Un web service es un sistema de software diseñado para admitir la interacción interoperable de varias máquinas entre si a través de una red que puede ser descripta, publicada, localizada e invocada desde cualquier plataforma y en cualquier lenguaje de programación. El funcionamiento detrás de las funcionalidades que entregan los servicios web es algo desconocido para la máquina que los ocupa, es por esto que quien quiera recibir los datos solo necesita usar el servicio y punto.
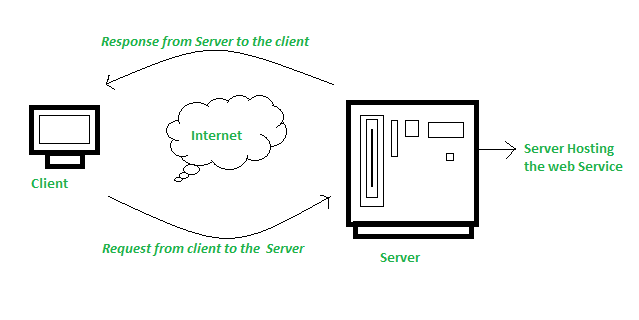
El proceso que sigue un web service para funcionar es muy sencillo y se trata únicamente de un servicio de interacción y comunicación entre distintas aplicaciones a través de Internet.
Los webs services tienen una interfaz descrita en un formato procesable por él computador. Los sistemas interactúan entre si utilizando mensajes SOAP, normalmente transmitidos mediante HTTP con una serialización XML junto con otros estándares relacionados con la web.
El proceso de funcionamiento se puede describir de la siguiente manera:
-
El proveedor de servicios envía un archivo WSDL con la definición del servicio web al corredor de servicios. Con este archivo, el corredor de servicios es capaz de saber qué funciones será posible ejecutar en el servidor a través del web service.
-
Después, el solicitante del servicio se comunica con el corredor de servicios para averiguar quién es el proveedor. De esta forma, el solicitante puede comunicarse con el proveedor de servicios para enviar una solicitud SOAP en forma de mensaje HTTP al servidor.
-
Una vez que esto sucede, el web service interpreta el contenido de la solicitud y el proveedor de servicios valida la petición del solicitante. Posteriormente, el web service envía los datos de respuesta necesarios en formato XML , usando nuevamente el protocolo SOAP y HTTP.
-
Finalmente, el fichero XML, enviado por el proveedor de servicios, es validado una vez más por el solicitante de los servicios, utilizando un fichero XSD para interpretarlo. La información resultante se envía al software y estará lista para ser procesada.
Algunos ejemplos que podemos encontrar son:
-
Microsoft .NET
-
WebLogic
-
WebSphere
-
Java Web Services Development Pack (JWSDP)
Corresponden a una serie de acciones que deben ejecutarse exitosamente en una base de datos. Si una de las operaciones falla, todos los pasos deben retroceder a su estado anterior para que la aplicación quede en su estado estable antiguo.
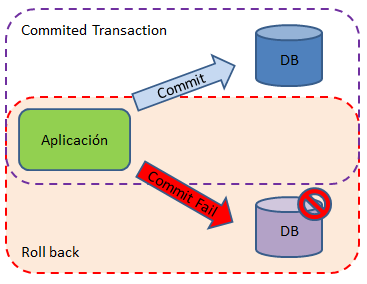
Las transacciones poseen las siguientes propiedades:
- Atomicidad: La transacción ocurre completamente o no ocurre.
- Consistencia: La base de datos debe ser consistente (es decir, el cambio solo ocurre si el nuevo estado es válido) antes y después de la transacción
- Aislamiento: Ocurren múltiples transacciones independientemente sin interferencia
- Durabilidad: Los cambios de una transacción exitosa ocurren incluso si el sistema falla. Dentro de una transacción, un evento es un cambio de estado que le ocurre a una entidad, y un comando encapsula toda la información necesaria para ejecutar una acción o gatillar un evento futuro.
Las API (Application Programming Interface), son un conjunto de funciones y procedimientos que permiten a dos softwares los cuales pueden estar programados en lenguajes diferentes, comunicarse entre sí.
