CREATE TABLE [NOME DA TABELA](
[NOME DO CAMPO] [TIPO DO CAMPO] [CONSTRAINT] -- Constraint são regras que este campo precisa serguir
[NOME DO CAMPO] [TIPO DO CAMPO] [IDENTITY([VALOR QUE ELA DEVE COMEÇAR],[VALOR QUE ELA DEVE INCREMENTAR])] -- Faz com esta coluna seja atualizada com o valor definido e de quanto em quanto ela irá atualizar
[NOME DO CAMPO] [TIPO DO CAMPO] [NOT NULL] -- Faz com que esta coluna não possa ser nula, será obrigado a ter algum valor
[NOME DO CAMPO] [TIPO DO CAMPO] [UNIQUE] -- Faz com que esta coluna possua um valor único, não podendo ser contido em outras colunas de outras rows
[NOME DO CAMPO] [TIPO DO CAMPO] [PRIMARY KEY] -- Torna esta coluna um indicador para tabela em cada linha do row
[NOME DO CAMPO] [TIPO DO CAMPO] [FOREIGN KEY {REFERENCES [TABELA][COLUNA PRIMÁRIA]} -- Diz que esta coluna está referindo/linkando uma primary key de outra tabela
[NOME DO CAMPO] [TIPO DO CAMPO] [CHECK {[NOME DO CAMPO] CONDIÇÃO}] -- Serve para limitar ou checar se o valor vido pode ser inserido nesta tabela ou não
[NOME DO CAMPO] [TIPO DO CAMPO] [DEAFAULT {VALOR}] -- Define um valor padrão para a coluna quando não chegar um valor
);
ALTER TABLE [NOME DA TABELA] ADD [NOME DA COLUNA] [TIPO DA COLUNA] -- Serve para você alterar a tabela, adicionando um novo campo de um determinado tipo
ALTER TABLE [NOME DA TABELA] DROP COLUMN [NOME DA COLUNA] [TIPO DA COLUNA] -- Serve para você alterar a tabela, removendo um novo campo de um determinado tipo
ALTER TABLE [NOME DA TABELA] DROP COLUMN [NOME DA COLUNA] [TIPO DA COLUNA] -- Serve para você alterar a tabela, removendo um novo campo de um determinado tipo
ALTER TABLE [NOME DA TABELA] MODIFY COLUMN [NOME DA COLUNA] [TIPO DA COLUNA] -- Serve para você alterar a tabela, alterando o tipo de um determinado campo
INSERT INTO [NOME DA TABELA] ([CAMPOS]) VALUES ([DADOS]) -- Podemos especificar os campos onde queremos inserir algum dado
INSERT INTO [NOME DA TABELA] VALUES ([DADOS]) -- Podemos não espeficar os campos, inserindo dados de acordo com o que passamos, precisam estar em ordem
INSERT INTO [NOME DA TABELA] VALUES ([SUBSELECT]) -- Podemos inserir a partir de um subselect trazendo dados de uma ou mais tabelas
UPDATE [TABELA] SET [COLUNA 1] = [VALOR] WHERE [CONDIÇÃO] -- Realiza uma atualização na tabela, no campo indicado caso haja uma condição
DELETE FROM [TABELA] WHERE [CONDIÇÃO] -- Remove dados da tabela quando a condição determinada for verdadeira
SELECT * FROM [TABELA] -- Feito para selecionar todos os dados da tabela
SELECT [CAMPOS] FROM [TABELA] -- Feito para selecionar dados especificos da tabela
SELECT [CAMPOS] FROM [TABELA] WHERE [CONDIÇÃO] -- Feito para selecionar dados da tabela que obedeçam certas condições
SELECT [CAMPOS] FROM [TABELA] WHERE [CONDIÇÃO (SUBSELECT)] -- Podemos realizar um subselect para poder termos uma condição que depende de um determinado dado
SELECT [CAMPOS], [FUNÇÕES DE AGRUPAMENTO] FROM [TABELA] WHERE [CONDIÇÃO] GROUP BY [CAMPOS SEM FUNÇÃO DE AGRUPAMENTO] -- Podemos utilizar as funções de agrupamento para realizar um select com algum tipo de retorno necessário
SELECT TOP [QUANTIDADE] FROM [TABELA] -- Feito para retornar uma quantidade espeficicada, sendo 1 ou qualquer outro inteiro
