

Find the user documentation here: https://hucebot.github.io/prescyent/
PreScyent is a trajectory forecasting library, built upon pytorch_lightning
It comes with datasets such as:
- AndyData-lab-onePerson
- AndyData-lab-onePersonTeleoperatingICub
- Human3.6M
- And synthetics dataset to test simple properties of our predictors.
It come also with baselines to run over theses datasets, referred in the code as Predictors, such as:
- SiMLPe a MultiLayer Perceptron (MLP) with Discrete Cosine Transform (DCT), shown as a strong baseline achieving SOTA results against bigger and more complicated models.
- Seq2Seq, an architecture mapping an input sequence to an output sequence, that originated from NLP and grew in popularity for time series predictions. Here we implemented an RNN Encoder and RNN Decoder.
- Probabilistic Movement Primitives (ProMPs), an approach commonly used in robotics to model movements by learning from demonstrations and generating smooth, adaptable trajectories under uncertainty.
- Some simple ML Baselines such as a Fully Connected MultiLayer Perceptron and an auto-regressive predictor with LSTMs.
- Non machine learning baselines, maintaining the velocity or positions of the inputs, or simply delaying it.
- With H our history size, the number of observed frames
- With F our future size, the number of frames we want to predict
- With X the points and features used as input
- With Y the points and features produced as output
We define P our predictor such as, at a given time step T we have:
You can install released versions of the project from PyPi. install using pip from source (you may want to be in a virtualenv beforehand):
pip install prescyentYou can build an image docker from the Dockerfile at the source of the repository.
Please refer to docker documentation for build command and options.
The Dockerfile is designed to be run interactively.
If you want to setup a dev environment, you should clone the repository:
git clone git@github.com:hucebot/prescyent.git
cd prescyentThen install using pip from source (you may want to be in a virtualenv beforehand):
For dev install (recommended if you intent to add new classes to the lib) use:
pip install -e .Each dataset is composed a list Trajectories, split as train, test and val.
In this lib, we call "Trajectory" a sequence in time split in F frames, tracking P points above D dimensions.
It is represented with a batched tensor of shape:
(B, F, P, D).
Note that unbatched tensors are also allowed for inference.
For each Trajectory we describe its tensor with Features, a list of Feature describing what are the dimensions tracked for each point at each frame. Theses allows conversions to occur in background or as preprocessing, as well as using some distance specific losses and metrics (e.g. Euclidean distance for Coordinates and geodesic distance for Rotations)
Alongside each trajectory tensor, some dataset provide some additional "context" (images, center of mass, velocities...), that is represented inside the library as a dictionary of tensors.
We use HDF5 file format to load a dataset internally. Please get the original data and pre process them using the scripts in /datapreprocessing to match the library's format.
Then when creating an instance of a Dataset, make sure you pass the path to the newly generated hdf5 file to the dataset's config attribute hdf5_path.
The hdf5 versions of theses datasets have also been uploaded here: https://gitlab.inria.fr/hucebot/datasets/
Download AndyData-lab-prescientTeleopICub's data here and unzip it, it should be following this structure:
├── AndyData-lab-prescientTeleopICub
│ └── datasetMultipleTasks
│ └── AndyData-lab-prescientTeleopICub
│ ├── datasetGoals
│ │ ├── 1.csv
│ │ ├── 2.csv
│ │ ├── 3.csv
│ │ ├── ...
│ ├── datasetObstacles
│ │ ├── 1.csv
│ │ ├── 2.csv
│ │ ├── 3.csv
│ │ ├── ...
│ ├── datasetMultipleTasks
│ │ ├── BottleBox
│ │ │ ├── 1.csv
│ │ │ ├── 2.csv
│ │ │ ├── 3.csv
│ │ │ ├── ...
│ │ ├── BottleTable
│ │ │ ├── 1.csv
│ │ │ ├── 2.csv
│ │ │ ├── 3.csv
│ │ │ ├── ...
│ │ ├── ...
