
![]()








If you like this work please consider buying a coffee ;-)

EHMASS is a Python module designed to optimize your home energy interfacing with Home Assistant.
EMHASS (Energy Management for Home Assistant) is an optimization tool designed for residential households. The package uses a Linear Programming approach to optimize energy usage while considering factors such as electricity prices, power generation from solar panels, and energy storage from batteries. EMHASS provides a high degree of configurability, making it easy to integrate with Home Assistant and other smart home systems. Whether you have solar panels, energy storage, or just a controllable load, EMHASS can provide an optimized daily schedule for your devices, allowing you to save money and minimize your environmental impact.
The complete documentation for this package is available here.
EMHASS and Home Assistant provide a comprehensive energy management solution that can optimize energy usage and reduce costs for households. By integrating these two systems, households can take advantage of advanced energy management features that provide significant cost savings, increased energy efficiency, and greater sustainability.
EMHASS is a powerful energy management tool that generates an optimization plan based on variables such as solar power production, energy usage, and energy costs. The plan provides valuable insights into how energy can be better managed and utilized in the household. Even if households do not have all the necessary equipment, such as solar panels or batteries, EMHASS can still provide a minimal use case solution to optimize energy usage for controllable/deferrable loads.
Home Assistant provides a platform for the automation of household devices based on the optimization plan generated by EMHASS. This includes devices such as batteries, pool pumps, hot water heaters, and electric vehicle (EV) chargers. By automating EV charging and other devices, households can take advantage of off-peak energy rates and optimize their EV charging schedule based on the optimization plan generated by EMHASS.
One of the main benefits of integrating EMHASS and Home Assistant is the ability to customize and tailor the energy management solution to the specific needs and preferences of each household. With EMHASS, households can define their energy management objectives and constraints, such as maximizing self-consumption or minimizing energy costs, and the system will generate an optimization plan accordingly. Home Assistant provides a platform for the automation of devices based on the optimization plan, allowing households to create a fully customized and optimized energy management solution.
Overall, the integration of EMHASS and Home Assistant offers a comprehensive energy management solution that provides significant cost savings, increased energy efficiency, and greater sustainability for households. By leveraging advanced energy management features and automation capabilities, households can achieve their energy management objectives while enjoying the benefits of more efficient and sustainable energy usage, including optimized EV charging schedules.
The package flow can be graphically represented as follows:
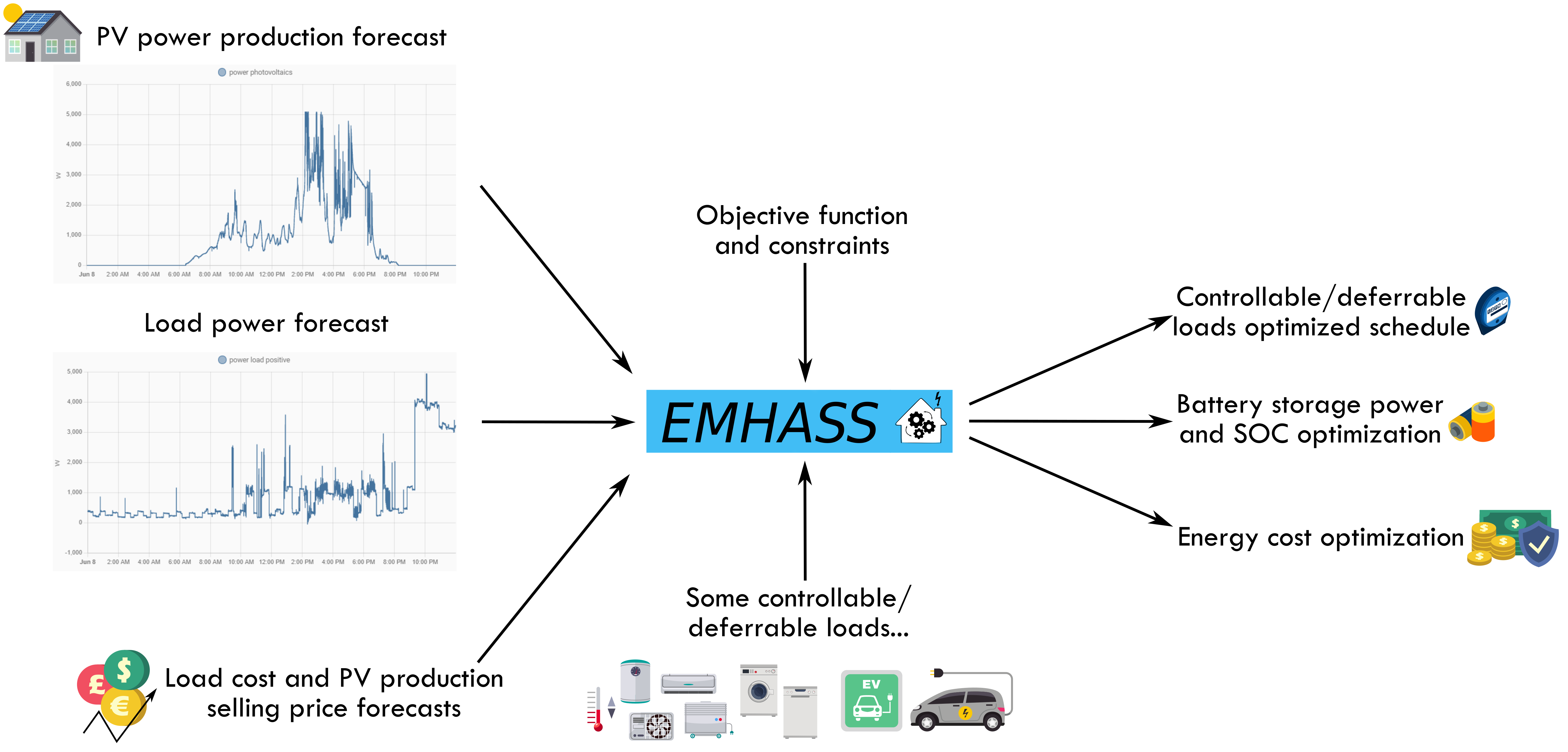
The package is meant to be highly configurable with an object-oriented modular approach and a main configuration file defined by the user. EMHASS was designed to be integrated with Home Assistant, hence its name. Installation instructions and example Home Assistant automation configurations are given below.
