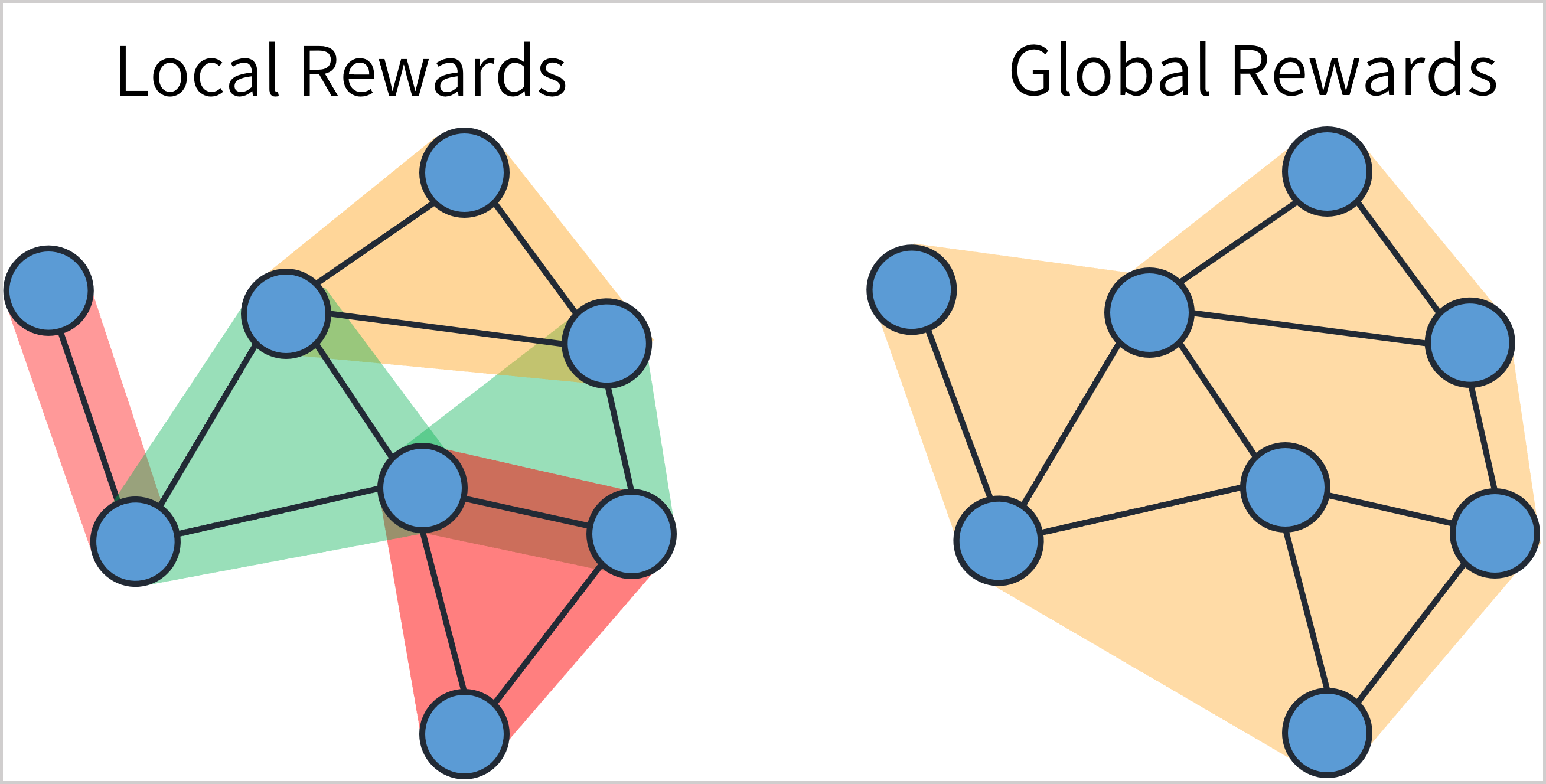
This repository offers a scalable value decomposition method for the cooperative CTDE setting. Our method leverages local agent rewards for improving credit assignment, whilst maintaining a cooperative objective. In addition, we provide a direct decomposition method for finding local rewards when only a global reward is provided.
Our code is built upon the pymarl repository, although the code has been significantly modified for our setting.
