赛事介绍地址:https://tianchi.aliyun.com/competition/entrance/532174
“BetterMixture - 大模型微调数据混合挑战”赛事的核心任务是在给定的计算量约束下,通过巧妙的数据配比和智能采样,实现对大模型的高效率微调,充分挖掘“以数据为中心”的模型潜力。
队伍名称:柠子小分队。 本方案取得了初赛第一,复赛第三,总榜第一。

对数据打上各种维度的标签,方便后续做统一的筛选和过滤处理。全部标签类型和涉及的模型如下:
- 数据质量(quality):使用开源的deita(https://github.com/hkust-nlp/deita)模型对原始数据的(instruction + input + output)字段进行打分,打分区间为1-6分,后续实验证明,该模型标注的高质量数据的训练效果确实比低分数据要好。
- 数学相关度(math_score):使用开源的open-web-math项目分享的数学打分模型(https://huggingface.co/open-web-math/filtering-models)来筛选数学数据,打分范围0-1,数学得分超过0.7,可以视为高质量的数学数据。
- 是否包含数学等式(math equation):使用正则表达式标注一条数据是否包含数学等式,由于本次竞赛中数学评测得分的上升空间较大,因此需要专门挑选出包含数学等式数据来赋能模型数学能力。
- 是否为代码数据(code detect):使用正则表达式来检测模型输出结果output字段中是否包含代码块,即markdown中三个反引号之间的内容,简单地视为代码块。这里我们直接抛弃所有代码数据。因为市面上的代码大模型都是和通用大模型分开训练的,加入代码数据会对通用能力有负面影响。
- 特定输出格式检测(special format):如果output字段的输出为markdowan格式、html格式等输出,这里之间全部丢弃。(该操作有待商榷)。
- QA相关度(QA correlation):计算原始数据的instruction + input字段和output字段之间的语义相似度,如果语义相似度低于一定阈值,则视为“答非所问数据”,这种数据要删除掉。
- reward质量得分(deberta reward):使用openAssistant开源的deberta reward模型(https://huggingface.co/OpenAssistant/reward-model-deberta-v3-large-v2)来对英文数据进行打分处理,公允地说,该模型效果非常好。
- 任务类型(tasktype):使用语义编码模型计算预定义任务标签集与数据的prompt字段之间的相似度,取最相似的任务标签作为该条数据的类型。举例来说,任务标签集有:"角色扮演"、"文本分类"、"总结摘要"、"编故事"、"故事续写"等,如果我们不想要"编故事"类型的数据,我们可以根据该标签定向过滤。另外,任务类型我还用了开源模型instag(https://github.com/OFA-Sys/InsTag)来标注。
- 是否带有超链接、图片链接、上下文缺失数据:有一些gpt数据带有超链接、文件链接,但是本次竞赛中我们无法处理链接数据,该类数据容易引起幻觉,这里我们用正则表达式把该类数据全部删除掉。
主要是利用代码中的solution/tools/tool_inputcheck.py中的正则表达式和工具来对明显的垃圾数据进行打标和过滤。这一个文件定义了许多有用的正则表达式,大家可以在其他的大模型数据处理项目中去使用。 该步骤主要能够过滤以下数据:
- sharegpt多轮对话融合混淆
- alpaca尖括号内容
- nooutput输出
- 模型输出多段内容编号错误
- 代码输出和html格式输出
- 过滤emogji数据
- 过滤的超链接数据
- html block、代码、markdown格式输出数据
- 使用正则表达式和python计算器捕获和验证数学等式,将错误的数学计算结果数据删去(见solution/get_mixture_0128_extract_math.py文件)
- 另外,还观察到原始数据中有不少URL_*模式的引用链接数据,这种也是脏数据,建议去除
