NoOffense provides a smart and fast tool for detecting offensive language in Turkish. It utilizes transformers and mostly relies on the Hugging Face library, making it fully compatible with it.
The Overfit-GM team developed this package as a part of the Türkiye Açık Kaynak Platformu NLP challenge.
To install this package, simply run the following command in your Python environment:
pip install git+https://github.com/ertugrul-dmr/NoOffense.gitThis command will install the package directly from the GitHub repository.
Important: Depending on your environment you might need to install dependencies. You can use requirements.txt file shared in repository by following steps:
- Locate the directory where requirements.txt located
- Run: pip install -r requirements.txt
And you are all set!
PyTorch with CUDA
If you wish to use a GPU / CUDA, you must install PyTorch with the matching CUDA Version.
NoOffense is a versatile tool that supports multiple standard NLP tasks, with a particular focus on detecting offensive language in Turkish texts.
To getting started you can take a look at our notebook, and try it yourself online by clicking colab link:
| Notebook | Description | |
|---|---|---|
| Getting Started | A quick tour to library |
We have a Hugging Face space dedicated to pretrained models for this task. Our space contains a wide variety of models trained specifically for detecting offensive language in Turkish text. You can choose the model that best suits your needs from our selection:

Most of our models are based on the works of BertTurk, which we have adapted for detecting offensive language in Turkish text using domain adaptation techniques. We accomplished this by applying Whole Word Masking pretraining objective on a domain-specific corpus in a semi supervised fashion.
You can easily obtain predictions for a list of texts by using NoOffense as follows:
from nooffense import Predictor
# Predictor applies some text cleaning&preps internally
# In case of multiple trained models use list of model paths,
# and NoOffense will yield ensemble results internally
# you can use gpu support by setting device for faster inference
# you can replace the model_path argument from huggingface hub link or local model weight file path
clf = Predictor(model_path='Overfit-GM/bert-base-turkish-128k-cased-offensive', device='cuda')
predictions = clf.predict(['sen ne gerizekalısın ya'], progress_bar=False)
# Code above will return dict contains these keys:
# ['probas']: probabilities of each class
# ['predictions']: label encoding for each predicted class
# ['predicted_labels']: str label mappings for each class, INSULT, Racist etc.NoOffense also supports making predictions on Pandas dataframes:
It expects a column named "text" to make predictions.
from nooffense import DFPredictor
# you can replace the model_path argument from huggingface hub link or local model weight file path
clf = DFPredictor(model_path='Overfit-GM/bert-base-turkish-128k-cased-offensive', device='cpu')
predicted_df = clf.predict_df(df_path="path_to_your_csv_file", save_csv=False, progress_bar=True)
# Code above will return a copy of original dataframe with predictions.NoOffense models are trained in a self-supervised fashion using a large Turkish offensive text corpus. These models are then fine-tuned for text classification tasks. However, as a byproduct of our Masked Language Model training, you can also use it as a fill-mask pipe!
from nooffense import MaskPredictor
model = MaskPredictor("Overfit-GM/bert-base-turkish-128k-uncased-offensive-mlm")
model.mask_filler('sen tam bir [MASK]')
# output:
# [{'score': 0.26599952578544617,
# 'token': 127526,
# 'token_str': 'aptalsın',
# 'sequence': 'sen tam bir aptalsın'},
# {'score': 0.10496608912944794,
# 'token': 69461,
# 'token_str': 'ibne',
# 'sequence': 'sen tam bir ibne'},
# {'score': 0.10287725925445557,
# 'token': 19111,
# 'token_str': 'pislik',
# 'sequence': 'sen tam bir pislik'},
# {'score': 0.05552872270345688,
# 'token': 53442,
# 'token_str': 'kaltak',
# 'sequence': 'sen tam bir kaltak'}]As you can see, it fills the [MASK] token with pretty offensive content. To compare, let's use it with a casual NLP model. By the way, NoOffense also supports Hugging Face's model hub!
from nooffense import MaskPredictor
model = MaskPredictor("dbmdz/bert-base-turkish-128k-uncased")
model.mask_filler('sen tam bir [MASK]')
# output:
# [{'score': 0.1943783015012741,
# 'token': 18,
# 'token_str': '.',
# 'sequence': 'sen tam bir.'},
# {'score': 0.09647665172815323,
# 'token': 5,
# 'token_str': '!',
# 'sequence': 'sen tam bir!'},
# {'score': 0.030896930024027824,
# 'token': 2289,
# 'token_str': 'sen',
# 'sequence': 'sen tam bir sen'},
# {'score': 0.024956168606877327,
# 'token': 3191,
# 'token_str': 'sey',
# 'sequence': 'sen tam bir sey'}]As you can see, the casual NLP model produces much less offensive content than NoOffense.