SELECT DISTINCT [CAMPO] FROM [TABELA] -- Feito para retornar valores distintos aos requeridos, para que não haja repetição
SELECT * FROM [TABELA] WHERE [CAMPO 1] >= [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser MAIOR OU IGUAL ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] <= [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser MENOR OU IGUAL ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] <> [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser DIFERENTE ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] > [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser MAIOR ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] < [CAMPO 2] -- Trás dados que obedecerem a condição, campo 1 precisa ser MAIOR ao campo 2
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] AND [CAMPO 3] > [CAMPO 4] -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2 E campo 3 precisa ser MAIOR que o campo 4
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] OR [CAMPO 3] < [CAMPO 4] -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2 OU campo 3 precisa ser MAIOR que o campo 4
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] LIKE [CAMPO 3] -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2 OU campo 3 precisa ser COMO o campo 4
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] LIKE %[CAMPO 3] -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2 OU campo 3 precisa terminar como o campo 4
SELECT * FROM [TABELA] WHERE [CAMPO 1] = [CAMPO 2] LIKE [CAMPO 3]% -- Trás dados que obedecerem a condição, campo 1 precisa ser IGUAL ao campo 2 OU campo 3 precisa começar como o campo 4
SELECT * FROM [TABELA] WHERE [CAMPO 1] IN (1, 2, 3 , 4) -- -- Trás dados que obedecerem a condição, campo 1 precisa ESTAR NOS dados entre pareteses
SELECT * FROM [TABELA] WHERE [CAMPO 1] BETWEEN [NUMERO 1] AND [NUMERO
-- Trás dados que obedecerem a condição, campo 1 precisa ESTAR ENTRE o número 1 e o número 2
SELECT [CAMPO 1] FROM [TABELA] WHERE [CAMPO 1] EXISTS (SELECT * FROM [TABELA])
-- Trás dados que obedecerem a condição, campo 1 precisa EXISTIR neste subselect
-- Quando existe uma cláusula de agrupando sozinha no select, não é necessário agrupar os campos
SELECT SUM([CAMPO]) FROM [TABELA] -- Retorna a soma do campo númerico especificado
SELECT COUNT([CAMPO]) FROM [TABELA] -- Retorna o número de linhas da tabela que possuam a coluna especificada com algum valor
SELECT AVG([CAMPO]) FROM [TABELA] -- Retorna a média de uma coluna especificada
Quando usados em selects com mais de um campo, é necessário usar a clausula GROUP BY, que agrupara os valores das funções de acordo com os outros campos
SELECT [CAMPO 1], [CAMPO 2], SUM([CAMPO 3]) FROM [TABELA] GROUP BY [CAMPO 1], [CAMPO 2] -- Retorna a soma do campo 3 especificado agrupando com os demais campos
SELECT MIN([CAMPO]) FROM [TABELA] -- Retorna o menor valor da tabela do campo determinado
SELECT MAX ([CAMPO] FROM [TABELA] -- Retorna o maior valor da tabela do campo determinado
Joins são realizados sempre da tabela que está após o FROM, ela seria a esquerda e esquerda do join é a direita!