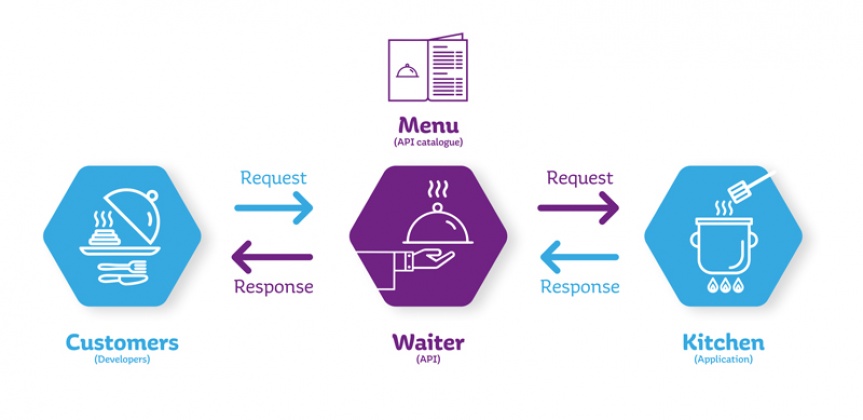
"Un cliente en un restaurante llama al mesero y le indica su orden, el mesero va a la cocina y transcurridos unos minutos, el cliente recibe los platillos que solicitó. En este ejemplo el cliente no tiene interés en lo que ocurre en la cocina o en la preparación específica de cada plato, sólo en recibir la comida que ordenó. Por otro lado, el mesero sería la API, un intermediario entre el cliente y los cocineros".
De manera similar, cuando una primera aplicación (o página web) solicita datos a una segunda aplicación, no es necesario que la primera conozca la manera en que se procesa su consulta, solo necesita obtener los datos que solicito.
Usualmente las comunicaciones entre aplicaciones que utilizan API’s se establecen entre un cliente y un servidor , a través de un protocolo (SOAP, REST, GraphQL), en donde las operaciones básicas permitidas son Create, Read, Update, Delete (CRUD).
Los microservicios son tanto un estilo de arquitectura como un modo de programar software, en donde aplicaciones se dividen en sus elementos más pequeños e independientes entre sí. A diferencia del enfoque tradicional y monolítico de las aplicaciones, en el que todo se compila en una sola pieza, los microservicios son elementos independientes que funcionan en conjunto para llevar a cabo las mismas tareas. Cada uno de esos elementos o procesos es un microservicio.
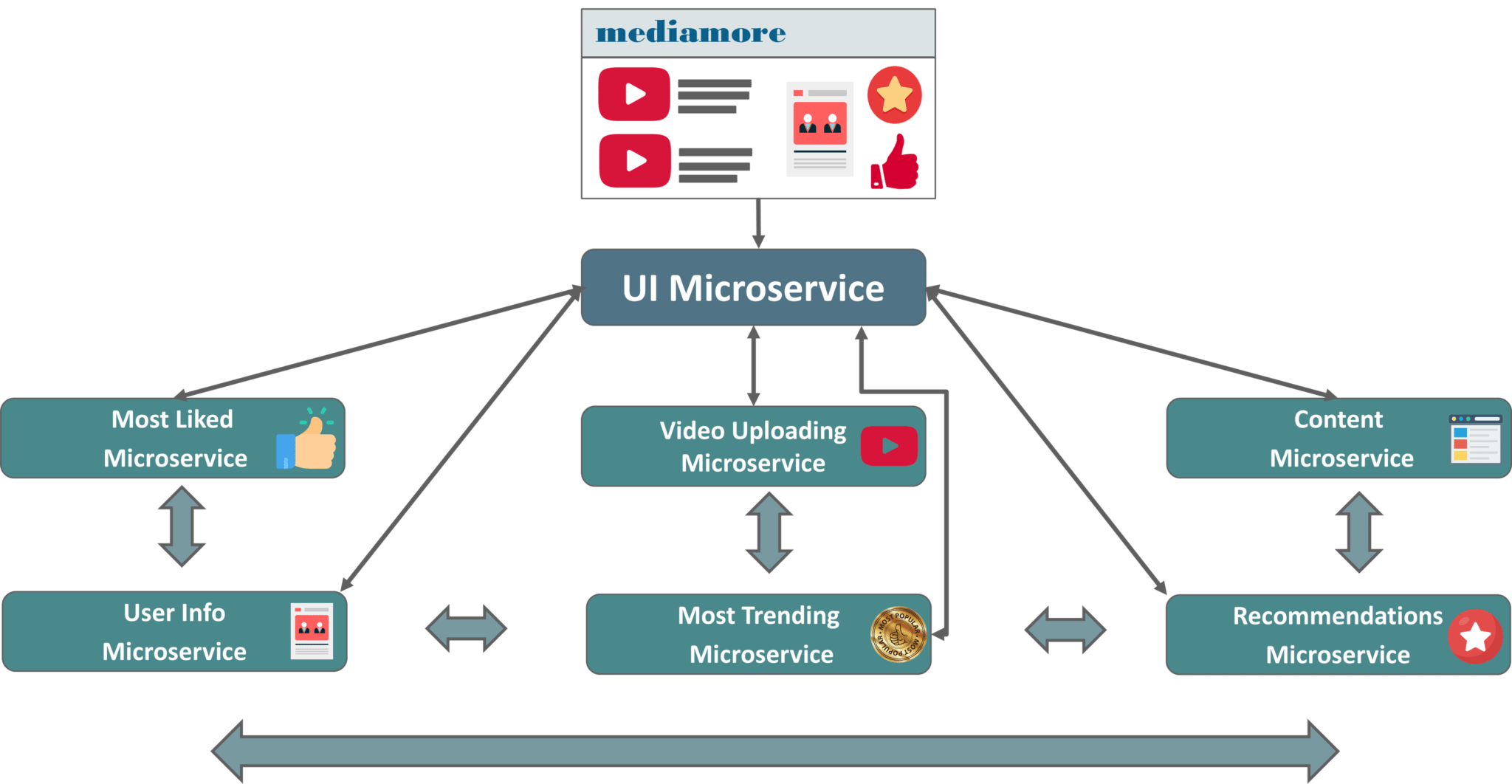
Al mismo tiempo, ya que cada servicio es un código más pequeño y aislado, nos permite la mejor detección de errores.
Por otro lado, algunos de los problemas que surgen son:
- La complejidad de la aplicación al tener varias partes en movimiento al mismo tiempo.
- Falta de control de cada equipo, ya que pueden utilizar distintas herramientas para realizar sus tareas.