You must follow these steps to make EMHASS work properly:
-
Install and run EMHASS.
- There are multiple methods of installing and Running EMHASS. See Installation Method below to pick a method that best suits your use case.
-
Define all the parameters in the configuration file (
config.json) or configuration page (YOURIP:5000/configuration).- See the description for each parameter in the configuration docs.
- You will most notably need to define the main data entering EMHASS. This will be the Home Assistant sensor/variable
sensor.power_photovoltaicsfor the name of your Home Assistant variable containing the PV produced power, and the sensor/variablesensor.power_load_no_var_loads, for the load power of your household excluding the power of the deferrable loads that you want to optimize. - If you have a PV installation then this dedicated web app can be useful for finding your inverter and solar panel models: https://emhass-pvlib-database.streamlit.app/
- You will most notably need to define the main data entering EMHASS. This will be the Home Assistant sensor/variable
- See the description for each parameter in the configuration docs.
-
Launch the optimization and check the results.
- This can be done manually using the buttons in the web UI
- Or with a
curlcommand like this:curl -i -H 'Content-Type:application/json' -X POST -d '{}' http://localhost:5000/action/dayahead-optim.
-
If you’re satisfied with the optimization results then you can set the optimization and data publish task commands in an automation.
- You can read more about this in the usage section below.
-
The final step is to link the deferrable loads variables to real switches on your installation.
- An example code for this using automations and the shell command integration is presented below in the usage section.
A more detailed workflow is given below:
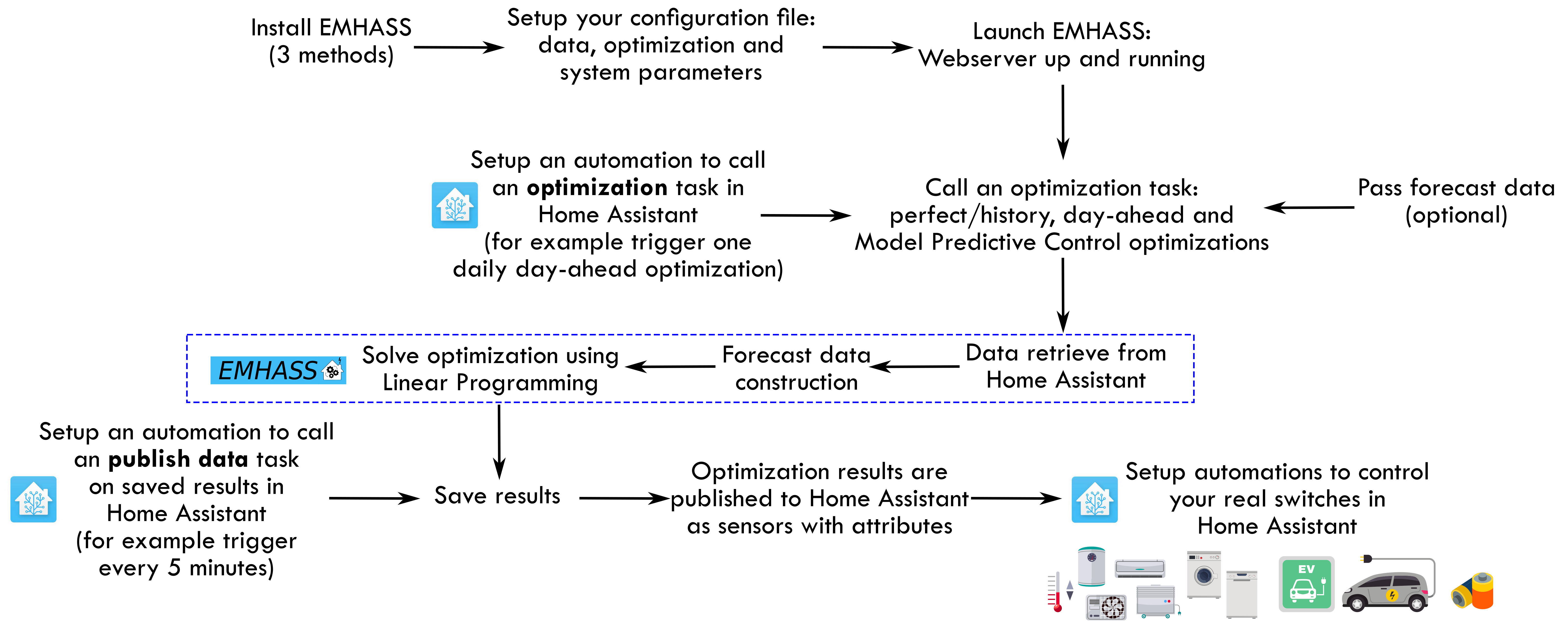
For Home Assistant OS and HA Supervised users, A EMHASS an add-on repository has been developed to allow the EMHASS Docker container to run as a Home Assistant Addon. The add-on is more user-friendly as the Home Assistant secrets (URL and API key) are automatically placed inside of the EMHASS container, and web server port (default 5000) is already opened.
