In this we explore detailed architecture of Transformer
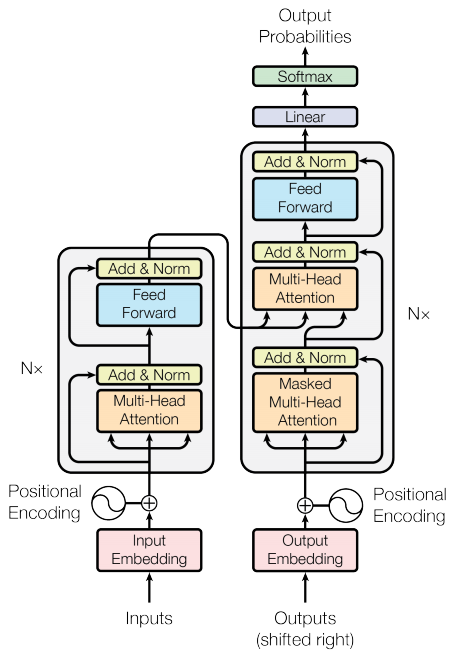
The Transformer architecture, introduced in the 2017 paper "Attention is All You Need" by Vaswani et al., revolutionized natural language processing (NLP) and other machine learning domains. The architecture's key innovation is the self-attention mechanism, which allows it to weigh the importance of different words in a sentence or sequence, regardless of their position. Transformers outperform recurrent architectures (like LSTMs and GRUs) by allowing for much more parallelization and handling long-range dependencies effectively.
The Transformer is primarily used in sequence-to-sequence tasks (e.g., machine translation, text summarization, etc.), and is composed of two main components:
- Encoder: Transforms the input sequence into an abstract representation.
- Decoder: Takes the encoded representation and produces the output sequence (e.g., translated text, generated summary, etc.).
The Transformer consists of stacked layers of encoders and decoders, typically 6 layers for both in the original model.
Each encoder layer has two sub-layers:
- Multi-Head Self-Attention: Computes the relationships between all words in the input sequence by focusing on different positions of the input sequence.
- Position-Wise Feed-Forward Network: Applies a fully connected neural network to each position in the sequence.
Each sub-layer is followed by layer normalization and residual connections (skip connections). This is to stabilize and improve the flow of gradients during training.
The encoder processes the input sequentially through these layers.
Each decoder layer has three sub-layers:
- Masked Multi-Head Self-Attention: Prevents the decoder from attending to future tokens in the sequence (important for autoregressive tasks like text generation).
- Multi-Head Attention over Encoder Outputs: Attends to the output from the encoder to gather relevant context from the input sequence.
- Position-Wise Feed-Forward Network: Similar to the encoder's feed-forward network, it applies non-linear transformations to the data.
Like the encoder, each decoder sub-layer is followed by layer normalization and residual connections.
The self-attention mechanism is the cornerstone of the Transformer. It allows the model to focus on specific parts of the input sequence when processing each token.
Given an input sequence, the self-attention mechanism works as follows:
- Every token in the sequence is transformed into three vectors: query (Q), key (K), and value (V).
- The attention score between two tokens is calculated using the dot product of the query of one token and the key of another.
- These scores are then normalized using the softmax function, which determines the influence of each token on others.
- The resulting scores are used to weight the values, which are summed to get the final output for each token.
The equation for scaled dot-product attention is:
The attention mechanism is defined as: [ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V ]
Where:
- Q: The Query matrix (represents the current word's feature vector).
- K: The Key matrix (represents the feature vectors of all words).
- V: The Value matrix (also represents the feature vectors of all words).
- (d_k): The dimensionality of the key vectors (used for scaling).
Where (d_k) is the dimensionality of the queries and keys.
The Transformer employs multi-head attention, which allows the model to focus on different parts of the sequence simultaneously. Multiple attention heads (usually 8 or 16) calculate self-attention in parallel, and their results are concatenated.
This mechanism allows the model to capture various aspects of the relationships between tokens (e.g., syntax, semantics).
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h) W^O ]
Each attention head calculates self-attention independently, with its own linear projections.
