Welcome to the Langchain Course repository! This repository contains code samples, exercises, and resources designed to help you get started with Langchain, a powerful Python library for building applications that interact with language models like GPT-4, GPT-4o, llama-3.1 & others.
Langchain is a framework that simplifies the development of language model-based applications. It enables developers to harness the capabilities of large language models (LLMs) for a variety of tasks, such as building chatbots, generating text, handling complex conversations, and creating advanced AI-driven applications.
This course will guide you through the core concepts of Langchain and help you build applications that can integrate language models effectively. Whether you're a beginner or an experienced developer, this course is designed to help you understand how to use Langchain in various real-world scenarios.
A ChatModel in LangChain is a specialized version of a language model designed to handle conversation-based inputs and outputs. Rather than dealing with simple text input and output, a ChatModel works with messages—pieces of text that are part of a dialogue, such as user inputs and model responses.
-
Message Format: ChatModels accept a structured format for inputs, typically with three types of messages:
- SystemMessage: A SystemMessage sets the context or behavior for the conversation. It’s like giving instructions to the AI on how to act, such as "You are a professional Python developer helping to write code." It defines the role or tone for the chat but doesn't directly interact with the conversation itself.
- HumanMessage: Represents the user's input in a conversation (e.g., questions or prompts).
- AIMessage: Response from the model to the user's input. It’s what the AI sends back based on the conversation or prompt provided.
-
Multi-turn Conversations: Capable of handling context-aware conversations.
-
Support for Different Providers: Can integrate with various providers such as OpenAI's GPT models and Google’s Generative AI models.
The invoke method in LangChain processes the input and returns the result. It ensures that the entire chain of models or prompts is executed in the correct order.
- Input: You provide input to the invoke method, usually a dictionary of key-value pairs.
- Sequential Processing: Input is passed through each model or step in the chain.
- Output: Returns the final result after processing.
A Prompt Template in LangChain defines reusable, structured prompts for language models. It allows you to define a general structure with placeholders for dynamic information.
-
Static Structure with Dynamic Placeholders: Fixed structure with placeholders filled in at runtime.
template = "Write a blog post about {topic} that focuses on {key_points}."
-
Customizable Input Variables: Can take multiple input variables for tailoring prompts.
from langchain.prompts import PromptTemplate template = "Translate the following text to {language}: {text}" prompt_template = PromptTemplate( input_variables=["language", "text"], template=template ) prompt = prompt_template.format(language="French", text="Hello, how are you?") # Output: "Translate the following text to French: Hello, how are you?"
-
Multiple Use Cases: Used for various applications such as content generation, translation, customer support, and more.
-
Maintaining Consistency: Ensures consistently structured prompts.
In LangChain, Chains are like workflows that connect different steps or processes together. Each step in the chain takes some input, does something with it (like generating text or answering a question), and then passes the result to the next step.
Think of it like an assembly line: one machine does its job and then passes the product to the next machine to finish the process. In LangChain, these "machines" are language models (or other tools), and the "product" is the information they generate or process.
Chains make it easy to combine different tasks and create more complex systems by connecting multiple steps in a sequence!
- Chain Extended: This is when you connect multiple steps or language models in a sequence, with each step passing its output as input to the next step. It’s like a pipeline where each task builds on the result of the previous one, allowing you to perform a series of actions in a structured order.
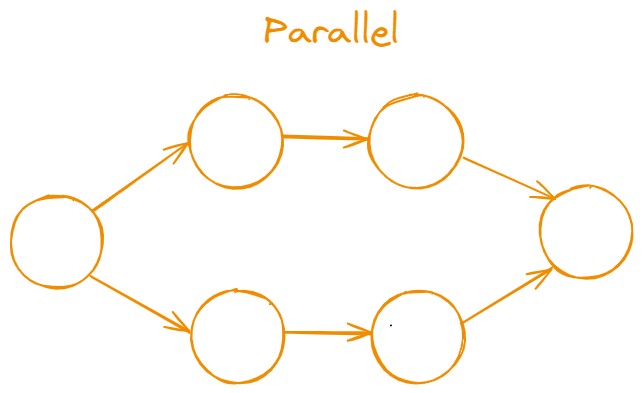
- Parallel Chain: In a parallel chain, multiple steps run at the same time, each working independently on different tasks or inputs. After all the steps finish, their results are combined or used together. This is useful when you need to process several pieces of information simultaneously.
