离群点是在给定数据集中,与其他数据点显著不同的数据点。异常检测是找出数据中离群点(和大多数数据点显著不同的数据点)的过程。

孤立森林(Isolation Forest)于2008年由西瓜书作者周志华团队提出,凭借其线性的时间复杂度与优秀的准确率被广泛应用于工业界中结构化数据的异常检测。
孤立森林的基本理论基础有二:
- 异常数据占总样本量的比例很小;
- 异常点的特征值与正常点的差异很大。
总结孤立森林的基本原理:异常样本相较普通样本可以通过较少次数的随机特征分割被孤立出来。
例如:假设这批样本点有一个特征为年龄,孤立森林随机选择认为年龄>70为异常,年龄<=70为正常。此时相当于在样本空间,画出了一个超平面。接着孤立森林再选了一个特征为收入,认为收入>1w为异常,收入<=1W为正常,此时则又在样本空间画出了一个超平面......根据直觉,是不是分布稀疏位置的点可以通过较少次数的超平面划分被孤立出来,而分布密集位置的点需要更多次数的超平面划分才能被孤立。
如下图所示,处于分布密集位置的xi用了11个超平面才被孤立,处于分布稀疏位置的x0用了4个超平面即被孤立。

假设一棵树通过这个方法认为x0是离群点,这一结果是未必准确的,因为随机选特征与阈值存在着诸多偶然性。但用很多棵树进行这样的随机分割,其中绝大部分树的结论都是认为x0是离群点,那么这个结果就比较可信了。
随机采样一部分数据去构造,采样的数据不用太多,论文提到采样大小超过256效果就提升不大了,并且越大还会造成计算时间上的浪费,原因看下面两张图:
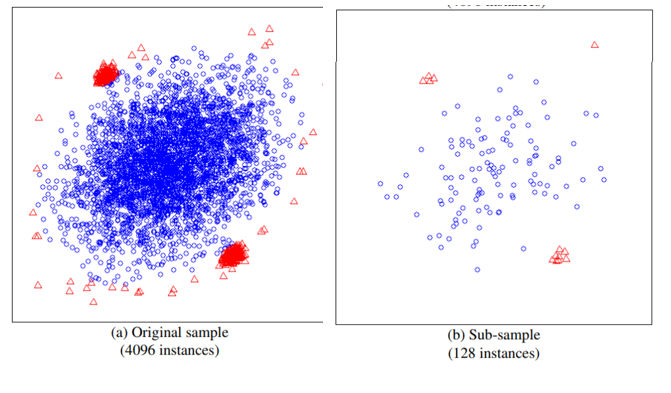
左边是原始数据,右边是采样数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之后,异常样本和正常样本可以明显的分开。
构建单棵树

1、从训练数据中随机选择 Ψ 个点作为子样本,放入一棵孤立树的根节点;
2、随机指定一个维度,在当前节点数据范围内,随机产生一个切割点 p —— 切割点产生于当前节点数据中指定维度的最大值与最小值之间;
3、此切割点的选取生成了一个超平面,将当前节点数据空间切分为2个子空间:把当前所选维度下小于 p 的点放在当前节点的左分支,把大于等于 p 的点放在当前节点的右分支;
4、在节点的左分支和右分支节点递归步骤 2、3,不断构造新的叶子节点,直到叶子节点上只有一个数据(无法再继续切割) 或树已经生长到了所设定的高度

1,从训练数据中随机选择 n 个点样本作为subsample。
2,根据样本数据容量迭代重复创建二叉搜索树 iTree,并将生成的 iTree 组成二叉树森林。
在构建孤立森林时,需要设定两个参数:树的数量t和每棵树采样样本大小的最大值Ψ 。
孤立森林通过引入异常值函数s(x,n)来衡量记录x 是否为异常点

其中,E(h(x))为x在多棵树中的路径长度的期望值,c(n)为一个包含n个样本的数据集,树的平均路径长度,用来标准化记录x的路径长度。
s(x,n)与E(h(x))的关系:
