Welcome to our GitHub repository for the Wildfire Segmentation Project, developed as the capstone project for the Postgraduate Program in Artificial Intelligence with Deep Learning. This project is aimed at leveraging the power of deep learning to address the critical and increasingly prevalent issue of wildfires. By employing semantic segmentation techniques on satellite images, we aim to accurately identify and predict wildfire-affected areas, contributing to better management, response, and mitigation strategies.
The original code is the Final Project delivery for the UPC Artificial Intelligence with Deep Learning Postgraduate Course 2023-2024 edition, authored by:
Advised by professor Amanda Duarte
Project Objective
Study the application of semantic segmentation, as a computer vision task, to satellite imagery for the precise identification of areas affected by wildfires.
By utilizing state-of-the-art deep learning techniques, we aim to develop a model capable of distinguishing between burned and unburned areas, thereby facilitating more effective wildfire monitoring and management.
The project underscores the importance of advanced AI in environmental protection and disaster response efforts.
TABLE OF CONTENTS
- General Configuration:
- Models
- Dealing with Satellite Imagery data is not easy at all
- Models
- Final Conclusions
- Future Usage
- Bibliography
To use the database already prepared go to (add link) and download the zip.
- Download the zip and check the name
- Check that the folder name macthes the one on the Colab.
- VGG15
- ResNET18
- ResNet50
- DeepLabV3
In the initial phase of the project, we were uncertain about the feasibility of building our own dataset. During this stage, we explored various satellite products, such as:
We realized that constructing our satellite imagery dataset would be quite challenging. So, we decided to split the work force into two groups. One group would continue investigating the feasibility of building our own dataset, while the other group would find a curated dataset using the following data sources:
- National Agriculture Imagery Program (NAIP)
- The Terra Moderate Resolution Imaging Spectroradiometer (MODIS) Thermal Anomalies and Fire 8-Day (MOD14A2) Version 6.1
- The Terra and Aqua combined MCD64A1 Version 6.1 Burned Area
Model A: Binary Classifier Model for Wildfire Risk Prediction
In Model A, we developed a binary classifier model dedicated to predicting wildfire risk. This initiative served as a backup plan, primarily driven by the considerable effort involved in data preparation for Model B. The complexity arose from working with the intricate GeoTIFF format and its metadata, adding a layer of intricacy to the project.
Although Model A showcases the application of deep learning for classification, it is presented primarily as a supportive effort. It highlights how deep learning can be employed for binary wildfire risk prediction, providing a comparative perspective against the main model's more complex challenges.
Model B: Semantic Segmentation for Wildfire Prediction
Model B represents the core of our innovation, focusing on semantic segmentation of satellite images to identify and predict wildfire-affected areas. Here, we trained a segmentation model, delving into the complexities of GeoTIFF formats, spatial metadata, and more.
This model marks a novel application, showcasing the capability of deep learning for precise wildfire detection through semantic segmentation. While Model A provides valuable insights, Model B represents a significant leap forward, demonstrating a pioneering approach to wildfire prediction with our newly trained segmentation model.
Contents
Build a binary classifier model that can predict whether an area is at risk of a wildfire or not.
After a few days of research, we found a curated dataset on Kaggle. The dataset is called Wildfire Prediction Dataset (Satellite Images).
This dataset contains satellite images of areas that previously experienced wildfires in Canada.
Source
Refer to Canada's website for the original wildfires data: Forest Fires - Open Government Portal
Original license for the data: Creative Commons 4.0 Attribution (CC-BY) license – Quebec
Description
This dataset contains satellite images (350x350px - 3 channels RGB - extension .jpg) divided on 2 classes:
wildfire: 22710 imagesnowildfire: 20140 images
The data was divided into train, test and validation with these percentages:
- Train: ~70% (
wildfire: 15750 images,nowildfire: 14500 images) - Test: ~15% (
wildfire: 3480 images,nowildfire: 2820 images) - Validation: ~15% (
wildfire: 3480 images,nowildfire: 2820 images)
Collection Methodology
Using Longitude and Latitude coordinates for each wildfire spot (> 0.01 acres -same as- > 40.5 m² burned) found on the dataset above satellite images were extracted of those areas using MapBox API to create a more convenient format of the dataset for deep learning and building a model that can predict whether an area is at risk of a wildfire or not. The minimum mapping area can be up to 0.1 ha -same as- 1000 m².