Then run the script dataset_preprocessing/teleopicubdataset_to_hdf5.py to generate the dataset in the lib's format, with --data_path argument providing the path to the downloaded dataset, and the --hdf5_path argument giving the path and name of the generated hdf5 file (optional).
For example something like:
python dataset_preprocessing/teleopicubdataset_to_hdf5.py --data_path AndyData-lab-prescientTeleopICub/ --hdf5_path AndyData-lab-prescientTeleopICub.hdf5For Human3.6M you need to download the zip here and prepare your data following this directory structure:
└── h36m
| ├── S1
| ├── S5
| ├── S6
| ├── ...
| ├── S11Then run the script dataset_preprocessing/h36mdataset_to_hdf5.py to generate the dataset in the lib's format, with --data_path argument providing the path to the downloaded dataset, and the --hdf5_path argument giving the path and name of the generated hdf5 file (optional).
For example something like:
python dataset_preprocessing/h36mdataset_to_hdf5.py --data_path h36m/ --hdf5_path h36m.hdf5For AndyDataset you need to download the zip here and prepare your data following this directory structure:
└── AndyData-lab-onePerson
| └── xsens_mnvx
| ├── Participant_541
| ├── Participant_909
| ├── Participant_2193
| ├── ...
| ├── Participant_9875Then run the script dataset_preprocessing/andydataset_to_hdf5.py to generate the dataset in the lib's format, with --data_path argument providing the path to the downloaded dataset, and the --hdf5_path argument giving the path and name of the generated hdf5 file (optional).
For example something like:
python dataset_preprocessing/andydataset_to_hdf5.py --data_path AndyData-lab-onePerson/ --hdf5_path AndyData-lab-onePerson.hdf5The trajectory prediction methods are organized as Predictor classes.
For example, the MlpPredictor class is the implementation of a configurable MLP as a baseline for the task of Trajectory prediction.
Relying on the PytorchLightning Framework, it instantiates or load an existing torch Module, with a generic predictor wrapper for saving, loading, iterations over a trajectory and logging.