SELECT [CAMPO X1], [CAMPO Y1] FROM [TABELA X]
JOIN [TABELA Y] ON [CAMPO Y PRIMARY KEY] = [CAMPO X PRIMARY KEY] -- Realiza o select em duas tabelas diferentes a partir das chaves primárias de cada tabela, as quais precisam estar relacionadas
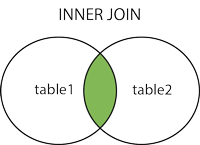
- Inner Join
SELECT [CAMPO X1], [CAMPO Y1] FROM [TABELA X]
INNER JOIN [TABELA Y] ON [CAMPO Y PRIMARY KEY] = [CAMPO X PRIMARY KEY] -- Realiza uma intercessão entre as duas tabelas, trazendo apenas valores que elas possuam em comum
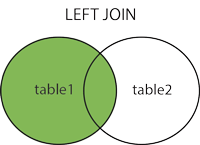
- Left Join
SELECT [CAMPO X1], [CAMPO Y1] FROM [TABELA X]
LEFT JOIN [TABELA Y] ON [CAMPO Y PRIMARY KEY] = [CAMPO X PRIMARY KEY] -- Realiza uma intercessão entre as duas tabelas, trazendo valores que elas possuam em comum e todos os valores da tabela a direita
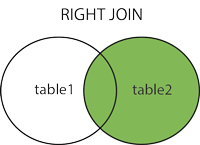
- Right Join
SELECT [CAMPO X1], [CAMPO Y1] FROM [TABELA X]
RIGHT JOIN [TABELA Y] ON [CAMPO Y PRIMARY KEY] = [CAMPO X PRIMARY KEY] -- Realiza uma intercessão entre as duas tabelas, trazendo valores que elas possuam em comum e todos os valores da esquerda
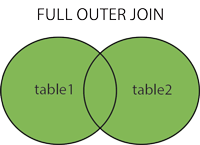
- Full Outer Join
SELECT [CAMPO X1], [CAMPO Y1] FROM [TABELA X]
FULL OUTER JOIN [TABELA Y] ON [CAMPO Y PRIMARY KEY] = [CAMPO X PRIMARY KEY] -- Realiza uma intercessão entre as duas tabelas, trazendo apenas valores que elas possuam em comum
SELECT [CAMPO] FROM [TABELA]
UNION
SELECT [CAMPO] FROM [TABELA] -- Trás todos os resultados de acordo com os dois selects, sendo dinstintos entre as duas tabelas
SELECT [CAMPO] FROM [TABELA]
UNION ALL
SELECT [CAMPO] FROM [TABELA] -- Tras todos os resultados de acordo com os dois selects, trás tudo indenpênte de ser igual ou não
SELECT [CAMPO 1], [CAMPO 2] FROM [TABELA] GROUP BY [CAMPO 1] -- trás os valores agrupando eles pelo campo 1, "traga o número de clientes de acordo com o país" SELECT [CLIENTE.NOME], [CLIENTE.PAIS] FROM [CLIENTE] GROUP BY [CLIENTE.PAIS]
SELECT SUM([CAMPO 1]) FROM [TABELA] HAVING SUM([CAMPO 2]) > 0 -- Having só pode ser usado casa exista alguma função de agrupamento no select, ela pode ser usada sem group by caso não exista um campo a mais no select, caso contrário, será necessário, basicamente estamos testando se ao selecionar a soma do campo 1 se a soma dele for maior que 0
SELECT [CAMPO 1], SUM([CAMPO 2]) FROM [TABELA] GROUP BY [CAMPO 1] HAVING SUM([CAMPO 2]) > 0 -- Como o having só pode ser usado quando há uma função de agregação, aqui temos 2 campos, para que o SQL seja executado com sucesso, ele terá que ser agrupado com o group by com o campo sem agregação
SELECT [CAMPO 1] FROM [TABELA] WHERE [CAMPO 1] = ANY (SELECT * FROM [TABELA] WHERE [CONDIÇÃO]) -- Trará os dados do select somente se QUALQUER valor da subconsulta atender a condição, resumindo, ao realizar o subselect ele trará alguns dados e com a comparação utilizando o any ele vai pegar esse conjunto de dados e vai comparar com [CAMPO 1] se apenas UM dos valores conincidrem, ele valida a condição
