-
Notifications
You must be signed in to change notification settings - Fork 607
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Showing
8 changed files
with
350 additions
and
122 deletions.
There are no files selected for viewing
This file was deleted.
Oops, something went wrong.
This file was deleted.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,32 @@ | ||
| # Metrics | ||
|
|
||
| ## Custom user metrics | ||
|
|
||
| It is possible to export custom user metrics by adding the `metrics_client` | ||
| argument to the predictor constructor. Below there is an example of how to use the metrics client with | ||
| the `PythonPredictor` type. The implementation would be similar to other predictor types. | ||
|
|
||
| ```python | ||
| class PythonPredictor: | ||
| def __init__(self, config, metrics_client): | ||
| self.metrics = metrics_client | ||
|
|
||
| def predict(self, payload): | ||
| # --- my predict code here --- | ||
| result = ... | ||
|
|
||
| # increment a counter with name "my_metric" and tags model:v1 | ||
| self.metrics.increment(metric="my_counter", value=1, tags={"model": "v1"}) | ||
|
|
||
| # set the value for a gauge with name "my_gauge" and tags model:v1 | ||
| self.metrics.gauge(metric="my_gauge", value=42, tags={"model": "v1"}) | ||
|
|
||
| # set the value for an histogram with name "my_histogram" and tags model:v1 | ||
| self.metrics.histogram(metric="my_histogram", value=100, tags={"model": "v1"}) | ||
| ``` | ||
|
|
||
| Refer to the [observability documentation](../observability/metrics.md#custom-user-metrics) for more information on | ||
| custom metrics. | ||
|
|
||
| **Note**: The metrics client uses the UDP protocol to push metrics, to be fault tolerant, so if it fails during a | ||
| metrics push there is no exception thrown. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,112 @@ | ||
| # Logging | ||
|
|
||
| Cortex provides a logging solution, out-of-the-box, without the need to configure anything. By default, logs are | ||
| collected with FluentBit, on every API kind, and are exported to each cloud provider logging solution. It is also | ||
| possible to view the logs of a single API replica, while developing, through the `cortex logs` command. | ||
|
|
||
| ## Cortex logs command | ||
|
|
||
| The cortex CLI tool provides a command to quickly check the logs for a single API replica while debugging. | ||
|
|
||
| To check the logs of an API run one of the following commands: | ||
|
|
||
| ```shell | ||
| # RealtimeAPI | ||
| cortex logs <api_name> | ||
|
|
||
| # BatchAPI or TaskAPI | ||
| cortex logs <api_name> <job_id> # the job needs to be in a running state | ||
| ``` | ||
|
|
||
| **Important:** this method won't show the logs for all the API replicas and therefore is not a complete logging | ||
| solution. | ||
|
|
||
| ## Logs on AWS | ||
|
|
||
| For AWS clusters, logs will be pushed to [CloudWatch](https://console.aws.amazon.com/cloudwatch/home) using fluent-bit. | ||
