2 Linux下的进程抽象
什么是程序,什么又是进程?程序,或者说可执行的Native程序,简单说就是用计算机代码编写好的源程序经过编译器编译后生成的可执行文件。那进程呢?进程是一个动态的概念,它是静态的可执行文件执行过程的描述,其包含了一个程序运行时的状态和其所占据的系统资源的总和。通俗的说,如果把程序代码比作菜谱,硬件比作厨具的话,那么炒菜的整个过程就是一个进程。
进程在现代的操作系统中是一个很重要也很核心的抽象概念。进程的抽象除了操作系统本身,也需要其所处的硬件架构提供硬件级别的抽象和隔离机制来辅助实现。具体到调试器的实现,本文章主要关注内存的抽象和进程切换的实现。
在一个进程的视角来看,在其运行的上下文中,只有自己和操作系统在使用整个计算机的内存资源,这也是现代操作系统对内存资源做出的抽象。
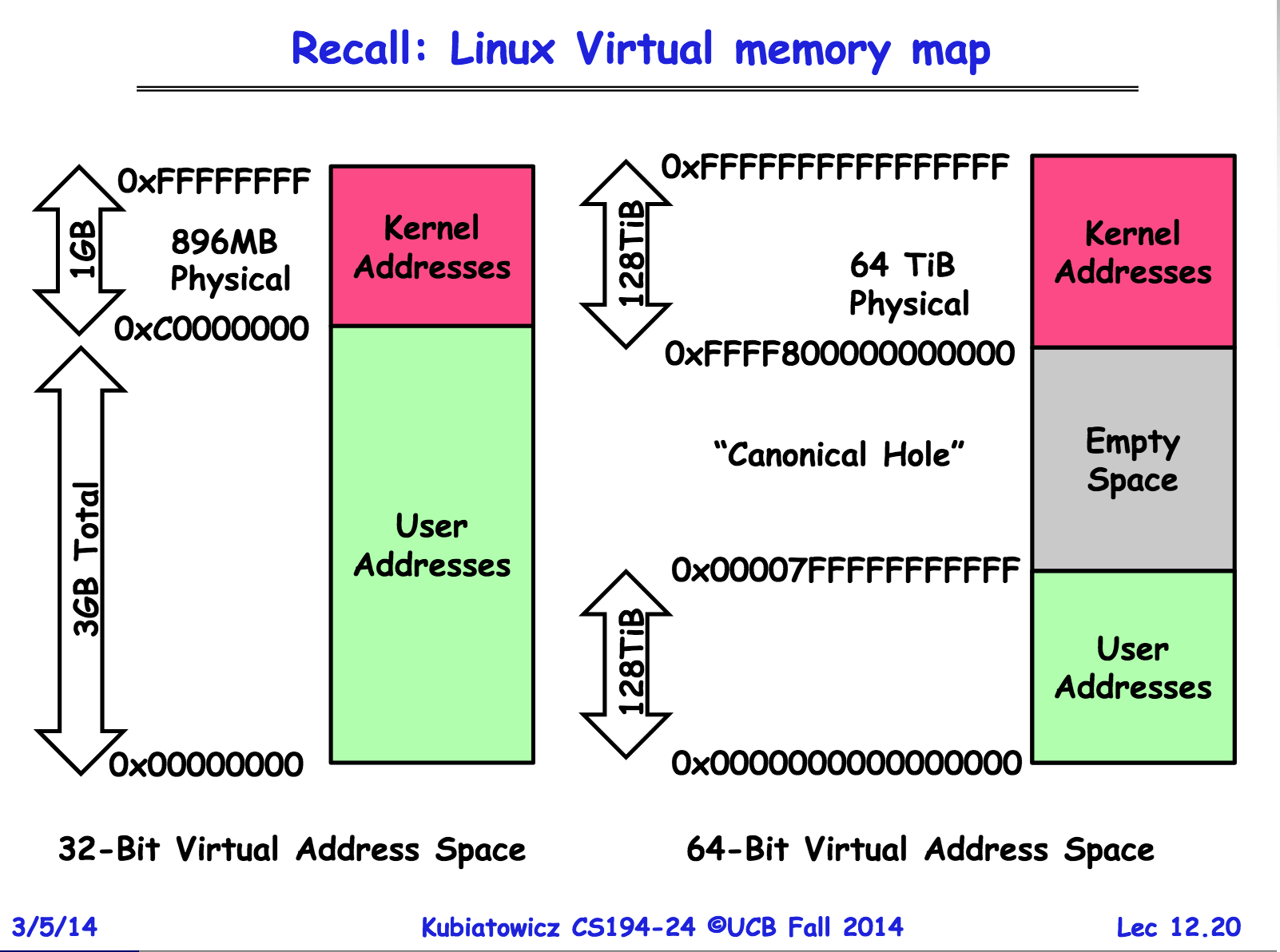
如上图(图片来源见图片标记的出处),分别是32-bit和64-bit操作系统中进程视角的内存线性地址空间的布局。略过32-bit不说,64bit的线性地址空间中间是存在一个“空洞”的。因为目前是用不到这么大编址空间的,避免浪费都是48-bit的地址总线宽度(甚至有些较低端的CPU还会被进一步偷工减料),而高位的16-bit要么扩展为全0,要么扩展为全1(规范要求任何虚拟地址的第48至63位的最高有效16位必须和第47位一致)。这样就形成了两个地址段,即0x0000000000000000 ~ 0x00007FFFFFFFFFFF和0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF这两个各64TB的地址空间。很自然的,高地址段作为内核使用的地址区间,低地址段为应用程序使用的地址区间。
