{kind=link}
{kind=link}
![]()
O motivo principal pelo qual resolvi desenvolver essa fila de processos foi o aprendizado das estruturas e APIs do Erlang/OTP utilizando o Elixir. Provalvemente existem muitas outras filas de processamento de serviços em segundo plano espalhadas por ai bem mais eficientes do que esta que se encontra aqui. No entanto acredito que para quem está começando é demasiado interessante ter acesso a estruturas mais simples, tanto do ponto de vista de lógica de programação quanto da perspectiva operacional do OTP. Por isso optei por fazer desde a base um software para execução de processos de forma a conseguir explicar as tomadas de decisão e, eventualmente, ir corrigindo esse caminho conforme a comunidade demonstre que uma ou outra opção é melhor, através de pull requests ou mesmo issues abertas. Tenho certeza que será de grande ajuda para iniciantes e para mim o que for tratado aqui.
Abaixo um diagrama completo do fluxo de dados e possibilidades de acontecimentos do sistema.
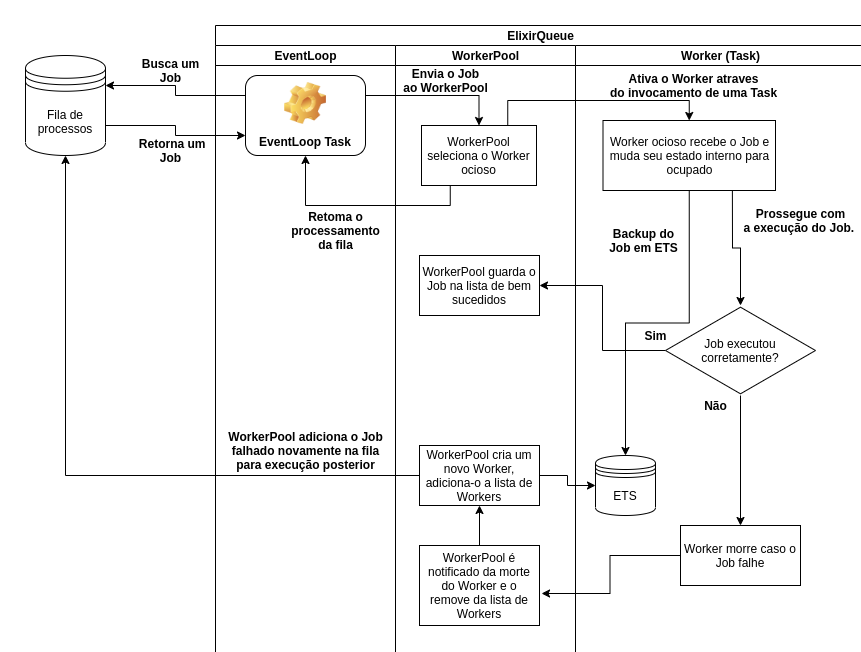
A Applicationdesta fila de processos supervisiona os processos que irão criar/consumir a fila. Eis os filhos da ElixirQueue.Supervisor:
children = [
{ElixirQueue.Queue, name: ElixirQueue.Queue},
{DynamicSupervisor, name: ElixirQueue.WorkerSupervisor, strategy: :one_for_one},
{ElixirQueue.WorkerPool, name: ElixirQueue.WorkerPool},
{ElixirQueue.EventLoop, []}
]Os filhos, de cima para baixo, representam as seguintes estruturas: ElixirQueue.Queue é o GenServer que guarda o estado da fila numa tupla; ElixirQueue.WorkerSupervisoré o DynamicSupervisor dos workers adicionados dinamicamente sempre igual ou menor que o número de schedulers onlines; ElixirQueue.WorkerPool, o processo responsável por guardar os pids dos workers e os jobs executados, quer seja com sucesso ou falha; e por último o ElixirQueue.EventLoop que é a Task que "escuta" as mudanças na ElixirQueue.Queue (ou seja, na fila de processos) e retira jobs para serem executados. O funcionamento específico de cada módulo eu explicarei conforme for me parecendo útil.
Eis aqui o processo que controla a retirada de elementos da fila. Um event loop por padrão é uma função que executa numa iteração/recursão pseudo infinita, uma vez que não existe a intenção de se quebrar o loop. A cada ciclo o loop busca jobs adicionados na fila - ou seja, de certa forma o ElixirQueue.EventLoop "escuta" as alterações que ocorreram na fila e reage a partir desses eventos - os direciona ao ElixirQueue.WorkerPool para serem executados. Este módulo assume o behaviour de Task e sua única função (event_loop/0) não retorna nenhum valor tendo em vista que é um loop eterno: ela busca da fila algum elemento e pode receber ou uma tupla {:ok, job} com a a tarefa a ser realizada ou uma tupla {:error, :empty} para caso a fila esteja vazia; no primeiro caso ele envia para o ElixirQueue.WorkerPool a tarefa e executa event_loop/0 novamente; no segundo caso ele apenas executa a própria função recursivamente, continuando o loop até encontrar algum evento relevante (inserção de elemento na fila).
O módulo ElixirQueue.Queue guarda o coração do sistema. Aqui os jobs são enfileirados para serem consumidos mais tarde pelos workers. É um GenServer sob a supervisão da ElixirQueue.Application, que guarda uma tupla como estado e nessa tupla estão guardados os jobs - para entender o porquê eu preferi por uma tupla ao invés de uma lista encadeada (List), mais abaixo em Análise de Desempenho está explicado. A Queue é uma estrutura bem simples, com funções triviais que basicamente limpam, buscam o primeiro elemento da fila para ser executado e insere um elemento ao fim da fila, de forma a ser executado mais tarde, conforme inserção.
Aqui está o módulo capaz de se comunicar tanto com a fila quanto com os workers. Quando a Application é iniciada e os processos supervisionados, um dos eventos que ocorre é justamente a inciação dos workers sob a supervisão do ElixirQueue.WorkerSupervisor, um DynamicSupervisor, e os seus respectivos PIDs são adicionados ao estado do ElixirQueue.WorkerPool. Além disso, cada worker iniciado dentro do escopo do WorkerPool é também supervisionado por esse, o motivo disso será abordado a frente.
Quando o WorkerPool recebe o pedido para executar um job ele procura por algum de seus workers PIDs que esteja no estado ocioso, ou seja, sem nenhum job sendo executado no momento. Então, para cada job recebido pelo WorkerPool através de seu perform/1, este vincula o job a um worker PID, que passa para o estado de ocupado. Quando o worker termina a execução, limpa seu estado e então fica ocioso, esperando por outro job. No caso, isso que aqui chamamos de worker nada mais é do que um Agent que guarda em seu estado qual job está sendo executado vinculado àquele PID; ele serve de lastro limitante uma vez que o WorkerPool incia uma nova Task para cada job. Imagine o cenário onde não tivessemos workers para limitar a quantidade de jobs sendo executados concorrentemente: o nosso EventLoop inciaria Tasks a bel prazer, podendo causar grande problemas como estouro de memória caso a Queue recebesse uma grande carga de jobs de uma só vez.
Neste módulo temos os atores responsáveis por tomar os jobs e executá-los. Porém o processo é um pouco mais do que apenas a execução do job; na verdade funciona da seguinte forma:
- O
Workerrecebe um pedido para performar um certo job, adiciona-o ao seu estado interno (estado interno doAgentdoPIDpassado) e também a uma tabela:etsde backup; - Depois segue para a execução do job em si. É extremamente necessário lembrarmos que a execução ocorre no escopo da
Taskinvocada peloWorkerPool, e não no escopo do processo do Agent. Foi uma opção de implementação, poderia ser feito de outras diversas formas porém escolhi assim pela simplicidade que acredito ter ficado o código. - Finalmente, com o job finalizado, o
Workervolta seu estado interno para ocioso e exclui o backup deste worker da tabela:ets. - Ademais, com a função do
Workertendo sido cumprida, a trilha de execução volta para aTaskinvocada peloWorkerPoole apenas completa a corrida inserindo o job na lista de jobs bem sucedidos.
Como ficou claro na explicação, não existe nenhum ponto da trilha de execução dos jobs onde nos preocupamos com a questão: o que acontece se uma função mal feita for passada como job para a fila de execução, ou até mesmo!, o que ocorre caso algum processo Agent Worker simplesmente corromper a memória e morrer? Pois bem, na intenção de escrever o código da forma mais perene possível, talvez o mais Elixir like o possível, o que foi feito é justamente adicionar garantias de que se os processos falharem (e falharão!) o sistema consiga reagir de tal forma que mitigue os erros.
Na ocasião da falha de algum worker que acarrete em sua morte via EXIT signal o WorkerPool, que monitora todos os seus workers via Process.monitor, repõe este worker morto por outro, adicionando-o ao WorkerSupervisor. Com isso também remove o PID do Worker morto da lista de PIDs e adiciona o novo. Porém não para por ai: o WorkerPool checa por algum backup criado do Worker morto e, encontrando, repõe o job na fila com seu valor de attempt_retry adicionado de um. O WorkerPool sempre irá adicionar o job novamente na fila uma quantidade pré-determinada de vezes, definida no arquivo mix.exs, no environment da application.
Para fila de processos funcionar normalmente eu preciso apenas de inserir no final e retirar do início. Claramente isso pode ser feito tanto com List quanto com Tuple, e acabei optando por tuple pelo simples fato de ser mais rápido. Direto do output do Benchee rodando mix run benchmark.exs na raiz do projeto:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Number of Available Cores: 8
Available memory: 15.56 GB
Elixir 1.10.2
Erlang 22.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking Insert element at end of linked list...
Benchmarking Insert element at end of tuple...
Name ips average deviation median 99th %
Insert element at end of tuple 4.89 K 204.42 μs ±72.94% 119.45 μs 571.85 μs
Insert element at end of linked list 1.24 K 808.27 μs ±54.67% 573.68 μs 1896.52 μs
Comparison:
Insert element at end of tuple 4.89 K
Insert element at end of linked list 1.24 K - 3.95x slower +603.85 μs
Preparei um teste de estresse para a aplicação que enfileira 1000 fake jobs, cada um ordenando uma List reversamente ordenada com 3 milhões de elementos, utilizando o Enum.sort/1 (de acordo com a documentação, o algoritmo é um merge sort). Para executá-lo basta entrar no terminal via iex -S mix e rodar ElixirQueue.Fake.populate; a execução leva alguns minutos (e pelo menos uns 2gb de RAM), e depois você pode conferir os resultados com ElixirQueue.Fake.spec.
Para ver a fila de processos funcionando basta executar iex -S mix na raiz do projeto e utilizar os comandos abaixo. A menos que você esteja em modo test, você verá logs de informação sobre a execução do job.
É possível construir a struct do job manualmente e passá-lo para a fila.
iex> job = %ElixirQueue.Job{mod: Enum, func: :reverse, args: [[1,2,3,4,5]]}
iex> ElixirQueue.Queue.perform_later(job)
:okAlém disso também podemos passar manualmente os valores do módulo, função e argumentos para perform_later/3.
iex> ElixirQueue.Queue.perform_later(Enum, :reverse, [[1,2,3,4,5]])
:ok