户端的代码部分
│ ├── client
│ ├── config 代理的相关设置
│ └── utils
├── zhihu_captcha 验证码识别CNN模型
│ ├── checkpoint 保存好的参数权重
│ ├── orcmodel.py
│ ├── utils.py
│ └── zhihu_captcha.py 恢复权重及识别验证码
├── setting.json 填入知乎账号密码
├── zhihu_login.py 知乎自动登录模块
├── zhihu_spider.py 知乎爬虫,run it!
└── zhihudata.sql 建库sql
-
使用代理池,几百个代理轮转使用,防止IP被封
-
伪造User-Agent,随机选择fake_useragent库提供的ua和requests_html自带的ua
-
headers加入referer,更加逼真
-
尽可能使用知乎api取数据,而不通过html解析获取文本,加快速度,另外模仿正常人分页查询
-
存在要求登录才能查看的情况,于是实现了自动登录
-
使用CNN,自动识别英文验证码,验证通过unhuman检测
-
24h不停歇爬取,放心挂机
关注ta的:followers_api = "https://www.zhihu.com/api/v4/members/{}/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics\u0026offset={}\u0026limit=20".format(url_token, offset)
ta的关注:followees_api = "https://www.zhihu.com/api/v4/members/{}/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics\u0026offset={}\u0026limit=20".format(url_token, offset)
关注的话题:follow_topic_api = "https://www.zhihu.com/api/v4/members/{}/following-topic-contributions?include=data%5B*%5D.topic.introduction&offset={}&limit=20".format(url_token, offset)
回答:answer_api = 'https://www.zhihu.com/api/v4/members/{}/answers?include=data%5B*%5D.comment_count%2Cvoteup_count%2Ccreated_time&offset={}&limit=20&sort_by=created'.format(url_token, offset)
问题:question_api = 'https://www.zhihu.com/api/v4/questions/{}?include=data%5B*%5D.answer_count%2Cfollower_count'.format(qid)虽然有些提交参数是我们用不到的信息,但经过测试,加入后似乎更不容易被检测到,尤其是limit,不分页很容易被检测到异常
另外,问题的api params没法通过抓包看到,最开始我是html解析,css选择器找的;后来一个一个试参数试出来了适合的api
爬取的思想是,找一个关注者较多的用户作为seed,数据库里存入该用户的url_token,然后爬取他的关注者和关注,从而获得user表数据
最开始我设计的递归爬取(深度优先),然而递归次数过多超过最大递归次数会抛出异常,因此改成迭代爬取(广度优先),将待爬取的送入数据库(不然太耗费内存)以待以后继续
因为封装比较多,具体爬取参见zhihu_spider.py
数据库用pymysql库读写,封装在db.py
西刺上的免费代理质量不是很好,ip被封后大多很长时间内无法使用
查找发现这个代理池确实不错 https://github.com/SpiderClub/haipproxy
我的项目中只有client的部分,server端请自行clone并进行相关配置,我使用的方式是在docker上run splash容器(不爬需要渲染的代理网页就不需要了),在haipproxy目录下运行代码,详情请看该项目的README
找了几个项目,很多都过时了,只有这个最好 https://github.com/zkqiang/zhihu-login 因为有js执行部分,需要配置好npm、nodejs,并下载需要的依赖
但是它的验证码是手动输入的,需要改成自动输入验证码
我使用了此项目的CNN https://github.com/littlepai/Unofficial-Zhihu-API 用他的模型恢复参数,然后送入图片即可