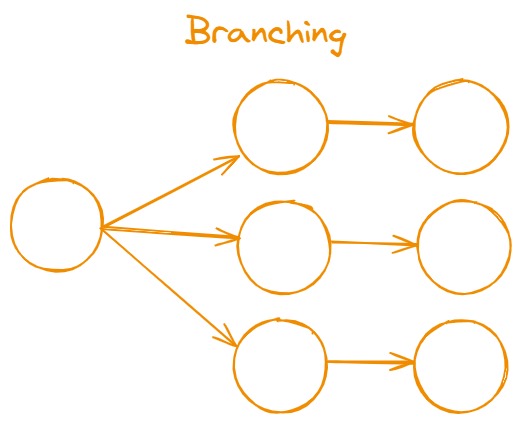
- Chain Branching: Chain branching involves splitting the workflow into different paths based on certain conditions or criteria. Depending on the input or result, the process can take different directions, allowing for more flexible and dynamic workflows.
In LangChain, RAG is a framework that enhances the generation of responses from a language model by augmenting it with external, up-to-date, and relevant information retrieved from specific data sources (like the web, documents, or databases).
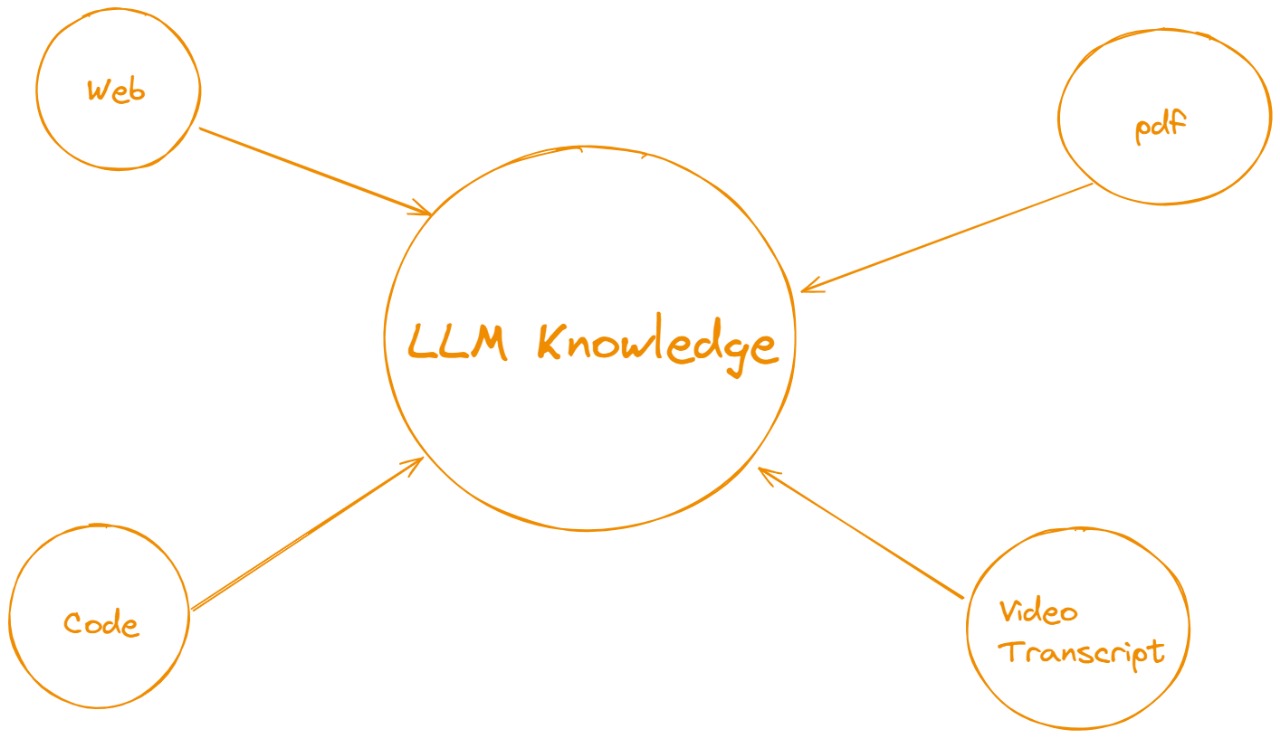
In the context of LangChain and RAG, think of the LLM Knowledge as the central piece, but it is being fed with various retrieval sources:
- Web: External data fetched from the internet.