Sometimes, you need to encode your sentences in vector form to use them in different tasks than classification. With NoOffense, you can get sentence embeddings for offensive language inputs and use them for downstream tasks like sentence similarity, retrieval, and ranking, etc.
from nooffense import SentenceEncoder
model = SentenceEncoder("Overfit-GM/electra-base-turkish-mc4-cased-discriminator-offensive")
model.encode(['input_text_here'])
# The code above will resuls mxn matrix where m is number of sentences given and n is dimension of encoder model.Speaking of sentence similarity, NoOffense library has method that helps you find most similar sentences using cosine similarity based on SentenceEncodings:
from nooffense import SentenceEncoder
# you can replace the model_path argument from huggingface hub link or local model weight file path
model = SentenceEncoder("Overfit-GM/electra-base-turkish-mc4-cased-discriminator-offensive")
model.find_most_similar("bir küfürlü içerik", ["text1", "text2", ..., "text_n"])The code above will result sorted dictionary starting with most similar text given from list of strings.
The results below were collected by using out of fold predictions, for evaluation we used 5 folds stratified by targets. The evaluation results below were generated using 5-fold stratified out-of-fold predictions. We provide both multiclass and binary evaluation metrics.
The multiclass evaluation results show the precision, recall, and F1-score for each class, as well as the overall macro and weighted average metrics. These are final results of model ensembling.
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| INSULT | 0.94 | 0.95 | 0.94 | 2393 |
| OTHER | 0.98 | 0.97 | 0.98 | 3584 |
| PROFANITY | 0.97 | 0.97 | 0.97 | 2376 |
| RACIST | 0.98 | 0.98 | 0.98 | 2033 |
| SEXIST | 0.98 | 0.98 | 0.98 | 2081 |
| accuracy | 0.97 | 12467 | ||
| macro avg | 0.97 | 0.97 | 0.97 | 12467 |
| weighted avg | 0.97 | 0.97 | 0.97 | 12467 |
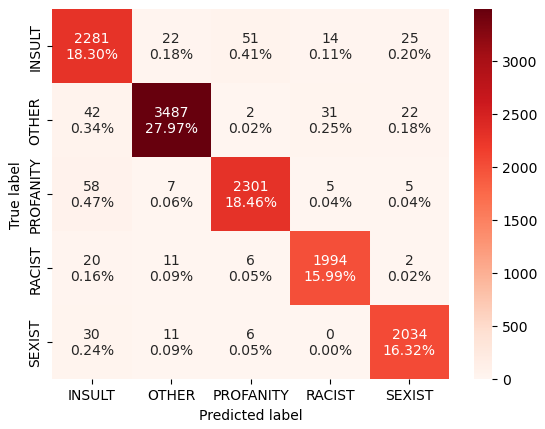
Without ensembling the model results are like shown below. You can also reach the model weights from there:
| Transformer Architecture | F-1 Macro Score |
|---|---|
| bert-base-turkish-cased | 0.9617 |
| bert-base-turkish-uncased | 0.9560 |
| bert-base-turkish-128k-cased | 0.9596 |
| bert-base-turkish-128k-uncased | 0.9548 |
| convbert-base-turkish-mc4-cased | 0.9609 |
| convbert-base-turkish-mc4-uncased | 0.9537 |
| convbert-base-turkish-cased | 0.9602 |
| distilbert-base-turkish-cased | 0.9503 |
| electra-base-turkish-cased-discriminator | 0.9620 |
| electra-base-turkish-mc4-cased-discriminator | 0.9603 |
| electra-base-turkish-mc4-uncased-discriminator | 0.9551 |
| xlm-roberta-large | 0.9529 |
| microsoft/mdeberta-v3-base | 0.9517 |
The binary evaluation results show the precision, recall, and F1-score for two classes: 'offensive' and 'not_offensive'. These are final results of model ensembling.
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| not_offensive | 0.98 | 0.97 | 0.98 | 3584 |
| offensive | 0.99 | 0.99 | 0.99 | 8883 |
| accuracy | 0.99 | 12467 | ||
| macro avg | 0.99 | 0.98 | 0.98 | 12467 |
| weighted avg | 0.99 | 0.99 | 0.99 | 12467 |

Team Members: