{kind=link}
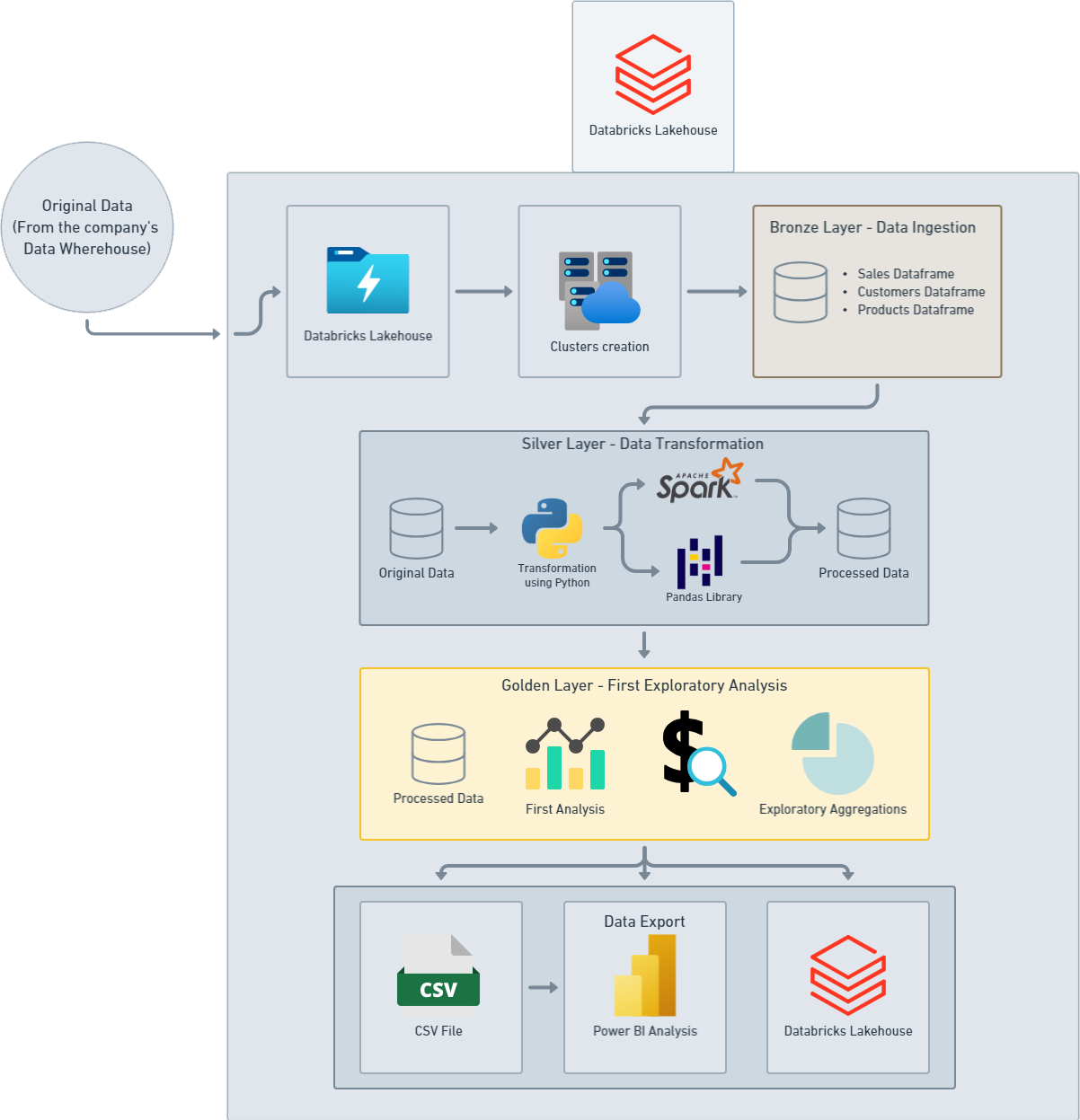
This repository contains a comprehensive data engineering and analytics project focused on optical sales data. The project integrates data processing, transformation, and analysis using Databricks and Power BI, providing valuable insights into sales performance.
Databricks Lakehouse: Used for data ingestion, transformation, and exploratory analysis. Power BI: Employed for creating visual reports and dashboards to facilitate data-driven decision-making. Data Pipeline: A robust ETL process implemented with PySpark, ensuring data is clean, processed, and ready for analysis.
Data Ingestion: Importing raw sales, customer, and product data into Databricks. Data Transformation: Cleaning and processing data using PySpark and Pandas to create structured datasets. Exploratory Analysis: Initial data exploration within Databricks to identify key trends and patterns. Data Visualization: Comprehensive dashboards created in Power BI to visualize sales metrics, customer insights, and product performance. End-to-End Workflow: A complete pipeline from data ingestion to visualization, providing a holistic view of the business.
- Databricks
- PySpark
- Pandas
- Power BI
- CSV for data export/import
Streamline data processing and analysis for optical sales data. Provide actionable insights for stakeholders through clear and interactive visualizations. Demonstrate the integration of Databricks and Power BI in a real-world data engineering and analytics project.