- PDF: Information extracted from documents.
- Code: Programmatic knowledge or examples retrieved from code bases.
- Video Transcript: Information extracted from video transcripts to include context from audiovisual content.
The RAG process involves retrieving relevant data from these sources, and the LLM then uses this data to generate a response. The retrieved information supplements the LLM's knowledge, resulting in more accurate and context-aware outputs.
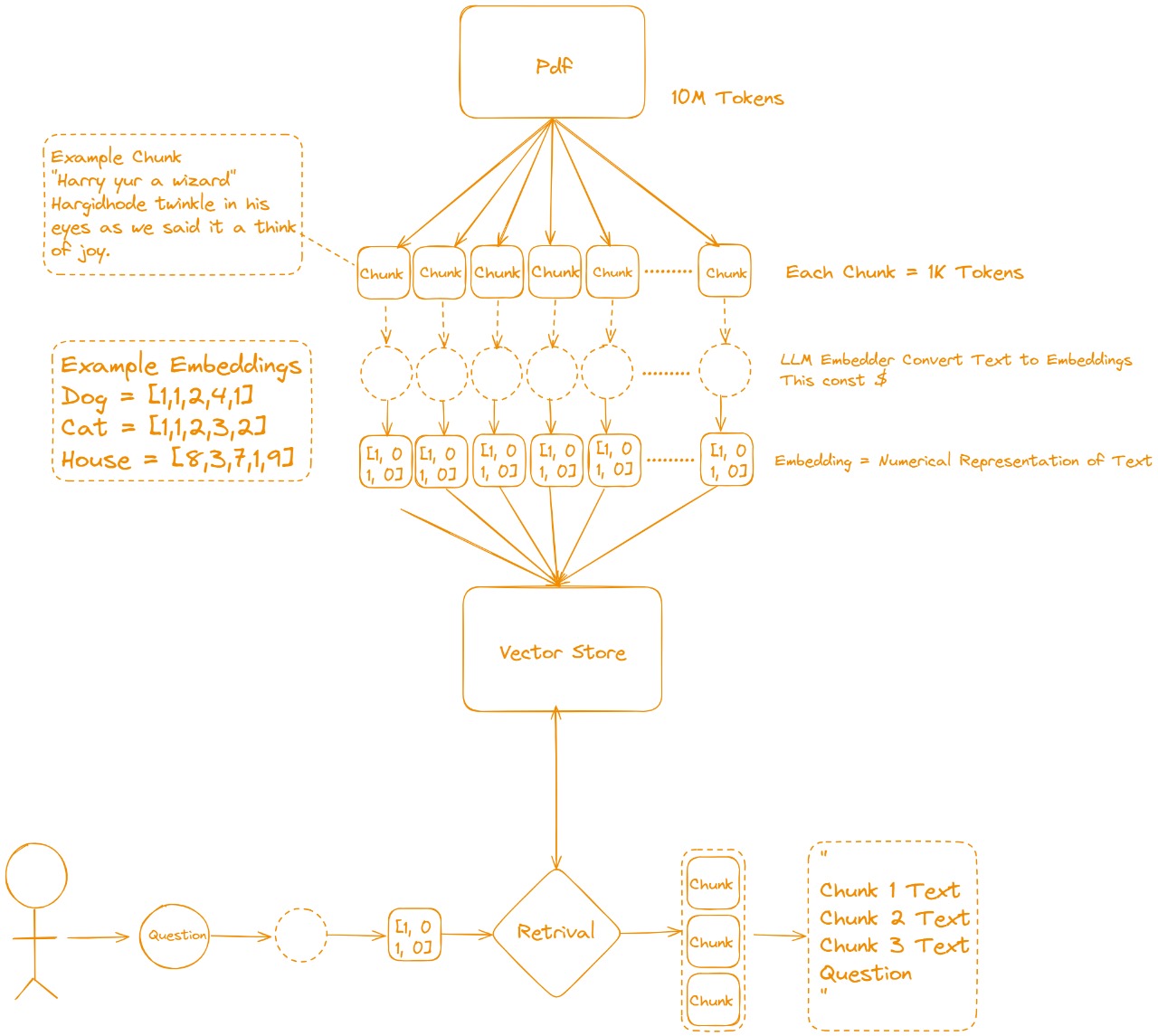
- You start with a large source of information, such as a PDF containing millions of tokens. Tokens are essentially the building blocks of text (like words or pieces of words).