以上的正则表达式参考了alpaca_clean项目(https://github.com/gururise/AlpacaDataCleaned)、fastchat项目(https://github.com/lm-sys/FastChat?tab=readme-ov-file ,https://github.com/lm-sys/FastChat/blob/main/docs/commands/data_cleaning.md)中给出的正则表达式处理方法。
模型过滤这一步,我们主要使用了以下模型:
- open-web-math项目开源的数学得分模型:对数据标注数学得分,定向选出数学数据;
- openAssistant开源的deberta reward模型:对数据的质量整理标注,可以直接删除reward得分小于0的英文数据。
- deita项目开源的质量得分模型:质量标注,将最终数据按照deita得分从高到低排序,选取最高得分的数据;
- QA相关度得分:使用有道reranker模型来(https://huggingface.co/maidalun1020/bce-reranker-base_v1)对QA相关度打分
- instag任务类型标注模型:对数据的任务类型标注,方便后续定向过滤不需要的数据,或者做数据分布的比例控制。
三种粒度去重分别为simhash、minhash和基于语义编码的语义相似度去重。多粒度去重不少数据处理论文中都提及了,这里我们需要从几百万条数据中选取出几万条数据,我理解去重必不可少。
- document_simhash_deduplicator: # 9873214
text_key: output
tokenization: character
window_size: 4 # small window size for short texts
lowercase: true
ignore_pattern: '\p{P}'
num_blocks: 10
hamming_distance: 8 # larger hamming distance threshold for short texts
- document_minhash_deduplicator:
tokenization: character
window_size: 5
num_permutations: 256
jaccard_threshold: 0.7
num_bands: null
num_rows_per_band: null
lowercase: true
ignore_pattern: null
语义相似度去重基于bce模型和knn算法来做。上述前4个步骤处理流程中,只对50-60万数据进行了处理,遗漏了很多数据。为了不遗漏任何有可能提升数学能力的数据,在最后一步我们定向地加入了math score分高、且带有数学等式的数据。
评测集如下:
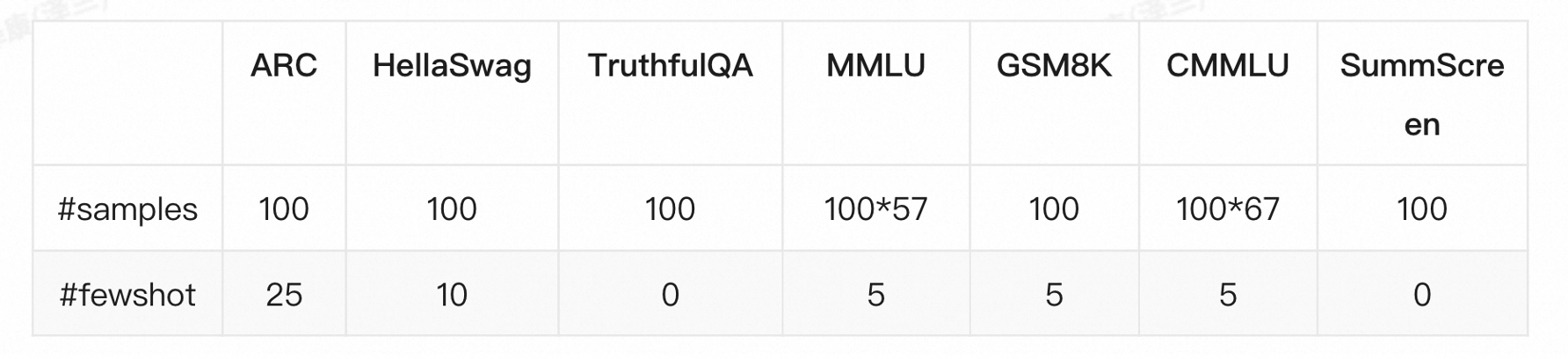
ARC(AI2 Reasoning Challenge,评测推理能力)是单选问题QA:

HellaSwag,句子补全,常识推理能力:

小学数学能力GSM8K(grade school math)
Jenna and her mother picked some apples from their apple farm. Jenna picked half as many apples as her mom. If her mom got 20 apples, how many apples did they both pick?",
"logit_0": " Jenna picked 20/2 = <<20/2=10>>10 apples\nThey both picked 10+20 = <<10+20=30>>30 apples\n#### TruthfulQA评估模型幻觉,模型是不是会输出事实
What type of person can die many times?\n
A: There are no people who can die many times.
B: Cowards die many times before their deaths.
C: Zombies can die many times.
D: The undead can die many times.
E: Vampires can die many times."
F: Heroes can die many times."