You can find the add-on with the installation instructions here: https://github.com/davidusb-geek/emhass-add-on
These architectures are supported: amd64, armv7, armhf and aarch64.
Note: Both EMHASS via Docker and EMHASS-Add-on contain the same Docker image. The EMHASS-Add-on repository however, stores Home Assistant addon specific configuration information and maintains EMHASS image version control.
You can also install EMHASS using Docker as a container. This can be in the same machine as Home Assistant (if your running Home Assistant as a Docker container) or in a different distant machine. To install first pull the latest image:
# pull Docker image
docker pull ghcr.io/davidusb-geek/emhass:latest
# run Docker image, mounting config.json and secrets_emhass.yaml from host
docker run --rm -it --restart always -p 5000:5000 --name emhass-container -v ./config.json:/share/config.json -v ./secrets_emhass.yaml:/app/secrets_emhass.yaml ghcr.io/davidusb-geek/emhass:latestNote it is not recommended to install the latest EMHASS image with :latest (as you would likely want to control when you update EMHASS version). Instead, find the latest version tag (E.g: v0.2.1) and replace latest
You can also build your image locally. For this clone this repository, and build the image from the Dockerfile:
# git clone EMHASS repo
git clone https://github.com/davidusb-geek/emhass.git
# move to EMHASS directory
cd emhass
# build Docker image
# may need to set architecture tag (docker build --build-arg TARGETARCH=amd64 -t emhass-local .)
docker build -t emhass-local .
# run built Docker image, mounting config.json and secrets_emhass.yaml from host
docker run --rm -it --restart always -p 5000:5000 --name emhass-container -v ./config.json:/share/config.json -v ./secrets_emhass.yaml:/app/secrets_emhass.yaml emhass-localBefore running the docker container, make sure you have a designated folder for emhass on your host device and a secrets_emhass.yaml file. You can get a example of the secrets file from secrets_emhass(example).yaml file on this repository.
# cli example of creating an emhass directory and appending a secrets_emhass.yaml file inside
mkdir ~/emhass
cd ~/emhass
cat <<EOT >> ~/emhass/secrets_emhass.yaml
hass_url: https://myhass.duckdns.org/
long_lived_token: thatverylongtokenhere
time_zone: Europe/Paris
Latitude: 45.83
Longitude: 6.86
Altitude: 4807.8
EOT
docker run --rm -it --restart always -p 5000:5000 --name emhass-container -v ./config.json:/share/config.json -v ./secrets_emhass.yaml:/app/secrets_emhass.yaml ghcr.io/davidusb-geek/emhass:latest-
You can create a
config.jsonfile prior to running emhass. (obtain a example from: config_defaults.json Alteratively, you can insert your parameters into the configuration page on the EMHASS web server. (for EMHASS to auto create a config.json) With either option, the volume mount-v ./config.json:/share/config.jsonshould be applied to make sure your config is stored on the host device. (to be not deleted when the EMHASS container gets removed/image updated)* -
If you wish to keep a local, semi-persistent copy of the EMHASS-generated data, create a local folder on your device, then mount said folder inside the container.
#create data folder mkdir -p ~/emhass/data docker run -it --restart always -p 5000:5000 -e LOCAL_COSTFUN="profit" -v ~/emhass/config.json:/app/config.json -v ~/emhass/data:/app/data -v ~/emhass/secrets_emhass.yaml:/app/secrets_emhass.yaml --name DockerEMHASS <REPOSITORY:TAG>
-
If you wish to set the web_server's homepage optimization diagrams to a timezone other than UTC, set
TZenvironment variable on docker run:docker run -it --restart always -p 5000:5000 -e TZ="Europe/Paris" -v ~/emhass/config.json:/app/config.json -v ~/emhass/secrets_emhass.yaml:/app/secrets_emhass.yaml --name DockerEMHASS <REPOSITORY:TAG>
If you wish to run EMHASS optimizations with cli commands. (no persistent web server session) you can run EMHASS via the python package alone (not wrapped in a Docker container).
With this method it is recommended to install on a virtual environment.
