
fastdup by Visual-Layer is an unsupervised powerful free tool designed to rapidly extract valuable insights from your image & video datasets. Assisting you to increase your dataset quality and reduce your data operations costs at an unparalleled scale.
From the authors of XGBoost, Apache TVM & Turi Create.
Danny Bickson, Carlos Guestrin & Amir Alush
Large Image Datasets Today are a Mess Blog | Processing LAION400m Video
- Clean & simple API: The new API is simpler to use
- Native Windows support: Windows now has first-class, full feature support in fastdup
- Amazing documentation: New and imporved fasdtdup documentation
- Sleek galleries: New and improved galleries to get a better view of your data
- Extensive labels support : Improved support for handling image and bounding box labels
- Additional image formats support: Apple’s HEIC+HEIF, 16 bit grayscale TIFF
- Support for Python3.10
- Fully backcompatible to old API

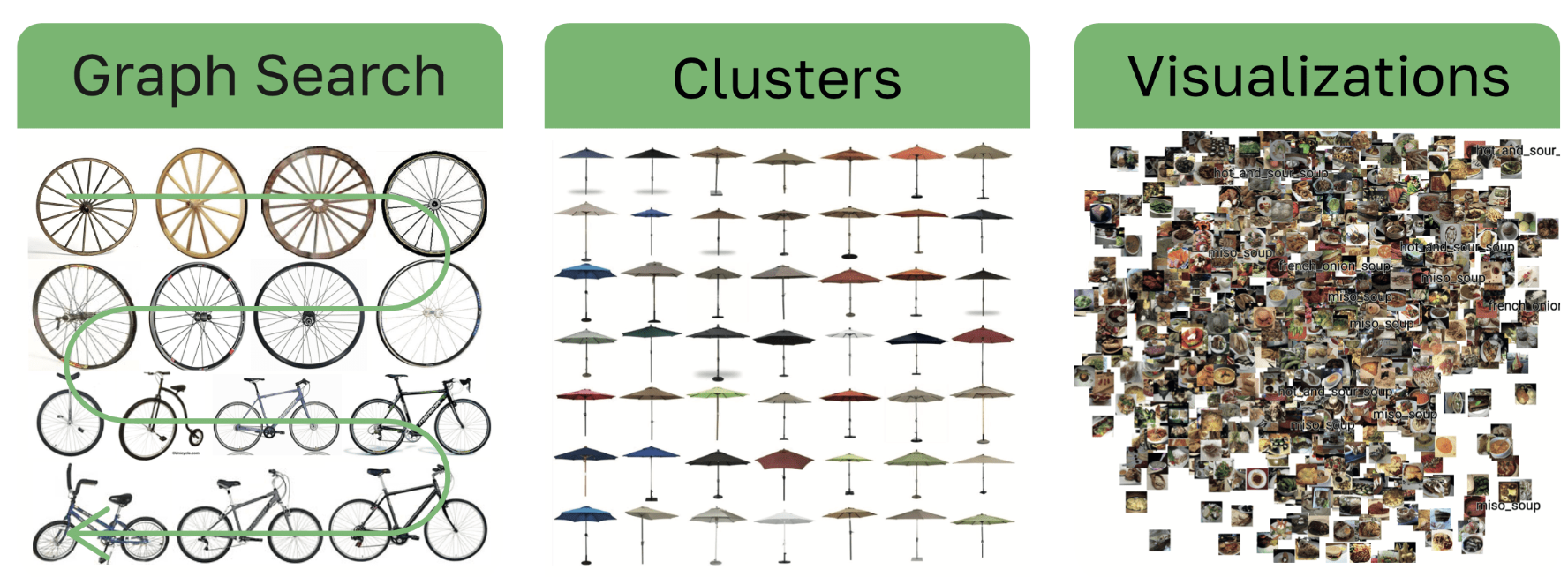
- Quality: fastdup can assist you in reaching a high quality dataset by finding and removing anomalies and outliers from your datasets. Finding duplicate and near duplicate of images (&videos) and finding clusters of similarity at a large scale!
- Cost : fastdup can also help you in reducing your data operations costs by facilitating the intelligent sampling of high-quality or novel datasets prior to labeling, as well as support the quality assessment of labeled data.
- Scale: fastdup graph engine is written in C++ and is highly efficient and works in an incredible scale! Running locally on a CPU only machine and can handle up to 400M images on a single CPU machine!

# upgrade pip to its latest version
pip install -U pip
# install fastdup
pip install fastdup
# Alternatively, use explicit python version (XX)
python3.XX -m pip install fastdup - Supported Python: 3.7, 3.8, 3.9, 3.10
- Supported OS: Windows 10, 11 and 2019 Server (Native), Windows WSL, Ubuntu (20.04, 18.04), Mac OSX 10+ (Intel and M1 CPUs), Amazon Linux 2, CentOS 7, RedHat 4.8.
- Full installation instructions are here
import fastdup
fd = fastdup.create(work_dir, images_dir)
fd.run(nearest_neighbors_k=5, cc_threshold=0.96)
fd.vis.duplicates_gallery() #create a visual gallery of found duplicates
fd.vis.outliers_gallery() #create a visual gallery of anomalies
fd.vis.component_gallery() #create visualiaiton of connected components
fd.vis.stats_gallery() #create visualization of images stastics (for example blur) Working on the Oxford Pet Dataset. Detecting identical pairs, similar-pairs (search) and outliers
Working on the Oxford Pet Dataset. Detecting identical pairs, similar-pairs (search) and outliers
- Quick dataset analysis
- Cleaning and preparing a dataset
- Preparing an image dataset for training
- Preparing an object dataset for training
Have a question? Use our discussion forum
Sign up at Visual Layer

- Master Data Integrity to Clean Your Computer Vision Datasets
- fastdup: A Powerful Tool to Manage, Clean & Curate Visual Data at Scale on Your CPU - For Free.
- Clean Up Your Digital Life: Simplify Your Photo Organization and Say Goodbye to Photo Clutter
Please reach us at info@visual-layer.com
Usage Tracking
We have added experimental crash report collection, using sentry.io. It does not collect user data other than anonymized IP address data, and it only logs fastdup library's own actions. We do NOT collect folder name, user name, image names, image content only aggregate performance statistics like total number of images, average runtime per image, total free memory, total free disk space, number of cores etc. Collecting fastdup crashes will help us improve stability.
The code for the data collection is found here. On MAC we use Google crashpad.
It is always possible to opt out of the experimental crash report collection via either of the following two options:
- Define an environment variable called
SENTRY_OPT_OUT - or run() with
turi_param='run_sentry=0'