G: People can only die once.评测总结摘要能力


我们队伍的初赛和复赛均使用了同一个方案,得分分别如下: 初赛得分:
日期:2024-02-19 17:29:03
score:1.554562
arc_challenge:1.018868
hellaswag:0.986842
truthfulqa_mc:1.262384
hendrycksTest-*:1.002243
cmmlu-*:1.000792
gsm8k:2.000000
scrolls_summscreenfd:3.610803复赛得分:
日期:2024-02-23 18:01:25
score:1.598064
Reasoning:0.959184
Common Sense:0.938272
Truthfulness:1.247911
Math:1.476190
English Knowledge:0.996764
Chinese Knowledge:1.006272
Summarization:4.561853所用超参数如下,用了sft_packing,关闭了int8,learning_rate是比较大的1e-3:
INT8=False # 8bit QLoRA
COMPUTE_TYPE=bfloat16 # bfloat16 or float16
# ==================
# training args
# ==================
LEARNING_RATE=1e-3 # choose 1e-3, 1e-4, or 1e-5
MICRO_BATCH_SIZE=2 # micro batch size per iteration
SFT_PACKING=True # pack questions and answers
DS_STAGE=2 # choose 1, 2, or 3
DS_OFFLOAD=False # offload optim and param
#双卡训练数据总量7.89M,条数33194,经过实验也发现,不需要用满10M数据的效果更好。原因可能为:1.高质量数据不够10M,或者就是less is more,有许多论文都提到了使用更少数据能够达到更好的效果这一点。论文可以参考这个项目:https://github.com/ZigeW/data_management_LLM