SELECT [CAMPO 1] FROM [TABELA] WHERE [CAMPO 1] = ALL (SELECT * FROM [TABELA] WHERE [CONDIÇÃO]) -- Trará os dados do select somente se QUALQUER valor da subconsulta atender a condição, resumindo, ao realizar o subselect ele trará alguns dados e com a comparação utilizando o any ele vai pegar esse conjunto de dados e vai comparar com [CAMPO 1] se apenas TODOS dos valores conincidrem, ele valida a condição
SELECT [CAMPOS] INTO [TABELA DESTINO] FROM [TABELA ORIGEM] -- Trás e insere os dados da tabela origem na tabela destino, de acordo com os campos
SELECT [CAMPOS] INT [TABELA DESTINO] IN [BANCO ONDE A TABELA DESTINO ESTÁ PRESENTE] FROM [TABELA ORIGEM] -- Trás e insere os dados da tabela origem na tabela destino, o IN indica em qual banco esta tabela destino está presente, caso ela esteja em um banco diferente
SELECT IF [CAMPO 1] = 1
(SELECT [CAMPO 1] FROM [TABELA X])
ELSE
[CAMPO 1]
FROM [TABELA] -- Basicamente possui a mesma finalidade das linguagens de programação, criar um bloco condicional para que você possa testar e arranjar alternativas para um determinado procedimento
SELECT [CAMPO 1], [ALIAS] =
CASE [CAMPO 1]
WHEN 'R' THEN 'RODA'
WHEN 'T' THEN 'TERRA'
ELSE 'NENHUM'
END,
[CAMPO 2] FROM [TABELA] -- O Case basicamente testa alguns campos para que haja uma inserção em um alias, logo ele testa as informaçoes presentes para que você possa trazer alguma informação desejada/formatada, nesse caso, "selecione o campo 1, um alias vai receber caso o campo 1 for 'R' ele receberá RODA, caso seja 'T' ele receberá TERRA"
O case pode estar contido tando em um select, como em um update, em uma cláusula having, order by como nos exemplos a baixo
SELECT [CAMPO 1], [CAMPO 2], [CAMPO 3] FROM [TABELA] ORDER BY (CASE
WHEN [CAMPO 1] = 'R' THEN [CAMPO 1]
WHEN [CAMPO 1] = 'T' THEN [CAMPO 2]
ELSE [CAMPO 3])
END) -- Aqui ele realizará uma ordenação com campo 1 caso a primeira condição for verdadeira e assim por diante
SELECT ISNULL([CAMPO 1], '0') FROM [TABELA] -- Realiza o select, com o ISNULL(), caso o valor do campo 1 for nulo, ele retorna um valor definido, como no caso, o '0' no lugar, podendo ser qualquer outro que vc passar no segundo parametro
SELECT COALESCE([CAMPO 1], '0') FROM [TABELA] -- Realiza o select, com o COALESCE(), caso o valor do campo 1 for nulo, ele retorna um valor definido, como no caso, o '0' no lugar, podendo ser qualquer outro que vc passar no segundo parametro
SELECT [CAMPO 1] + 1 FROM [TABELA] -- Retorna o valor, campo 1 MAIS 1
SELECT [CAMPO 1] * 1 FROM [TABELA] -- Retorna o valor, campo 1 VEZES 1
SELECT [CAMPO 1] - 1 FROM [TABELA] -- Retorna o valor, campo 1 MENOS 1
SELECT [CAMPO 1] / 1 FROM [TABELA] -- Retorna o valor, campo 1 DIVIDIDO 1
SELECT [CAMPO 1] % 1 FROM [TABELA] -- Retorna o valor, o RESTO DA DIVISÃO do campo 1 com 1
DECLARE @[NOME DA VARIAVEL] [TIPO DA VARIAVEL] -- Forma de se declarar uma variável exemplo "DECLARE @var_primeira VARCHAR(10)", a variável pode ser utilizada para armazenar dados vindos de um select ou simplesmente um valor que você possa definir com o comando logo a baixo
SET @[NOME DA VARIAVEL] = [VALOR DEFAULT]
CREATE TRIGGER [NOME TRIGGER] ON [TABELA] AFTER/STEAD OF [ISERT, DELETE, UPDATE] -- Assinatura, podendo adicionar este avento ao AFTER que seria após realizar as mudanças ou INSTEAD OF que seria antes de executar as mudanças no banco.
