This project implements a Retrieval-Augmented Generation (RAG) system using Streamlit as the user interface, LangChain for document processing and retrieval, and Ollama for conversational AI responses. The system allows users to upload PDF documents, process them to create a vector store for retrieval, and then answer queries based on the document content using a Large Language Model (LLM).
This RAG system is especially useful for contexts where domain-specific knowledge stored in documents needs to be accessed dynamically through natural language queries.
- System Workflow
- Script Descriptions
- Integrated LLM and Embedding Models
- Tech Stack
- Ollama Installation
- Usage
- Future Work
- Conclusion
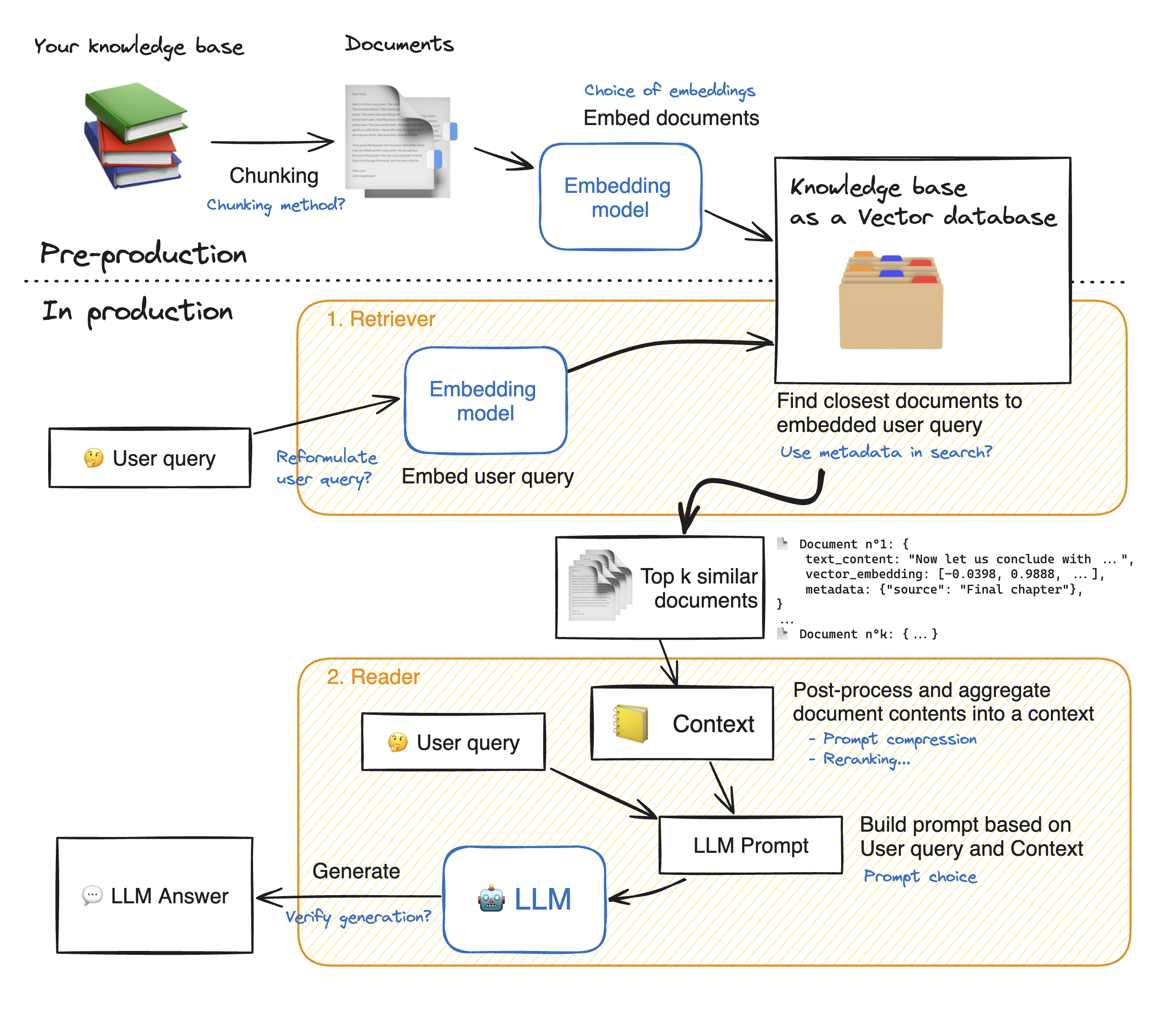
- Upload Documents: Users upload PDF documents via Streamlit, which checks for any new documents and flags them for processing.
- Document Processing:
- Documents are loaded, split into chunks using LangChain's
RecursiveCharacterTextSplitter. - Chunks are embedded with a Hugging Face model (
BAAI/bge-small-en) and stored in a vector store using Chroma.
- Documents are loaded, split into chunks using LangChain's
- Retriever Initialization: A retriever instance is created from the vector store, allowing similarity-based search on document chunks.
- Question-Answering:
- The user inputs a query, which is processed through a retrieval chain.
