Implementation of a simple gradient descent problem in Python, Numpy, JAX, C++ (binding with Python) and Mojo. My goal here is to make a fair evaluation on the out-of-the-box, raw performance of a tech stack choice. Neither of the implementations is optimal. But what I hope to show is what execution speeds to expect out of the box, the complexity of each implementation and to pinpoint which ones have the possibility of squeezing out every bit of performance the hardware has to offer.
 |
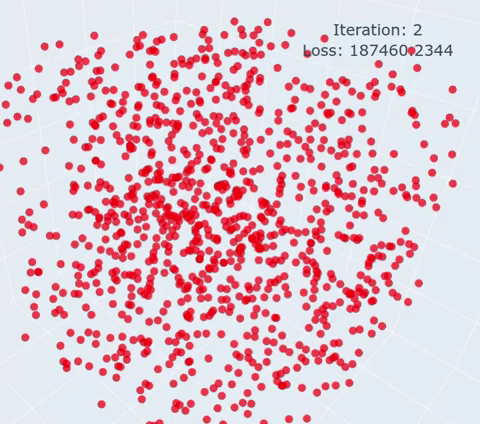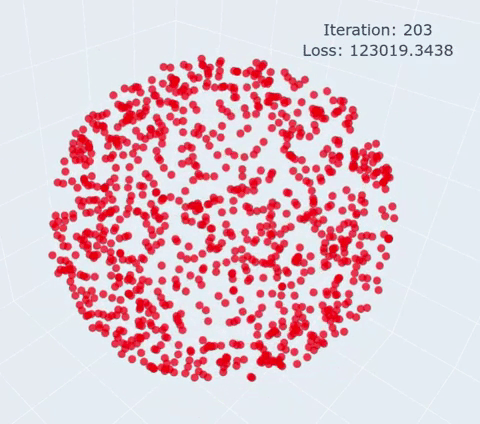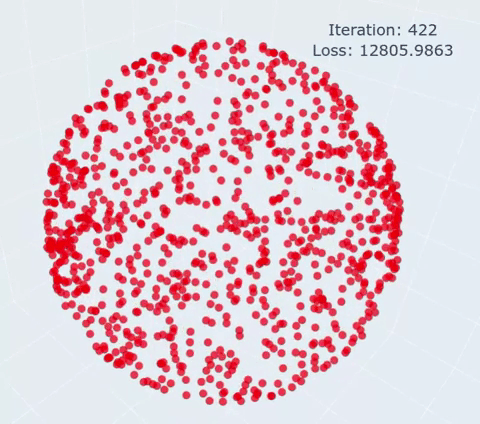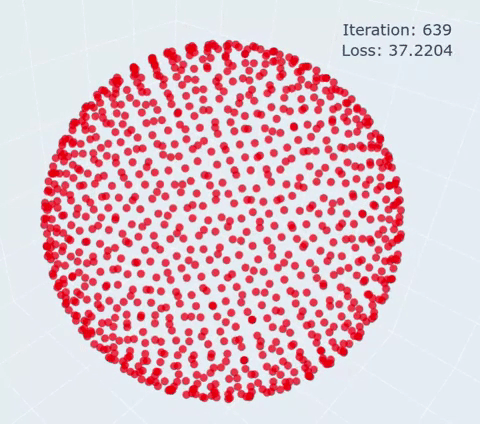 |
 |
 |
System Requirements:
Mojo v0.4.0
Linux: Ubuntu 22.04
x86_64 architecture
Project setup: by running make setup
Create virtual environment:
python3 -m venv .venv
Upgrade pip:. .venv/bin/activate && python -m pip install --upgrade pip
Install project requirements:. .venv/bin/activate && pip install -r python-requirements.txt
All implementation can be executed by running the main.mojo file: make mo
. .venv/bin/activate && mojo run main.mojo
- Runs the Mojo implementation
- Python interop to main.py > "benchmarks" function
- Benchmarks Python/Numpy/JAX/C++(binding)
- Python interop to all visualizations
From main.mojo:
The shape, optimization target can be adapted by changing the points variable. You can choose either:
- A circle of N points (fixed dim = 2)
- A sphere of N points (fixed dim = 3)
- A flame shape (fixed N points)
- A modular shape (fixed N points)
The optimization parameters can be changed:
- dim: Dimensionality of the gradient descent algorithm (visualization support only dim = 2 & 3)
- lr: Learning rate
- niter: Number of iterations (no early stopping is implemented)
- plot: (bool) Generat plots and animations
- run_python: (bool) Run python interop to main.py > benchmarks
Python based implementation can be executed from main.py: make py This includes: Python/Numpy/Jax and C++ (binding)
. .venv/bin/activate && python main.py
Mojo only can executed by changing run_python to False in the main.mojo file and running: make py
. .venv/bin/activate && mojo run main.mojo
To change the parellelization of the gradient calculations in Mojo: Identify the number of logical CPUs on a Linux system: nproc And configure the number of workers in ./mojo/gradient_descent.mojo
Switching between default and parallel mode can be done by changing how to compute the gradient in gradient_descent function of ./mojo/gradient_descent.mojo
compute_gradient[dtype](grad, X, D)
compute_gradient_parallel[dtype, nelts](grad, X, D)
Both default and parallel (20 workers) C++ binaries are included in the ./cpp/bin and ./cpp/lib folder. So you don't have to run this again if you just want to run the code. But you can build the binary & shared object yourself:
First unzip the 3rd party eigen-3.4.0.zip library in the ./cpp/include/ folder and compile the C++ code by running make cpp-build (g++ build tools installation required).
To change the parellelization of the gradient calculations: Identify the number of logical CPUs on a Linux system: nproc And configure the number of workers in ./cpp/src/gradient_descent.cpp. After building the sharded object (make cpp-build). Configure the exact gradient_descent.so. file you just compiled for the Python binding in ./cpp/binding.py
libc = CDLL("cpp/build/lib/gradient_descent_p20.so")