Feel free to add some new predictor implementations following the example of this simple class, inheriting at least from the BasePredictor class.
We also provide a set of functions to run evaluations and plot some trajectories.
Runners take a list of predictors, with a list of trajectories and provide an evaluation summary on the following metrics:
- Average Displacement Error (ADE): Mean distance over all points (feature wise) over the whole prediction.
- Final Displacement Error (FDE): Mean distance over all points (feature wise) over the last frame predicted.
- Mean Per Joint Position Error (MPJPE): Mean distance over all points (feature wise) given at each predicted frame.
- Real Time Factor (RTF): Processing time (in seconds) / trajectory duration (in seconds).
Please look into the examples/ directory to find common usages of the library
We use tensorboard for training logging, use tensorboard --logdir {log_path} to view the training and testing infos (default log_path is data/models/)
For example to run the script for mlp training on teleopIcub dataset use this in the environment where prescyent is installed:
python examples/mlp_icub_train.pyIf you want to start a training from a config file (as examples/configs/mlp_teleopicub_with_center_of_mass_context.json), use the following:
python examples/train_from_config.py examples/configs/mlp_teleopicub_with_center_of_mass_context.jsonThe script start_multiple_trainings.py is an example of how to generate variations of configuration files and running them using methods from train_from_config.py
Also for evaluation purposes, you can see an example running tests and plots using AutoPredictor and AutoDataset in load_and_plot_predictors.py or animations such as in plot_pred_over_time.py
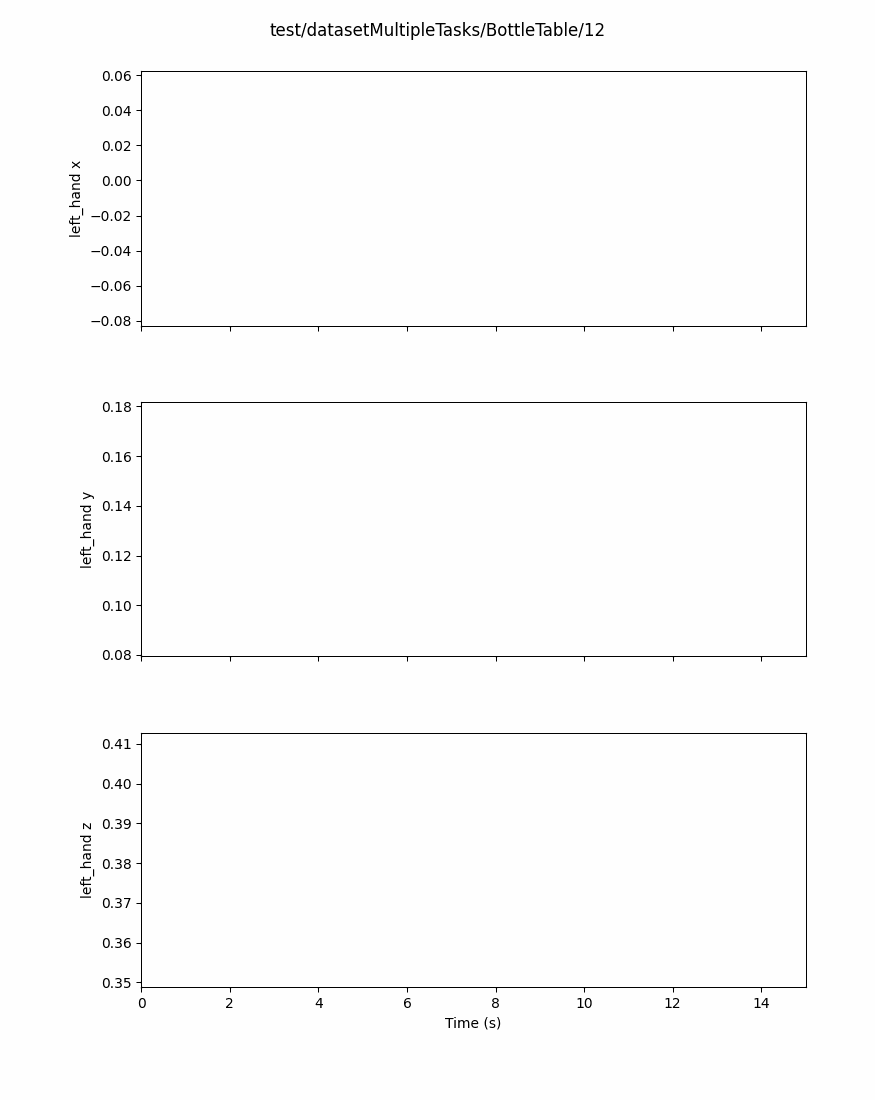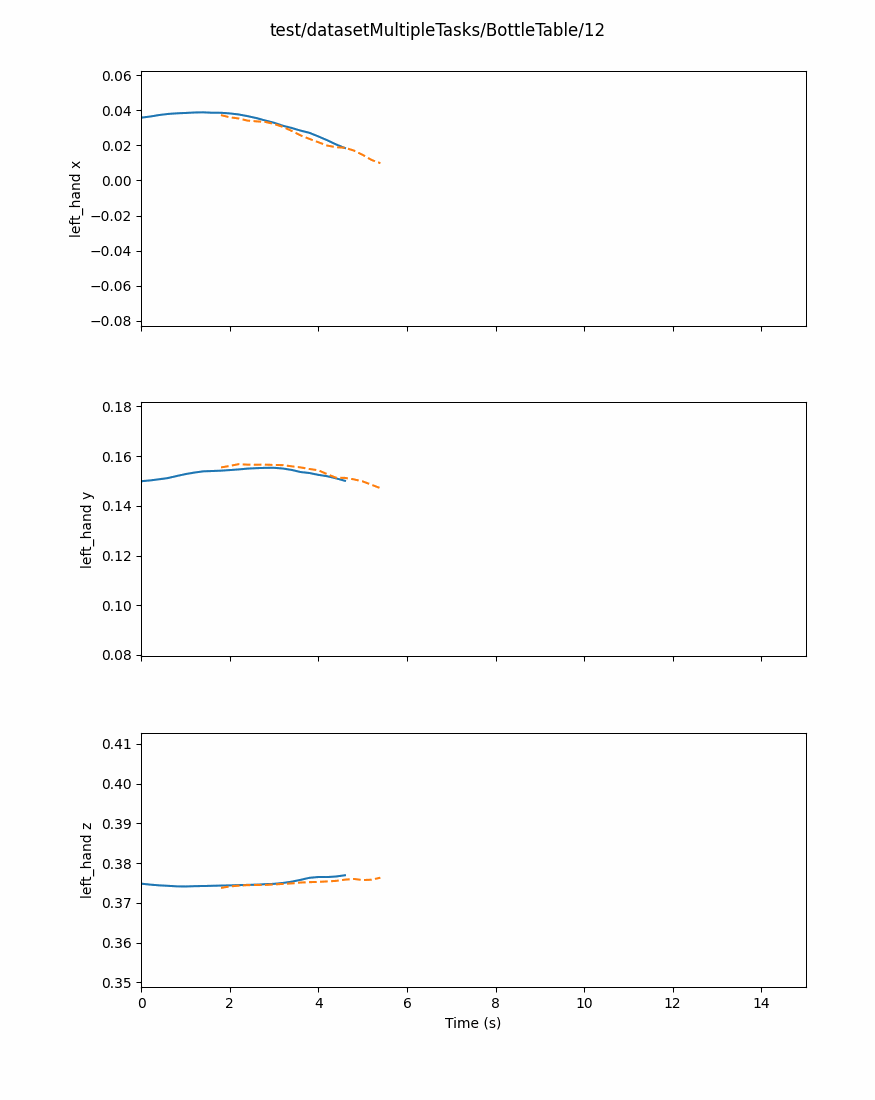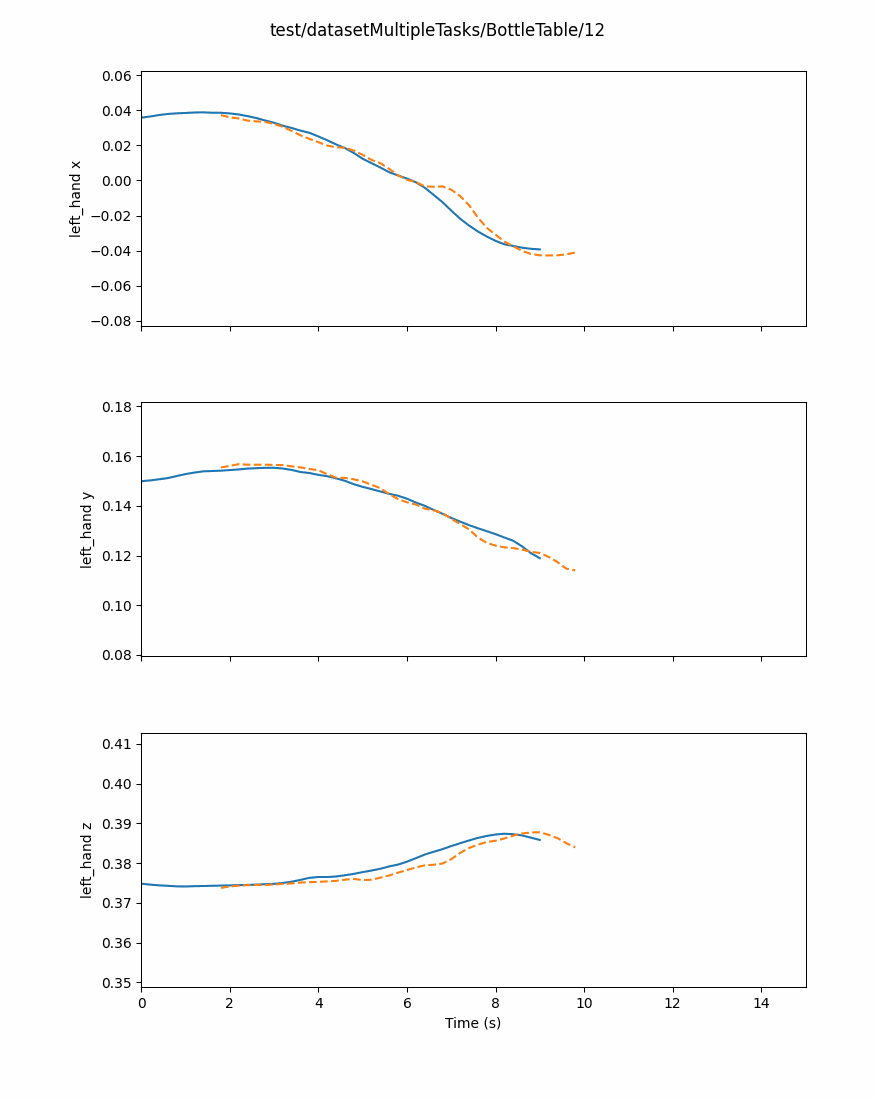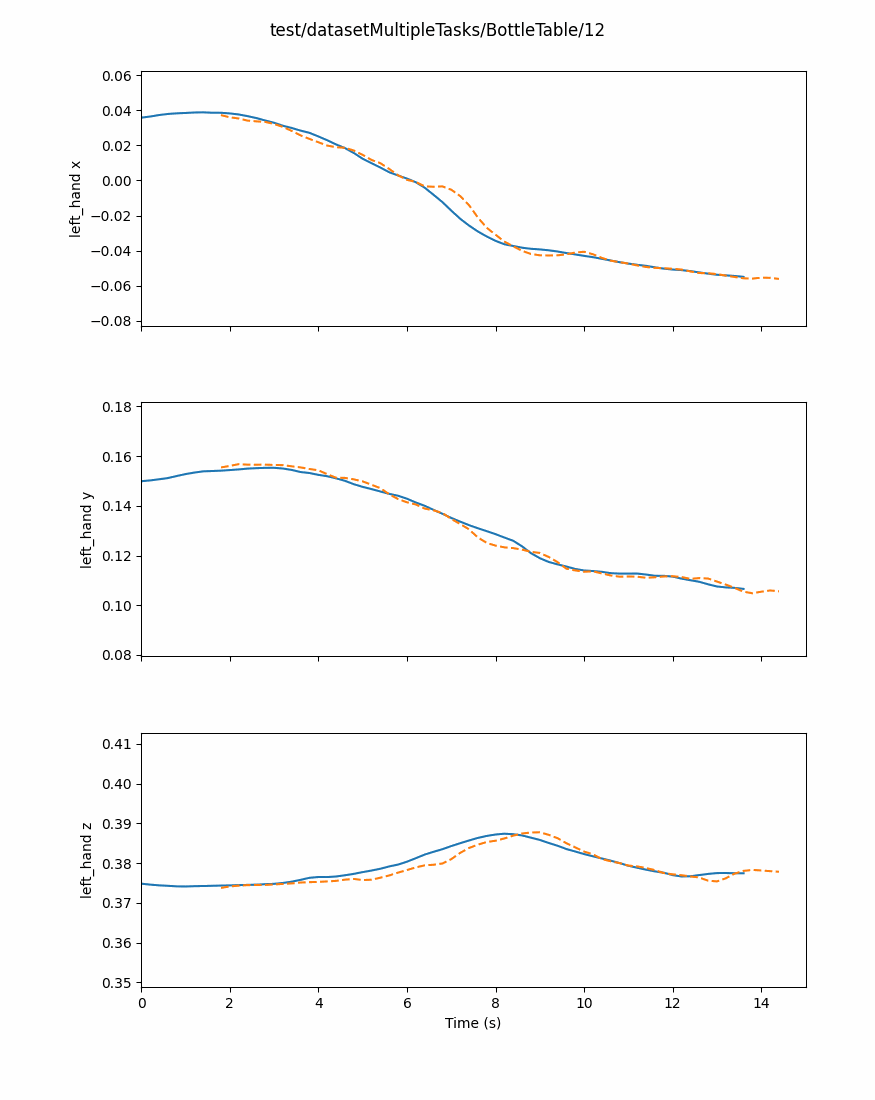
Predictors inherit from the BasePredictor class, which define interfaces and core methods to keep consistency between each new implementation.