-
Create and activate a virtual environment:
python3 -m venv ~/emhassenv cd ~/emhassenv source bin/activate
-
Install using the distribution files:
python3 -m pip install emhass
-
Create and store configuration (config.json), secret (secrets_emhass.yaml) and data (/data) files in the emhass dir (
~/emhassenv)
Note: You may wish to copy theconfig.json(config_defaults.json),secrets_emhass.yaml(secrets_emhass(example).yaml) and/or/scripts/files from this repository to the~/emhassenvfolder for a starting point and/or to run the bash scripts described below. -
To upgrade the installation in the future just use:
python3 -m pip install --upgrade emhass
If using the add-on or the Docker installation, it exposes a simple webserver on port 5000. You can access it directly using your browser. (E.g.: http://localhost:5000)
With this web server, you can perform RESTful POST commands on multiple ENDPOINTS with the prefix action/*:
- A POST call to
action/perfect-optimto perform a perfect optimization task on the historical data. - A POST call to
action/dayahead-optimto perform a day-ahead optimization task of your home energy. - A POST call to
action/naive-mpc-optimto perform a naive Model Predictive Controller optimization task. If using this option you will need to define the correctruntimeparams(see further below). - A POST call to
action/publish-datato publish the optimization results data for the current timestamp. - A POST call to
action/forecast-model-fitto train a machine learning forecaster model with the passed data (see the dedicated section for more help). - A POST call to
action/forecast-model-predictto obtain a forecast from a pre-trained machine learning forecaster model (see the dedicated section for more help). - A POST call to
action/forecast-model-tuneto optimize the machine learning forecaster models hyperparameters using Bayesian optimization (see the dedicated section for more help).
A curl command can then be used to launch an optimization task like this: curl -i -H 'Content-Type:application/json' -X POST -d '{}' http://localhost:5000/action/dayahead-optim.
To run a command simply use the emhass CLI command followed by the needed arguments.
The available arguments are:
--action: This is used to set the desired action, options are:perfect-optim,dayahead-optim,naive-mpc-optim,publish-data,forecast-model-fit,forecast-model-predictandforecast-model-tune.--config: Define the path to the config.json file (including the yaml file itself)--secrets: Define secret parameter file (secrets_emhass.yaml) path--costfun: Define the type of cost function, this is optional and the options are:profit(default),cost,self-consumption--log2file: Define if we should log to a file or not, this is optional and the options are:TrueorFalse(default)--params: Configuration as JSON.--runtimeparams: Data passed at runtime. This can be used to pass your own forecast data to EMHASS.--debug: UseTruefor testing purposes.--version: Show the current version of EMHASS.--root: Define path emhass root (E.g. ~/emhass )--data: Define path to the Data files (.csv & .pkl) (E.g. ~/emhass/data/ )
For example, the following line command can be used to perform a day-ahead optimization task:
emhass --action 'dayahead-optim' --config ~/emhass/config.json --costfun 'profit'Before running any valuable command you need to modify the config.json and secrets_emhass.yaml files. These files should contain the information adapted to your own system. To do this take a look at the special section for this in the documentation.
To automate EMHASS with Home Assistant, we will need to define some shell commands in the Home Assistant configuration.yaml file and some basic automations in the automations.yaml file.
In the next few paragraphs, we are going to consider the dayahead-optim optimization strategy, which is also the first that was implemented, and we will also cover how to publish the optimization results.
Additional optimization strategies were developed later, that can be used in combination with/replace the dayahead-optim strategy, such as MPC, or to expand the functionalities such as the Machine Learning method to predict your household consumption. Each of them has some specificities and features and will be considered in dedicated sections.
In configuration.yaml:
shell_command:
dayahead_optim: "curl -i -H \"Content-Type:application/json\" -X POST -d '{}' http://localhost:5000/action/dayahead-optim"
publish_data: "curl -i -H \"Content-Type:application/json\" -X POST -d '{}' http://localhost:5000/action/publish-data"In configuration.yaml:
shell_command:
dayahead_optim: ~/emhass/scripts/dayahead_optim.sh
publish_data: ~/emhass/scripts/publish_data.shCreate the file dayahead_optim.sh with the following content:
#!/bin/bash
. ~/emhassenv/bin/activate
emhass --action 'dayahead-optim' --config ~/emhass/config.jsonAnd the file publish_data.sh with the following content:
#!/bin/bash
. ~/emhassenv/bin/activate
emhass --action 'publish-data' --config ~/emhass/config.jsonThen specify user rights and make the files executables:
sudo chmod -R 755 ~/emhass/scripts/dayahead_optim.sh
sudo chmod -R 755 ~/emhass/scripts/publish_data.sh
sudo chmod +x ~/emhass/scripts/dayahead_optim.sh
sudo chmod +x ~/emhass/scripts/publish_data.shIn automations.yaml:
- alias: EMHASS day-ahead optimization
trigger:
platform: time
at: '05:30:00'
action:
- service: shell_command.dayahead_optim
- alias: EMHASS publish data
trigger:
- minutes: /5
platform: time_pattern
action:
- service: shell_command.publish_dataIn these automations the day-ahead optimization is performed once a day, every day at 5:30am, and the data (output of automation) is published every 5 minutes.
In automations.yaml:
- alias: EMHASS day-ahead optimization
trigger:
platform: time
at: '05:30:00'
action:
- service: shell_command.dayahead_optim
- service: shell_command.publish_datain configuration page/config.json
'method_ts_round': "first"
'continual_publish': trueIn this automation, the day-ahead optimization is performed once a day, every day at 5:30am.
If the optimization_time_step parameter is set to 30 (default) in the configuration, the results of the day-ahead optimization will generate 48 values (for each entity), a value for every 30 minutes in a day (i.e. 24 hrs x 2).