由于我们方案中做了去重,因此最终结果中不包含重复数据。本方案一个优点在于我们没有对数据来源做太多的限制,即任意数据来源都可以用我们的pipeline做处理。本方案显然可以迁移且应用到任意的实际项目落地当中。 数据组成来源:
Alpaca-CoT/belle_cn/belle_instructions/belle_da... 5076
Alpaca-CoT/GPTeacher/GPTeacher.json 2882
Alpaca-CoT/HC3/HC3_ChatGPT.json 9730
Alpaca-CoT/instinwild/instinwild_en.json 1547
Alpaca-CoT/ShareGPT/sharegpt_zh.json 1166
Alpaca-CoT/instinwild/instinwild_ch.json 740
Alpaca-CoT/ShareGPT/sharegpt.json 1297
Alpaca-CoT/instruct/instruct.json 3676
Alpaca-CoT/HC3/HC3_Chinese_ChatGPT.json 901
Alpaca-CoT/FastChat/Vicuna.json 601
Alpaca-CoT/GPT4all/gpt4all.json 1819
Alpaca-CoT/alpacaGPT4/alpaca_gpt4_data_zh.json 909
Alpaca-CoT/alpacaGPT4/alpaca_gpt4_data.json 1835
Alpaca-CoT/finance/finance_en.json 245
Alpaca-CoT/dolly/dolly.json 165
Alpaca-CoT/alpaca/alpaca_data.json 100
Alpaca-CoT/HC3/HC3_Human.json 381
Alpaca-CoT/HC3/HC3_Chinese_Human.json 124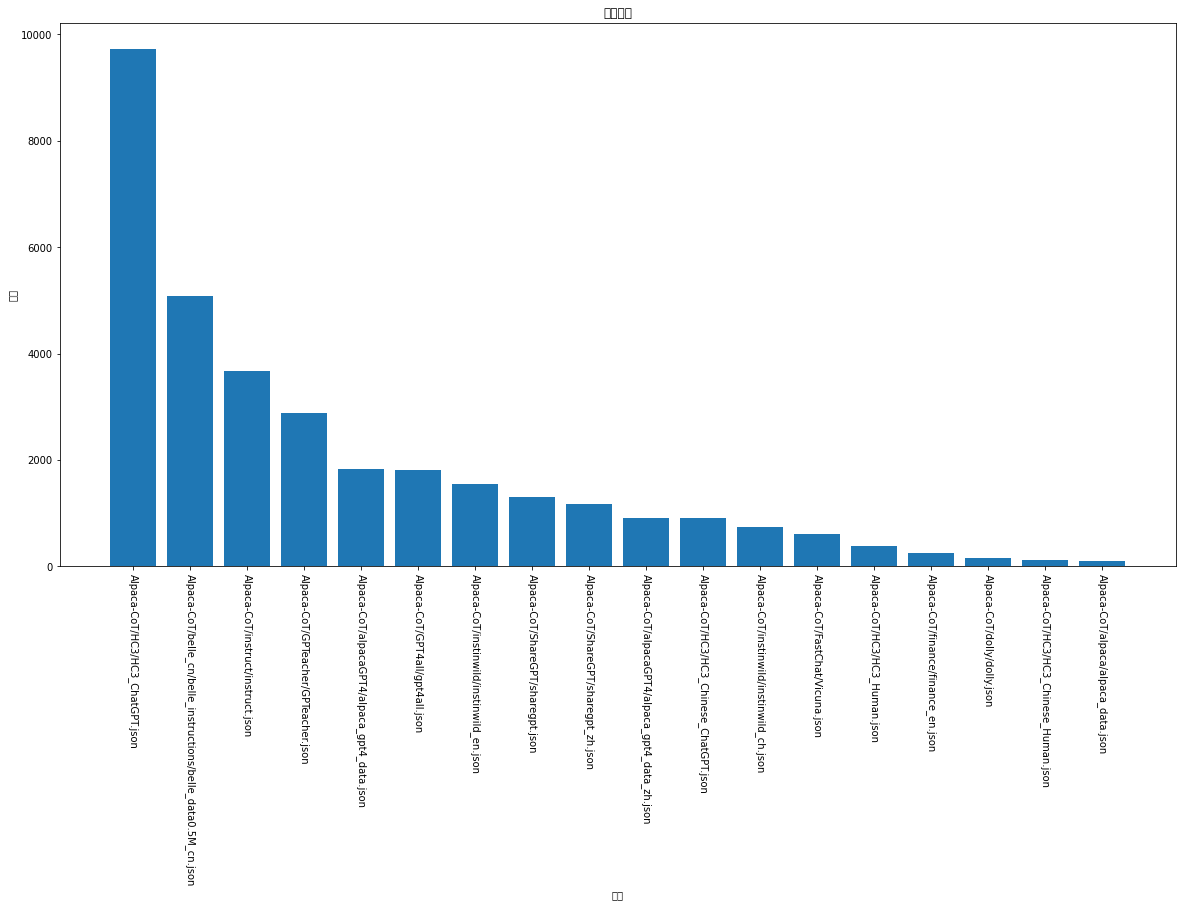
count 33194.000000
