一个 HEXO 插件,实现了用 HEXO 语法来在博客中插入一个豆瓣读书卡片的功能,现在实现了读书和电影两个板块



首先请安装插件
$ npm install hexo-douban-card --save然后使用以下语法
{% douban movie 24745500 %}
{% douban book 30376420 %}
{% douban music 35099703 %}-
第一项
douban代表插件名 -
第二项可选:
movie,book,music -
第三项请填入对应的
id例如:

填写subject后面的那串数字就好

https://www.tanknee.cn/2020/07/08/Hexo%E8%B1%86%E7%93%A3%E6%96%87%E7%AB%A0%E6%8F%92%E4%BB%B6/
需要在 _config.yml 中配置 doubanCard,但这并不是必选项,如果你遇到了某些需要登录的豆瓣网址,那么请填写 cookie,如果你遇到图片代理失效的问题,请自行替换 imgProxy。未经验证的代理网址可以参考这个 issue:图像加速服务weserv地址被reset了,不能显示图片
doubanCard:
enable: true
cookie: ABCDEFGHIJKLMNOPQRSTUVWXYZ
imgProxy: https://images.weserv.nl/?url=
添加了全局开关,现在可以直接在配置中开启或者关闭 douban-card,如果你想要关闭,请将 enable 设置为 false 现已取消这个总开关。另外,本版本中卡片的样式改为一次性插入到页面head中,不再重复插入。
添加了一个背景懒加载属性,请配合https://github.com/Troy-Yang/hexo-lazyload-image使用。
修复了构造器的问题,并将自定义图片代理的功能放入用户配置中,现在,你可以使用如下配置:
doubanCard:
cookie: ABCDEFGHIJKLMNOPQRSTUVWXYZ
imgProxy: https://images.weserv.nl/?url=
修复了缓存失效的问题,上一个版本由于对象键大小写的问题导致缓存无法正常工作,所以还是会有不断访问豆瓣网站的问题,该版本修复了这个问题。
同时,本版本添加了部分日志,方便出错之后的调试工作。
添加了一个内容缓存文件,每次生成卡片的时候会优先从缓存文件中查找,若是找到了则直接使用,若没有则重新生成,这样做减少了对豆瓣网页的访问,降低了被当做机器人的概率。
缓存文件名字为 DoubanCard.json,若爬取到的数据有误,可以直接把这个文件删了,或者手动修改这个文件。
使用自己编写的渲染器替换 nunjucks 渲染器,理论上是不会出现 #3 那个报错了,如果还出错请清空缓存,重新安装 hexo-douban-card 试试,还不行的话我也无能为力了。
新增电影、书籍的阅读状态爬取,前提是你配置了 cookie,详情请参照 2020/09/17 更新的更新内容。

修复1.2.1中不使用cookie时出现报错无法编译的问题,该问题较为严重,希望1.2.1及以下版本的用户尽快更新!!!!
当前版本(1.2.0)中修复了部分电影,音乐无法正常爬取的问题,例如电影《天浴》,id:1302836。
无法爬取的原因在于电影需要登陆才可以正常爬取内容,因此当前版本添加了新的配置。如果你遇到了上述问题,请到hexo根目录下的_config.yml文件中,添加一项:
doubanCard:
cookie: xxxxx然后将xxxx替换成你的cookie,cookie的获取办法是:
-
打开豆瓣网页,登陆账号
-
随便点击一个页面,然后打开控制台
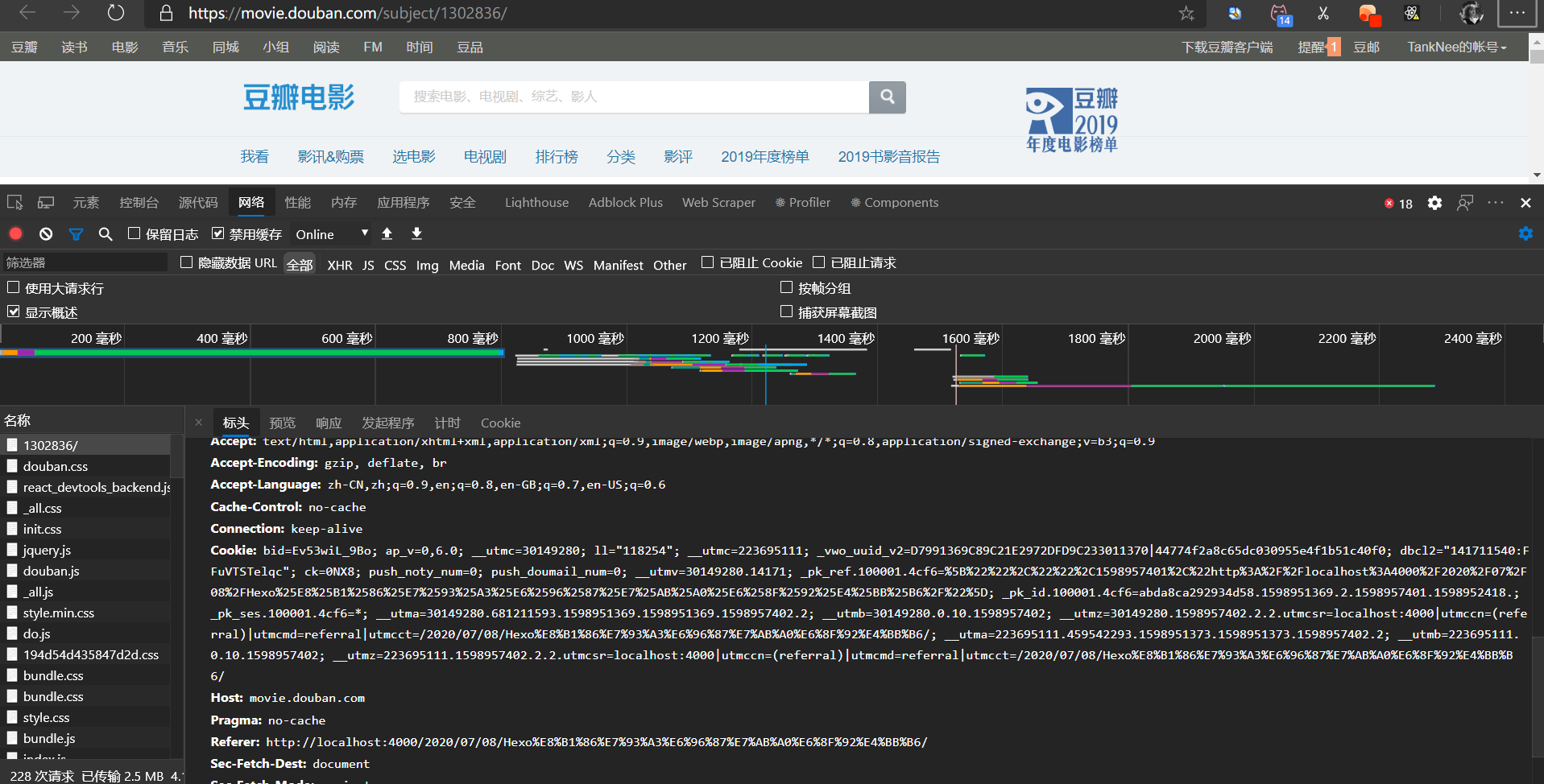
- 将Cookie那一项的所有内容复制出来,放在配置文件中即可
某些特定的电影需要登陆才可以查看到对应的信息,1.1.8-c版本不做修改时会报生成错误,暂时只做冷处理,即显示一个提示图片,在下一个版本1.2.0中会做更优化的处理!
