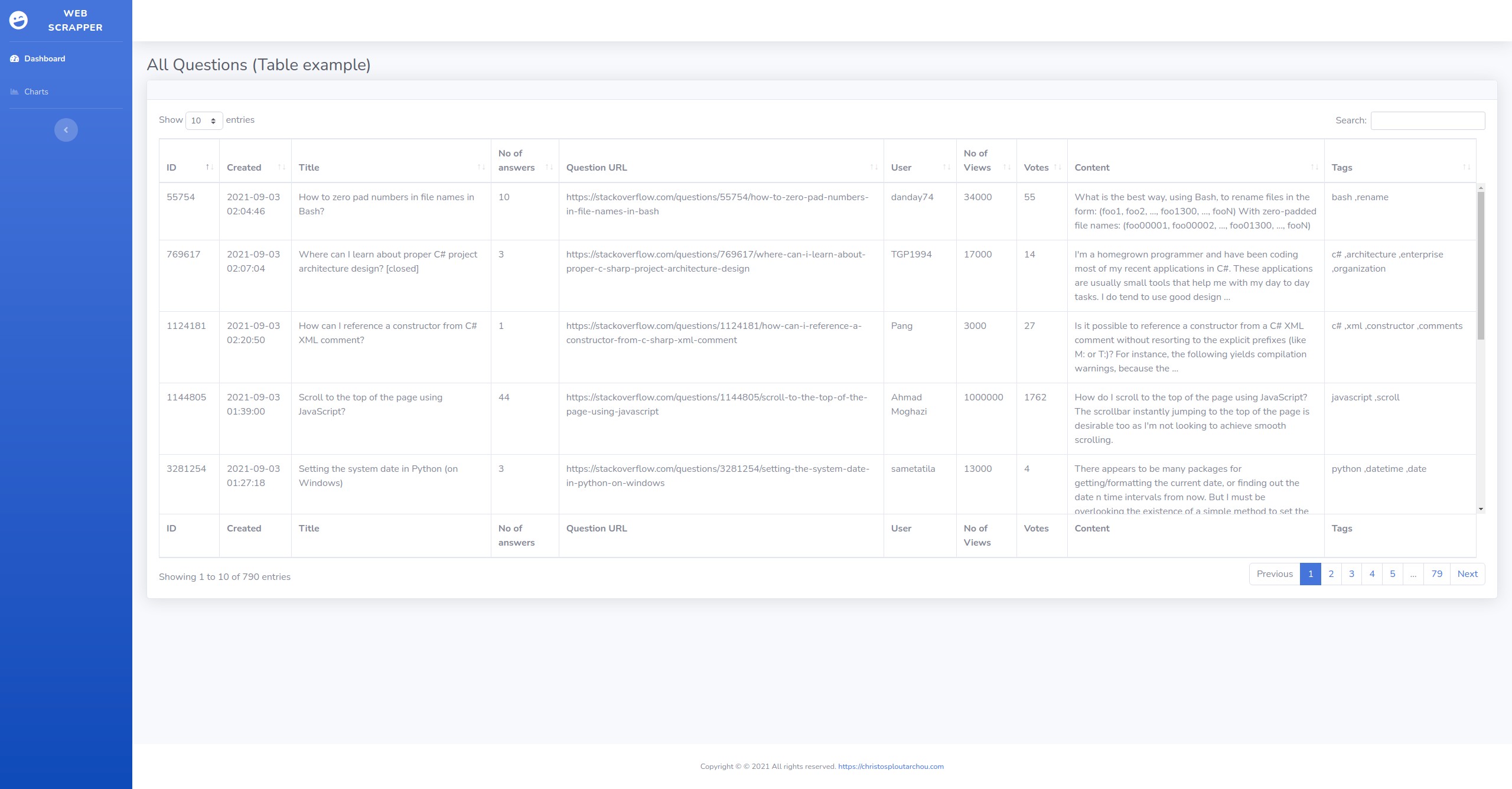
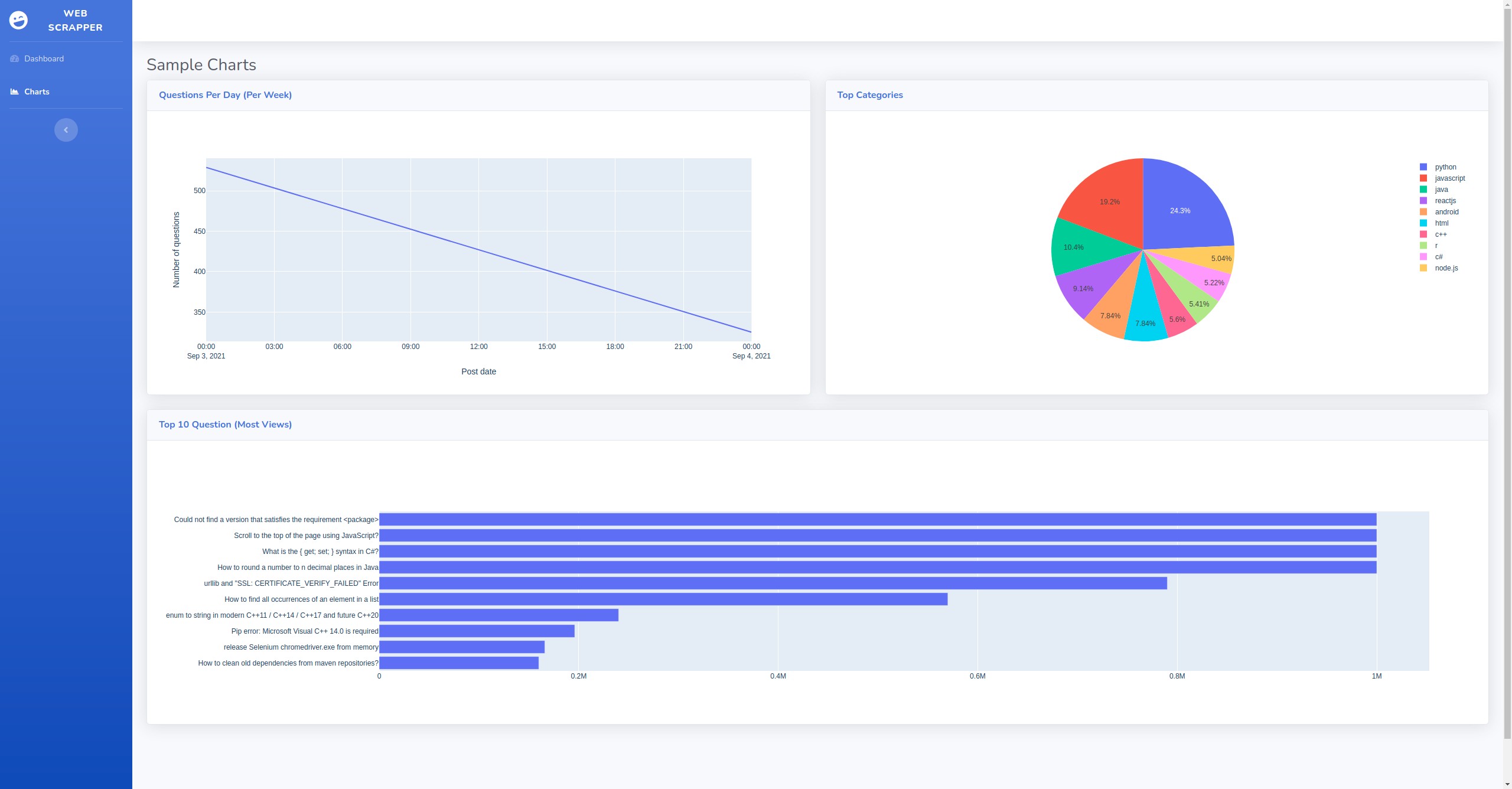
A simple scraper app for StackOverflow using MongoDB.
- For the first time you need to run ./init.sh
- You can stop the infrastructure usinf ./stop.sh
- You can start the infrastructure usinf ./start.sh
- docker
- docker-compose
- http://172.21.0.35:9000/
- Usename : admin
- password : admin
To be able to receive application logs to Graylog you need to make the followings
- Create one GelfTCP input stream
- Click on System/inputs/gelf
- Select Gelf TCP from the dropdown
- Click on Launch new input
- add a Title for the input
- Click save
- Now, you can access the application log by Click on Show Received Messages
- Url : http://172.21.0.25
- Url : http://172.21.0.20
- Database name : webscrapper
- Database User : admin
- Database password : admin
if is required to update cron job run you can edit the followings:
- Docker/scripts/entrypoint.sh and update the default expression (*/30 * * * *) bases on your requirements.
- Docker/scripts/scheduler.txt and update the default expression (*/30 * * * *) bases on your requirements.
-
The application, by default, fetches the first ten pages from StackOverflow every 30 minutes. A cron job runs the scraper and updates the application database.
-
It is required to fetch more pages. You can update the passed parameters of method execute_job() from 10 to any other value between 10 and 1000. The file is located on app/scraper.py