The code is written in Python 3, with extensive use of the Pytorch library. Installation of the relevant python packages can be done by running
cd LOMAQ/
pip install -r requirements.txtOur method is dependent on hyper-parameters that can be found under src/config/. There are 4 different
types of configuration files
-
Default Configuration - found under
src/config/default.yaml. This file depicts the default parameters for all runs. Is overriden by any other configuration file. An example of a parameter here could bebatch_size, which is generally similar for all algorithms. -
Enviroment Configuration - found under
src/config/envs/<env-name>.yaml. This file depicts the parameters that are relevant for running the enviroment. An example of this isnum_agents. -
Algorithm Configuration - found under
src/config/algs/<alg-name>.yaml. This file depicts the parameters for the current algorithm. An example of this islearning_rate. -
Test Configuration - found under
src/config/test/test<test-num>.yaml. This file depicts information for a specific test. For instance, if one wishes to run a certain algorithm against different num_agents, this should be done using a seperate test file. Each test file depicts a series of runs. Seesrc/config/test/example_test.yamlfor an example of this. This config file overrides all other configurations.
We offer a variety of different ways for running the code for different purposes. All the mentioned
bash files can be found under scripts/. Note that running the code should always be done from the
main LOMAQ/ directory, and NOT from src/ or scripts/.
We also note that we provide 2
versions for every script: <script-name>-local.sh and <script-name>-server.sh. The server
version doesn't attempt to display a visualization of the environment, and instead uploads data to
WANDB.
Note that all examples demonstrate the "local" version, but can be easily changed into the "server"
option by substitution.
The simplest way to run the code is using src/main.py, which expects exactly 2 arguments - Am environment
name, and an algorithm name. The code assumes that these names correspond to 2 configuration files that depict
the relevant parameters. For instance:
python3 src/main.py --env-name=lomaq --alg-name=multi_particleAn alternative is running scripts/run_local.sh. By default, the script will run src/main.py with LOMAQ and the
multi_particle environment.
If one wishes to run a test from src/test/, this can be done using src/multi_main.py. The python script will
read the relevant test file, and initiate the runs that it depicts. The runs are run in parallel. For example,
if one wishes to run test number 53:
python3 src/multi_main.py --test-num=53If one wishes to run the same test multiple times with different seeds, this can be done using another argument
iteration_num (default is 0). The corresponding seed will be iteration_num + test_num, and can be done using:
python3 src/multi_main.py --test-num=53 --iteration-num=10If one wishes to only run a single run from a test, this can be done using src/single_main.py by specifying the
run_num argument:
python3 src/single_main.py --test-num=53 --iteration-num=10 --run-num=2The following file diagram depicts an outline of the code, with explanations regarding key modules in our code.
LOMAQ
└───documentation (includes some figures from the paper)
└───results (where local results are stored)
└───scripts (runnable scripts that are described above)
└───src (main code folder)
│ └───config (configuration files described above)
│ └───envs (used environments, includes multi_cart (Coupled Multi Cart Pole), multi_particle (Bounded Cooperative Navigation), payoff_matrix....
│ └───reward_decomposition (includes the full implementation for our RD method)
│ └───learners (the main learning loop, bellman updates)
│ │ │ q_learner (a modified q_learner that supports local rewards and rweard decomposition)
│ │ │ ...
│ └───modules (NN module specifications)
│ │ └───mixers (Mixing layers specifications)
│ │ │ │ gcn (a GCN implementation for LOMAQ, occasionly used)
│ │ │ │ lomaq.py (The main specification of our mixing networks)
│ │ │ │ ...
│ └───controllers (controls a set of agent utlity networks)
│ │ │ hetro_controller.py (an agent controller that doesn't implement parameter sharing)
│ │ │ ...
│ └───components (general components for LOMAQ)
│ │ │ locality_graph.py (A module that efficiently represents the graph of agents)
│ │ │ ...
│ │ main.py (for running a certain env-alg pair with default parameters)
│ │ multi_main.py (for running a certain test with multiple runs)
│ │ single_main.py (for running arun within a test)
│ │ offline_plot.py (for plotting results)
│ │ ...
│ README.md (you are here)
│ requirements.txt (all the necessary packages for running the code)
│ ...