The Feed-Forward Network (FFN) is applied independently to each position in the sequence. It's a simple two-layer fully connected network with a ReLU activation between them:
[ \text{FFN}(x) = \text{max}(0, xW_1 + b_1)W_2 + b_2 ]
This helps introduce non-linearity and interaction between different parts of the input representation.
Since the Transformer architecture does not have any recurrence or convolution, it lacks the means to capture the sequential nature of the input data. To address this, positional encodings are added to the input embeddings to give the model information about the position of tokens in the sequence.
The positional encodings are added to the input embeddings before being fed into the encoder. These encodings are typically sinusoidal, allowing the model to generalize to different sequence lengths.
The formula for positional encoding is:
[ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right) ] [ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right) ]
Where (pos) is the position and (i) is the dimension index.
The Transformer is typically trained using teacher forcing in sequence-to-sequence tasks:
- During training, the decoder is provided with the true output sequence, shifted by one position.
- During inference, the decoder generates tokens step by step (autoregressively), using the previously generated tokens.
-
Parallelization: Since the Transformer does not rely on sequential processing like RNNs, it can process entire sequences at once. This allows for significant parallelization and faster training times, especially on modern hardware.
-
Long-Range Dependencies: The self-attention mechanism can model relationships between tokens that are far apart in the sequence, something RNNs struggle with.
-
Scalability: Transformers scale well to large models and datasets, making them suitable for very large tasks like GPT-3, BERT, and T5.
-
Universal Applicability: Transformers have been successfully adapted beyond NLP to other domains like vision (e.g., Vision Transformers) and speech processing.
-
BERT (Bidirectional Encoder Representations from Transformers): BERT uses the Transformer encoder stack and is trained to predict masked tokens, making it well-suited for tasks requiring deep understanding of language context.
-
GPT (Generative Pre-trained Transformer): GPT uses the Transformer decoder stack for autoregressive text generation tasks.
-
T5 (Text-To-Text Transfer Transformer): T5 frames every NLP task as a text-to-text task, using both the encoder and decoder stacks.
-
Vision Transformer (ViT): Adapts the Transformer architecture for image classification tasks by treating patches of images as tokens.
The Transformer architecture has become the dominant model in many machine learning tasks, particularly in NLP. Its innovative use of self-attention, coupled with multi-head mechanisms and feed-forward layers, provides a highly flexible, efficient, and scalable model. The architecture continues to evolve and inspire newer models across multiple domains, pushing the boundaries of what’s possible in machine learning.
The Transformer architecture is composed of several key components, each serving a distinct function to facilitate the model's efficiency and effectiveness in handling sequential data like text. Below is a detailed explanation of the usage of all components in the Transformer.
The self-attention mechanism allows the model to weigh the importance of different tokens (words) in a sequence relative to one another. This is crucial because, unlike traditional models (e.g., RNNs), the Transformer doesn't process the sequence in a strict order but rather looks at the entire sequence at once.
- Token Dependency Modeling: When processing a word in a sentence, the model can attend to other words, understanding the relationships between them regardless of their position in the sequence.
- Parallel Processing: Since all tokens in the sequence are attended to simultaneously, the self-attention mechanism allows the Transformer to process the sequence in parallel rather than step-by-step, like RNNs.
- Contextual Embedding: Each token's embedding is updated to reflect its relationships with other tokens, helping the model understand word meanings in context (e.g., polysemy).
Example**: In a sentence like "The cat sat on the mat," when processing the word "sat," the model may attend to "cat" to understand that the subject (the cat) is performing the action (sat).
The multi-head attention mechanism allows the Transformer to capture different aspects of the relationships between tokens. It splits the attention mechanism into several heads, each learning different patterns in the sequence, and combines the results for a more nuanced understanding.
- Capturing Multiple Relationships: Each attention head focuses on different parts of the sequence, which helps the model understand different linguistic relationships. For example, one head might focus on syntactic relationships while another head focuses on semantic relationships.
- Dimensional Reduction and Representation: Each head processes attention with a reduced dimensionality (fewer parameters per head), allowing the model to efficiently compute multiple perspectives of the same sequence.
Example**: In the sentence "The dog chased the cat," one attention head may focus on "dog" and "chased," while another head might attend to "cat" and "chased" to capture different dependencies.