| A log group with the same name as your cluster will be created to store your logs. API logs are tagged with labels to | ||
| help with log aggregation and filtering. | ||
|
|
||
| Below are some sample CloudWatch Log Insight queries: | ||
|
|
||
| **RealtimeAPI:** | ||
|
|
||
| ```text | ||
| fields @timestamp, log | ||
| | filter labels.apiName="<INSERT API NAME>" | ||
| | filter labels.apiKind="RealtimeAPI" | ||
| | sort @timestamp asc | ||
| | limit 1000 | ||
| ``` | ||
|
|
||
| **BatchAPI:** | ||
|
|
||
| ```text | ||
| fields @timestamp, log | ||
| | filter labels.apiName="<INSERT API NAME>" | ||
| | filter labels.jobID="<INSERT JOB ID>" | ||
| | filter labels.apiKind="BatchAPI" | ||
| | sort @timestamp asc | ||
| | limit 1000 | ||
| ``` | ||
|
|
||
| **TaskAPI:** | ||
|
|
||
| ```text | ||
| fields @timestamp, log | ||
| | filter labels.apiName="<INSERT API NAME>" | ||
| | filter labels.jobID="<INSERT JOB ID>" | ||
| | filter labels.apiKind="TaskAPI" | ||
| | sort @timestamp asc | ||
| | limit 1000 | ||
| ``` | ||
|
|
||
| ## Logs on GCP | ||
|
|
||
| Logs will be pushed to [StackDriver](https://console.cloud.google.com/logs/query) using fluent-bit. API logs are tagged | ||
| with labels to help with log aggregation and filtering. | ||
|
|
||
| Below are some sample Stackdriver queries: | ||
|
|
||
| **RealtimeAPI:** | ||
|
|
||
| ```text | ||
| resource.type="k8s_container" | ||
| resource.labels.cluster_name="<INSERT CLUSTER NAME>" | ||
| labels.apiKind="RealtimeAPI" | ||
| labels.apiName="<INSERT API NAME>" | ||
| ``` | ||
|
|
||
| **BatchAPI:** | ||
|
|
||
| ```text | ||
| resource.type="k8s_container" | ||
| resource.labels.cluster_name="<INSERT CLUSTER NAME>" | ||
| labels.apiKind="BatchAPI" | ||
| labels.apiName="<INSERT API NAME>" | ||
| labels.jobID="<INSERT JOB ID>" | ||
| ``` | ||
|
|
||
| **TaskAPI:** | ||
|
|
||
| ```text | ||
| resource.type="k8s_container" | ||
| resource.labels.cluster_name="<INSERT CLUSTER NAME>" | ||
| labels.apiKind="TaskAPI" | ||
| labels.apiName="<INSERT API NAME>" | ||
| labels.jobID="<INSERT JOB ID>" | ||
| ``` | ||
|
|
||
| Please make sure to navigate to the project containing your cluster and adjust the time range accordingly before running | ||
| queries. | ||
|
|
||
| ## Structured logging | ||
|
|
||
| You can use Cortex's logger in your Python code to log in JSON, which will enrich your logs with Cortex's metadata, and | ||
| enable you to add custom metadata to the logs. | ||
|
|
||
| See the structured logging docs for each API kind: | ||
|
|
||
| - [RealtimeAPI](../../workloads/realtime/predictors.md#structured-logging) | ||
| - [BatchAPI](../../workloads/batch/predictors.md#structured-logging) | ||
| - [TaskAPI](../../workloads/task/definitions.md#structured-logging) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,150 @@ | ||
| # Metrics | ||
|
|
||