在Linux系统下执行cat /proc/cpuinfo | grep 'address sizes'可以查看系统的CPU地址线宽带,输出类似:
root@082caa3dfb1d ~ $ cat /proc/cpuinfo | grep 'address sizes'
address sizes : 39 bits physical, 48 bits virtual普通的PC上输出的physical很可能只有可怜的36 bits,但这并不影响后续的讨论。无非是可用的地址范围更小,地址中间的“空洞”更大罢了。
那么这个抽象的原理是什么?实际的物理地址空间是怎么被隐藏起来的?这个抽象的线性地址空间怎么和物理内存对应起来?是不是要有个对应表之类的东西。没错,是有个对应表。这个东西称之为页表(Page Table)。
这里不会完整的阐述段页式的内存管理,尤其在目前主流x86_64操作系统已经基本废弃分段机制的情况下,所以这里只简单介绍下分页机制(以下介绍略过分段机制,请自行脑补,脑补不出来?那就当不存在吧)。
虚拟地址->页机制处理(MMU)->物理地址虚拟地址经过CPU内部的MMU(Memory Management Unit, 内存管理单元)的处理之后,就得到了物理地址。这个处理过程其实就是查个表,检查个地址权限什么的。显然不可能是一个字节的虚拟地址到一个字节的物理地址这么映射的。因为表示这个映射关系都不只占用一个字节了,不可能这么奢侈的。主流的页表大都是默认选择4KB为映射单位映射的(当然有其他更大的尺寸,这里不讨论)。即实际的设计是划分地址空间为页,然后一个虚拟地址页对应一个物理地址页,那么这个页表长什么样子?