-- Podendo ser chamada nas ações de inserir, remover e atualizar, podendo realizar ações de inserções.
AS
BEGIN
[REGRA DE NEGÓCIO]
END -- Triggers servem basicamente para realizar alguma ação quando aconteça alguma alteração em determinada tabela, muito interessante em tabelas de auditoria
DECLARE [NOME DA VARIAVEL] INT = 0; -- É necessário declarar um contador para a estrutura de repetição e uma variável que irá receber os valores que o cursor está apontando
DECLARE [NOME DA VARIAVEL 2] INT = 0;
DECLARE [NOME DO CURSOR] CURSOR
FOR SELECT [COLUNA] FROM [TABELA] -- É necessário apontar para qual tabela/coluna ele deve estar
OPEN [NOME DO CURSOR] -- é necessário iniciar o cursor, por isso temos que utilizar o OPEN
FETCH NEXT FROM [NOME DO CURSOR] INTO [NOME VARIAVEL 2]
WHILE @@FETCH_STATUS = 0 -- Aqui é verificado se o cursos já percorreu todas as linhas
BEGIN
IF EXISTS(SELECT [COLUNAS] FROM [TABELA] WHERE [COLUNA DA TABELA] = [NOME DA VARIAVEL 2])
SET [NOME DA VARIAVEL] = [NOME DA VARIAVEL] + 1;
FETCH NEXT FROM [NOME DO CURSOR] INTO DECLARE [NOME DA VARIAVEL 2] -- aqui ele basicamente pula de linha e pega o proximo valor
END
CLOSE [NOME DO CURSOR]
DEALLOCATE [NOME DO CURSOR]
PRINT 'TOTAL: ' + CAST([NOME DA VARIAVEL] AS NVARCHAR(10));
CREATE PROCEDURE [NOME DO PROCEDIMENTO]
AS
[COMANDO SQL]
GO; -- Procedimentos são basicamente uma forma de reutilizar um trecho de código, como um select, update, create, delete, drop, enfin, você pode passar parametros ou não
EXEC [NOME DO PROCEDIMENTO]
CREATE PROCEDURE [NOME DA PROCEDIMENTO] @[VARIAVEL]
AS
SELECT [CAMPO 1] FROM [TABELA] WHERE [CAMPO 1] = @[VARIAVEL] -- Na criação de procedimentos com parametros, é necessário criar uma variável que vá receber o valor passado por parametro para que ela realize as ações desejadas.
EXEC [NOME DA PROCEDIMENTO] @[VARIAVEL] = [VALOR] -- Para executar a procedure, você deve criar uma variável logo a frente e mandando ela com algum valor
SELECT [CAMPO 1], [ALIAS] =
CASE [CAMPO 1]
WHEN [VALOR] THEN
BEGIN
SELECT [CAMPO X1] FROM [TABELA X1]
END
WHEN [VALOR] THEN
BEGIN
SELECT [CAMPO X1] FROM [TABELA X1]
END
ELSE 'NENHUM'
END,
[CAMPO 2] FROM [TABELA] -- O Begin serve basicamente para você determinar o escopo de alguma passagem do codigo, seja ela estrura condicional, de repetição ou em um procedimento
CREATE INDEX [NOME DO INDEX] ON [NOME DA TABELA] ([NOME DA COLUNA]) -- Index é utilizado para recuperar dados de uma forma mais rápida, porém, para atualizar a mesma se torna algo demorado
DROP INDEX [NOME DO INDEX] -- Isso irá remover o index caso ele exista
CREATE VIEW [NOME DA VIEW] AS [SELECT [CAMPOS] FROM [TABELA]] -- Views são como tabelas, porém, elas são tabelas criadas a partir de um ou vários selects, basicamente você usa ela para retornar os dados como se fossem provenientes de uma única tabela
SELECT [CAMPOS] * FROM [NOME DA VIEW] -- Você pode selecionar como um campo ou todos os campos, a view vai funcionar como uma tabela, uma tabela criada a partir de um ou vários selects.