- E incluso puede haber congestión de redes si los servicios realizan muchas conexiones hacia las API.
Una arquitectura monolítica corresponde a una arquitectura donde todos los procesos están estrechamente asociados y se ejecutan como un solo servicio.
| Ventajas ✅ | Desventajas ❌ |
|---|---|
| Son más fáciles de desarrollar y desplegar, pues los componentes están centralizados | Agregar o mejorar las características se vuelve más complejo a medida que crece la base del código |
| Más fáciles de testear, ya que hay solo un repositorio de código | Aumentan el riesgo de la disponibilidad de la aplicación porque muchos procesos dependientes y estrechamente vinculados aumentan el impacto del error de un proceso |
| No se requieren, o se requieren menos habilidades especializadas | Difícil de escalar, ya que para escalar una aplicación monolítica, esto debe hacerse todo a la vez añadiendo recursos de cómputo adicionales, lo cual es caro |
Una arquitectura de microservicios corresponde a una arquitectura donde la aplicación se crea con componentes independientes que ejecutan cada proceso de la aplicación como un servicio, los que se comunican a través de una interfaz bien definida mediante APIs ligeras. Los microservicios son autónomos, es decir, cada servicio componente en una arquitectura de microservicios se puede desarrollar, implementar, operar y escalar sin afectar el funcionamiento de otros servicios, sin tener que compartir código o implementaciones con otros servicios; y especializados, es decir, cada servicios está diseñado para un conjunto de capacidades y se enfoca en resolver un problema específico, y si el servicio se vuelve más complejo, se puede dividir en servicios más pequeños.
