Efficiency zh CN
Caffeine 使用 Window TinyLfu策略因为其高命中率和更低的内存开销。
ARC使用一个队列储存只看了一次的元素,另一个队列存放查看多次的元素,和非常驻队列用来存放被监控的驱逐元素。队列的最大大小将根据工作负载模式和缓存性能动态调整。
这个策略容易被实现,但是其要求缓存的容量加倍以存放被驱逐的元素。并且已经获得专利,未经IBM许可不可使用。
LIRS 通过IRR(一个数据块被访问两次的间隔)来组织数据块,并将元素根据热数据块(LIR)或者冷数据块(HIR)进行分组。LIR热数据元素将会被更倾向保留在缓存当中,而被驱逐的HIR冷数据元素江北保留为非常驻HIR冷数据元素。在数次缓存未命中后,允许非常驻HIR元素被晋升为LIR元素。
这个策略实现起来非常复杂,并且需要扩大缓存大小为原来的三倍以保留被驱逐的元素达到最高效的性能。
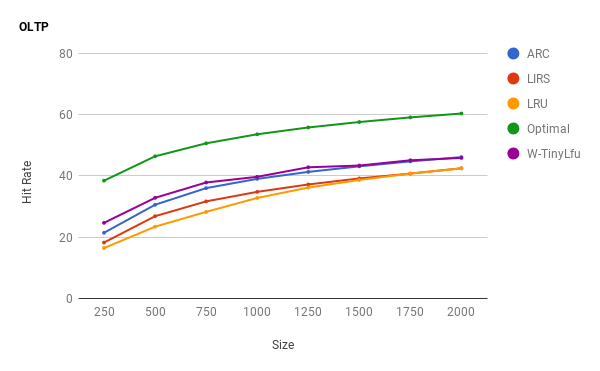
W-TinyLfu通过LRU将小范围窗口中的数据数据驱逐到更大的范围中进行Segmented LRU进行驱逐。 TinyLfu依赖一个频率sketch 来预估元素的历史访问频率。小范围的数据窗口的设计使该策略在新数据大量加入的时候具有较高的命中率。小范围的时间窗口大小和大范围的主要空间大小将根据hill climbing算法进行动态优化。这允许缓存能以较低的开销估计元素的访问频率和就近度。
这通过4-bit CountMinSketch实现,为了准确性每个元素消耗8字节空间。与ARC 和 LIRS不同的是,这个策略不会保留被驱逐的元素。