Each Predictor defines its PredictorConfig with arguments that will be passed on to the core class, again with a BaseConfig with common attributes that needs to be defined.
If you want to implement a new ML predictor using PyTorch follow the structure of one of our simple predictors such as MlpPredictor and its 3 files where:
- in
module.pyyou create your torch.nn.Module and forward method as you would usually do, you may want to inherit from BaseTorchModule instead of just torch.nn.Module and decorate your forward method with@self_auto_batchand@BaseTorchModule.deriv_tensorto benefit from some of the lib's features. - in
config.pycreate your pydantic BaseModel inheriting fromModuleConfigto ensure your predictor's config has all the needed variables, and add any new values you want as variables in your model's architecture. - finally
predictor.pysimply connects the above two by declaring both classes as class attributes for this specific predictor. Most of the magic happens in the parent classes using pytorch_lightning with your torch module.
In the same way you can extend the dataset module with a new Dataset inheriting from TrajectoriesDataset with its own DatasetConfig. Again taking examples on one of our implementation as TeleopIcubDataset, you must:
- in
dataset.py, inherit from the TrajectoriesDataset class and implement aprepare_datamethod where you must initself.trajectorieswith aTrajectoriesinstance built from your data/files. - in
config.pycreate your pydantic BaseModel inheriting fromTrajectoriesDatasetConfigto ensure you have all variables for the dataset processes, and add any new value you want as variables in your dataset's architecture. - optionally use
metadata.pyas we did to store some constant describing your dataset.
All the logic creating the datasamples and dataloaders is handled in the parent class as long as self.trajectories is defined and the config is valid.
If you simply want to test a Predictor over some data, you can create an instance of CustomDataset. As long as you turned your lists of episodes into Trajectories, the CustomDataset allows you to split them into training samples using a generic DatasetConfig and use all the functionalities of the library as usual (except that a CustomDataset cannot be loaded using AutoDataset)...
After installing, you can run the test suite to make sure the installation is ok
python -m unittest -vThis repo use Github actions to run the test suite and linting at pushes and merge over the dev and main branches as continuous integration.
If the integration workflow is successful and we are on the main branch, then we'll build the library and publish it to pypi.
Please make sure that you updated the library's version prescyent.__init__py:__version__ otherwise the deployment will fail.
siMLPe
Wen Guo, Yuming Du, Xi Shen, Vincent Lepetit, Xavier Alameda-Pineda, et al.. Back to MLP: A Simple Baseline for Human Motion Prediction. WACV 2023 - IEEE Winter Conference on Applications of Computer Vision, Jan 2023, Waikoloa, United States. pp.1-11. ⟨hal-03906936⟩
AndyDataset
Maurice P., Malaisé A., Amiot C., Paris N., Richard G.J., Rochel O., Ivaldi S. « Human Movement and Ergonomics: an Industry-Oriented Dataset for Collaborative Robotics ». The International Journal of Robotics Reserach, Volume 38, Issue 14, Pages 1529-1537.
TeleopIcub Dataset
Penco, L., Mouret, J., & Ivaldi, S. (2021, July 2). Prescient teleoperation of humanoid robots. arXiv.org. https://arxiv.org/abs/2107.01281
H36M Dataset
Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. (n.d.). IEEE Journals & Magazine | IEEE Xplore. https://ieeexplore.ieee.org/document/6682899
On the Continuity of Rotation Representations in Neural Networks
Zhou, Y., Barnes, C., Lu, J., Yang, J., & Li, H. (2018, December 17). On the Continuity of Rotation Representations in Neural Networks. arXiv.org. https://arxiv.org/abs/1812.07035
ProMPs
Paraschos, Alexandros & Daniel, Christian & Peters, Jan & Neumann, Gerhard. (2018). Using probabilistic movement primitives in robotics. Autonomous Robots. 42. 10.1007/s10514-017-9648-7. ```