| Ventajas ✅ | Desventajas ❌ |
|---|---|
| Debido a que se ejecutan de forma independiente, cada servicio se puede actualizar, implementar y escalar para satisfacer la demanda de funciones de la aplicación | La complejidad es más alta, debido a la manera en que los microservicios están conectados entre sí |
| Los equipos pueden fácilmente añadir funcionalidades y nuevas tecnologías a una arquitectura de microservicios a medida que se necesite | Requiere habilidades y conocimientos especializados, los que no todos los desarrolladores poseen |
| La seguridad y el testeo están distribuidos, ya que cada módulo tiene sus propias vulnerabilidades y bugs, lo cual toma más tiempo de debuggear |
Es un patrón de manejo de fallos que ayuda a establecer la consistencia en aplicaciones distribuidas, y coordina transacciones entre múltiples microservicios para mantener la consistencia de datos. Una saga es una secuencia de transacciones que actualizan cada servicio y publican un mensaje o evento para gatillar el siguiente paso de a transacción. Si un paso falla, la saga ejecuta transacciones compensadoras que contrarrestan las transacciones anteriores.
Un microservicio publica un evento por cada transacción, y la siguiente transacción está basada inicialmente en el resultado del evento. Puede tomar dos diferentes caminos, dependiendo del éxito o fracaso de la transacción.
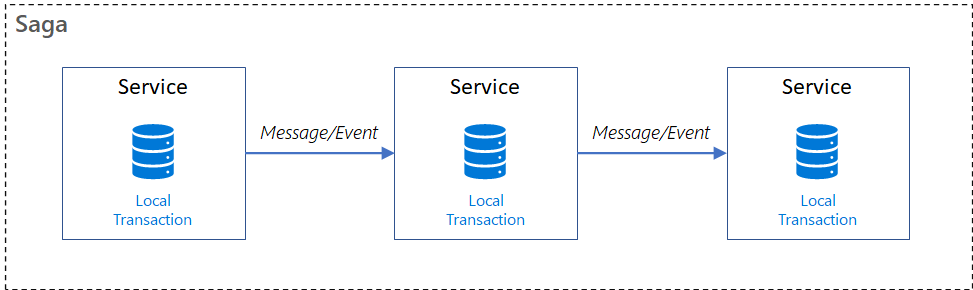
El patrón saga es útil si:
- La aplicación requiere mantener consistencia de datos a través de múltiples microservicios sin acoplamiento estrecho
- Hay transacciones longevas y no se quieren bloquear otros microservicios si un microservicio corre por un largo tiempo
- Se necesita retroceder si una operación falla en la secuencia.
El patrón saga es difícil de debuggear e implementar y su complejidad aumenta con el número de microservicios.
Es un protocolo de commit atómico y un algoritmo distribuido que coordina todos los procesos que participan en una transacción atómica distribuida para hacer commit o abortar (retroceder) la transacción. Corresponde a un set de acciones usadas para asegurarse de que un programa hace todos los cambios o no. Las fases son:
- Fase 1: Cada gestor de recursos se prepara para hacer commit de los cambios. La decisión de hacer o no commit depende de las respuestas de todos los gestores de recursos. Una vez que se hace una decisión de commit, se considera que se ha hecho commit de los cambios en la aplicación. Si la aplicación o algún gestor de recursos falla luego de que se toma la decisión, los cambios en la aplicación se harán luego del reinicio. Pero si antes de tomarse la decisión hay algún fallo, se revierten los cambios durante el reinicio.
- Fase 2: El gestor de recursos hace commit o revierte los cambios.

Cada microservicio debe formar parte de la aplicación y a la vez ser autónomo con todas las ventajas y los desafíos que eso conlleva, ¿Cómo podemos identificar estos límites?.
El objetivo al identificar los límites del modelo y el tamaño de cada microservicio no es llegar a la separación más específica posible, sino que debería ser llegar a la separación más significativa basada en el conocimiento del dominio. La idea es que cada microservicio sea lo más aislado posible , que este permita trabajar sin tener que estar solicitando recursos de otros microservicios (en lo posible).
