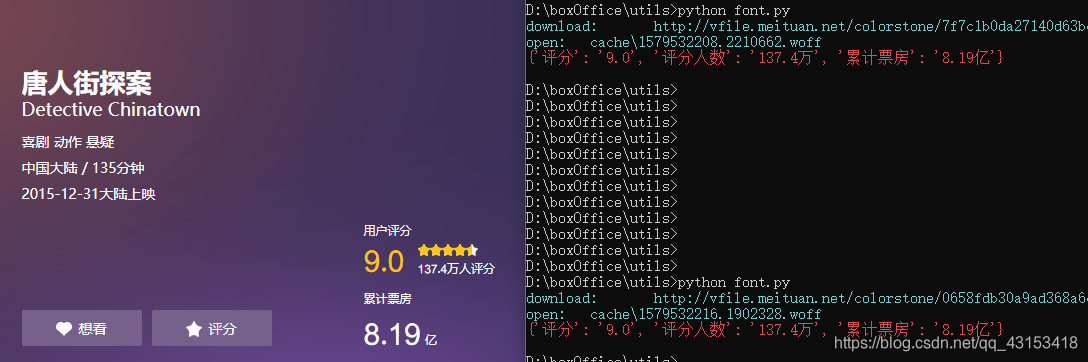
首先下载一个字体文件,手动写个 unicode-数字 对应关系。每次打开页面时,下载页面中的字体文件,获取页面字体的坐标数组,使用欧式距离判断字体相似度。相似度最高的则是最有可能的字体,目前做 100 次爬取,没有看到误差。
Make sure you have installed the modules in the file 'requirements.txt'. Or you can use the following statement to install.
确保你已经安装 requirements.txt 文件里的模块。如果没有安装,请使用下面的语句安装:
pip install -r requirements.txt
import requests
import font
from lxml import etree
# 构建头部,获取页面内容
url = 'https://maoyan.com/films/247300'
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
resp = requests.get(url, headers=header).text
# 获取编码字典,并替换页面中的编码
font_dict = font.getFont(resp)
for key in font_dict.keys():
resp = resp.replace(key, font_dict[key])
# 下面是额外内容:
# 获取评分、票房等数据
body = etree.HTML(resp)
mark_info = body.xpath('//div[@class="movie-index"]/div')
mark = mark_info[0].xpath('string(.)').replace(' ', '')
mark = re.sub(r'\n+', '|', mark)[1:-1].split('|')
if len(mark) < 2:
myMark = ''
myNum = ''
else:
myMark = mark[0]
myNum = mark[1][:-3]
boxOffice = mark_info[1].xpath('string(.)').replace(' ', '').replace('\n', '')
movie = {}
movie['评分'] = myMark
movie['评分人数'] = myNum
movie['累计票房'] = boxOffice
print(movie)