CREATE FUNCTION [NOME DA FUNÇÃO] (@[NOME DO PARAMENTRO][TIPO DO PARAMENTRO])
RETURNS [TIPO DO RETORNO]
BEGIN
[SELECT [CAMPO 1] FROM [TABELA]]
END -- As funções funcionam como um procedimento ou view, porém, ela só podem executar selects, elas podem receber ou não parametros e podem retornar um valor ou uma tabela, diferente dos procedimentos
- Função escalar
CREATE FUNCTION [NOME DA FUNÇÃO](@[NOME DO PARAMETRO][TIPO DO PARAMETRO])
RETURNS [TIPO DO RETORNO]
BEGIN
DECLARE @[NOME DA VARIAVEL][TIPO DA VARIAVEL]
SET @[NOME DA VARIAVEL] = (SELECT SUM([CAMPO 1]) FROM [TABELA] WHERE [CAMPO 1] = @[NOME DO PARAMETRO])
RETURN @[NOME DA VARIAVEL]
END -- Função escalar é aquela que pode ou não receber um paramêtro, porém, ela só deve retornar um valor, como no caso desta função que está recebendo um valor e retorando a somátoria do campo de uma tabela que possui o valor do parametro em um determinado campo
SELECT [CAMPO 1], [CAMPO 2], [ALIAS] = DBO.[NOME DA FUNÇÃO]([PARAMETRO])
FROM [TABELA] -- Você pode chamar a sua função escalar dentro de um select, desta forma, atrinuindo o valor dela em algum alias ou variavel ou campo caso seja um insert
- Função multi-statement table-valued
CREATE FUNCTION [NOME DA FUNÇÃO](@[NOME DO PARAMETRO][TIPO DO PARAMENTRO], @[NOME DO PARAMETRO][TIPO DO PARAMETRO])
RETURNS @[NOME DA TABELA] [TABLE]([CAMPO 1] [TIPO], [CAMPO 2] [TIPO CAMPO 2])
AS
BEGIN
INSERT INTO @[NOME DA TABELA] (SELECT [CAMPOS] FROM [TABELA] WHERE [CAMPO 1] = @[NOME DO PARAMETRO] OR [CAMPO 1] = @[NOME DO PARAMETRO])
RETURN
END -- é aquela que pode ou não receber um paramêtro, Basicamente você passa os campos que a sua tabela de retorno quando você define o tipo de retorno, somente esse tipo de função pode executar o insert e mesmo assim, somente na tabela criada para o tipo de retorno
SELECT * FROM DBO.[NOME DA FUNÇÃO]([PARAMETROS]) -- Como esta função retorna uma tabela, você pode utilizar ela como tabela fonte no seu select
- Função in-line table-valued
CREATE FUNCTION [NOME DA FUNÇÃO] (@[NOME DO PARAMETRO])
RETURNS [TABLE]
AS
RETURN (SELECT [CAMPO 1], [CAMPO 2], [CAMPO 3] FROM [TABELA] WHERE [CAMPO 5] = @[NOME DO PARAMETRO])
-- A função inline é um tipo de função que você não precisa declarar um escopo com o BEGIN e END, já que você faz a chamada do return passando um select com vários campos logo a frente
SELECT * FROM DBO.[NOME DA FUNÇÃO]
Alan Nunes (Rootticc) @rootticc no instagram @rootticc no Twitter Youtube, clique aqui "Conhecimento não é algo que devemos guardar para nós"