-
Since handling the entire document at once can be computationally expensive, the text is chunked into smaller pieces, typically of 1K tokens each.
-
Each chunk represents a small segment of the original text, making it more manageable for processing and retrieval.
-
Embeddings are the core of this process. They are numerical representations of text, meaning the chunks of text are converted into vectors (arrays of numbers).
-
For example, as shown in the diagram, simple embeddings for "Dog" could be [1,1,2,4,1], and similarly for "Cat" and "House."
-
These embeddings help the machine understand and compare the chunks of text by converting the semantic meaning into a format it can mathematically process.
-
LLM Embedder: The task of converting text into embeddings is done by a Language Model Embedder. This process may have a cost, because generating embeddings for large texts requires significant computational resources.
- Once the text is embedded (converted to numerical form), the embeddings are stored in a Vector Store.
-A Vector Store is a specialized database designed to handle and store high-dimensional vectors (i.e., embeddings).
- It allows for efficient retrieval of relevant chunks based on similarity searches, meaning it can quickly find the chunks most closely related to a specific query.
-
When a user asks a Question, the question itself is also converted into an embedding.
-
This embedding is then matched against the embeddings stored in the Vector Store, and the closest matches (in terms of similarity) are retrieved.
-
The most relevant chunks of text (based on the vector similarity) are pulled from the vector store.
-
The retrieved chunks are combined along with the user's original question to form a final input.
-
This input, consisting of both the relevant chunks of text and the question, is sent to a Language Model to generate a final response.
-
Final Output: The output includes all relevant chunks that can help the model generate an informed answer, as well as the specific response to the user’s question.
-
A large document (like a PDF) is split into smaller, manageable pieces (chunks).
-
Each chunk is converted into a vector (embedding), which is a mathematical representation of the text.
-
These embeddings are stored in a vector database (Vector Store).
-
When a user asks a question, it is also converted into an embedding, and the system retrieves the most relevant chunks based on vector similarity.
-
The relevant chunks, along with the user’s question, are processed together to generate a more informed response.
- Efficiency: Instead of passing an entire document to the model, RAG retrieves only the most relevant chunks, reducing the computational load.
- Accuracy: By using real-time data retrieval, the model can generate more accurate and context-aware answers.
- Scalability:: RAG can scale to handle large volumes of text, as it uses chunking and efficient retrieval techniques to access specific parts of the document.
Agents & Tools are two key concepts in LangChain that allow language models to perform actions, interact with external systems, and generate results dynamically.