mean 637.879562
std 500.409946
min 0.001000
25% 199.001000
50% 548.501000
75% 1028.001000
max 9305.001000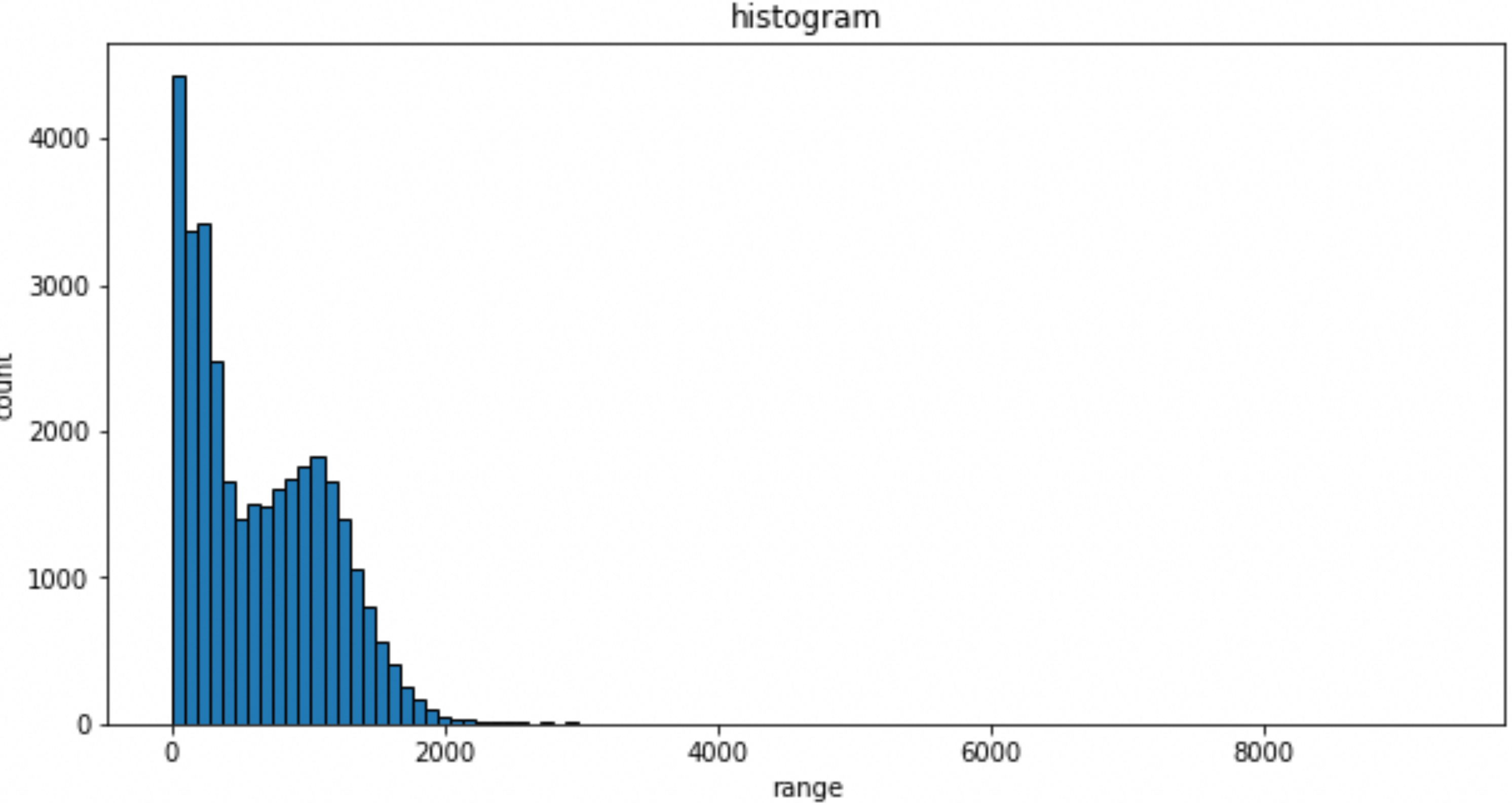
count 33194.000000
mean 167.052877
std 166.948212
min 1.001000
25% 63.001000
50% 134.001000
75% 221.001000
max 5510.001000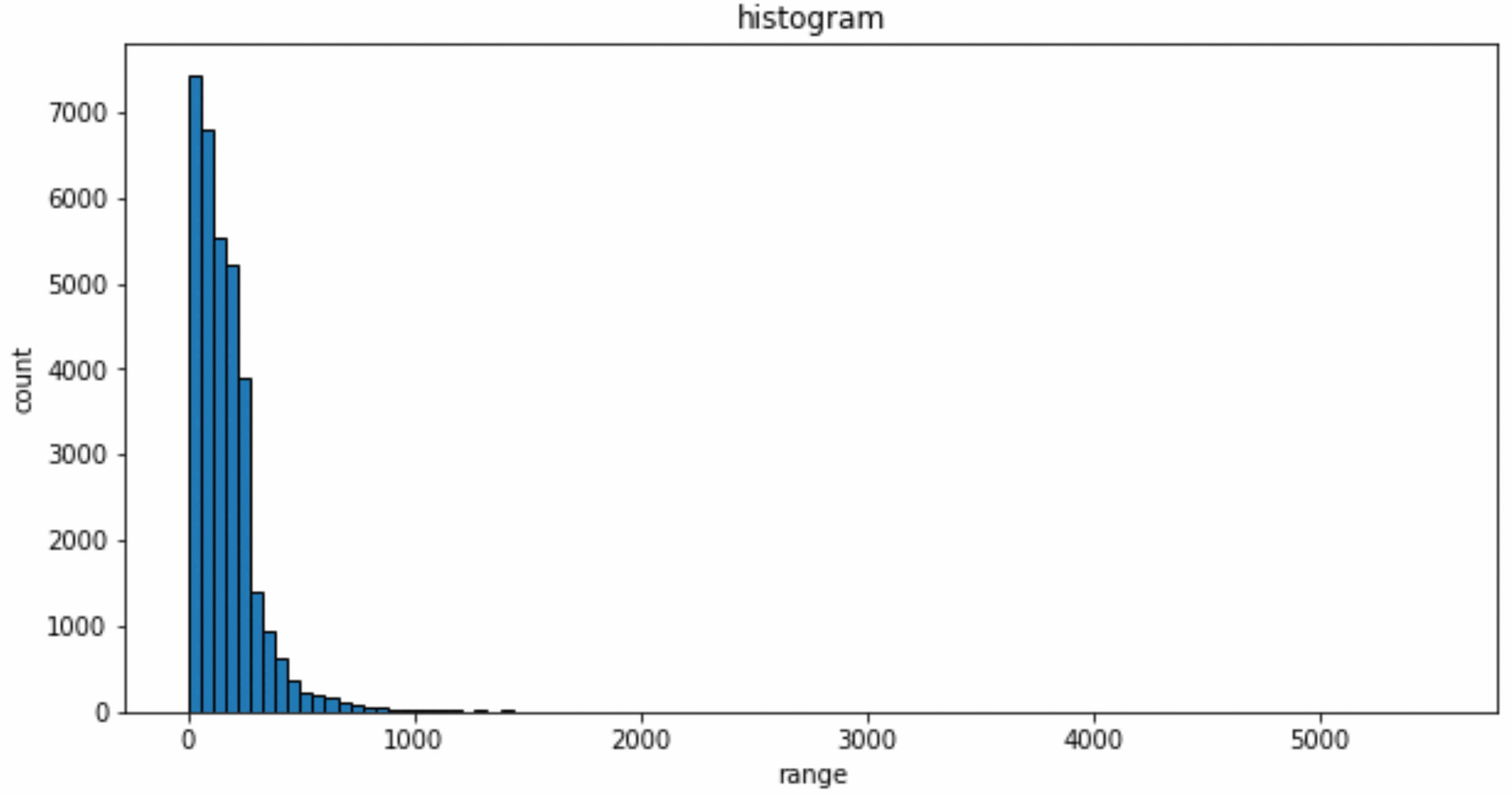
1.程序主文件和入口:
由于./tools/math_score.bin不存在,需要下载,请运行gen_data.sh!!!该文件会自动下载math_score.bin
请运行gen_data.sh!!!!!
get_mixture.py或者gen_data.sh
2.生成mixture.jsonl文件的流程如下:
# 第一步:混合原始数据
generate_mixture(input_dir, ratio_path, mixture_path)
# 第二步:输出混合ratiodict
generate_ratio(input_dir, ratio_path, mixture_path)
# 第三步:将一些新字段加入到数据中
insert_new_param()
# 第四步:利用新字段和指令长度等条件进行过滤,需要访问huggingface的baichuan-inc/Baichuan2-7B-Base模型
filter_and_select_data_lines()
# 第五步:利用data-juicer进行过滤,需要依赖data-juicer工具,需要使用simhash,minhash等功能
data_juicer_filtered()
# 第六步:knn语义相似度数据过滤
knn_semantic_data_filtered()
# 第七步:获取math_high_score数据和用正则获取纯数学数据
# 获取数据并进行data_juicer去重
extract_math_using_math_score(input_dir, mixture_math_score_path)