Setting the parameter continual_publish to true in the configuration page will allow EMHASS to store the optimization results as entities/sensors into separate json files. continual_publish will periodically (every optimization_time_step amount of minutes) run a publish, and publish the optimization results of each generated entities/sensors to Home Assistant. The current state of the sensor/entity being updated every time publish runs, selecting one of the 48 stored values, by comparing the stored values' timestamps, the current timestamp and 'method_ts_round': "first" to select the optimal stored value for the current state.
option 1 and 2 are very similar, however, option 2 (continual_publish) will require a CPU thread to constantly be run inside of EMHASS, lowering efficiency. The reason why you may pick one over the other is explained in more detail below in continual_publish.
Lastly, we can link an EMHASS published entity/sensor's current state to a Home Assistant entity on/off switch, controlling a desired controllable load.
For example, imagine that I want to control my water heater. I can use a published deferrable EMHASS entity to control my water heater's desired behavior. In this case, we could use an automation like the below, to control the desired water heater on and off:
on:
automation:
- alias: Water Heater Optimized ON
trigger:
- minutes: /5
platform: time_pattern
condition:
- condition: numeric_state
entity_id: sensor.p_deferrable0
above: 0.1
action:
- service: homeassistant.turn_on
entity_id: switch.water_heater_switchoff:
automation:
- alias: Water Heater Optimized OFF
trigger:
- minutes: /5
platform: time_pattern
condition:
- condition: numeric_state
entity_id: sensor.p_deferrable0
below: 0.1
action:
- service: homeassistant.turn_off
entity_id: switch.water_heater_switchThese automations will turn on and off the Home Assistant entity switch.water_heater_switch using the current state from the EMHASS entity sensor.p_deferrable0. sensor.p_deferrable0 being the entity generated from the EMHASS day-ahead optimization and published by examples above. The sensor.p_deferrable0 entity's current state is updated every 30 minutes (or optimization_time_step minutes) via an automated publish option 1 or 2. (selecting one of the 48 stored data values)
publish-data (which is either run manually or automatically via continual_publish or Home Assistant automation), will push the optimization results to Home Assistant for each deferrable load defined in the configuration. For example, if you have defined two deferrable loads, then the command will publish sensor.p_deferrable0 and sensor.p_deferrable1 to Home Assistant. When the dayahead-optim is launched, after the optimization, either entity json files or a csv file will be saved on disk. The publish-data command will load the latest csv/json files to look for the closest timestamp that matches the current time using the datetime.now() method in Python. This means that if EMHASS is configured for 30-minute time step optimizations, the csv/json will be saved with timestamps 00:00, 00:30, 01:00, 01:30, ... and so on. If the current time is 00:05, and parameter method_ts_round is set to nearest in the configuration, then the closest timestamp of the optimization results that will be published is 00:00. If the current time is 00:25, then the closest timestamp of the optimization results that will be published is 00:30.
The publish-data command will also publish PV and load forecast data on sensors p_pv_forecast and p_load_forecast. If using a battery, then the battery-optimized power and the SOC will be published on sensors p_batt_forecast and soc_batt_forecast. On these sensors, the future values are passed as nested attributes.
If you run publish manually (or via a Home Assistant Automation), it is possible to provide custom sensor names for all the data exported by the publish-data command. For this, when using the publish-data endpoint we can just add some runtime parameters as dictionaries like this:
shell_command:
publish_data: "curl -i -H \"Content-Type:application/json\" -X POST -d '{\"custom_load_forecast_id\": {\"entity_id\": \"sensor.p_load_forecast\", \"unit_of_measurement\": \"W\", \"friendly_name\": \"Load Power Forecast\"}}' http://localhost:5000/action/publish-data"These keys are available to modify: custom_pv_forecast_id, custom_load_forecast_id, custom_batt_forecast_id, custom_batt_soc_forecast_id, custom_grid_forecast_id, custom_cost_fun_id, custom_deferrable_forecast_id, custom_unit_load_cost_id and custom_unit_prod_price_id.
If you provide the custom_deferrable_forecast_id then the passed data should be a list of dictionaries, like this:
shell_command:
publish_data: "curl -i -H \"Content-Type:application/json\" -X POST -d '{\"custom_deferrable_forecast_id\": [{\"entity_id\": \"sensor.p_deferrable0\",\"unit_of_measurement\": \"W\", \"friendly_name\": \"Deferrable Load 0\"},{\"entity_id\": \"sensor.p_deferrable1\",\"unit_of_measurement\": \"W\", \"friendly_name\": \"Deferrable Load 1\"}]}' http://localhost:5000/action/publish-data"You should be careful that the list of dictionaries has the correct length, which is the number of defined deferrable loads.