The feed-forward network applies a transformation to each position independently after the attention layer. It is a two-layer fully connected neural network with a non-linear activation (e.g., ReLU). The idea is to add complexity and flexibility by enabling each token's representation to be refined based on the entire input sequence's attention results.
- Non-Linear Transformations: After the self-attention mechanism computes token relations, the FFN introduces non-linearity to the model, allowing it to learn more complex patterns.
- Independent Processing: The FFN processes each token independently, helping the model capture features from the embedding space, even after the attention process.
Example**: After attending to other words in the sentence, the FFN layer processes the new representation of the token "sat" and applies further transformations to refine its meaning.
Since the Transformer does not have any recurrence or convolution (which naturally capture sequential information), it needs a way to understand the order of tokens in the input sequence. Positional encodings are added to the input embeddings to provide information about the position of each token in the sequence.
- Injecting Sequential Order: The positional encoding allows the model to differentiate between tokens based on their position, crucial for understanding syntactic structures, such as "who did what to whom" in a sentence.
- Sinusoidal Encoding: The original Transformer uses sinusoidal positional encodings, but other versions might use learned embeddings. These positional encodings are added to token embeddings, ensuring that tokens like "dog" and "chased" are understood differently in different positions.
Example**: In the sentence "The cat sat on the mat," the positional encodings ensure that "The" (position 1) and "mat" (position 5) are treated differently by the model, even if their embeddings are similar.
- Layer Normalization ensures that the inputs to each sub-layer have a stable distribution, improving training speed and stability.
- Residual Connections (skip connections) help alleviate the vanishing gradient problem by allowing gradients to flow through the network more easily. These connections also enable deeper models by passing information across layers directly.
- Layer Normalization: Applied to the outputs of the attention and feed-forward sub-layers, normalizing the data to ensure consistent scaling and avoid exploding or vanishing gradients.
- Residual Connections: At each sub-layer (both self-attention and feed-forward layers), the residual connection adds the input of the sub-layer to its output, enabling smoother gradient propagation and stabilizing training.
Example**: When processing a sentence, the input to each attention or FFN layer is passed along to the next, but with an added residual (or shortcut) connection that allows the model to learn more robust features.
The decoder has a unique form of masked multi-head attention that prevents it from attending to future tokens during training, ensuring that the generation of a token depends only on the previous tokens, preserving the autoregressive nature of language models.
- Autoregressive Modeling: In sequence generation tasks, this masking ensures that the model only attends to already generated tokens, mimicking how humans generate text (from left to right, without knowing future words).
- Masking Future Tokens: This prevents tokens from looking ahead in the sequence, which is critical during training for tasks like machine translation or text generation.
Example**: When generating the word "chased" in the sentence "The dog chased the cat," the decoder only looks at the words "The dog" and not "the cat" since it's not yet predicted.
This layer in the decoder attends to the encoder's final hidden states to gather relevant context from the input sequence (e.g., source language in machine translation) to help generate the output sequence.
- Attending to Input Sequence: The decoder needs information from the encoder to correctly translate or transform the input sequence into the target sequence. This layer ensures that the decoder has full access to the input sequence's encoded representation.
- Cross-Attention: This is crucial for tasks like translation, where the decoder needs to attend to both the current target token and all input tokens to generate an accurate translation.
Example**: In translating "The dog chased the cat" from English to French, the decoder attends to the encoder outputs (which contain the encoded representation of the English sentence) while generating the French translation.
The final linear layer maps the decoder's output to a probability distribution over the vocabulary. The softmax function is then applied to generate probabilities for each possible word/token, allowing the model to pick the most likely next word in the sequence.
- Vocabulary Distribution: The final layer outputs a probability distribution over the vocabulary at each step. The word with the highest probability is selected as the next token.
- Text Generation: This step is essential for any sequence generation task (e.g., translation, summarization, or text completion), where the model needs to output coherent, grammatically correct, and contextually appropriate sentences.
Example**: After processing the input, the model might predict that the next word in the sequence has a high probability of being "dog" based on the encoder-decoder attention.
- Input Embedding: The input tokens are first embedded (converted into dense vectors) and passed through the positional encoding layer.
- Encoder: Each encoder layer processes the input sequence using multi-head self-attention, followed by feed-forward networks. The sequence passes through multiple encoder layers, capturing long-range dependencies between tokens.
- Decoder: The decoder uses masked multi-head self-attention to focus on already generated tokens, followed by attention over the encoder’s output (cross-attention). The processed sequence then passes through feed-forward layers to refine the outputs.
- Output: The decoder produces the output sequence, token by token, by sampling from the softmax probabilities generated by the final linear layer.
Each component in the Transformer architecture serves a critical function, contributing to the model's ability to understand sequences, attend to important information, and generate meaningful output. The combination of attention mechanisms, feed-forward layers, and positional encodings makes the Transformer versatile and powerful across various tasks, especially in natural language processing, machine translation, and beyond.
Certainly! Let's dive deeper into the components of the Transformer architecture and discuss additional details about their inner workings, motivations, and impact on the model's overall performance.
The input text is tokenized and each token (word or sub-word) is converted into a fixed-dimensional vector. This vector, or embedding, captures semantic information about the token. Transformers typically use pre-trained embeddings (like Word2Vec or BERT embeddings), or learn these embeddings during training.
- Motivation: Token embeddings are essential for converting discrete tokens (words) into continuous vectors that can be processed by neural networks.
- Usage: Each token in the input sequence is represented by an embedding vector of a fixed dimension (e.g., 512 or 1024 dimensions in large models like BERT or GPT).
Since the Transformer architecture does not naturally capture the order of tokens (no recurrence or convolution), positional embeddings are added to token embeddings to give the model a sense of token order.
-
Sinusoidal Positional Embedding: The original Transformer uses sinusoidal functions to generate these embeddings. These functions allow the model to generalize to sequences longer than those seen during training.
- Equation: [ PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{\text{model}}}) ] [ PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}}) ]
- Even indices of the embedding are filled with the sine function, while odd indices are filled with the cosine function. This allows the Transformer to learn relationships between token positions, regardless of sequence length.
-
Learned Positional Embedding: Some Transformer variants use learned positional embeddings instead of sinusoidal functions. These are learned during training and offer more flexibility but may not generalize as well to unseen sequence lengths.
The Scaled Dot-Product Self-Attention mechanism forms the backbone of the Transformer. It computes attention scores for every token pair in the input sequence, which helps the model decide how much focus one token should give to other tokens.
The self-attention mechanism operates on three matrices derived from the input embeddings:
- Query (Q): Represents the current token being processed.
- Key (K): Represents other tokens to which the current token will attend.
- Value (V): Represents the contextual information carried by the other tokens.
The attention score is computed using the dot product of the query and key, scaled by the square root of the dimensionality of the key vectors ((\sqrt{d_k})) to avoid large values: [ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V ]
- Scaling: The scaling factor (\sqrt{d_k}) is crucial because without it, dot products could result in excessively large gradients, which can cause convergence issues during training.
- Long-Range Dependencies: Self-attention captures both short-term and long-term dependencies, allowing the model to relate tokens across the entire input sequence. This enables better contextual understanding of relationships, unlike RNNs, which struggle with long dependencies.
- Parallelization: Unlike RNNs that require sequential processing, the self-attention mechanism operates on the entire sequence at once, making it highly parallelizable and efficient.
The Transformer applies attention mechanisms multiple times in parallel, which is referred to as multi-head attention. Each attention head processes the input in different subspaces, enabling the model to learn varied types of relationships between words.
- Multiple Attention Heads: The input embeddings are projected into different query, key, and value spaces using learned matrices. Each head performs attention independently.
- Concatenation: The outputs from each head are concatenated and linearly transformed to produce the final attention output.
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O ]
- Here, (W^O) is a weight matrix learned during training, and each head focuses on different aspects of the input sequence.
- Capturing Different Patterns: With multiple attention heads, the model can capture various linguistic patterns (e.g., syntactic, semantic, co-reference, etc.). Each head may attend to different tokens, improving the model's overall understanding of the input.
- Dimensionality Reduction: Instead of processing attention in a single large space, multi-head attention splits the attention mechanism into smaller subspaces, reducing the computational load and making the model more efficient.
Each encoder and decoder layer has a Position-wise Feed-Forward Network (FFN) that processes each token’s embedding independently after the attention mechanism.