Classes
a) 0- nowildfire
Sample images of nowildfire class:


b) 1- wildfire
Sample images of wildfire class:


Diagram
Neural Network Architecture Diagram:

Code is available here
Resources
MPSdevice on Apple MacBook Pro with M1 chip with 32 GB RAM.Poetryfor setting up the virtual environment and installing the dependencies.
Explanation
In the context of Apple's M1 chip, MPS stands for Metal Performance Shaders. Metal Performance Shaders is a framework provided by Apple that allows developers to perform advanced computations on the GPU (Graphics Processing Unit).
By specifying device = torch.device("mps"), we utilized MPS for computations on the GPU.
This led us to:
- Train the model faster (in just 27 minutes).
- Work with around 40,000 images using local resources, thereby avoiding the usage of Google Drive storage, which is slow and problematic.
- Might be possible that the person who runs this model does not have an
Apple M1computer. Keeping this in mind, we have provided the checkpoint model prediction validation option through a Google Colab notebook.
Hyperparameters:
| Hyperparameter | Value |
|---|---|
| Batch Size | 256 |
| Num Epochs | 10 |
| Test Batch Size | 256 |
| Learning Rate | 1e-3 |
| Weight Decay | 1e-5 |
| Log Interval | 10 |
Evidence
Train Epoch: 9 [23040/30250 (76%)] Loss: 0.348124
Train Epoch: 9 [25600/30250 (85%)] Loss: 0.360356
Train Epoch: 9 [28160/30250 (93%)] Loss: 0.362320
\Validation set: Average loss: 0.3616, Accuracy: 5836/6300 (93%)
Final Test set: Average loss: 0.3527, Accuracy: 93.65%
Saving model to /Users/julianesteban.borona/Github/upc/projects/aidl-upc-winter2024-satellite-imagery/app/with_curated_dataset/wildfire_bin_classifier/src/checkpoints...
Model saved successfully!- Training run log is available here
How to run this training
This section would only be possible if you have an Apple M1 computer. If you don't have an Apple M1 computer, you can use the Google Colab notebook provided in the Prediction section.
- Clone the repository.
- Navigate to the
wildfire_bin_classifierdirectory. - Execute the following
Poetrycommands to set up the virtual environment and install the dependencies:
poetry config virtualenvs.in-project trueAbove command configures Poetry to create virtual environments within the project directory itself rather than in a global location. It ensures that each project has its own isolated environment, making it easier to manage dependencies and avoid conflicts between different projects.
poetry shellAbove command activates a virtual environment managed by Poetry, allowing you to work within an isolated environment where project dependencies are installed.
poetry installAbove command installs the dependencies specified in the pyproject.toml file using Poetry, ensuring that the project has all the necessary packages to run successfully.
That would be all you need to do to set up the virtual environment and install the dependencies.
- Download the dataset from Kaggle and place it in a reachable directory within your local machine.
- Accommodate dataset paths in the
wildfire_bin_classifier/src/main.pyfile. - Configure your IDE to use the virtual environment created by Poetry.
- Run the
wildfire_bin_classifier/src/main.pyfile. - The model will start training and will save the checkpoint model in the
wildfire_bin_classifier/src/checkpointsdirectory.
Plot of Learning Curves

Checkpoint
Model checkpoint is available here
Accuracy
MODEL CHECKPOINT ACCURACY FOR THIS MODEL IS: 93.65% 👌
Easy execution
For the sake of simplicity while validating this model, we have created a straightforward Google Colab notebook that can be used to predict the class {'nowildfire': 0, 'wildfire': 1} of a given satellite image.