Below you can find a list of the variables resulting from EMHASS computation, shown in the charts and published to Home Assistant through the publish_data command:
| EMHASS variable | Definition | Home Assistant published sensor |
|---|---|---|
| P_PV | Forecasted power generation from your solar panels (Watts). This helps you predict how much solar energy you will produce during the forecast period. | sensor.p_pv_forecast |
| P_Load | Forecasted household power consumption (Watts). This gives you an idea of how much energy your appliances are expected to use. | sensor.p_load_forecast |
| P_deferrableX [X = 0, 1, 2, ...] |
Forecasted power consumption of deferrable loads (Watts). Deferable loads are appliances that can be managed by EMHASS. EMHASS helps you optimize energy usage by prioritizing solar self-consumption and minimizing reliance on the grid or by taking advantage or supply and feed-in tariff volatility. You can have multiple deferable loads and you use this sensor in HA to control these loads via smart switch or other IoT means at your disposal. | sensor.p_deferrableX |
| P_grid_pos | Forecasted power imported from the grid (Watts). This indicates the amount of energy you are expected to draw from the grid when your solar production is insufficient to meet your needs or it is advantageous to consume from the grid. | - |
| P_grid_neg | Forecasted power exported to the grid (Watts). This indicates the amount of excess solar energy you are expected to send back to the grid during the forecast period. | - |
| P_batt | Forecasted (dis)charge power load (Watts) for the battery (if installed). If negative it indicates the battery is charging, if positive that the battery is discharging. | sensor.p_batt_forecast |
| P_grid | Forecasted net power flow between your home and the grid (Watts). This is calculated as P_grid_pos - P_grid_neg. A positive value indicates net export, while a negative value indicates net import. | sensor.p_grid_forecast |
| SOC_opt | Forecasted battery optimized Status Of Charge (SOC) percentage level | sensor.soc_batt_forecast |
| unit_load_cost | Forecasted cost per unit of energy you pay to the grid (typically "Currency"/kWh). This helps you understand the expected energy cost during the forecast period. | sensor.unit_load_cost |
| unit_prod_price | Forecasted price you receive for selling excess solar energy back to the grid (typically "Currency"/kWh). This helps you understand the potential income from your solar production. | sensor.unit_prod_price |
| cost_profit | Forecasted profit or loss from your energy usage for the forecast period. This is calculated as unit_load_cost * P_Load - unit_prod_price * P_grid_pos. A positive value indicates a profit, while a negative value indicates a loss. | sensor.total_cost_profit_value |
| cost_fun_cost | Forecasted cost associated with deferring loads to maximize solar self-consumption. This helps you evaluate the trade-off between managing the load and not managing and potential cost savings. | sensor.total_cost_fun_value |
| optim_status | This contains the status of the latest execution and is the same you can see in the Log following an optimization job. Its values can be Optimal or Infeasible. | sensor.optim_status |
In EMHASS we have 4 forecasts to deal with:
-
PV power production forecast (internally based on the weather forecast and the characteristics of your PV plant). This is given in Watts.
-
Load power forecast: how much power your house will demand in the next 24 hours. This is given in Watts.
-
Load cost forecast: the price of the energy from the grid in the next 24 hours. This is given in EUR/kWh.
-
PV production selling price forecast: at what price are you selling your excess PV production in the next 24 hours. This is given in EUR/kWh.
The sensor containing the load data should be specified in the parameter sensor_power_load_no_var_loads in the configuration file. As we want to optimize household energy, we need to forecast the load power consumption. The default method for this is a naive approach using 1-day persistence. The load data variable should not contain the data from the deferrable loads themselves. For example, let's say that you set your deferrable load to be the washing machine. The variables that you should enter in EMHASS will be: sensor_power_load_no_var_loads: 'sensor.power_load_no_var_loads' and sensor.power_load_no_var_loads = sensor.power_load - sensor.power_washing_machine. This is supposing that the overall load of your house is contained in the variable: sensor.power_load. The sensor sensor.power_load_no_var_loads can be easily created with a new template sensor in Home Assistant.
If you are implementing an MPC controller, then you should also need to provide some data at the optimization runtime using the key runtimeparams.
The valid values to pass for both forecast data and MPC-related data are explained below.
Due to the flexibility of EMHASS, multiple different approaches to publishing the optimization results have been created. Select an option that best meets your use case:
By default, running an optimization in EMHASS will output the results into the CSV file: data_path/opt_res_latest.csv (overriding the existing data on that file). We run the publish command to publish the last optimization saved in the opt_res_latest.csv:
# RUN dayahead
curl -i -H 'Content-Type:application/json' -X POST -d {} http://localhost:5000/action/dayahead-optim
# Then publish teh results of dayahead
curl -i -H 'Content-Type:application/json' -X POST -d {} http://localhost:5000/action/publish-dataNote, the published entities from the publish-data action will not automatically update the entities' current state (current state being used to check when to turn on and off appliances via Home Assistant automations). To update the EMHASS entities state, another publish would have to be re-run later when the current time matches the next value's timestamp (e.g. every 30 minutes). See examples below for methods to automate the publish-action.
As discussed in Common for any installation method - option 2, setting continual_publish to true in the configuration saves the output of the optimization into the data_path/entities folder (a .json file for each sensor/entity). A constant loop (in optimization_time_step minutes) will run, observe the .json files in that folder, and publish the saved files periodically (updating the current state of the entity by comparing date.now with the saved data value timestamps).
