We wanted to solve a communication challenge that hearing-impaired individuals have to face daily. The World Health Organization is predicting that more than 600 million people will lose their hearing by 2030. Meanwhile, there are over 400 million individuals suffer from hearing loss currently. As such with we wanted to be able to provide live support for these individuals so they can continue to have their independence. We decided to tackle this by harnessing the power of machine learning and computer vision so we can come up with a solution that can provide reliable results and to be able to scale easily.
Hand Speak allows for live video translation of ASL alphabet letters and custom hand gestures. This allows for it to be a viable translation tool for individuals with hearing impairment so they can face less challenges when communicating with others.
Code was written in python. Model was built and trained using TensorFlow and Keras for the image processing. We used a pre-trained model VGG16 as the input to our custom CNN for it's experimental success in categorical classifications. The model used a unique dataset with over 10,000 images that we created from scratch, with no augmentation. This allowed us to have a higher accuracy by being more stringent with the data validation and allowed for custom categories for hand gesture recognition. Finally openCV was used for video and image detection to be able to isolate the object of interest (in our case an individuals hand).
In the beginning we were attempted to use a few popular datasets for alphabet and digit classification, and even though we had very high accuracy during training the results did not translate outside of it. After attempting to use other datasets, combining multiple ones, and performing data augmentation with little translation success we decided to build our own dataset. One of the main difficulties we saw was that the variation was low in most popular large datasets we could find, and combined with unusual backgrounds to be found made them hard to generalize.
So we tried to solve this by adding depth, lighting, and image centring variations alongside a more neutral background so image processing was easier with the hope that it would be better able to generalize. Which is fortunately exactly what we saw, our model had greater than 99% accuracy and we were able to translate and generalize this to live images as well. This ended up being a fortunate coincidence as this also allowed us to add support for custom hand gestures that we may not have been able to reliable do before.
We were very happy that we were able to train our model to have a greater than 99% accuracy using a dataset that we had built ourselves considering this was our first time doing data creation and validation at this scale.
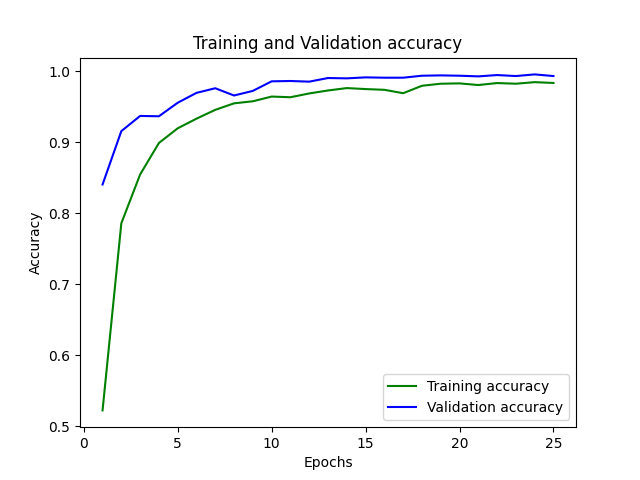
Categorization is difficult, and so is the ability to recognize complex hand movements. As we added more categories and gestures we needed more refinement on our hyper parameters and an equal amount of hair pulling for our model to be able to distinguish between them. Things such as having greater layers and more filters so we are able to better extract the subtle feature differences that are required to distinguish between letters such as 'm' and 'n' in the ASL alphabet.
- Develop a mobile application so it can be used in any environment
- Integrate it with voice assistants such as Alexa and Siri so it can not only provide wake features but voice to text would be automated for seamless conversation both ways
- Add gesture support for different dialects, and to be able to parse more complicated sequences and combinations of gestures