Further details
Classes
{'nowildfire': 0, 'wildfire': 1}
 |
 |
| * Example with class `nowildfire` | * Example with class `wildfire` |
| Expected: `nowildfire` | Expected: `wildfire` |
| Prediction: `nowildfire` ✅ | Prediction: `wildfire` ✅ |
Application Code
Available here.
At this point, we successfully built a binary classifier model that can predict whether an area is at risk of a wildfire or not. This was accomplished from scratch using a kaggle curated dataset which contains satellite imagery data.
From a given satellite image with similar characteristics to the ones within the curated dataset, the model can predict the class (0 - 'nowildfire' or 1 - 'wildfire') with an accuracy of 93.65%.
Additionally
- We managed how to use
Poetryto set up the virtual environment and install the dependencies. - We learnt how to take advantage of using
MPSon anApple M1computer to train a deep learning model faster.
Conclusions
- Now that the model works, we want to try with another dataset made of masks obtained from NASA Satelites.
- The new model will use a more powerful CNN performed on AWS.
We curated a custom dataset by incorporating imagery from the National Agriculture Imagery Program (NAIP) and the Moderate Resolution Imaging Spectroradiometer (MODIS) Fire and Thermal Anomalies datasets, retrieved through Google Earth Engine (GEE). The dataset encompasses:
- NAIP Imagery: High-resolution aerial imagery from NAIP, crucial for detailed landscape features. The NAIP dataset can be accessed here.
- MODIS Thermal Anomalies and Fire Data: Essential data for identifying wildfire occurrences, sourced from the MODIS dataset. This dataset can be found here.
Manual Annotation
For the accurate identification of burned and not burned areas corresponding to the wildfires in Paradise, California, and Cameron Peak, Colorado, we performed manual annotations. By visually inspecting the BurnDate mask provided by MODIS within GEE, we systematically marked areas affected by the fires. This meticulous process resulted in a precise dataset consisting of images and corresponding masks for training our model, with a total of 145 burned areas and 182 not burned areas annotated. This step was crucial for ensuring the high quality and reliability of our training dataset, directly impacting the model's ability to accurately segment satellite imagery based on the presence of wildfires.

Sample data points from Colorado wildfires manually labelled in GEE.
- You can explore them in Google Earth Engine.
Data Processing and Preparation
The creation of our dataset involved several key steps:
- Data Acquisition: Programmatic access and download of high-resolution NAIP imagery and MODIS thermal anomalies data from GEE.
- Preprocessing: Alignment and scaling of NAIP and MODIS data to ensure that each NAIP image was perfectly matched with its corresponding MODIS mask based on geographic location and projection.
- Augmentation and Splitting: The dataset was augmented and randomly split into training, validation, and testing sets to ensure robust model training and evaluation.