知乎的验证码是base64 uri,以data:image/png;base64,开头, 后面是图片的base64编码,注意爬到的中间带有换行符,需要删掉再解码
自动登录时验证码通过 https://www.zhihu.com/api/v3/oauth/captcha?lang=en 获得(中文的需要用zheye,但没必要,识别英文足够了)
爬的数据量过多时,会出现unhuman验证,
验证码的get和post的url都是https://www.zhihu.com/api/v4/anticrawl/captcha_appeal
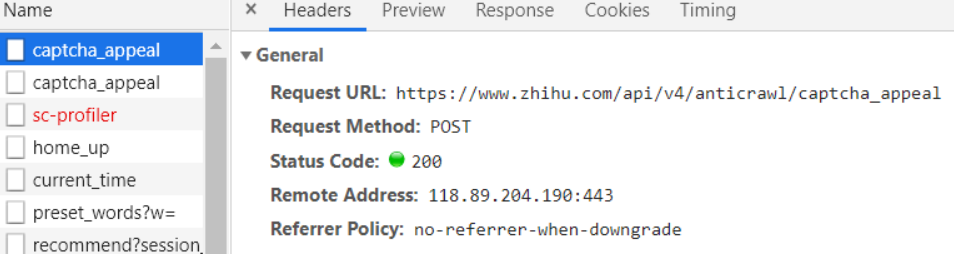
需要注意post的时候headers里没有xsrf会请求失败, 而之前get的时候,session的cookie里保存了xsrf,那么设置cookie就可以
import json
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
def appeal(self, url):
r = self.HTMLSession.get('https://www.zhihu.com/api/v4/anticrawl/captcha_appeal')
captchaUrl = r.json()['img_base64']
captchaUrl = re.sub('\n', '', captchaUrl)
with open('cache/captcha2.gif', 'wb') as f:
img_base64 = base64.b64decode(captchaUrl.strip('data:image/png;base64,').strip())
print(img_base64)
f.write(img_base64)
im = Image.open('cache/captcha2.gif')
im.save('cache/captcha2.png')
im = Image.open('cache/captcha2.png')
captcha = self.captcha_model.recgImg(im)
print(captcha)
r = self.HTMLSession.post('https://www.zhihu.com/api/v4/anticrawl/captcha_appeal',
data=json.dumps({"captcha": captcha}),
headers={"User-Agent": user_agent,
"referer": 'https://www.zhihu.com/account/unhuman?type=unhuman&message=%E7%B3%BB%E7%BB%9F%E7%9B%91%E6%B5%8B%E5%88%B0%E6%82%A8%E7%9A%84%E7%BD%91%E7%BB%9C%E7%8E%AF%E5%A2%83%E5%AD%98%E5%9C%A8%E5%BC%82%E5%B8%B8%EF%BC%8C%E4%B8%BA%E4%BF%9D%E8%AF%81%E6%82%A8%E7%9A%84%E6%AD%A3%E5%B8%B8%E8%AE%BF%E9%97%AE%EF%BC%8C%E8%AF%B7%E8%BE%93%E5%85%A5%E9%AA%8C%E8%AF%81%E7%A0%81%E8%BF%9B%E8%A1%8C%E9%AA%8C%E8%AF%81%E3%80%82&need_login=false',
'Content-Type': 'application/json',
'x-xsrftoken': self.HTMLSession.cookies._cookies['.zhihu.com']['/']['_xsrf'].value})
return self.HTMLSession.get(url, allow_redirects=False)词云


----------+---------+---------+-----------------------------------------------------
| avg_num | max_num | name_of_the_max (question, topic or usr)
----------+---------+---------+-----------------------------------------------------
答案赞同数 | 49.9 | 283059 | 北京协和医院有多牛?
答案评论数 | 7.4 | 23642 | 在交通工具上靠着陌生人的肩膀睡着了是怎样一种体验?
问题回答数 | 61.2 | 103795 | 有哪些让你感觉惊艳的名字?
问题关注数 | 522.3 | 569948 | 你有哪些内行人才知道的省钱诀窍?