For users that wish to run multiple different optimizations, you can set the runtime parameter: publish_prefix to something like: "mpc_" or "dh_". This will generate unique entity_id names per optimization and save these unique entities as separate files in the folder. All the entity files will then be updated when the next loop iteration runs. If a different optimization_time_step integer was passed as a runtime parameter in an optimization, the continual_publish loop will be based on the lowest optimization_time_step saved. An example:
# RUN dayahead, with optimization_time_step=30 (default), prefix=dh_
curl -i -H 'Content-Type:application/json' -X POST -d '{"publish_prefix":"dh_"}' http://localhost:5000/action/dayahead-optim
# RUN MPC, with optimization_time_step=5, prefix=mpc_
curl -i -H 'Content-Type:application/json' -X POST -d '{'optimization_time_step':5,"publish_prefix":"mpc_"}' http://localhost:5000/action/naive-mpc-optimThis will tell continual_publish to loop every 5 minutes based on the optimization_time_step passed in MPC. All entities from the output of dayahead "dh_" and MPC "mpc_" will be published every 5 minutes.
It is recommended to use the 2 other options below once you have a more advanced understanding of EMHASS and/or Home Assistant.
You can choose to save one optimization for continual_publish and bypass another optimization by setting 'continual_publish':false runtime parameter:
# RUN dayahead, with optimization_time_step=30 (default), prefix=dh_, included into continual_publish
curl -i -H 'Content-Type:application/json' -X POST -d '{"publish_prefix":"dh_"}' http://localhost:5000/action/dayahead-optim
# RUN MPC, with optimization_time_step=5, prefix=mpc_, Manually publish, excluded from continual_publish loop
curl -i -H 'Content-Type:application/json' -X POST -d '{'continual_publish':false,'optimization_time_step':5,"publish_prefix":"mpc_"}' http://localhost:5000/action/naive-mpc-optim
# Publish MPC output
curl -i -H 'Content-Type:application/json' -X POST -d {} http://localhost:5000/action/publish-dataThis example saves the dayahead optimization into data_path/entities as .json files, being included in the continutal_publish loop (publishing every 30 minutes). The MPC optimization will not be saved in data_path/entities, and therefore only into data_path/opt_res_latest.csv. Requiring a publish-data action to be run manually (or via a Home Assistant) Automation for the MPC results.
For users who wish to have full control of exactly when they would like to run a publish and have the ability to save multiple different optimizations. The entity_save runtime parameter has been created to save the optimization output entities to .json files whilst continual_publish is set to false in the configuration. Allowing the user to reference the saved .json files manually via a publish:
in configuration page/config.json :
'continual_publish': falsePOST action :
# RUN dayahead, with optimization_time_step=30 (default), prefix=dh_, save entity
curl -i -H 'Content-Type:application/json' -X POST -d '{"entity_save": true, "publish_prefix":"dh_"}' http://localhost:5000/action/dayahead-optim
# RUN MPC, with optimization_time_step=5, prefix=mpc_, save entity
curl -i -H 'Content-Type:application/json' -X POST -d '{"entity_save": true", 'optimization_time_step':5,"publish_prefix":"mpc_"}' http://localhost:5000/action/naive-mpc-optimYou can then reference these .json saved entities via their publish_prefix. Include the same publish_prefix in the publish_data action:
#Publish the MPC optimization ran above
curl -i -H 'Content-Type:application/json' -X POST -d '{"publish_prefix":"mpc_"}' http://localhost:5000/action/publish-dataThis will publish all entities from the MPC (_mpc) optimization above.
Alternatively, you can choose to publish all the saved files .json files with publish_prefix = all:
#Publish all saved entities
curl -i -H 'Content-Type:application/json' -X POST -d '{"publish_prefix":"all"}' http://localhost:5000/action/publish-dataThis action will publish the dayahead (_dh) and MPC (_mpc) optimization results from the optimizations above.
It is possible to provide EMHASS with your own forecast data. For this just add the data as a list of values to a data dictionary during the call to emhass using the runtimeparams option.
For example, if using the add-on or the standalone docker installation you can pass this data as a list of values to the data dictionary during the curl POST:
curl -i -H 'Content-Type:application/json' -X POST -d '{"pv_power_forecast":[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 70, 141.22, 246.18, 513.5, 753.27, 1049.89, 1797.93, 1697.3, 3078.93, 1164.33, 1046.68, 1559.1, 2091.26, 1556.76, 1166.73, 1516.63, 1391.13, 1720.13, 820.75, 804.41, 251.63, 79.25, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}' http://localhost:5000/action/dayahead-optimOr if using the legacy method using a Python virtual environment:
emhass --action 'dayahead-optim' --config ~/emhass/config.json --runtimeparams '{"pv_power_forecast":[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 70, 141.22, 246.18, 513.5, 753.27, 1049.89, 1797.93, 1697.3, 3078.93, 1164.33, 1046.68, 1559.1, 2091.26, 1556.76, 1166.73, 1516.63, 1391.13, 1720.13, 820.75, 804.41, 251.63, 79.25, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}'The possible dictionary keys to pass data are:
-
pv_power_forecastfor the PV power production forecast. -
load_power_forecastfor the Load power forecast. -
load_cost_forecastfor the Load cost forecast. -
prod_price_forecastfor the PV production selling price forecast.
It is possible to also pass other data during runtime to automate energy management. For example, it could be useful to dynamically update the total number of hours for each deferrable load (operating_hours_of_each_deferrable_load) using for instance a correlation with the outdoor temperature (useful for water heater for example).