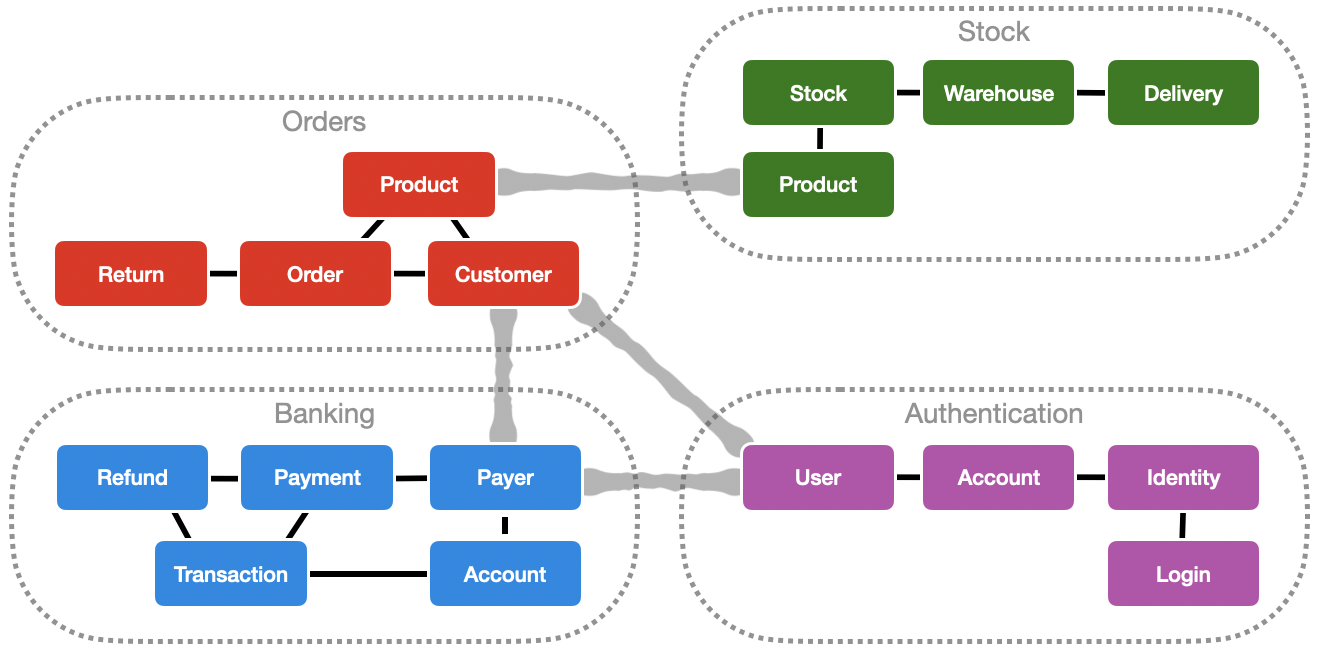
Un segundo desafío es implementar consultas que recuperen datos de varios microservicios, evitando al mismo tiempo un exceso de comunicación entre los microservicios y las aplicaciones cliente remotas. Si la aplicación llega a tener muchos microservicios, administrar tantos puntos de conexión desde las apps clientes puede ser un caos. Las soluciones más comunes son las siguientes:
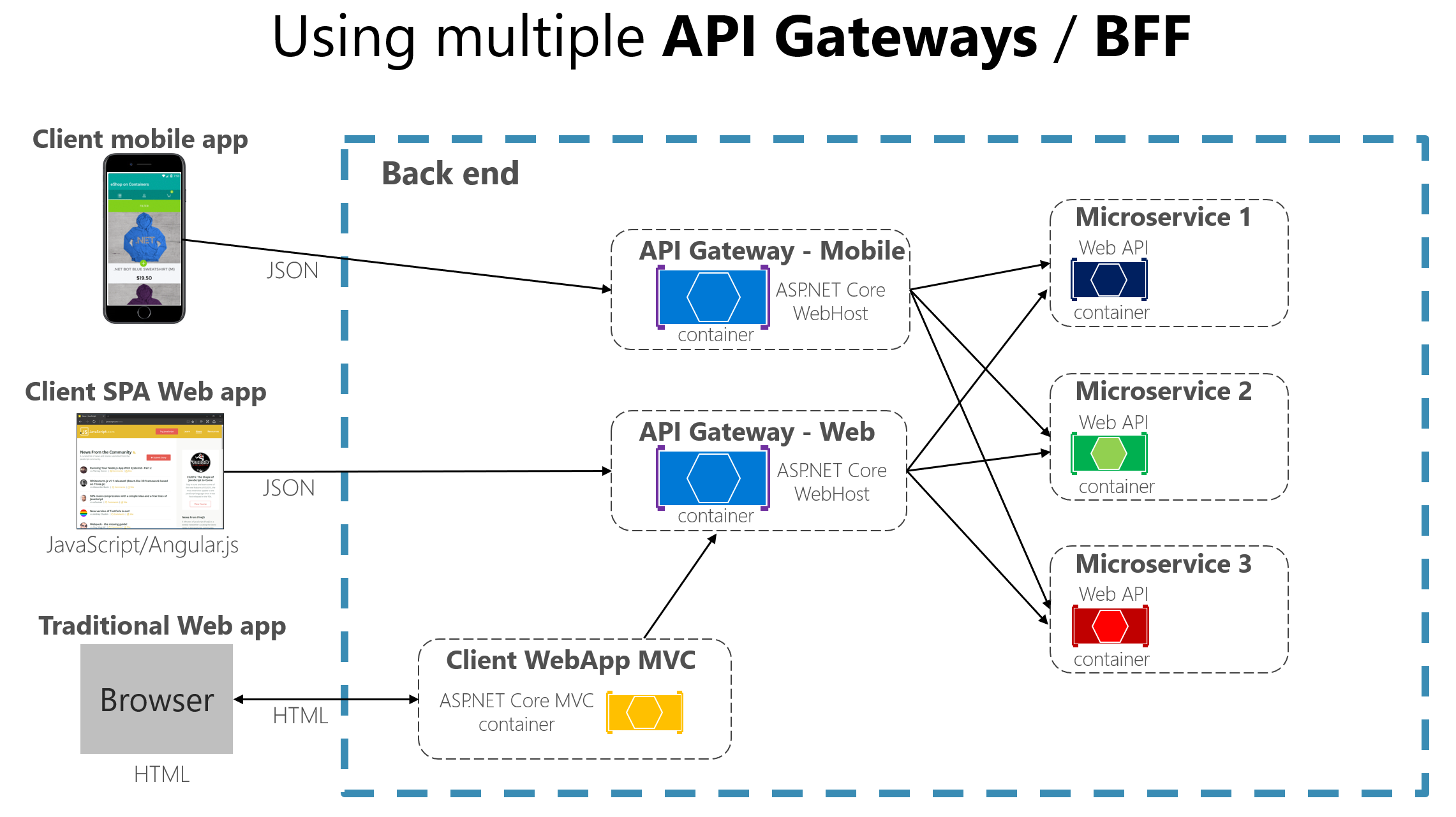
- Puerta de enlace de API: Se trata de un nivel intermedio que actúa como punto de entrada único para un grupo de microservicios. No es buena idea tener