Satellite Imagery for Segmentation Algorithm Input
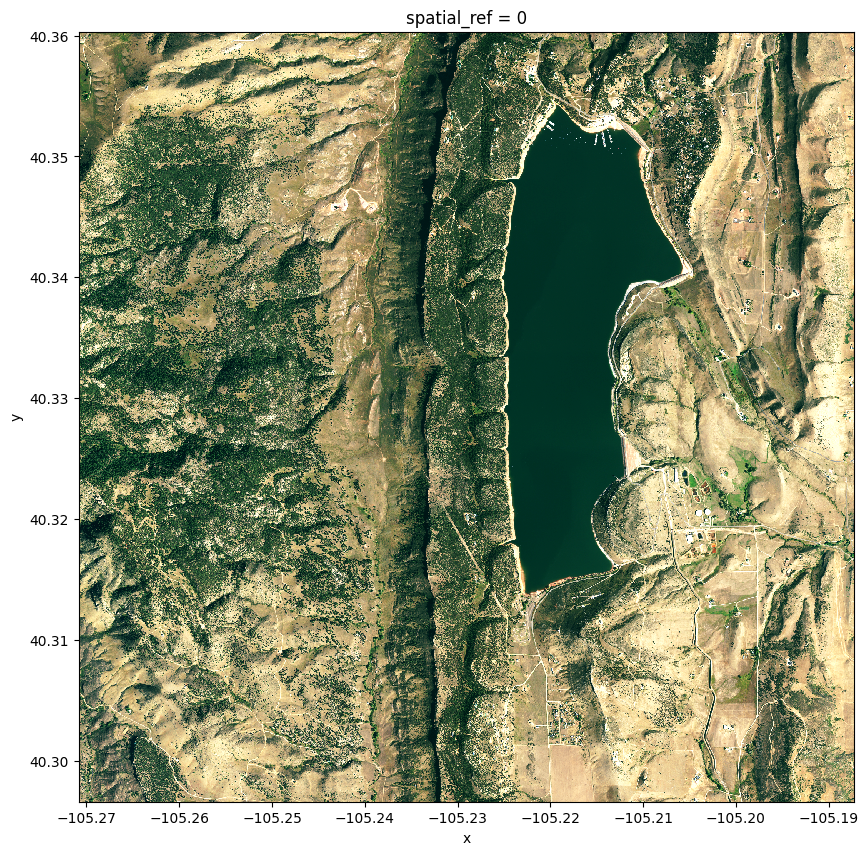
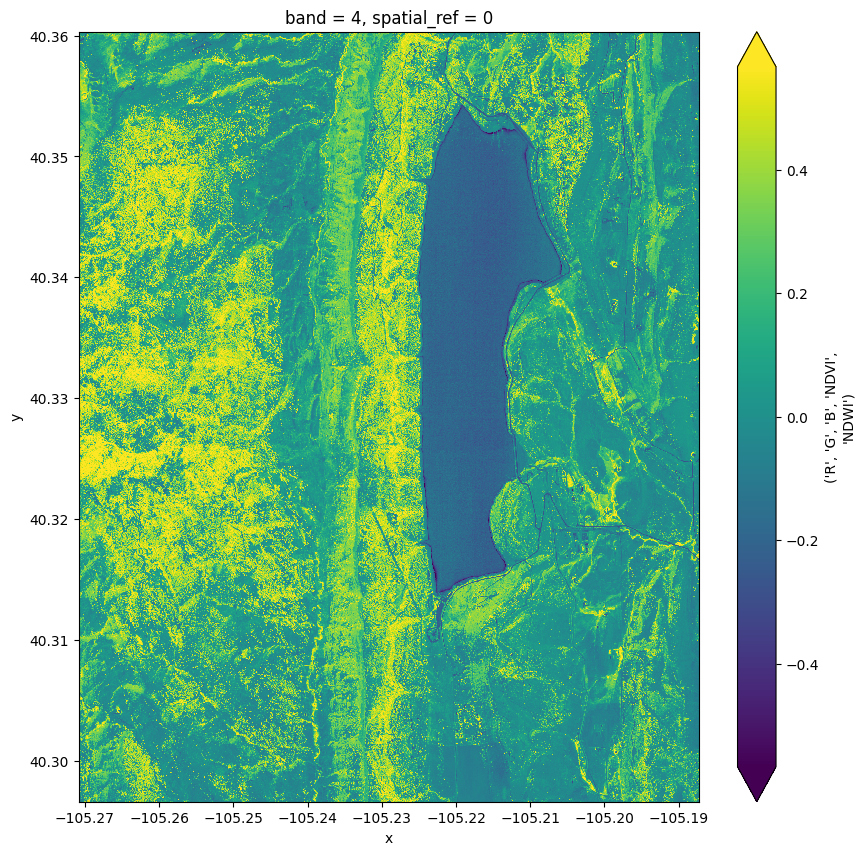

From left to right: Landcover image showcasing diverse surface features, NDVI visualization revealing vegetation health, and NDWI mask highlighting water bodies.
Crucially, these images, depicting landcover, NDVI, and NDWI, serve as the foundational dataset feeding into the segmentation algorithm. Each piece of information captured in these images contributes to training the model to distinguish and identify specific features, enabling precise semantic segmentation for wildfire prediction.
NDVI (Normalized Difference Vegetation Index): NDVI is a vegetation index commonly derived from satellite imagery. It quantifies the presence and health of vegetation by comparing the reflectance of near-infrared light to that of red light. Higher NDVI values typically indicate healthier and more abundant vegetation. Watch it live in Google Earth Engine
NDWI (Normalized Difference Water Index): NDWI is another spectral index, but it focuses on water content. It is derived by comparing the reflectance of green and near-infrared light. Higher NDWI values suggest the presence of water, aiding in the identification of water bodies.
Role in Algorithm: Including NDVI and NDWI data in the segmentation algorithm is crucial. NDVI helps in delineating vegetation, enabling the model to discern areas susceptible to wildfires. On the other hand, NDWI assists in identifying water bodies, aiding in a more comprehensive understanding of the landscape. Together, these indices enhance the algorithm's ability to accurately segment satellite imagery, contributing to effective wildfire prediction and management.
For detailed information on the data and the process of obtaining it from GEE, please refer to the notebook segmentation_model_data.ipynb in this repository. This notebook contains comprehensive details to facilitate the understanding and reproduction of the analysis conducted in this project.
Notebook: For a detailed explanation about the data and how you can generate the dataset you can browse segmentation_model_data.ipynb notebook.
Our model is based on a transfer learning approach using DeepLabv3 with a ResNet50 backbone, pre-trained on a relevant dataset to kickstart the learning process. We further customized the model to accept inputs with additional channels (RGB, NDVI, and NDWI features) and output two layers representing the probabilities assigned to each pixel for being part of a burned or unburned area.
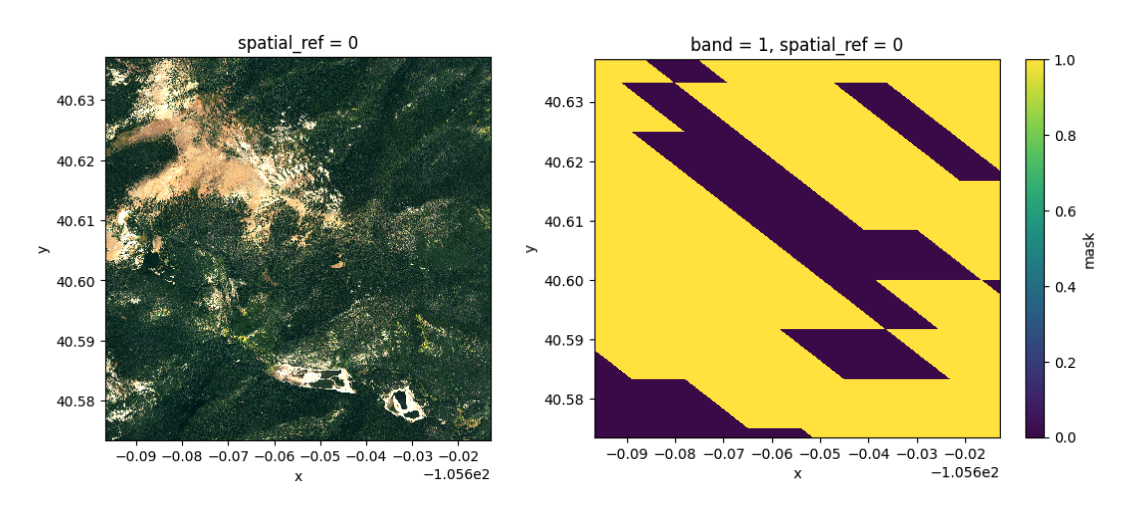
The primary landcover image captures high-resolution details of the landscape, providing valuable visual information for understanding the terrain. The mask serves as the ground truth for wildfire prediction. It indicates areas affected by wildfire and was derived from MODIS FireMask data, calculated in GEE.