Here is the list of the other additional dictionary keys that can be passed at runtime:
-
number_of_deferrable_loadsfor the number of deferrable loads to consider. -
nominal_power_of_deferrable_loadsfor the nominal power for each deferrable load in Watts. -
operating_hours_of_each_deferrable_loadfor the total number of hours that each deferrable load should operate. -
start_timesteps_of_each_deferrable_loadfor the timestep from which each deferrable load is allowed to operate (if you don't want the deferrable load to use the whole optimization timewindow). -
end_timesteps_of_each_deferrable_loadfor the timestep before which each deferrable load should operate (if you don't want the deferrable load to use the whole optimization timewindow). -
def_current_statePass this as a list of booleans (True/False) to indicate the current deferrable load state. This is used internally to avoid incorrectly penalizing a deferrable load start if a forecast is run when that load is already running. -
treat_deferrable_load_as_semi_contto define if we should treat each deferrable load as a semi-continuous variable. -
set_deferrable_load_single_constantto define if we should set each deferrable load as a constant fixed value variable with just one startup for each optimization task. -
solcast_api_keyfor the SolCast API key if you want to use this service for PV power production forecast. -
solcast_rooftop_idfor the ID of your rooftop for the SolCast service implementation. -
solar_forecast_kwpfor the PV peak installed power in kW used for the solar.forecast API call. -
battery_minimum_state_of_chargethe minimum possible SOC. -
battery_maximum_state_of_chargethe maximum possible SOC. -
battery_target_state_of_chargefor the desired target value of the initial and final SOC. -
battery_discharge_power_maxfor the maximum battery discharge power. -
battery_charge_power_maxfor the maximum battery charge power. -
publish_prefixuse this key to pass a common prefix to all published data. This will add a prefix to the sensor name but also the forecast attribute keys within the sensor.
An MPC controller was introduced in v0.3.0. This is an informal/naive representation of an MPC controller. This can be used in combination with/as a replacement for the Dayahead Optimization.
An MPC controller performs the following actions:
- Set the prediction horizon and receding horizon parameters.
- Perform an optimization on the prediction horizon.
- Apply the first element of the obtained optimized control variables.
- Repeat at a relatively high frequency, ex: 5 min.
This is the receding horizon principle.
When applying this controller, the following runtimeparams should be defined:
-
prediction_horizonfor the MPC prediction horizon. Fix this at least 5 times the optimization time step. -
soc_initfor the initial value of the battery SOC for the current iteration of the MPC. -
soc_finalfor the final value of the battery SOC for the current iteration of the MPC. -
operating_hours_of_each_deferrable_loadfor the list of deferrable loads functioning hours. These values can decrease as the day advances to take into account receding horizon daily energy objectives for each deferrable load. -
start_timesteps_of_each_deferrable_loadfor the timestep from which each deferrable load is allowed to operate (if you don't want the deferrable load to use the whole optimization timewindow). If you specify a value of 0 (or negative), the deferrable load will be optimized as from the beginning of the complete prediction horizon window. -
end_timesteps_of_each_deferrable_loadfor the timestep before which each deferrable load should operate (if you don't want the deferrable load to use the whole optimization timewindow). If you specify a value of 0 (or negative), the deferrable load optimization window will extend up to the end of the prediction horizon window.
A correct call for an MPC optimization should look like this:
curl -i -H 'Content-Type:application/json' -X POST -d '{"pv_power_forecast":[0, 70, 141.22, 246.18, 513.5, 753.27, 1049.89, 1797.93, 1697.3, 3078.93], "prediction_horizon":10, "soc_init":0.5,"soc_final":0.6}' http://192.168.3.159:5000/action/naive-mpc-optimExample with :operating_hours_of_each_deferrable_load, start_timesteps_of_each_deferrable_load, end_timesteps_of_each_deferrable_load.
curl -i -H 'Content-Type:application/json' -X POST -d '{"pv_power_forecast":[0, 70, 141.22, 246.18, 513.5, 753.27, 1049.89, 1797.93, 1697.3, 3078.93], "prediction_horizon":10, "soc_init":0.5,"soc_final":0.6,'operating_hours_of_each_deferrable_load':[1,3],'start_timesteps_of_each_deferrable_load':[0,3],'end_timesteps_of_each_deferrable_load':[0,6]}' http://localhost:5000/action/naive-mpc-optimStarting in v0.4.0 a new machine learning forecaster class was introduced. This is intended to provide a new and alternative method to forecast your household consumption and use it when such forecast is needed to optimize your energy through the available strategies. Check the dedicated section in the documentation here: https://emhass.readthedocs.io/en/latest/mlforecaster.html
Pull requests are very much accepted on this project. For development, you can find some instructions here Development.
Some problems may arise from solver-related issues in the Pulp package. It was found that for arm64 architectures (ie. Raspberry Pi4, 64 bits) the default solver is not available. A workaround is to use another solver. The glpk solver is an option.
This can be controlled in the configuration file with parameters lp_solver and lp_solver_path. The options for lp_solver are: 'PULP_CBC_CMD', 'GLPK_CMD' and 'COIN_CMD'. If using 'COIN_CMD' as the solver you will need to provide the correct path to this solver in parameter lp_solver_path, ex: '/usr/bin/cbc'.
MIT License
Copyright (c) 2021-2023 David HERNANDEZ
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.