

Full knowledge and control of the train state.
DeepTrain is founded on control and introspection: full knowledge and manipulation of the train state.
- Resumability: interrupt-protection, can pause mid-training
- Tracking & reproducibility: save & load model, train state, random seeds, and hyperparameter info
- Flexible batch_size: can differ from that of loaded files, will split/combine (ex)
- Faster SSD loading: load larger batches to maximize read speed utility
- Stateful timeseries: splits up a batch into windows, and
reset_states()(RNNs) at end (ex)
- Model: auto descriptive naming (ex); gradients, weights, activations visuals (ex)
- Train state: image log of key attributes for easy reference (ex); batches marked w/ "set nums" - know what's being fit and when
- Algorithms, preprocesing, calibration: tools for inspecting & manipulating data and models
Training few models thoroughly: closely tracking model and train attributes to debug performance and inform next steps.
DeepTrain is not for models that take under an hour to train, or for training hundreds of models at once.
Abstract away boilerplate train loop and data loading code, without making it into a black box. Code is written intuitively and fully documented. Everything about the train state can be seen via dedicated attributes; which batch is being fit and when, how long until an epoch ends, intermediate metrics, etc.
DeepTrain is not a "wrapper" around TF; while currently only supporting TF, fitting and data logic is framework-agnostic.
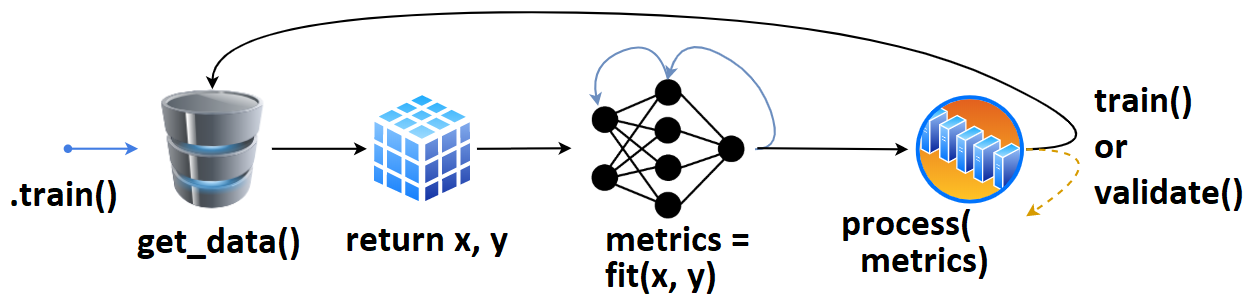

- We define
tg = TrainGenerator(**configs), - call
tg.train(). get_data()is called, returning data & labels,- fed to
model.fit(), returningmetrics, - which are then printed, recorded.
- The loop repeats, or
validate()is called.