| A cortex cluster includes a deployment of Prometheus for metrics collections and a deployment of Grafana for | ||
| visualization. You can monitor your APIs with the Grafana dashboards that ship with Cortex, or even add custom metrics | ||
| and dashboards. | ||
|
|
||
| ## Accessing the dashboard | ||
|
|
||
| The dashboard URL is displayed once you run a `cortex get <api_name>` command. | ||
|
|
||
| Alternatively, you can access it on `http://<operator_url>/dashboard`. Run the following command to get the operator | ||
| URL: | ||
|
|
||
| ```shell | ||
| cortex env list | ||
| ``` | ||
|
|
||
| If your operator load balancer is configured to be internal, there are a few options for accessing the dashboard: | ||
|
|
||
| 1. Access the dashboard from a machine that has VPC Peering configured to your cluster's VPC, or which is inside of your | ||
| cluster's VPC | ||
| 1. Run `kubectl port-forward -n default grafana-0 3000:3000` to forward Grafana's port to your local machine, and access | ||
| the dashboard on [http://localhost:3000/](http://localhost:3000/) (see instructions for setting up `kubectl` | ||
| on [AWS](../../clusters/aws/kubectl.md) or [GCP](../../clusters/gcp/kubectl.md)) | ||
| 1. Set up VPN access to your cluster's | ||
| VPC ([AWS docs](https://docs.aws.amazon.com/vpc/latest/userguide/vpn-connections.html)) | ||
|
|
||
| ### Default credentials | ||
|
|
||
| The dashboard is protected with username / password authentication, which by default are: | ||
|
|
||
| - Username: admin | ||
| - Password: admin | ||
|
|
||
| You will be prompted to change the admin user password in the first time you log in. | ||
|
|
||
| Grafana allows managing the access of several users and managing teams. For more information on this topic check | ||
| the [grafana documentation](https://grafana.com/docs/grafana/latest/manage-users/). | ||
|
|
||
| ### Selecting an API | ||
|
|
||
| You can select one or more APIs to visualize in the top left corner of the dashboard. | ||
|
|
||
| 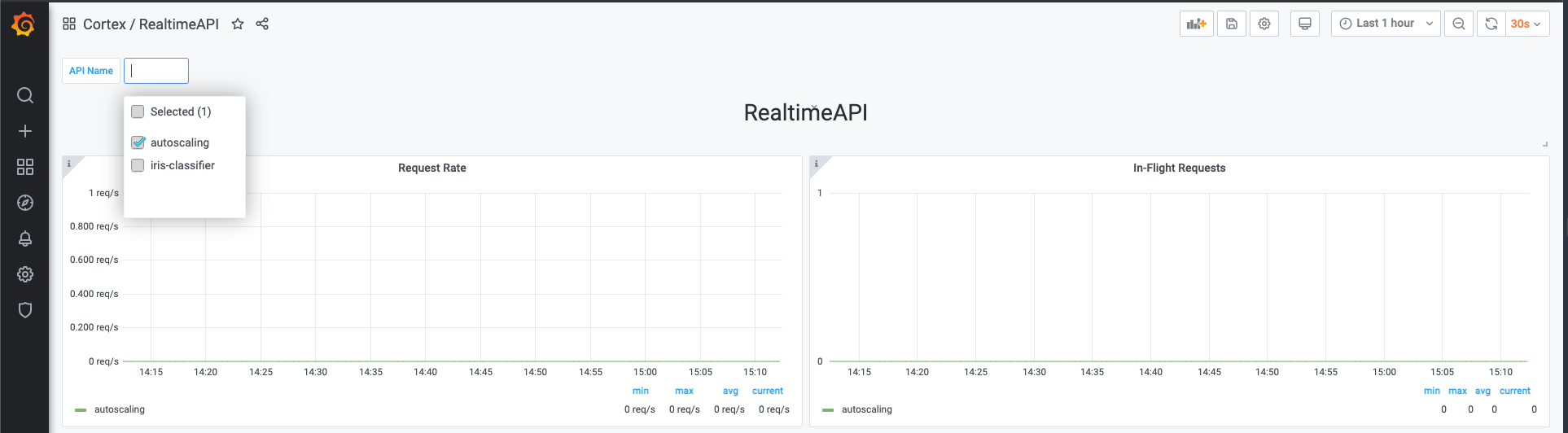 | ||
|
|
||
| ### Selecting a time range | ||
|
|
||
| Grafana allows you to select a time range on which the metrics will be visualized. You can do so in the top right corner | ||
| of the dashboard. | ||
|
|
||
| 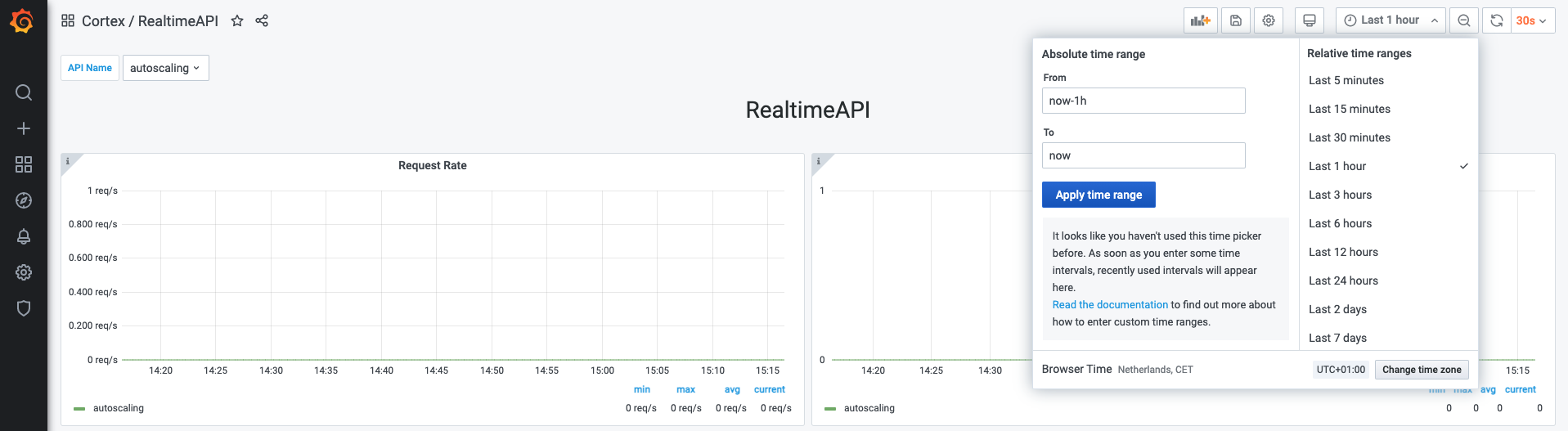 | ||
|
|
||
| **Note: Cortex only retains a maximum of 2 weeks worth of data at any moment in time** | ||
|
|
||
| ### Available dashboards | ||
|
|
||
| There are more than one dashboard available by default. You can view the available dashboards by accessing the Grafana | ||
| menu: `Dashboards -> Manage -> Cortex folder`. | ||
|
|
||
| The dashboards that Cortex ships with are the following: | ||
|
|
||
| - RealtimeAPI | ||
| - BatchAPI | ||
| - Cluster resources | ||
| - Node resources | ||
|
|
||
| ## Exposed metrics | ||
|
|
||
| Cortex exposes more metrics with Prometheus, that can be potentially useful. To check the available metrics, access | ||