- The FFN applies two linear transformations with a non-linear activation in between, usually ReLU: [ \text{FFN}(x) = \text{max}(0, x W_1 + b_1) W_2 + b_2 ] Where (W_1) and (W_2) are learned weight matrices, and (b_1) and (b_2) are learned biases.
- Token-Level Non-Linearity: The FFN provides the non-linear transformation required to model complex relationships. It ensures that each token embedding is processed individually after the attention mechanism, improving the model’s ability to capture diverse patterns.
- Token Independence: The FFN operates independently on each token, allowing the model to refine each token’s representation without considering its relation to other tokens at this stage.
Layer Normalization and Residual Connections help improve training stability and efficiency by ensuring that inputs to each sub-layer are well-behaved and that gradients propagate smoothly.
- Operation: Layer normalization is applied to each token’s embedding before it passes into the attention or FFN layers. It normalizes the embedding values, improving gradient flow and stabilizing training. [ \text{LayerNorm}(x) = \frac{x - \mu}{\sigma + \epsilon} ] Where (\mu) is the mean and (\sigma) is the standard deviation of the input (x), and (\epsilon) is a small constant for numerical stability.
- Motivation: Residual (or skip) connections add the input of a layer directly to its output. This alleviates the problem of vanishing gradients and allows the model to propagate information from earlier layers more effectively. [ \text{Output of Layer} = \text{Layer Output} + \text{Input} ]
- Faster Convergence: Both layer normalization and residual connections help accelerate the model’s training by ensuring better gradient flow and preventing the model from becoming unstable.
- Deeper Models: Residual connections make it possible to train deeper models by mitigating the problem of gradient vanishing over multiple layers.
The Transformer’s decoder has two main differences compared to the encoder:
-
Masked Self-Attention: The decoder uses masked multi-head attention to ensure that each position in the target sequence can only attend to earlier positions. This prevents the model from "cheating" by looking at future tokens during training, making it an autoregressive model.
- The mask ensures that predictions depend only on previously generated tokens.
-
Cross-Attention: The decoder also uses a second multi-head attention layer (cross-attention) that attends to the encoder’s output. This allows the decoder to focus on relevant parts of the input sequence when generating the output sequence.
- Cross-Attention makes sure the decoder has full access to the context of the input sequence, which is vital for tasks like machine translation.
The final output of the decoder is passed through a linear layer that maps the decoder output to the size of the vocabulary. The softmax function is then applied to obtain a probability distribution over all possible tokens.
- Next Word Prediction: For each position in the sequence, the model generates a probability distribution over the entire vocabulary. The token with the highest probability is selected as the output.
- Autoregressive Process: For sequence generation, this process is repeated for each position in the sequence, using the previously predicted token as input to generate the next token.
During training, especially with variable-length sequences, attention masks are used to avoid computing attention for padding tokens. This ensures the model doesn’t waste attention on irrelevant tokens.
Transformers typically use a custom learning rate schedule that increases during the early stages of training and then decreases: [ \text{lr} = d_{\text{model}}^{-0.5} \times \min(\text
{step_num}^{-0.5}, \text{step_num} \times \text{warmup_steps}^{-1.5}) ]
- This allows the model to quickly move out of local minima early on and then fine-tune with smaller steps as training progresses.
These details explain the core mechanisms that make Transformers so powerful and versatile across various tasks such as machine translation, text generation, and question answering. They contribute to the model's capacity for parallelism, long-range dependency capture, and complex relationship modeling.
Let’s break down the Transformer architecture using a concrete example of machine translation—specifically, translating the sentence “I love cats.” into French: “J’aime les chats.”
We will go step by step through the Transformer’s processes.
Source (English): "I love cats."
Target (French): "J’aime les chats."
First, the input sentence is broken down into smaller units (tokens). For simplicity, let's assume word-level tokenization.
- Source Tokenization: ["I", "love", "cats", "."]
- Target Tokenization: ["J'", "aime", "les", "chats", "."]
Each token is then converted into a fixed-dimensional vector (embedding) that captures its meaning. These are initialized randomly or come from a pre-trained model.
Example:
- "I" → [0.1, 0.2, 0.3]
- "love" → [0.4, 0.5, 0.6]
- "cats" → [0.7, 0.8, 0.9]
Since the Transformer is non-sequential (unlike RNNs), it doesn't know the order of the tokens, so it adds positional embeddings that encode each token's position in the sequence.
