Home
- 数据库增量数据100%一致性的保证
- 为了100%数据一致性的保证,会在极少数时候出现极少数数据的重复,需要业务保证幂等操作
- 高实时性保证,同一机房延时控制在1s以内
- 面向数据库层面设计,而非数据库实例层面(与业务的隔离性保持相同)
- 高可用性,各个边界上都有ha方案的保证
- 高可运维性,提供接口与数据库管理系统进行联动,尽可能对业务保持透明

总体的数据库增量消费流程如下:
- Puma服务器伪装成Mysql Slave节点,连接上Mysql服务器,接收binlog日志
- Puma服务器解析,过滤并存储数据库的增量变化
- Puma客户端连接到Puma服务器,进行数据库增量的消费
Puma对于数据库的要求:
- Puma目前只支持Mysql数据库,后续会加入对于其他数据库的支持
- Mysql支持5.1 - 5.6版本,后续会对5.7版本进行支持
Puma对于数据库权限的要求:
- Select权限
- Replication Slave权限
- Replication Client权限
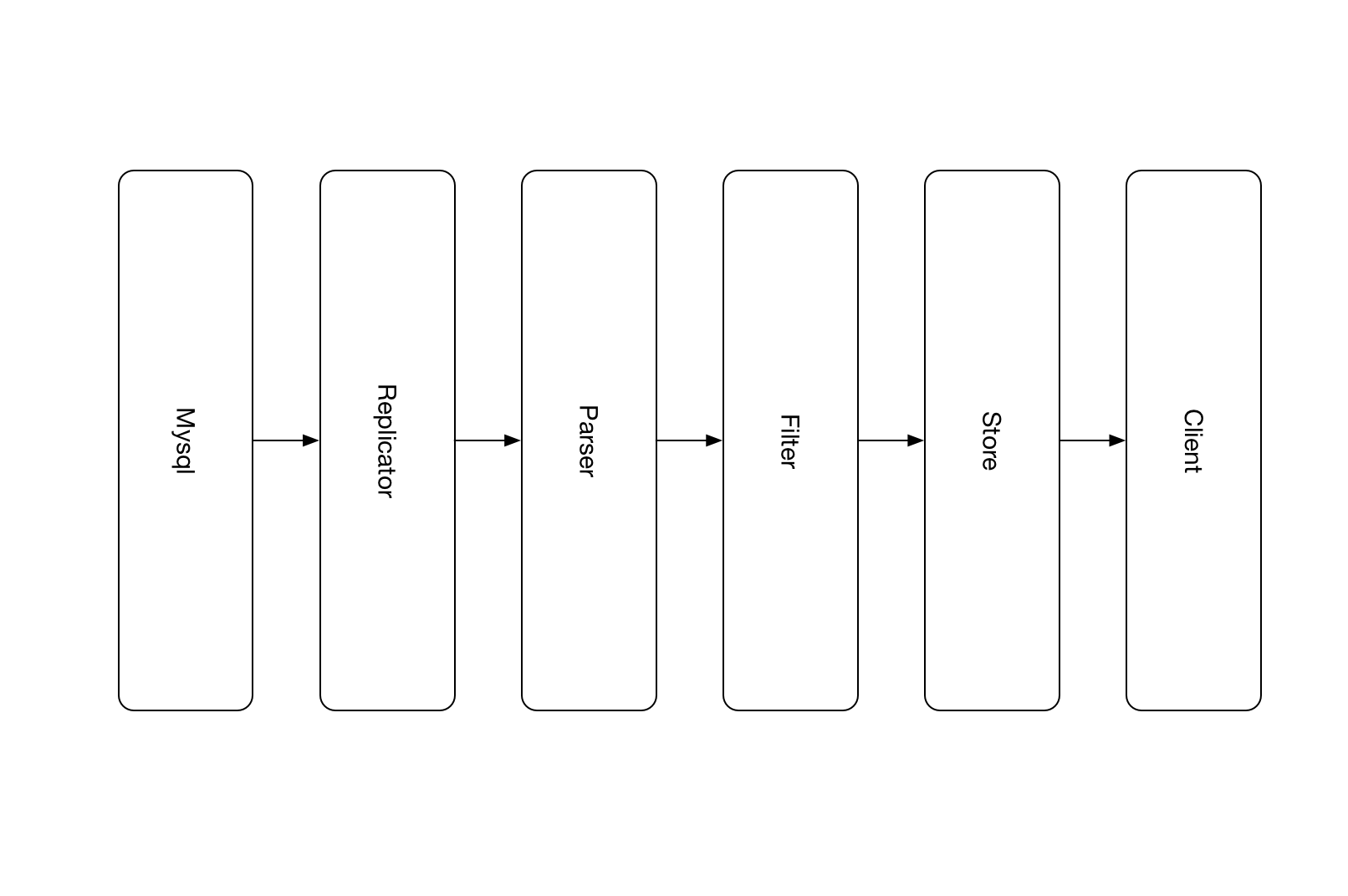
- Relicator,以socket通信连接上Mysql服务器,以主从同步的协议接受binlog日志
- Parser,设计初始参考了[https://github.com/whitesock/open-replicator](Open Replicator)
- Filter,过滤掉不关心的数据库和表,节约之后的存储空间
- Store,提供了内存和文件两种方式。实时业务走内存模式,文件模式则给客户端rollback提供了更大的时间选择度。
数据库集群在使用过程中,经常会出现机器宕机,拆库迁库等场景的出现。这些变化需要及时地反应到数据库监听的程序。 而Puma则提供了专门的接口,如果公司存在良好的数据库管理工具,通过实现这些接口,能够完成Puma自动感知这些变化的功能。
现在Puma主要涵盖到以下几个方面:
- 数据库某台服务器宕机或者延时被摘除
- 某个数据库被迁移到了另外一个实例上
以下是将来会支持的方面:
- 拆库的场景,比如a库拆成了a0-a99,Puma将能自动响应分库分表的变化
无法支持的场景:
- 数据库更改名字,比如从a库改为了b库
- 拆库更改了逻辑表名,比如a库拆成了b0-b99
Puma伪装成Slave,连接上Mysql服务器,但是Mysql服务器并不能无限制地拖任意台的Puma服务器,那么会产生一个问题:
- 业务需要数据库实例A上的库a当天的增量数据
- 业务需要数据库实例A上的库b 10天前的增量数据
- 业务需要数据库实例A上库c 20天前的增量数据
这样,对于实例A所在的Mysql服务器,就会有三台Puma服务器伪装成Slave连接上来,Puma对于这种场景进行了优化。 Puma服务器检测到实例A下有库a,库b,库c三个任务,且它们解析的进度已经接近,就会尝试将它们合并到一起。这样只有1台Puma服务器会连接到Mysql服务器。
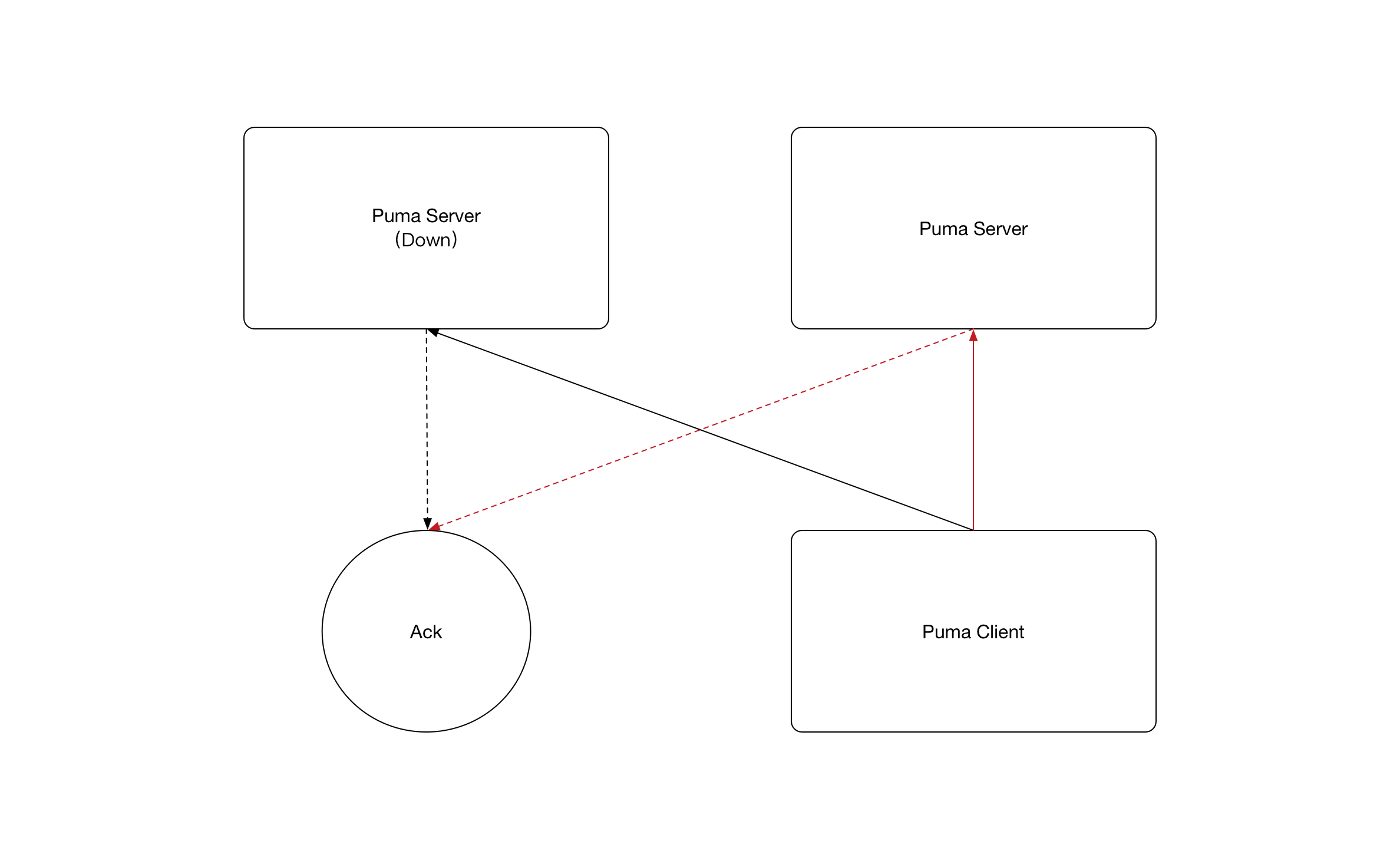 Puma服务器现在暂时只支持冷备的方案,即有多台Puma服务器同时监听一个数据库,如果一台Puma服务器宕机,则客户端连接到其他服务器继续消费。
Puma客户端的消费信息会被保存在持久化存储中,供所有的Puma服务器共享,完成客户端的切换消费。
Puma服务器现在暂时只支持冷备的方案,即有多台Puma服务器同时监听一个数据库,如果一台Puma服务器宕机,则客户端连接到其他服务器继续消费。
Puma客户端的消费信息会被保存在持久化存储中,供所有的Puma服务器共享,完成客户端的切换消费。
Puma客户端接口的设计以灵活性为主,能够为业务方提供最大的便利性。
- 提供批量获取功能,提升吞吐率
- 提供获取超时时间
- 提供确认接口,使客户端能够灵活地掌控确认增量数据的进度
- 提供回滚接口,使客户端能够灵活地回滚消费增量数据的进度
接口列举如下:
BinlogMessage get(int batchSize) throws PumaClientException;
BinlogMessage get(int batchSize, long timeout, TimeUnit timeUnit) throws PumaClientException;
BinlogMessage getWithAck(int batchSize) throws PumaClientException;
BinlogMessage getWithAck(int batchSize, long timeout, TimeUnit timeUnit) throws PumaClientException;
void ack(BinlogInfo binlogInfo) throws PumaClientException;
void rollback(BinlogInfo binlogInfo) throws PumaClientException;
Puma客户端与服务端之间的通信,选择了HTTP长轮询的方式。
- 当服务端没有数据提供时,连接处于等待状态
- 当服务端有数据时,立即返回数据
选择HTTP长轮询的方案有以下几个优点:
- HTTP协议,为今后开发多语言客户端提供了便利
- 长轮询比一般的客户端轮询节约了资源,减少了对于服务端的压力
Puma提供了针对业务级别的告警,对于客户端出现的消费延时,可能的宕机等情况都会发出告警 列举主要的告警数据:
- 客户端连接错误
- 客户端消费延迟
- 客户端长时间未连接上服务端
- 服务器解析数据库日志延迟
- 服务器解析出现错误
提供了以下的告警方式(针对点评)
- 邮件告警
- 微信告警
- 短信告警
提供了以下的告警策略
- 不告警
- 线性间隔告警
- 指数间隔告警
以下数据指标均在同一机房的环境下测得:
- 延迟1s以内
- 本地文件存储达到50000TPS以上
- 对于分库分表实时同步任务,10000TPS以上