| the `Explore` menu in grafana and press the `Metrics` button. | ||
|
|
||
|  | ||
|
|
||
| You can use any of these metrics to set up your own dashboards. | ||
|
|
||
| ## Custom user metrics | ||
|
|
||
| It is possible to export your own custom metrics by using the `MetricsClient` class in your predictor code. This allows | ||
| you to create a custom metrics from your deployed API that can be later be used on your own custom dashboards. | ||
|
|
||
| Code examples on how to use custom metrics for each API kind can be found here: | ||
|
|
||
| - [RealtimeAPI](../realtime/metrics.md#custom-user-metrics) | ||
| - [BatchAPI](../batch/metrics.md#custom-user-metrics) | ||
| - [TaskAPI](../task/metrics.md#custom-user-metrics) | ||
|
|
||
| ### Metric types | ||
|
|
||
| Currently, we only support 3 different metric types that will be converted to its respective Prometheus type: | ||
|
|
||
| - [Counter](https://prometheus.io/docs/concepts/metric_types/#counter) - a cumulative metric that represents a single | ||
| monotonically increasing counter whose value can only increase or be reset to zero on restart. | ||
| - [Gauge](https://prometheus.io/docs/concepts/metric_types/#gauge) - a single numerical value that can arbitrarily go up | ||
| and down. | ||
| - [Histogram](https://prometheus.io/docs/concepts/metric_types/#histogram) - samples observations (usually things like | ||
| request durations or response sizes) and counts them in configurable buckets. It also provides a sum of all observed | ||
| values. | ||
|
|
||
| ### Pushing metrics | ||
|
|
||
| - Counter | ||
|
|
||
| ```python | ||
| metrics.increment('my_counter', value=1, tags={"tag": "tag_name"}) | ||
| ``` | ||
|
|
||
| - Gauge | ||
|
|
||
| ```python | ||
| metrics.gauge('active_connections', value=1001, tags={"tag": "tag_name"}) | ||
| ``` | ||
|
|
||
| - Histogram | ||
|
|
||
| ```python | ||
| metrics.histogram('inference_time_milliseconds', 120, tags={"tag": "tag_name"}) | ||
| ``` | ||
|
|
||
| ### Metrics client class reference | ||
|
|
||
| ```python | ||
| class MetricsClient: | ||
|
|
||
| def gauge(self, metric: str, value: float, tags: Dict[str, str] = None): | ||
| """ | ||
| Record the value of a gauge. | ||
| Example: | ||
| >>> metrics.gauge('active_connections', 1001, tags={"protocol": "http"}) | ||
| """ | ||
| pass | ||
|
|
||
| def increment(self, metric: str, value: float = 1, tags: Dict[str, str] = None): | ||
| """ | ||
| Increment the value of a counter. | ||
| Example: | ||
| >>> metrics.increment('model_calls', 1, tags={"model_version": "v1"}) | ||
| """ | ||
| pass | ||
|
|
||
| def histogram(self, metric: str, value: float, tags: Dict[str, str] = None): | ||
| """ | ||
| Set the value in a histogram metric | ||
| Example: | ||
| >>> metrics.histogram('inference_time_milliseconds', 120, tags={"model_version": "v1"}) | ||
| """ | ||
| pass | ||
| ``` |
Oops, something went wrong.