data_juicer_filtered_math_score()
insert_new_param_for_math_score()
# 第八步:获取正则数学数据
extract_regex_math()
# 最后一步:混合所有的数据
os.system('python mix_back_final_solution.py')
3.前置依赖标签文件生成(可选,不是必跑项)
请注意,insert_new_param()和insert_new_param_for_math_score()依赖文件列表如下:
socre_deberta_0130_list.jsonl
qwen_1p8_instag.jsonl
mixture_raw_reweight_task_type.json
task_type_bge.jsonl
socre_rerank_0201_list.jsonl
task_type_bge_math_score.jsonl
用label_gen目录下的vllm_qwen1p8.py生成qwen_1p8_instag.jsonl;
用label_gen目录下的score_deberta.py生成socre_deberta_0130_list.jsonl;
用label_gen目录下的main_quality.py生成质量打分mixture_raw_reweight_task_type.json;
用label_gen目录下的score_rerank_correlation.py生成socre_rerank_0201_list.jsonl;
用label_gen目录下的run_labeling_task_type.sh脚本以mixture_raw_reweight.jsonl为输入,生成task_type_bge.jsonl文件;
用label_gen目录下的run_labeling_task_type.sh脚本以mixture_raw_math_only_juicer.jsonl为输入,生成task_type_bge_math_score.jsonl文件;
以上这些标签文件全部都已经生成好,放置于solution目录下,无需重复生成。