- Relevant document chunks are retrieved and fed into an Ollama-based LLM for contextual answers.
app.py: The main application file that initializes the RAG system and manages user interactions, serving as the entry point for deploying the retrieval-augmented generation interface.document_processor.py: Handles loading and splitting of PDF documents into manageable chunks for efficient retrieval.vector_store.py: Creates and maintains the vector store, supporting document embedding and retrieval operations.rag_system.py: Initializes the language model and orchestrates the generation of responses based on retrieved document data.config.py: Contains configuration settings, such as model parameters and retrieval options, essential for customizing the RAG system.test.py: A dedicated test script that debug the RAG pipeline, including document processing, vector storage, retrieval setup, and answer generation. It also keeps track in the log file.
| Model | Parameters | Size | Run Command |
|---|---|---|---|
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
For each model in this table, the size of the model is given next to its parameters. The run commands provide the exact syntax to run the respective models.
| Embedding Model Name | Embedding Dim | Repo ID |
|---|---|---|
| BGE Large English v1.5 | 1024 | BAAI/bge-large-en-v1.5 |
| Multilingual E5 Large | 1024 | intfloat/multilingual-e5-large |
| Jina Embeddings v2 Base EN | 768 | jinaai/jina-embeddings-v2-base-en |
| MXBAi Embed Large v1 | 1024 | mixedbread-ai/mxbai-embed-large-v1 |
| E5 Mistral 7B Instruct | 4096 | intfloat/e5-mistral-7b-instruct |
| Jina Embeddings v3 | 768 | jinaai/jina-embeddings-v3 |
| BGE Base English v1.5 | 768 | BAAI/bge-base-en-v1.5 |
| BCE Embedding Base v1 | 768 | maidalun1020/bce-embedding-base_v1 |
| BGE Reranker Large | 1024 | BAAI/bge-reranker-large |
| BGE Small English v1.5 | 384 | BAAI/bge-small-en-v1.5 |
| SFR Embedding Mistral | 4096 | Salesforce/SFR-Embedding-Mistral |
| Multilingual E5 Large Instruct | 1024 | intfloat/multilingual-e5-large-instruct |
| UAE Large V1 | 1024 | WhereIsAI/UAE-Large-V1 |
| Jina Embeddings v2 Base ZH | 768 | jinaai/jina-embeddings-v2-base-zh |
| Jina Embeddings v2 Base DE | 768 | jinaai/jina-embeddings-v2-base-de |
| Jina Embeddings v2 Small EN (512d) | 512 | jinaai/jina-embeddings-v2-small-en |
| BGE Small EN | 384 | BAAI/bge-small-en |
| GTE Small | 384 | Supabase/gte-small |
| all-MiniLM-L6-v2 | 384 | sentence-transformers/all-MiniLM-L6-v2 |
| all-mpnet-base-v2 | 768 | sentence-transformers/all-mpnet-base-v2 |
| e5-large-v2 | 1024 | intfloat/e5-large-v2 |
- Streamlit: Web interface for document upload, configuration, and interaction.
- LangChain: Document loading, text splitting, vectorization, and retrieval workflows.
- Ollama: Language model API for conversational responses.
- Chroma: Vector store to store and retrieve document embeddings.
- Hugging Face: Embedding model for document vectorization.
Ollama is the LLM used in this project. To install it:
- Visit the Ollama Official Repo and download the installer for your OS (Linux/WSL Recommended).
- Follow the installation instructions provided for your operating system.
After installation, Run Ollama model from your environment by running:
ollama run <model_name>More ollama models are provided in the official Ollama Repository.
To run the RAG system:
-
Clone the Repository:
git clone https://github.com/anindyamitra2002/DocQnA.git cd DocQnA -
Install Dependencies: Ensure you have Python 3.10+ installed. Install the required packages:
pip install -r requirements.txt
-
Start the Streamlit Application:
streamlit run app.py
-
Upload PDF Documents:
- Use the sidebar to upload documents. The system will process and store them in a vector store.
- Configure LLM model options and document retrieval parameters in the sidebar.
-
Query the System:
- Enter a query in the chat input box, and the system will retrieve relevant document chunks and generate an answer based on the uploaded documents.
-
Improving Retrieval Accuracy: Incorporate hybrid search and dynamic indexing to improve retrieval precision and ensure real-time data relevance.
-
Contextual Understanding: Use contextual embeddings and chunk sequencing to enhance the relevance and coherence of retrieved information.
-
Handling Complex Queries: Enable multi-document reasoning and filtering techniques to manage complex queries and reduce irrelevant data distractions.
-
Evaluation Frameworks: Develop robust evaluation metrics and establish benchmarks to measure and compare system performance effectively.
-
User Interaction and Feedback Loops: Integrate interactive learning and feedback mechanisms to refine responses based on user interactions over time.
-
Agentic RAG: Add agentic capabilities to autonomously determine retrieval based on user intent, improving response relevance.
-
Graph RAG: Utilize graph-based structures to map data relationships, enhancing retrieval by connecting related information.
This RAG system leverages document embeddings, similarity search, and LLM-driven responses to build a robust question-answering tool for document-based knowledge. Future expansions can enhance the capabilities for a variety of applications, from customer support to research.