话题关注数 | 127.5 | 167525 | 电影
话题问题数 | 3.2 | 33120 | 生活
用户回答数 | 5.5 | 30635 | 盐选推荐
用户关注数 | 138.1 | 7019194 | 知乎日报
用户文章数 | 0.4 | 41836 | 太平洋电脑网
----------+---------+---------+-----------------------------------------------------
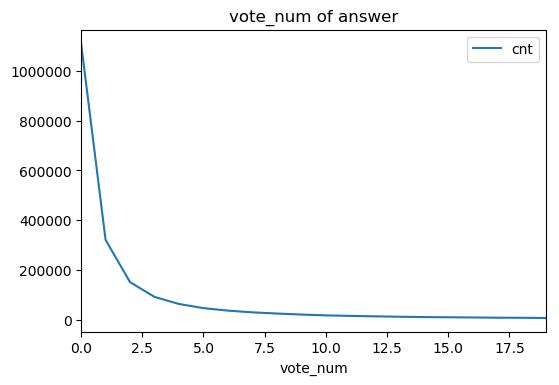
符合常识
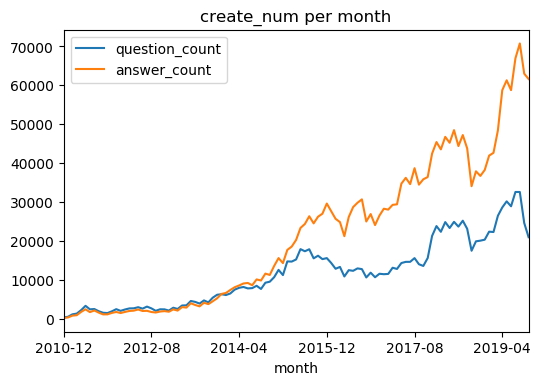
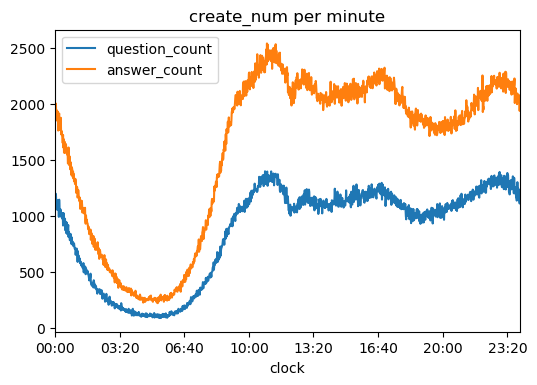
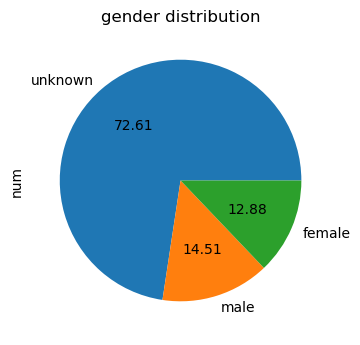
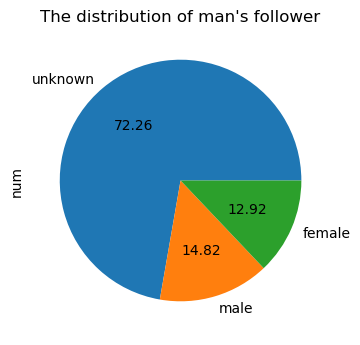
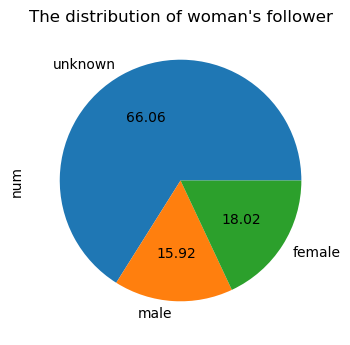
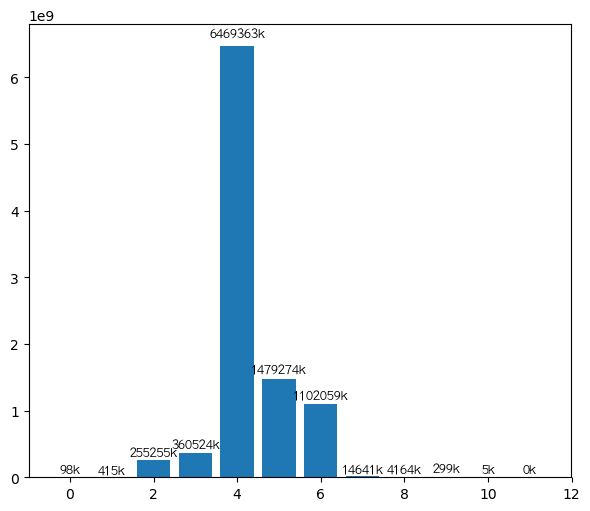
可以看到,最短距离6以上极少极少(这里也有没有把整个网络爬完的原因),基本验证了六度空间理论,并且社交距离绝大部分为4