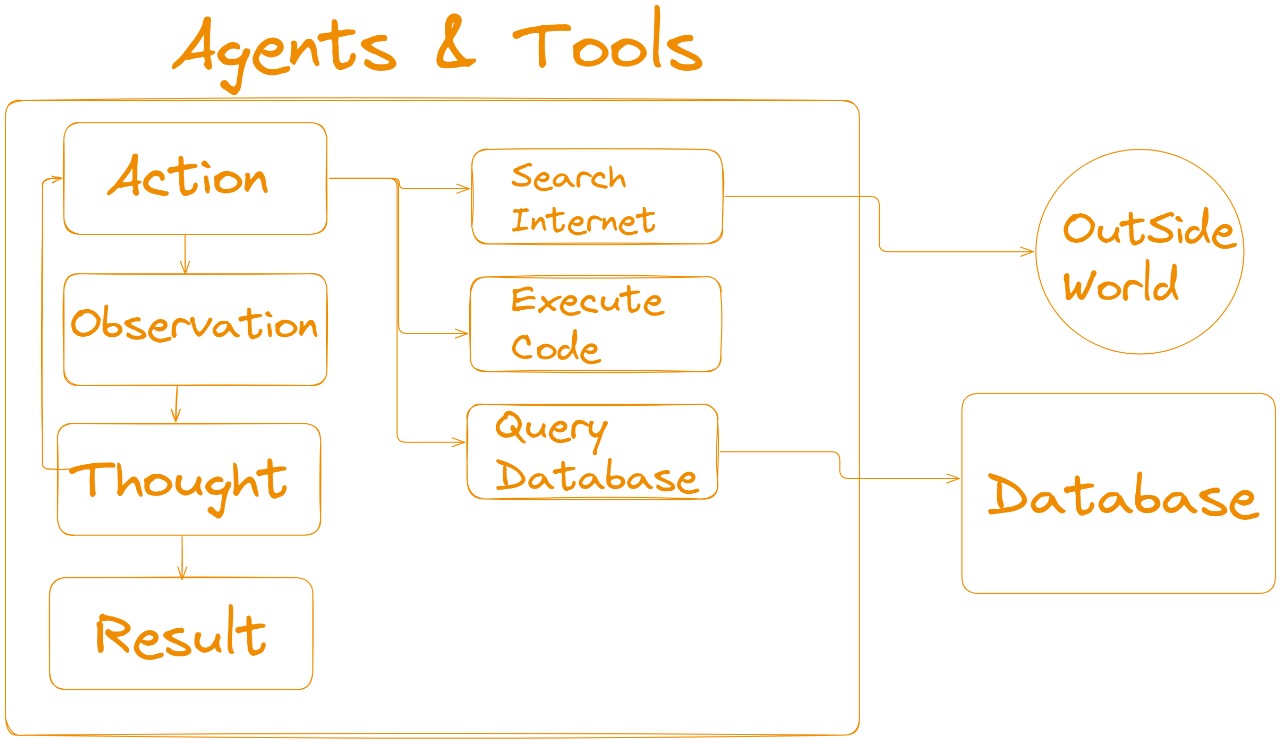
In LangChain, an Agent is essentially a language model (LLM) that has been provided with a specific prompt to define its behavior. The behavior of an agent is comparable to a state machine, where different actions are performed depending on the agent's state. Each state has its own action, and the agent moves from one state to the next, looping through tasks as defined by the prompt.
- Action: The agent takes an action (like answering a question, performing a task, etc.).
- Observation: After taking an action, the agent observes the result or feedback from the action.
- Thought: Based on its observations, the agent thinks or processes the information.
- Result: Finally, the agent produces a result or output based on its thought process.
This cycle repeats, allowing the agent to handle tasks dynamically. Each time, the agent's actions are guided by the prompts you design, which tell it how to behave in different states.
Tools in LangChain are interfaces that an agent, chain, or LLM can use to interact with the external world. These tools enable agents to perform actions beyond simple text generation, such as searching the web, executing code, or querying a database.
- Search Internet: The agent uses this tool to retrieve information from the web, accessing real-time data to supplement its responses.
- Execute Code: With this tool, the agent can run scripts or code to perform computations or other programmatic tasks.
- Query Database: This tool allows the agent to access and retrieve information from databases, providing more structured data or facts in its outputs. By using these tools, the agent can perform more complex tasks and retrieve relevant data from external sources, enhancing its functionality and making it more versatile.
In summary, agents in LangChain are state-driven language models that move through a sequence of actions, observations, and thoughts to produce a result. Tools enhance the agent's capabilities by providing interfaces to interact with the external world, enabling it to search for information, run code, or query databases. Together, agents and tools allow you to create highly dynamic, flexible, and intelligent systems capable of complex tasks.