Example of embeddings with positional encoding added:
- "I" → [0.15, 0.25, 0.35]
- "love" → [0.44, 0.55, 0.66]
- "cats" → [0.75, 0.85, 0.95]
The encoder processes the source sentence ("I love cats.") to learn relationships between the tokens.
The key mechanism here is self-attention, which lets each word pay attention to other words in the sentence to understand their relationships.
For the token "love", the self-attention mechanism calculates its relationship with:
- "I"
- "love"
- "cats"
- "."
-
Query, Key, Value Matrices: For each word, a query, key, and value are computed. These are learned representations of each word used to determine how much each token should attend to others.
Example: For "love"
- Query vector: [0.4, 0.5, 0.6]
- Key vector: [0.5, 0.1, 0.3] (for other words)
- Value vector: [0.6, 0.2, 0.5]
-
Attention Score: The attention score between "love" and "I" (or any other word) is computed using the dot product of the query (for "love") and key (for "I"). The score is then normalized (using softmax) and used to scale the value vector of "I".
Example: [ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q \cdot K}{\sqrt{d_k}}\right) \cdot V ] The higher the attention score between two tokens, the more one word will attend to the other.
-
Multi-Head Attention: This is repeated for multiple attention heads. Each head can focus on different aspects of the relationships, such as syntactic (subject, object) or semantic (emotion, action) features.
After computing self-attention for every token, the result is passed through a feed-forward network. This network further processes each token's representation independently, applying non-linear transformations (ReLU activation) to introduce more complexity.
Once the encoder processes the full sentence "I love cats.", it produces an encoded representation. Now, the decoder uses this representation to generate the translated sentence.
- Encoder Output (Representation):
- [Encoded vector for "I"]
- [Encoded vector for "love"]
- [Encoded vector for "cats"]
The decoder works in an autoregressive manner, generating the translated sentence word by word. It takes in the target sentence as input, but with masked self-attention so that the model only attends to the previously generated tokens.
- At the first time step, the model generates "J'".
- At the second time step, the model generates "aime", but only attends to "J'" (and not "aime" itself).
- At the third time step, the model generates "les", attending to "J'" and "aime".
Masked self-attention ensures that the model doesn’t “cheat” by looking ahead to future tokens that it hasn’t generated yet.
In addition to masked self-attention, the decoder also has an encoder-decoder attention layer, where it attends to the full encoded representation of the input sequence.
Example: When generating the token "chats", the decoder looks at:
- The words it has already generated in French: "J'aime les"
- The encoded English words: "I", "love", "cats" (attending more to "cats" when generating "chats")
The cross-attention layer helps the decoder align tokens from the source and target sequences.
Finally, the decoder outputs a vector representing the probability distribution over the target vocabulary. The word with the highest probability is chosen as the next word in the translation.
- Decoder output after "J'aime les" → [0.1, 0.3, 0.8, 0.05, ...] (for "chats")
- The word "chats" has the highest probability, so it’s selected as the next word.
This process repeats until the model generates the entire target sentence, "J’aime les chats."
The Transformer model is trained using teacher forcing, where at each step the actual target word is provided as input to the decoder instead of the previously predicted word. The loss is computed using the cross-entropy between the predicted and actual target sequences, and backpropagation is used to update the model weights.
- The input sentence "I love cats." is tokenized and embedded.
- The encoder uses self-attention to relate each word in the input sentence to the others.
- The decoder uses masked self-attention to generate the French sentence step by step, attending to previously generated words.
- The decoder also uses cross-attention to focus on relevant parts of the encoded input sentence.
- The model continues generating words until the entire sentence is produced.
- Parallelization: Unlike RNNs, Transformers can process entire sequences in parallel, speeding up training and inference.
- Long-Range Dependencies: The attention mechanism allows every token to attend to every other token, making it easier to capture long-range dependencies.
- Scalability: Transformers scale well to large datasets and longer sequences, making them suitable for a wide range of tasks (translation, text generation, summarization, etc.).
This example illustrates how the Transformer efficiently handles complex tasks like machine translation through its attention mechanisms and parallel processing capabilities.