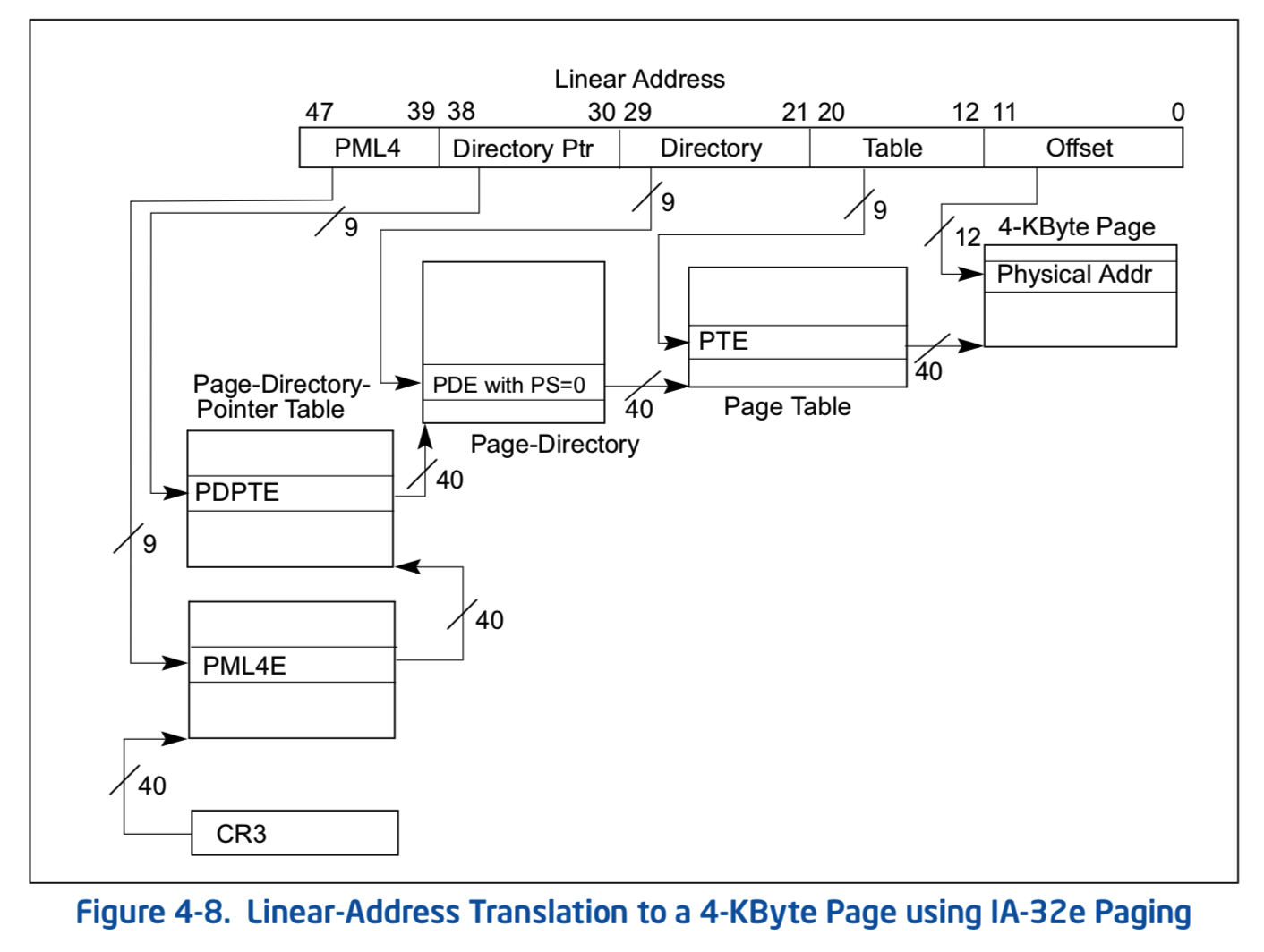
上图是Intel文档中的4级页表插图,也是64-bit目前标准的分页方式(其实这里感觉我应该贴AMD的文档,但是Intel的文档就在手边就直接拿来截图了)。具体这个分级页表是怎么分级的也不讨论,因为相关的文档到处都是。有兴趣也可以看我以前写的内核demo的文档,虽然是32-bit的3级页表,但是原理是一样的。
这个页表的具体数据是哪里来的?当然是操作系统按照规范创建并告知MMU的。所以当实际的程序执行的时候,操作系统已经贴心的创建好了只属于这个程序的独一无二的内存映射表(一般情况下多个应用程序页表中的内核部分是一样的,可以复用),然后就把执行权交给CPU了。应用程序里访问的每一个地址都是虚拟地址,CPU在每一次内存访问时,MMU都会查询这个虚拟地址对应的实际物理地址,最终并对物理地址进行数据操作。那页表在哪里存储的?当然也是内存(MMU里保存的是页表首地址必须是物理地址,不然就鸡生蛋蛋生鸡循环了)。所以整体来看,应用程序里“一次”内存操作实际上对应了真实的数次内存访问操作。这个效率损失自然是存在的,为了减少这里的访存次数,MMU一般会使用TLB(Translation Lookaside Buffer, 转换检测缓冲区)来缓存查询结果,加速下一次查询。TLB其实说白了就是个cache,俗称快表,没啥讨论的。
综上,通过页表和MMU的配合,操作系统给当前程序制造了一个虚拟的内存概念。这样做的好处是什么呢?首先是编译器和链接器的实现变的简单了,生成的每一个程序都拥有完整的地址空间,计算和分配地址变的很容易。另外操作系统在加载可执行程序的时候也变得简单了,不再需要对每一个地址都进行映射和重定位(共享库中用的PIC技术这里不讨论)。另外,因为地址空间隔离,使得应用程序间完全隔离,不会有数据泄露风险。
至于具体的可执行程序的载入过程,以及该程序的User Address部分是如何分配的。将在下一届介绍了ELF文件格式之后详述。
接下来看权限隔离。当执行权限交给CPU之后,当前CPU核心上将直接执行应用程序的代码。如果这个应用程序恶意的读取和修改内核地址空间的数据怎么办?页表上是可以设置权限位,但是页表也被这个应用程序改了怎么办?所以单纯的页机制是不够的,还需要CPU对执行的代码进行分级,不同级别的代码允许执行的CPU指令集合是不一样的。如题,Intel将代码的执行级别划分为ring0~rong3等级别(考虑到虚拟化的话,这里会稍微复杂一点。但是,作为入门文档,肯定不会考虑的)。
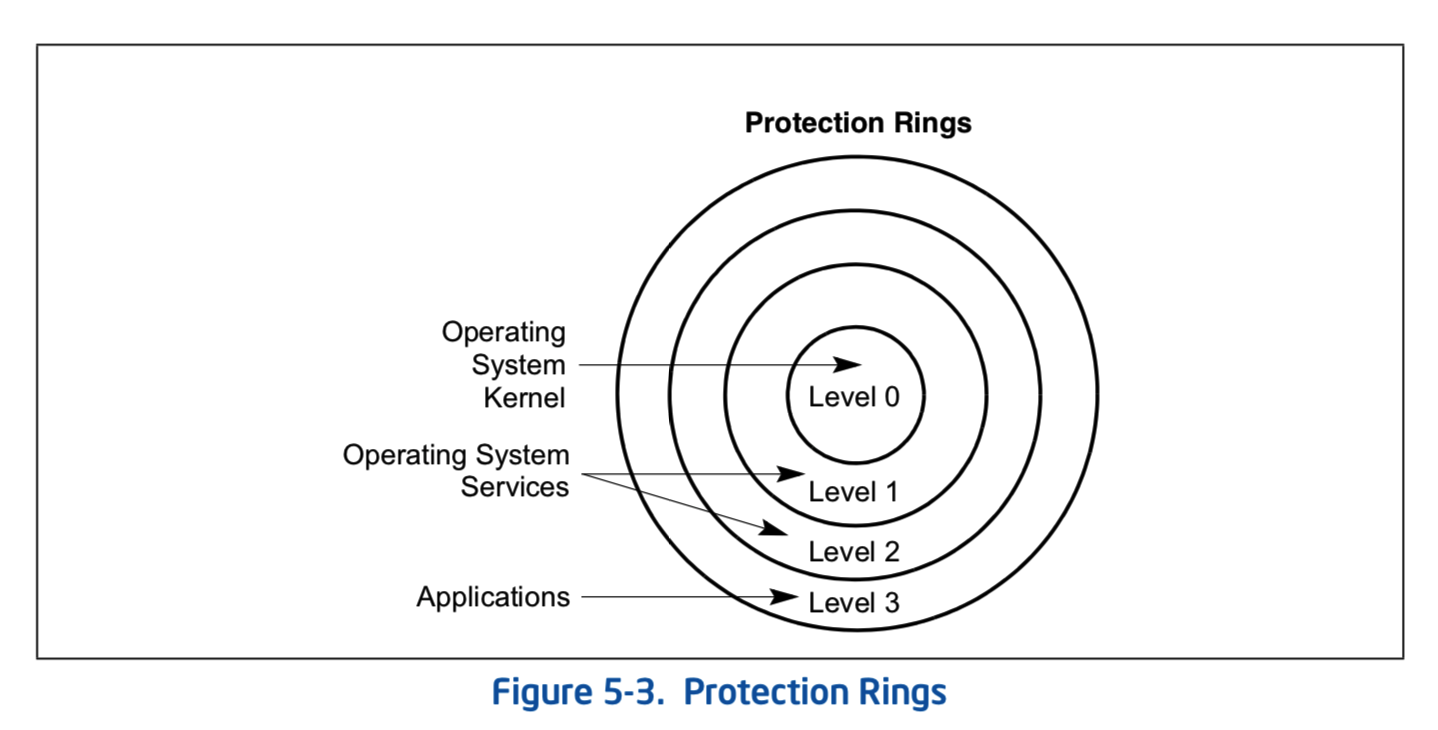
操作系统在计算机启动的时候接管一切,自身处于ring0级别,之后创建的普通应用程序都执行在ring3级别。而这个级别只能降级无法自行升级,这就限制了应用程序的提权和执行特权指令(有安全风险的指令)。如果这个应用程序调用特权指令,就会被CPU拒绝并产生一个异常,将执行权重新交给操作系统,让操作系统来裁决这个不守规矩的应用程序。
大致的原理过程就是这样。实际上这里有很多(无聊的)细节。有兴趣的话可以去翻阅Intel的文档,还不过瘾的话可以拿上面说的内核demo去练手。如果觉得差不多理解了的话,这章节也见好就收了。
进程切换这里也不准备细说,因为和调试器需要的背景知识关联不大。只需要知道,CPU的寄存器等资源只有一份,同时执行的多个应用程序需要操作系统为其创建寄存器数据的内存备份,以供下一次调度执行时候初始化寄存器的值,这就够了。