将各个驱逐策略和Bélády's optimal进行比较以得到其理论上限。评估追踪程序中的数据子集用来描述一系列策略下的工作负载。
WikiBench提供了所有向Wikipedia发出的请求中的10%的追踪程序。
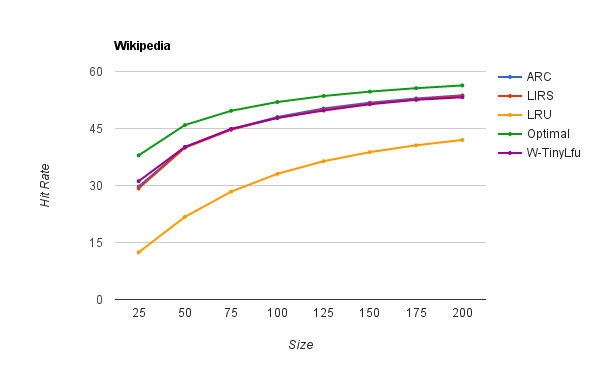
此追踪程序由LIRS算法的作者提供,并显示出其的循环访问模式。
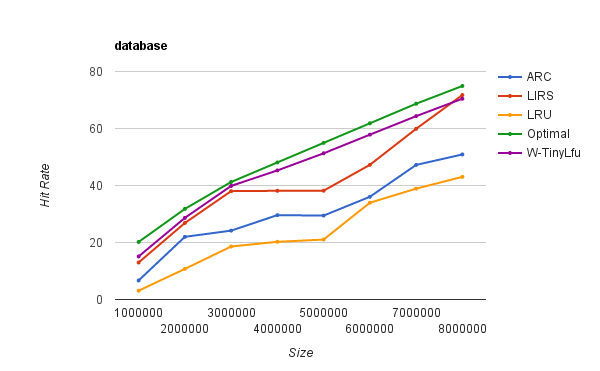
此追踪程序由ARC算法的作者提供,并被描述为“一个运行在商业站点上的数据库服务器上运行着的一个ERP应用的商业数据库”。
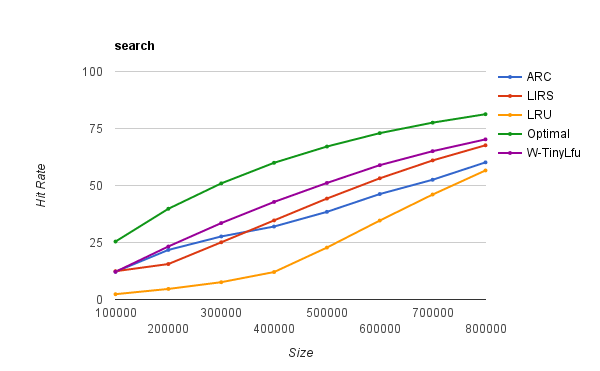
此追踪程序由ARC算法的作者提供,并被描述为“一个大型商业搜索引擎为了响应各种Web搜索请求而发起的磁盘读取访问”。
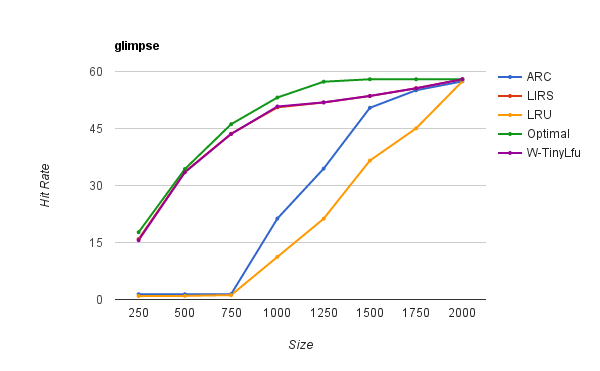
此追踪程序由ARC算法的作者提供,并被描述为“包含一个小时内对CODASYL数据库的引用”。
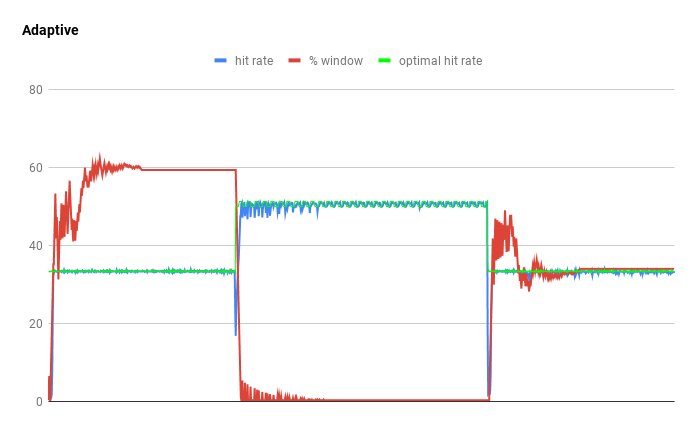
工作负载在偏向就近度的追踪程序(Corda)和偏向频率的追踪程序 (5x Lirs' loop)之间切换。这体现了W-TinyLfu具有重新配置自己的能力。
和ARC ,LIRS相比,Window TinyLfu 提供了近乎最佳的命中率。它在做到这一点的同时实现相对简单,并不会要求非常驻元素的存在,并且要求更低的内存开销。这个策略对各种工作负载的LRU提供了优秀的改造,并使得其成为通用缓存里更好的选择。