Initial Model Training Details
-
Environment: Training was conducted on Google Colab Pro with GPU acceleration and high-memory VMs to handle the computational demands.
-
Monitoring and Experimentation: We utilized TensorBoard for real-time monitoring of training metrics and experimented with various configurations using Weights & Biases (W&B).
-
Loss Function: The model employs Focal Loss to address the class imbalance issue inherent in our dataset, focusing on harder-to-classify examples for improved performance.
-
Early Stopping: To prevent overfitting, we implemented an EarlyStopping mechanism based on validation loss.
Notebook: You can execute the training task with the provided dataset using the segmentation_model_training_demo.ipynb notebook. This notebook has detailed exlanations about the training of the Semantic Segmentation Model, covering data preparation, normalization, model fine tunning, etc.
Final Model Training and Results
Our segmentation model was trained on AWS using the complete dataset, comprising a total of [insert number] images. The training process leveraged GPU resources in the cloud, utilizing high-capacity machines capable of efficiently processing the extensive 12 GB dataset.
Training Details:
- Training Duration: The model was trained over multiple epochs, with noteworthy results achieved by the end of the third epoch.
- Hardware Configuration: The training process made use of GPUs in the cloud, ensuring accelerated computation to handle the large dataset.
- Hyperparameters:
| Hyperparameter | Value |
|---|---|
| Model | DeepLabv3+ |
| Backbone | ResNet50 |
| Input Channels | 5 |
| Number of Classes | 2 |
| Number of Filters | 3 |
| Loss Function | Focal Loss |
| Learning Rate | 0.0001 |
| Patience for Early Stopping | 5 |
| Freezing Backbone | True |
| Freezing Decoder | False |
| Batch Size | 6 |
| Patch Size | 256 |
| Training Length | 4000 |
| Number of Workers | 64 |
Model Metrics:
- Model Accuracy: 0.75 (epoch 3)
These results showcase the model's capability to effectively learn from the dataset and make accurate predictions. The chosen hyperparameters, model architecture, and careful training contribute to a robust and reliable segmentation model for wildfire prediction.
Notebook: You can review the code used for training the final model in the cloud in the end_to_end_model_creation_cloud_env.ipyn notebook.
Below, in our developed application, we showcase the predictive capability of our segmentation model. Leveraging geographic coordinates, the model adeptly identifies areas at heightened risk of wildfire occurrence.
This model paves the way for further exploration of harnessing satellite imagery's metadata richness alongside deep learning models. The goal is to construct high-impact applications that contribute significantly to wildfire mitigation efforts.

Wildfire probability zones (marked on yellow)
Notebook: You can review the code used for obtaining the model prediction in the model_prediction.ipyn notebook.
- The model has achieved 75% accuracy.
- Through this project, we demonstrate the potential of deep learning in enhancing our ability to monitor and respond to wildfires. We invite you to explore our notebooks, replicate our findings, and contribute to this vital field of research.
- As satellites are continually monitoring and photographing the planet, an application of this type can be very useful to detect particularly sensitive areas so that they can be subjected to stricter surveillance, thereby helping to prevent fires.
- We've experimented with the two datasets and two models and, in both cases, they suggest the feasibility of the project.
- The use of masks is particularly useful for:
- Allowing the precise identification and delineation of objects or regions of interest in a satellite image.
- Reducing noise or parts of the image that are not essential for analysis.
- Improving model accuracy; masks enable increased model precision by helping it better understand the image structure, leading to more accurate predictions.
- Optimizing computational resources by eliminating irrelevant information in images.
- Finetune to get a better accuracy
- Develop a frontend to visualize everything
Thank you for visiting our repository.