Once validate() finishes, training may checkpoint, and train() is called again. Internally, data loads with DataGenerator.load_data() (using e.g. np.load).
That's the high-level overview; details here. Callbacks & other behavior can be configured for every stage of training.
| MNIST AutoEncoder | Timeseries Classification | Health Monitoring |
|---|---|---|
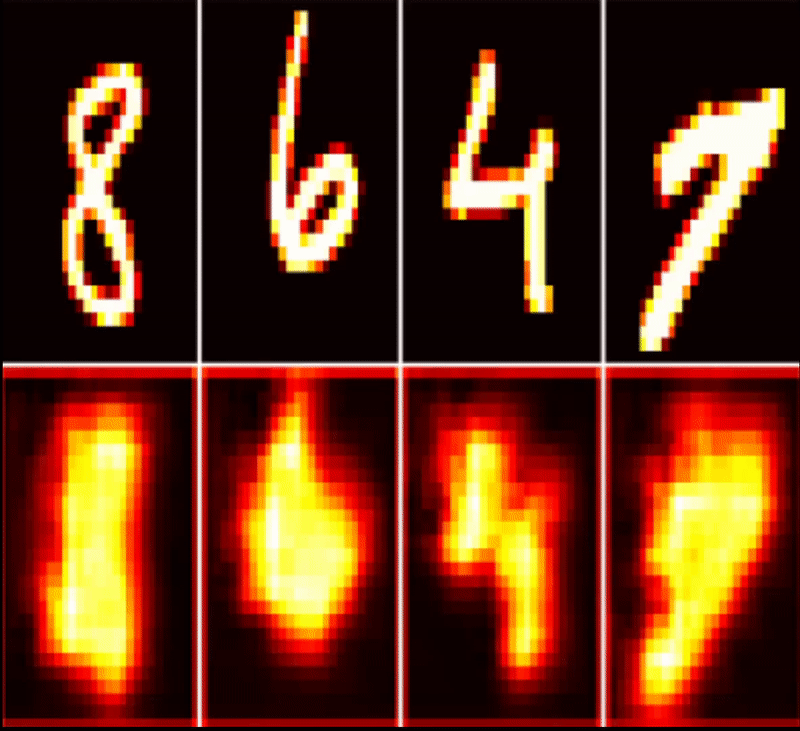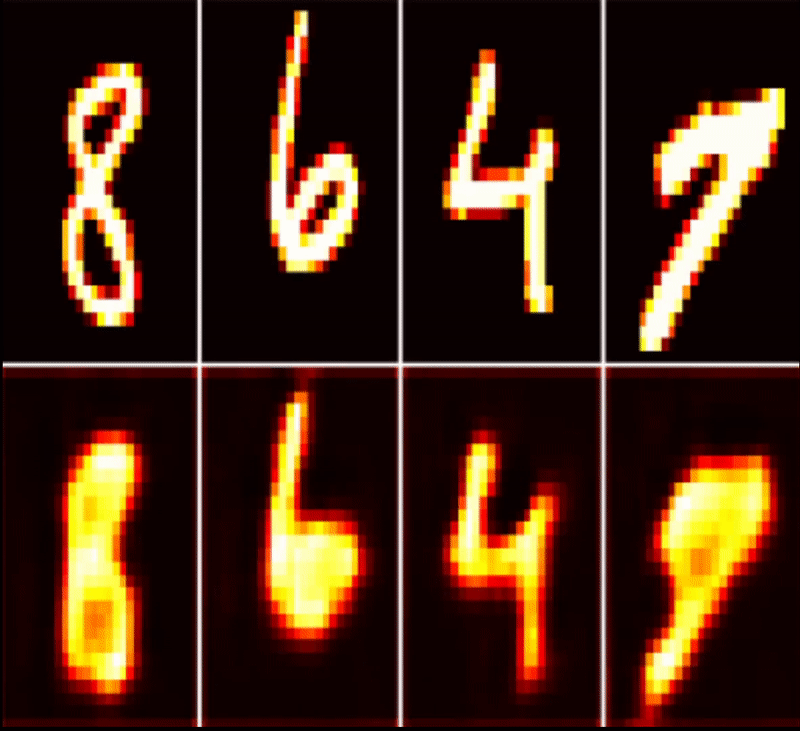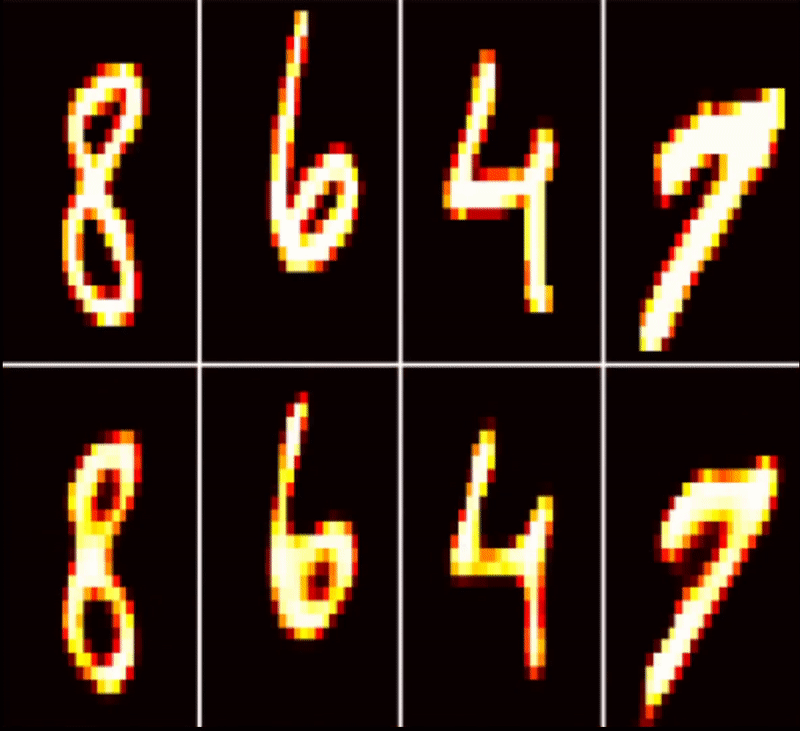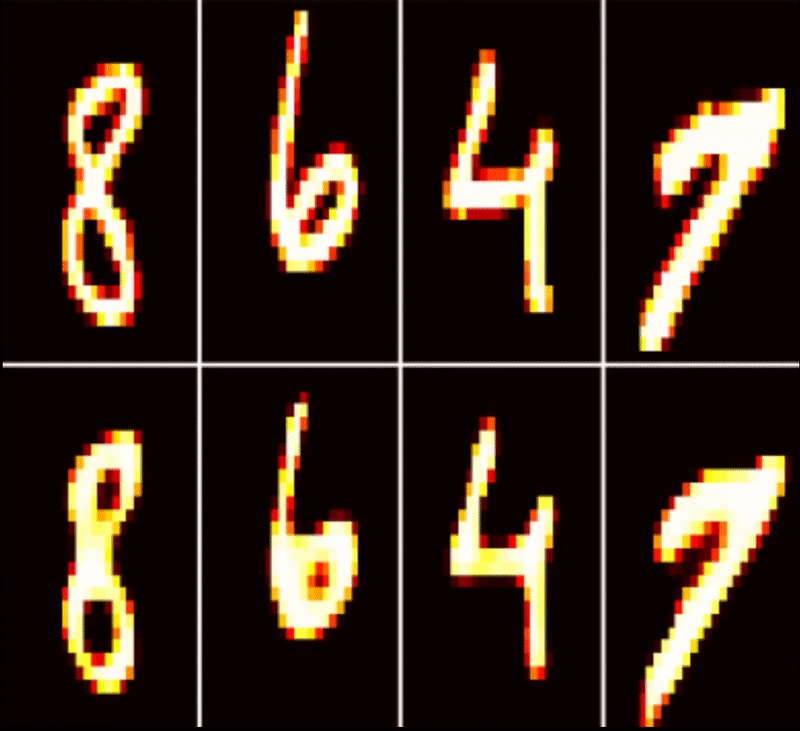 |
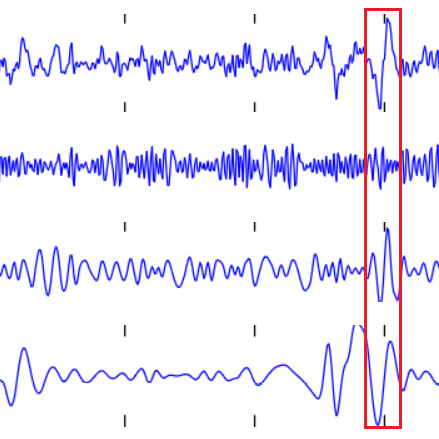 |
 |
| Tracking Weights | Reproducibility | Flexible batch_size |
|---|---|---|
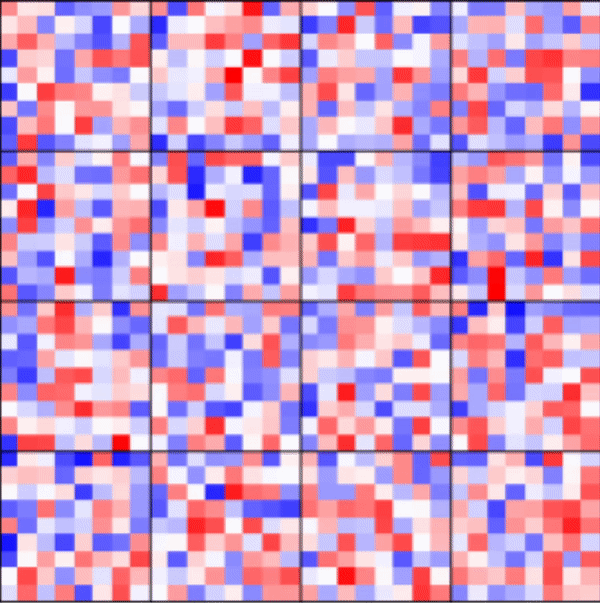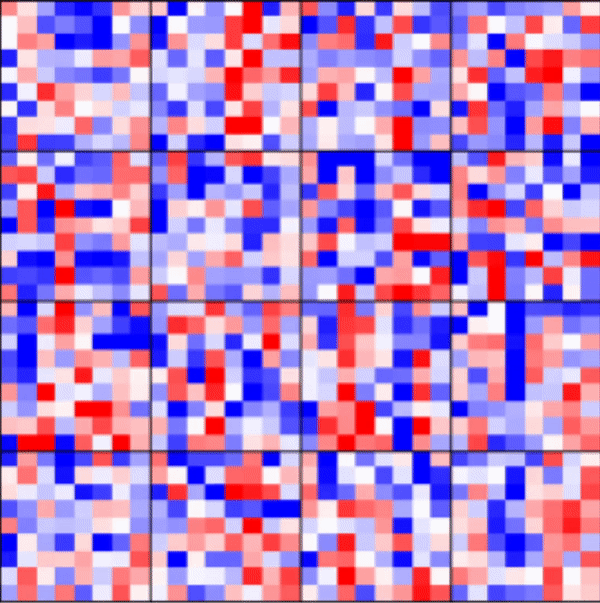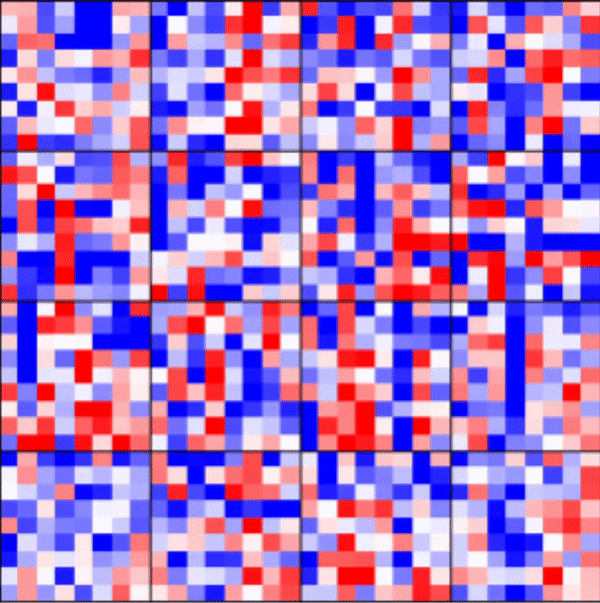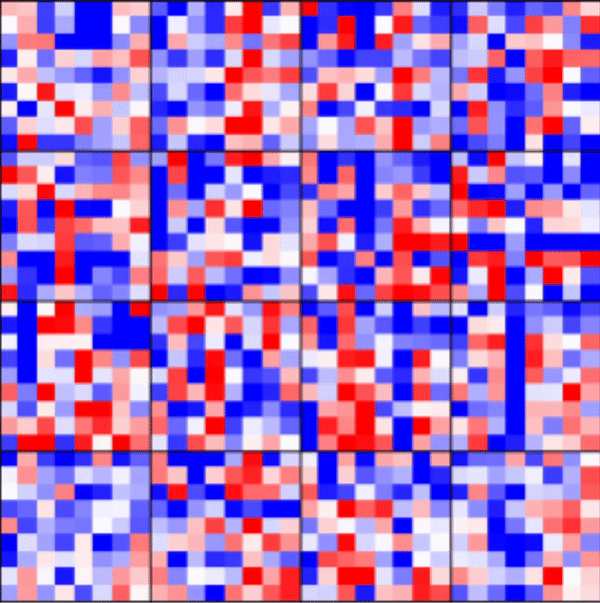 |
 |
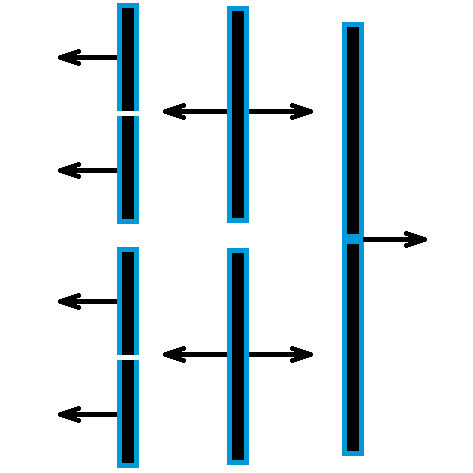 |
pip install deeptrain (without data; see how to run examples), or clone repository
To run, DeepTrain requires (1) a compiled model; (2) data directories (train & val). Below is a minimalistic example.
Checkpointing, visualizing, callbacks & more can be accomplished via additional arguments; see Basic and Advanced examples. Also see Recommended Usage.
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from deeptrain import TrainGenerator, DataGenerator
ipt = Input((16,))
out = Dense(10, 'softmax')(ipt)
model = Model(ipt, out)
model.compile('adam', 'categorical_crossentropy')
dg = DataGenerator(data_path="data/train", labels_path="data/train/labels.npy")
vdg = DataGenerator(data_path="data/val", labels_path="data/val/labels.npy")
tg = TrainGenerator(model, dg, vdg, epochs=3, logs_dir="logs/")
tg.train()MetaTrainer: direct support for dynamic model recompiling with changing hyperparameters, and optimizing thereof- PyTorch support