- Wonjoon Goo(SNU, now at UT Austin), Juyong Kim(SNU), Gunhee Kim(SNU), and Sung Ju Hwang(UNIST)
This project hosts the code for our ECCV 2016 paper. [pdf]
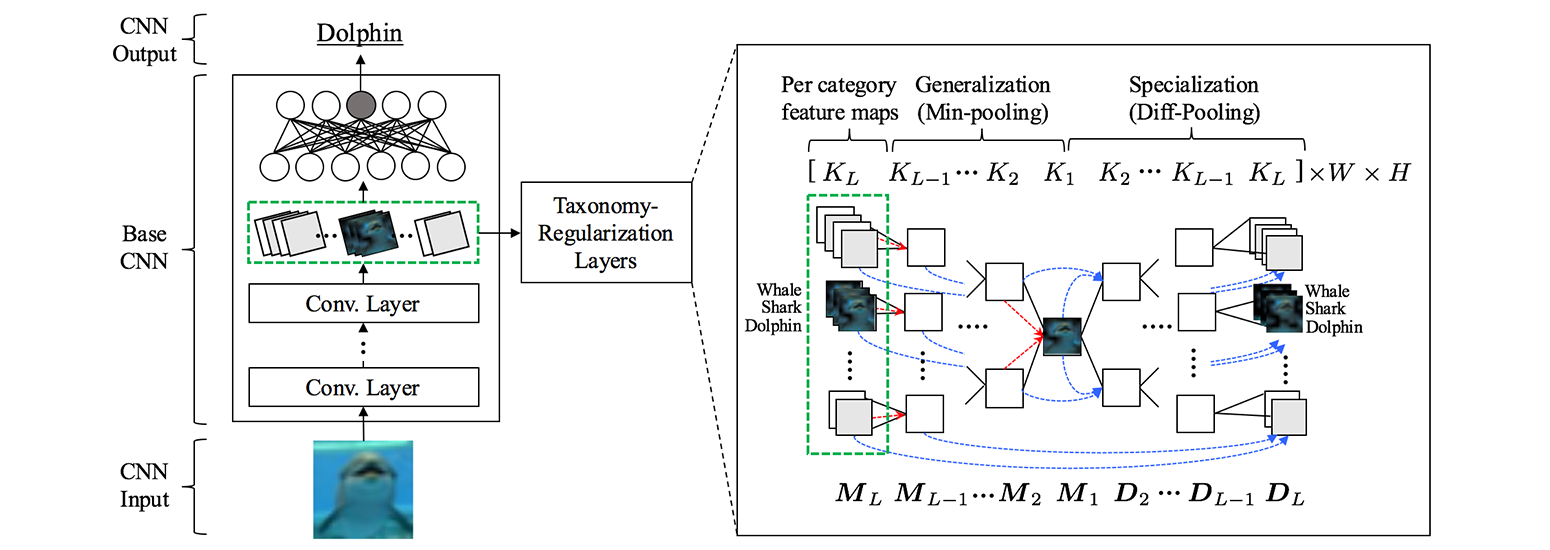
We propose a novel convolutional neural network architecture that abstracts and differentiates the categories based on a given class hierarchy. We exploit grouped and discriminative information provided by the taxonomy, by focusing on the general and specific components that comprise each category, through the min- and difference-pooling operations. Without using any additional parameters or substantial increase in time complexity, our model is able to learn the features that are discriminative for classifying often confusing sub-classes belonging to the same superclass, and thus improve the overall classification performance.
##Reference
If you use this code as part of any published research, please refer the following paper.
@inproceedings{taxonomy:2016:ECCV,
author = {Wonjoon Goo, Juyong Kim, Gunhee Kim and Sung Ju Hwang},
title = "{Taxonomy-Regularized Semantic Deep Convolutional Neural Networks}"
booktitle = {ECCV},
year = 2016
}
We implemented a new type of regularize layer as described in the paper based on BVLC caffe deep learning library. It would be better to go through tutorials of Caffe deep learning library before running our code. Most of error you might encounter will be the problem on running caffe, not ours.
git clone --recursive https://github.com/hiwonjoon/eccv16-taxonomy.git taxonomy
If you look at directory, there will be three important sub-directories; caffe, code, example.
'caffe' directory is the code of BVLC caffe on specific branch "dd6e8e6" commit, which was our working branch. The directory added in the form of git submodule, so if you want to use latest caffe version, then try it :)
'code' directory contains our implementations(super category label layer, etc.)
'example' directory contains the sample prototxt files that is required for training and validation.
First, copy our implementation into original caffe code.
$copy -r ./code/* ./caffe/
Then, build caffe as same as original caffe; Config by modifying Makefile.config and make all.
Before you start and acquire the same experiment result of ours, you need preprocessed Cifar 100 dataset as described on the paper. We assumed that the dataset is located on the top directory(cloned directory), named 'cifar100'. Please change lmdb file locations which are specified on train_val.prototxt
You also need taxonomy tree in the form of prototxt. The sample taxonomy tree for Cifar 100 dataset is given on the directory.
If you execute run.sh script, then you can start training, or you can directly start it from a shell. The script provided is only for less typing :) And, with provided trained model and small modification of scripts and prototxt, you can reproduce our experiment results.
./run.sh
You can use our code for your own datasets or taxonmy trees with minor modification of example prototxt files. If you find any problems, please contact me. Enjoy :)
This work was supported by Samsung Research Funding Center of Samsung Electronics under Project Number SRFC-IT1502-03.
Wonjoon Goo1, Juyong Kim1, Gunhee Kim1, and Sung Ju Hwang2
1Vision and Learning Lab @ Computer Science and Engineering, Seoul National University, Seoul, Korea
2MLVR Lab @ School of Electrical and Computer Engineering, UNIST, Ulsan, South Korea
MIT license