una sola API que sirva como puerta para todos los microservicios, ya que se estaría replicando el comportamiento de una aplicación monolítica, por el contrario, conviene agrupar los microservicios en varias API dependiendo del propósito.
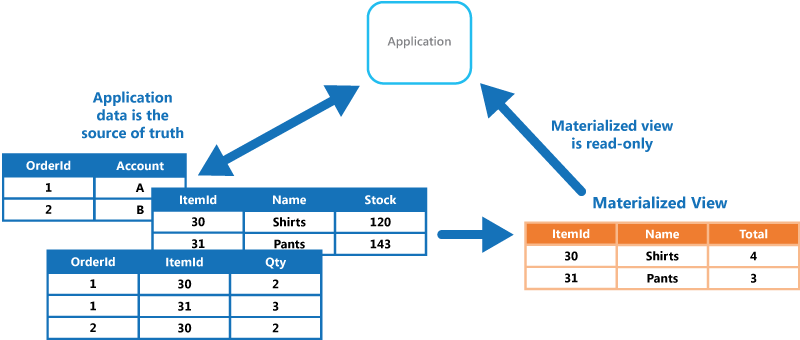
- Patrón de vista materializada: Útil en aquellos casos en que la información que se requiere no se encuentra en un formato adecuado para ser visualizado o cuando resulta difícil generar o esperar la respuesta de una consulta. Se trata de tener previamente generadas tablas con los datos de las consultas más frecuentes para ahorrar tiempo.