所谓Image Caption,即看图说话,是指从图片中自动生成一段描述性文字,有点类似于小时候做过的“看图说话”,对于人来说非常简单,但对于机器,却充满了挑战性。
机器要自动完成Image Caption分为3步:(1) 检测出图像中的物体;(2) 理解物体之间的相互关系;(3) 用合理的语言表达出来;每一步都具有难度。
Image Caption(看图说话)任务是结合CV(Computer Vision,计算机视觉)和NLP(Natural Language Processing,自然语言处理)两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字。这项任务要求模型可以识别图片中的物体、理解物体间的关系,并用一句自然语言表达出来。
Image Caption(看图说话)任务的应用场景非常广泛,主要包括:
-
为照片匹配合适的文字,方便检索或省去用户手动配字;
-
帮助视觉障碍者去理解图像内容;
-
在艺术创作和罪犯画像等领域也有应用。
图像理解可以认为是一种动态的目标检测,由全局信息生成图像摘要。早先的做法例如《Baby Talk》,《Every picture tell a story》等都是利用图像处理的一些算子提取出图像的特征,经过SVM分类等等得到图像中可能存在的目标object。根据提取出的object以及它们的属性利用CRF(Conditional Random Fields,条件随机场)或者是一些认为制定的规则来恢复成对图像的描述。这种做法非常依赖于图像特征的提取和生成句子时所需要的规则,效果并不理想。
BabyTalk: Understanding and Generating Simple Image Descriptions.
Every Picture Tells a Story: Generating Sentences from Images.
在show and tell出现之前,利用RNN做机器翻译实际上已经取得了非常不错的成果。常用的做法是利用编码器RNN读入源语言文字生成中间隐层变量,然后利用解码器RNN读入中间隐层变量,逐步生成目标语言文字。当然,这里的RNN可能是LSTM或者是GRU等其他变体。
受到这种启发,google团队则将机器翻译中编码源文字的RNN替换成CNN来编码图像,希望用这种方式来获得图像的描述。从翻译的角度来看,此处源文字就是图像,目标文字就是生成的描述。
show and tell论文是Image Caption使用深度学习方法的开山之作,它只把Ecoder-Decoder结构做了简单修改,并取得了较好的结果。

通过预训练的InceptionV3提取图像的特征,然后将softmax前一层的数据作为图像编码过后的特征,传入LSTM中。LSTM另一的输入是word embedding,每步输出单词表中所有单词的概率。
李飞飞的Neural Talk同样如此,只是使用的是VGG+RNN,她们还做了一个工作就是利用片段图像生成局部区域的描述。这个工作主要是结合RCNN,将RCNN最后要输出的分类改成输出对object的丰富语义描述。

**小结:**两篇论文几乎同时提出来encoder-decoder框架,对后人做图像理解提供了一条鲜明的道路,接下来的几年在MSCOCO的leader board上几乎都是基于这种框架拿第一。这种做法也有很明显的缺点,比如图像特征仅仅只在开始的时候以bias的形式传入RNN,只关注了全局特征,模型也是学习到了一种模板然后再往里面进行填词等等。
Show and Tell: A Neural Image Caption Generator.
Deep visual-semantic alignments for generating image descriptions.
前者解决了图像仅在开始时传入LSTM的问题,后者则解决了仅传入全局特征的问题。
att-LSTM是通过图像多标签分类来提取出图像中可能存在的属性。这些属性则是根据字典中出现频率最高的一些单词所组成的。利用手工剔除非法字符,合并不同时态,单复数形态的方式,认为的剔除噪声。剩下的就和之前一样,将att传入LSTM的偏置。
Guiding Long-Short Term Memory for Image Caption Generation.
What Value Do Explicit High Level Concepts Have in Vision to Language Problems?
针对翻译精度的下降问题,论文呢提出了一种注意力机制,不再使用统一的语义特征,而让Decoder在输入序列中自由选取需要的特征,从而大大提高模型性能。

不同于以往采用全连接层作为图像特征,这次是直接使用卷积层conv5_3作为特征。特征图大小通常为77512(VGG),每个时刻传入LSTM的则是上一时刻的状态c,h以及加权过后的卷积层特征。attention在这里的作用就是做加权用的,对应不同的加权方式分为了两种。
Neural Baby Talk 是一种新型图像字幕框架,以图像中目标检测器所发现的实体明确的建立自然语言。 减少对语言模型的依赖,更多地结合图像内容。
首先生成一个句子模板,其中槽位明确与特定图像区域绑定。然后这些插槽被目标探测器在该区域中识别的视觉词汇所填。其架构为端到端。

NIC模型的结构非常“清晰”:
利用encoder-decoder框架
1.首先利用CNN(这里是inceptionv3)作为encoder,生成feature map
2.feature map作一次embeding全连接,生成长度为512的一维向量。
3.再使用LSTM作为decoder,将向量输入decoder。
4.模型训练就是使用最大化对数似然来训练,然后在测试阶段采用beam search来减小搜索空间。
与传统的lstm网络的区别在于,图像特征不是每一时刻都有输入,而只在第一时刻给入,作者给出的理由是,如果在每个时刻都输入图像特征,那么模型会把图像的噪声放大,并且容易过拟合。
Image Caption任务的训练过程可以描述为这个形式:
对于训练集的一张图片 I,其对应的描述为序列 S={S1,S2,...}(其中 Si代表句子中的词)。对于模型 θ ,给定输入图片I,模型生成序列 S的概率为连乘形式的似然函数。
将似然函数取对数,得到对数似然函数:
模型的训练目标就是最大化全部训练样本的对数似然之和:
一些思考:虽然训练是用的最大化后验概率,但是在评估时使用的测度则为BLEU,METEOR,ROUGE,CIDER等。
这里有训练loss和评估方法不统一的问题。而且log似然可以认为对每个单词都给予一样的权重,然而实际上有些单词可能更重要一些(比如说一些表示内容的名词,动词,形容词)。
-
深度学习时代
采用LSTM模型,过分依赖language model,导致caption经常与图像内容关联不够。
-
深度学习之前
更依赖图像内容,而对language model关注不多,例如采用一系列视觉检测器检测图像内容,然后基于模板或者其他方式生成caption
-
作者观点
减少对语言模型的依赖,更多地结合图像内容。
采用物体检测器检测图像中的物体(visual words),然后在每个word的生成时刻,自主决定选取textual word(数据集中的词汇) 还是 visual word(检测到的词汇)。
如图3.1所示,(a)为Baby Talk模型示意图,(b)为Neural Baby Talk模型示意图,(c)为neural image captioning模型示意图。Neural Baby Talk方法先生成一个句子模板,其中关键单词空缺,如图中的有色方块所示,接着,目标检测器对图片中目标进行检测,并将检测得到的物体名称填入句子模板中。

如图3.2,展示了使用4个不同目标检测器的效果,(1)未使用目标检测器;(2)使用弱目标检测器,只检测出来“person”和"sandwich";(3)使用在COCO数据集上训练出来的目标检测器,结果较为准确;(4)使用具有新奇概念novel concepts的目标检测器,图片captions训练集中并没有“Mr.Ted”和"pie"词汇。
本文提出的神经方法会生成一个句子模板,模板中的空槽和图片区域捆绑在一起。在每个time step,模型决定选择从textual词汇表生成词语还是使用视觉词汇。
visual word:
每个visual word对应一个区域$r_I$,如图3.1所示,“puppy”和"cake"分别属于“dog”和"cake"的bounding box类别,是visual words。
textual word:
来自Caption的剩余部分,图3.1中,“with” 和 “sitting”与图片中的区域没有关系,因此是textual words。
目标:

其中,$I$为输入图片,$y$为图片描述语句。
公式可以分成两个级联的目标:
-
最大化生成句子“模板”的概率;
如图3.3所示,“A <region-2>is laying on the <region-4> near a <region-7>"即为“模板”。
-
最大化依据grounding区域和目标识别信息得到的visual words的概率;

“Slotted” Caption模板生成:
本文使用recurrent neural network(RNN)生成Caption的模板。此RNN由LSTM层组成,CNN输出的feature maps作为其输入。
使用pointer network,通过调制一个在grounding区域上基于内容的注意力机制来生成visual words的槽“slot”。
Caption改良:槽填充
使用目标检测框架在grounding区域上,可以识别区域内的物体类别,例如,“狗”。
还需要对词语进行变换使其适合当前文本上下文,比如单复数、形态等。
而Captions指的是比较时尚的词“puppy”,或复数形式“dogs”。因此,为了适应语言的变化,我们模型生成的visual words是经过细致改良过的,变换的主要措施为:1、单复数,确定此类别物体是否有多个(如dog跟dogs);2、确定细粒度的类别名称(如dog可以细分为puppy等);
两种变换分别学习两个分类器实现,单复数用二分类器,fine-grained用多分类做。
目标函数:

第一部分为Textual word 概率,第二部分为Caption细微改良(针对词形态),第三部分为目标区域平均概率。
其中,$y_t^$为ground truth caption在t时刻的word;$1_{(y_t^=y^{txt})}$为指示函数,yt*为textual word则为1,否则为0;$b_t^{*}$为target ground truth 复数形式,$s_t^{*}$为target ground truth分类名称进行细微调整;$({r_t^i})_{i=1}^m$为target grounding区域在t时刻对应的visual word。
**Detection model:**Faster R-CNN
**Region feature:**预训练的ResNet-101
输入图片大小为576X576,我们随机裁切为512X512,然后作为CNN的输入。 $$ v_i=[v_i^p;v_i^l;v_i^g] $$ Region feature$v_i$由3部分组成,$v_i^p$为pooling feature of RoI align layer(不明白),$v_i^l$为location feature,$v_i^g$为区域$i$的类标签对应的glove vector embedding。
**Language model:**基本的注意力模型使用2层的LSTM

如图4所示,attention layers有两层,分别用来注意Region feature()和CNN最后一个卷积层输出的feature
训练细节:
2层LSTM的隐层大小为1024
attention layer隐藏单元数量为512
input word embedding大小为512
优化器:Adam
学习速率:初始学习速率为$5\times10^{-4}$,每3个epoch衰减至原来的0.8倍
epoch数量:最初训练了50个epochs
在训练过程中,没有对CNN进行finetune
batch size:COCO(100) Flickr30k(50)
Detector pre-training
使用开源的Faster-RCNN来训练目标检测器。
对于Flickr30K:
visual words取数据集中出现超过100次的词,总共460个detection labels。
detection labels和visual words是一一对应的。
我们不再对检测得到的类别名称进行调整,只关注物体是否有多个。
对于COCO:
使用ground truth detection annotations来训练目标检测器。
Caption pre-processing
我们将COCO和Flickr30k数据集中caption的长度缩减,使其不超过16个词。
建立一个词汇表,将出现超过5次的词都加入表内,COCO和Flickr30k词汇表长度分别为9587和6864。
BLEU(bilingual evaluation understudy),双语互译质量评估辅助工具,主要用来评估机器翻译质量的工具。
**评判思想:**机器翻译结果越接近专业人工翻译的结果,则越好。
实际工作:判断两个句子的相似程度。
计算公式: $$ BLEU-N=BP \cdot exp\Big(\sum_{n=1}^{N}{w_nlog{p_n}}\Big) $$ 其中,BP为惩罚因子,$p_n$为多元精度,$w_n$为多元精度对应的权重。
多元精度n-gram precision
原始多元精度:
原文:猫坐在垫子上
机器译文: the the the the the the the.
参考译文:The cat is on the mat.
- 1元精度 1-gram

6个词中,5个词命中译文,1元精度$p_1$为5/6。
- 2元精度 2-gram

2元词组的精度则是 3/5.
- 3元精度 3-gram

3元词组的精度为1/4.
-
4元精度 4-gram
4元词组的精度为0。
一般情况,1-gram可以代表原文有多少词被单独翻译出来,可以反映译文的充分性,2-gram以上可以反映译文的流畅性,它的值越高说明可读性越好。
-
异常情况
原文:猫坐在垫子上 机器译文: the the the the the the the. 参考译文:The cat is on the mat.
此时,1-gram匹配度为7/7,显然,此译文翻译并不充分,此问题为常用词干扰。
改进多元精度:

其中,$Count_{w_i}$为单词$w_i$在机器译文中出现的次数,$Ref_jCount_{w_i}$为单词$w_i$在第$j$个译文中出现的次数,$Count^{clp}_{w_i,j}$为单词$w_i$对于第$j$个参考译文的截断计数,$Count^{clp}$为单词$w_i$在所有参考翻译里的综合截断计数,$p_n$为各阶N-gram的精度,$p_n$的公式分子部分表示$n$元组在翻译译文和各参考译文中出现的最小次数之和,分母部分表示$n$元组在各参考译文中出现的最大次数之和。
此时对于异常情况:$Count^{clp}=2$,此时,一元精度为2/7,避免了常用词干扰问题。
因此,改进的多元精度得分可以用来衡量翻译评估的充分性和流畅性两个指标。
多元精度组合:
随着$n$的增大,精度得分总体成指数下降,采取几何加权平均,使各元精度起同等作用。


其中,$p_{ave}$为多元精度组合值,$p_n$为n元精度,$w_n$为各元权重。
通常,BLEU-4为经典指标,$N$取4,$w_n$取1/4。
惩罚因子:

其中,$c$是机器译文的词数,$r$是参考译文的词数。
惩罚因子主要用来惩罚机器译文与参考译文长度差距过大情况。
总结:
-
优点:方便、快速、结果有参考价值 。
-
缺点:
- 不考虑语言表达(语法)上的准确性;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定。
Rouge(Recall-Oriented Understudy for Gisting Evaluation),是评估自动文摘以及机器翻译的一组指标。它通过将自动生成的摘要或翻译与一组参考摘要(通常是人工生成的)进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考摘要之间的“相似度”。
Rouge-L中,L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。Rouge-L计算方式如下:

其中$LCS(X,Y)$是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数),$R_{lcs}$、$P_{lcs}$分别表示召回率和准确率。最后的$F_{lcs}$即是我们所说的Rouge-L。在DUC中,β被设置为一个很大的数,所以$Rouge_L$几乎只考虑了$R_{lcs}$,与上文所说的一般只考虑召回率对应。
模型在最后的inference中使用了beam search。
传统的搜索算法中,随着词序列的增长,每个位置都有一个词表级别的序列要遍历,找到所有序列再挑出最优解的计算量就太大了,beam search(集束搜索)则选择了概率最大的前k个。这个k值也叫做集束宽度(Beam Width)。也是这个搜索算法的唯一参数。如果一个序列深度有10000,我们取k=3 可以得到30000句话,选择前三个最优解。
一点思考:关于自然语言,如果用贪婪算法找到评分最高的解,不一定是最优解,要考虑到语言的局部相关性更大,而不是全局最优,这点上,beam search 虽然可能在剪枝的过程中丢弃了评分最高的解,但更大概率找到最合适的解。

Word Embedding是NLP中一组语言模型和特征学习技术的总称。这些技术会把词汇表中的单词或者短语映射成实数构成的向量上。
Word2Vec使用一层神经网络将one-hot(独热编码)形式的词向量映射到分布式形式的词向量。使用了Hierarchical softmax, negative sampling等技巧进行训练速度上的优化。
本次代码使用的是skip-gram model的方式进行训练。
Skip-Gram 的损失函数是通过将目标词汇的正例和负例使用二元对数回归(Binary Logistic Regeression)计算概率并相加得到的。损失函数公式为:


为二元对数回归中的正例概率,k为所取的负例个数,

为对负例的二元逻辑回归概率进行蒙特卡洛平均(Monte Carlo average)计算。
Word2Vector有2种机制:
- Skip-gram
输入词去找和它关联的词,计算更快。
- CBOW
输入关联的词去预测词。
本项目分别使用了Flickr8k、Flickr30k、MSCOCO数据集。
数据集下载链接分别为:
Flickr8k:
http://nlp.cs.illinois.edu/HockenmaierGroup/Framing_Image_Description/Flickr8k_Dataset.zip
http://nlp.cs.illinois.edu/HockenmaierGroup/Framing_Image_Description/Flickr8k_text.zip
Flickr30k:
http://shannon.cs.illinois.edu/DenotationGraph/data/flickr30k-images.tar
MSCOCO:
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/zips/val2014.zip
http://images.cocodataset.org/zips/test2014.zip
http://images.cocodataset.org/annotations/annotations_trainval2014.zip
http://images.cocodataset.org/annotations/image_info_test2014.zip
- 首先,数据集按照下表所示进行分割,分成训练集和测试集;

- 然后,根据token生成词汇表,将出现频率小于4的词统一设为UNK;
- 最后,将图片数据和其对应caption数据,打包存成TFRecord格式。
本项目主要实现了Show and Tell和Neural Baby Talk。
基础代码使用Google提供的,其之前在MSCOCO2015 Image Caption竞赛上夺得第一的Show and Tell模型基于TensorFlow的实现源码,即im2txt。
原代码包中,train和evaluate过程分别在不同的代码文件中,因此编写train_eval.py使得模型运行过程中,1个epoch分别进行一次train和evaluate过程,可实时观察模型训练过程中evaluate结果。 主要代码如下所示:
for i in range(epoch_num):
steps = int(step_per_epoch * (i + 1))
print('epoch{[', i, ']} goal steps :', steps)
# train 1 epoch
print('################ train ################')
p = os.popen(train_cmd.format(**{'input_file_pattern': FLAGS.train_input_file_pattern,
'inception_checkpoint_file': FLAGS.pretrained_model_checkpoint_file,
'train_dir': FLAGS.train_dir,
'train_inception': FLAGS.train_CNN,
'number_of_steps': steps,
'log_every_n_steps': FLAGS.log_every_n_steps,
'CNN_name': FLAGS.CNN_name,
'dataset_name': FLAGS.dataset_name,
'batch_size': FLAGS.batch_size}) + ckpt)
for l in p:
print(l.strip())
# eval
if steps < FLAGS.min_global_step:
print('Global step = ', steps,' < ', FLAGS.min_global_step,', ignore eval this epoch!')
continue
print('################ eval ################')
p = os.popen(eval_cmd.format(**{'input_file_pattern': FLAGS.eval_input_file_pattern,
'checkpoint_dir': FLAGS.train_dir,
'eval_dir': FLAGS.eval_dir,
'eval_interval_secs': FLAGS. eval_interval_secs,
'num_eval_examples': FLAGS.num_eval_examples,
'min_global_step': FLAGS.min_global_step,
'CNN_name': FLAGS.CNN_name,
'batch_size': FLAGS.batch_size}))
for l in p:
print(l.strip())
基础代码实现的模型为Inceptionv3+LSTM,考虑到Inceptionv4和Densenet在图像分类任务中,相比于Inceptionv3,能更好地学习到图像特征,因此,在模型中添加Inceptionv4和Densenet实现方式。
修改的代码集中在image_embedding.py中,即Encoder过程,在其中分别添加Inceptionv4和Densenet网络的实现过程。当建立Show and Tell模型时,根据指定的CNN名称,创建对应的网络模型。
BLEU
借助于nltk.translate.bleu_score包中的sentence_bleu计算模型输出描述语句与数据集中提供的token之间的各阶BLEU值。
BLEU计算的具体实现详情参见:https://www.nltk.org/_modules/nltk/translate/bleu_score.html
Rouge
指标利用Diego提供的py-rouge包进行计算,具体安装和使用说明参见:https://pypi.org/project/py-rouge/
主要修改build_mscoco_data.py,具体实现以下步骤:
-
判断train、val 、test的片区是否能够与线程数匹配整除;
-
取出源文件的图片信息和描述信息,生成包含图片id信息、图片名称以及五句描述话的namedtuple和 ImageMetadata;
-
生成图片词汇处理的词频表;
-
根据生成的image_metada、生成的词频表、shard thread等相关信息,多线程生成最后的tfrecord;
-
tfrecord中包含imageid、image source以及image filename。
Neural Baby Talk模型的基础代码使用论文作者提供的GitHub仓库中的代码(https://github.com/jiasenlu/NeuralBabyTalk)。
本模型代码是在pytorch框架上实现的,需要安装nvidia的docker,具体操作如下。
install docker-ce 18.06
-
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
-
sudo apt install docker.io
-
sudo snap install docker
-
sudo service docker start (can check the correctness of software installation)
-
Error: Failed to start docker.service: Unit docker.service is masked.
solution :
systemctl unmask docker.service systemctl unmask docker.socket systemctl start docker.service
update docker-ce to 18.09
-
https://www.cnblogs.com/Dicky-Zhang/p/7693416.html
install 18.09 docker-ce
sudo apt-get -y install docker-ce=5:18.09.0
3-0ubuntu-bionic
install nvidia-docker 2
-
following nvidia docker installation instruction
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f sudo apt-get purge -y nvidia-docker curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update sudo apt-get install -y nvidia-docker2 sudo pkill -SIGHUP dockerd docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
** run DockerFile to configure docker environment and creating necessaryproject files **
-
before executing bash cmd : sudo docker build -t nbt . ,revising DockerFile in nbt folder, comment five wget commands in DockerFile
follow certain steps :
-
sudo docker build -t nbt .
-
create certain folders and copy files into them
1 use following linux bash command to find out the container folders I currently use
sudo find / -print0 | grep -FzZ 'normal_coco_res101.yml'

2 cd into the \var\lib\docker\overlay2 find the folder which is revised recently and contain diff/workspace/neuralbabytalk folder 3 mk certain folders and copy files under this folder or sub-folders according to DockerFile instruction 4 Download get_stanford_models.sh from github coco-caption files,move it into tools/coco-caption folder located in neuralbabytalk workspace
-
run sudo docker build -t nbt . again
-
it works, and you can get the following result
-
execute following bash command to log in docker environment
-
COCO_IMAGES=/home/fandichao/dataset/datas
COCO_ANNOTATIONS=/home/fandichao/dataset/annotations
sudo nvidia-docker run --name nbt_container -it
-v $COCO_IMAGES:/workspace/neuralbabytalk/data/coco/images
-v $COCO_ANNOTATIONS:/workspace/neuralbabytalk/data/coco/annotations
--shm-size 8G -p 8888:8888 nbt /bin/bash -
However ,COCO_IMAGES and COCO_ANNOTATIONS variables didn't work
-
copy annotations folder and underlying files into merged/workspace/neuralbabytalk/data/coco folder under overlay2 folder
-
copy images folder and all coco images into above folder
-
revising 1. demo.py ,main.py 2. AttModel.py model.py under misc folder. 3. eval.py under pycocoevalcap folder
-
execute cmd to do normal training in docker system
python main.py --path_opt cfgs/normal_coco_res101.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 10 --start_from save/coco_nbt_1024
-
execute cmd to do normal evaluating in docker system
python main.py --path_opt cfgs/normal_coco_res101.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 30 --inference_only True --beam_size 3 --start_from save/coco_nbt_1024 --val_split test -
execute cmd to do robust training in docker system
python main.py --path_opt cfgs/robust_coco.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 13 --start_from save/robust_coco_1024
-
execute cmd to do robust training in docker system
-
python main.py --path_opt cfgs/robust_coco.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 30 --inference_only True --beam_size 3 --start_from save/robust_coco_nbt_1024
-
execute cmd to do inference in docker system
-
python demo.py --cbs True --cbs_tag_size 2 --cbs_mode unqiue --start_from save/coco_nbt_1024
Docker 重新进入
-
sudo docker service docker restart
-
docker ps -a
-
在docker 中的container ID 之内,找到需要用的container ID
-
docker start 170f2f9f46a0 (containerID)
-
docker exec -it 170f2f9f46a0 /bin/bash (containerID)
如何从Docker 环境中拷贝 相关文件
run a new terminal , execute following command when another terminal have already logged into docker environment.
bash
docker container cp nbt_container1:workspace/neuralbabytalk/save /home/fandichao/models
docker container cp nbt_container1:workspace/neuralbabytalk/visu /home/fandichao/models
docker container cp nbt_container1:workspace/neuralbabytalk/visu.json /home/fandichao/models
本项目分别训练了模型 Show and Tell(Inceptionv3-LSTM、Inceptionv4-LSTM及Densenet-LSTM)和Neural Baby Talk(Faster R-CNN + ResNet-101 + LSTM)。
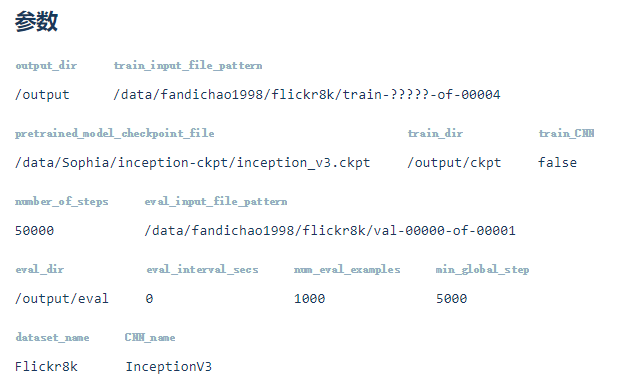
Flickr8k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/3kz4we05)。
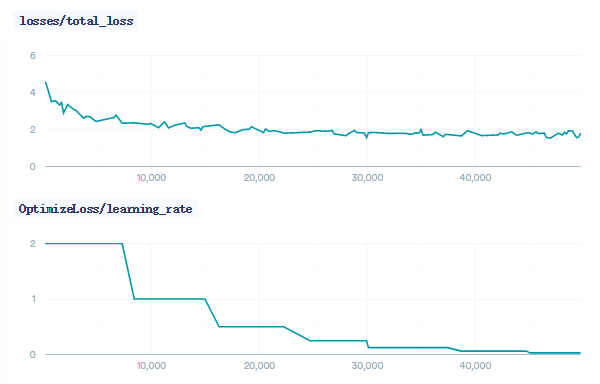
训练过程loss如下所示:
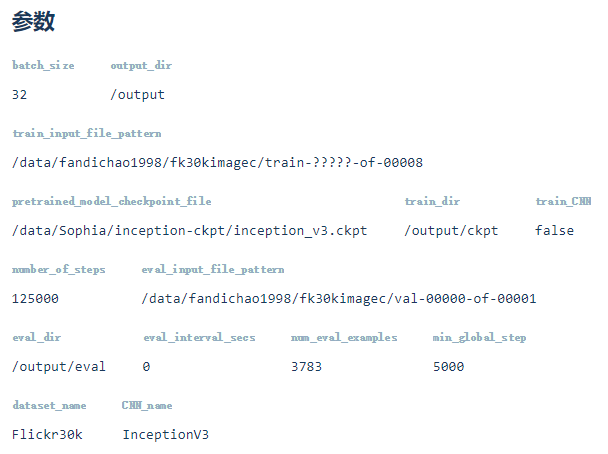
Flickr30k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/k7mvtn3x)。
训练过程loss如下所示:
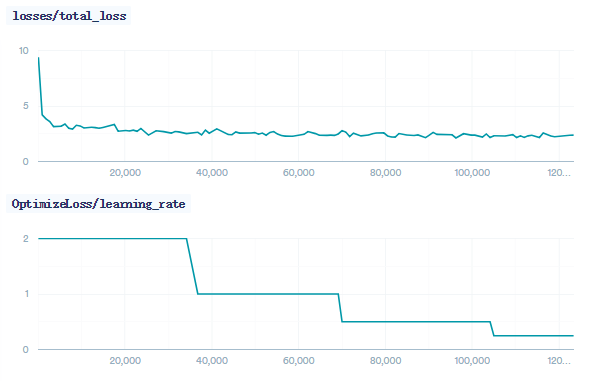
MSCOCO参数
因COCO数据集太大,没法传到tinymind上,因此此模型在本地进行训练,主要参数如下所示:
batch_size 32
embedding_size 512
num_lstm_units 512
lstm_dropout_keep_prob 0.7
dataset_name MSCOCO
optimizer SGD
initial_learning_rate 2.0
learning_rate_decay_factor 0.5
num_epochs_per_decay 8
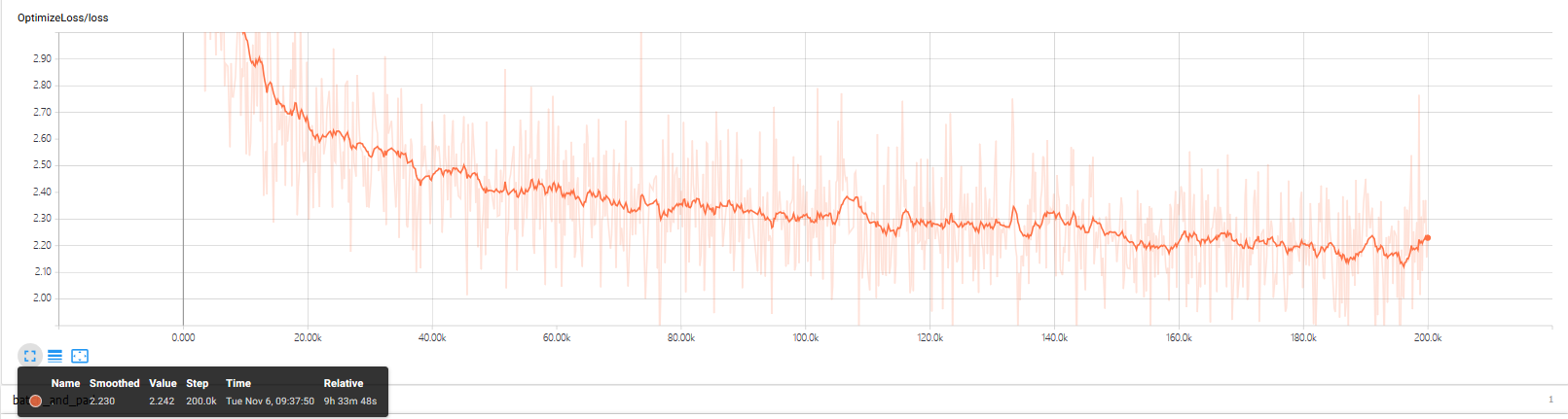
训练过程loss如下所示:
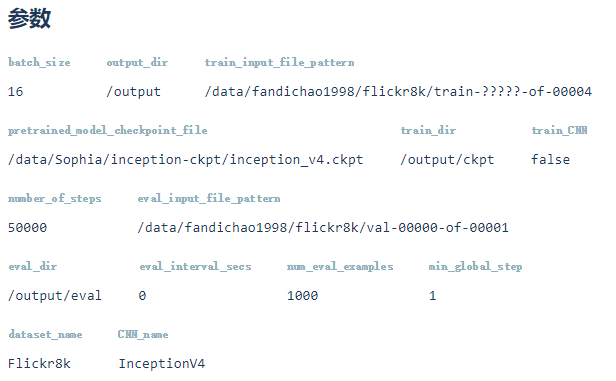
Flickr8k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/rgxdqi73)。
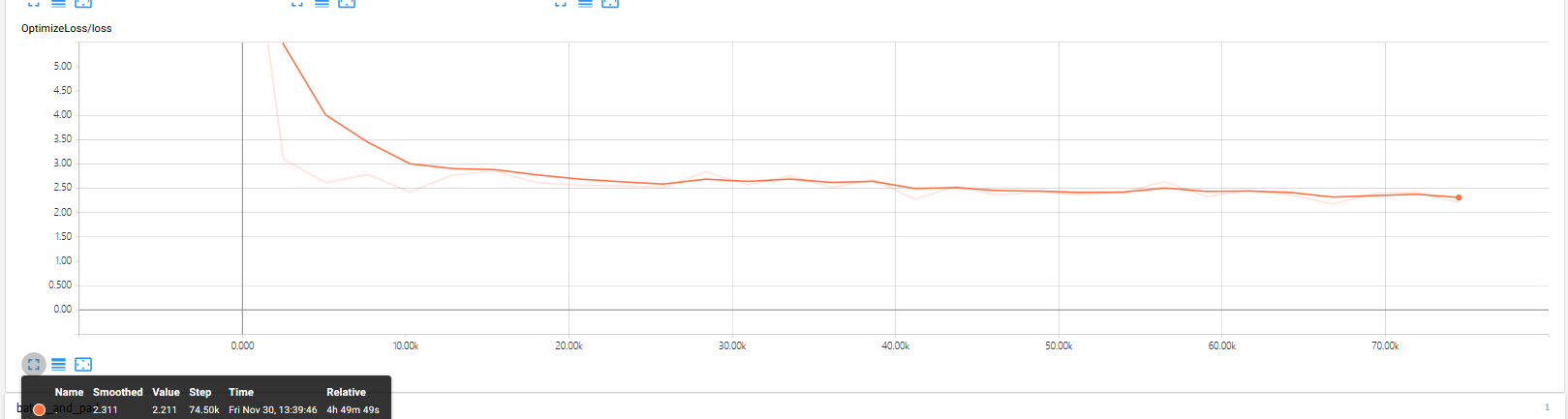
训练过程loss如下所示:

Flickr30k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/w3d26ob9)。

训练过程loss如下所示:
MSCOCO参数
因COCO数据集太大,没法传到tinymind上,因此此模型在本地进行训练,主要参数如下所示:
batch_size 32
embedding_size 512
num_lstm_units 512
lstm_dropout_keep_prob 0.7
dataset_name MSCOCO
optimizer SGD
initial_learning_rate 2.0
learning_rate_decay_factor 0.5
num_epochs_per_decay 8
训练过程loss如下所示:
Flickr8k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/gwv8h4v0)。
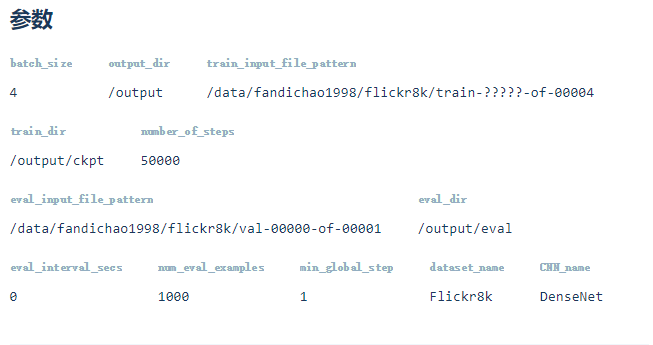
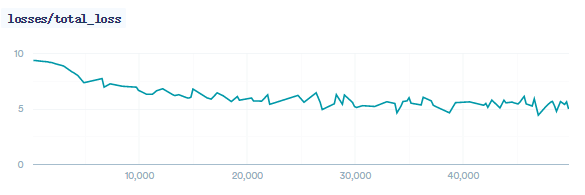
训练过程loss如下所示:
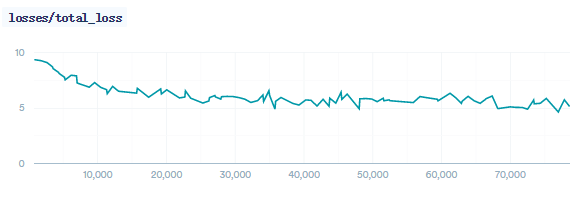
Flickr30k参数
此模型在tinymind上运行,参数如下图所示(https://www.tinymind.com/executions/zj1eifub)。

训练过程loss如下所示:
因为项目时间和机器有限,没有在ImageNet上训练Densenet分类模型作为预训练模型,所以,Densenet模型没有可加载的预训练模型,导致训练结果并不好,故后续的结果分析不考虑DenseNet-LSTM模型。
**Detection model:**Faster R-CNN
**Region feature:**预训练的ResNet-101
2层LSTM的隐层大小为1024
attention layer隐藏单元数量为512
input word embedding大小为512
优化器:Adam
学习速率:初始学习速率为$5\times10^{-4}$,每3个epoch衰减至原来的0.8倍
epoch数量:训练了10个epochs
在训练过程中,没有对CNN进行finetune
batch size:COCO(20)
Flickr8k数据集上Show and Tell模型训练结果指标如下所示:

从上表中可以看出,使用InceptionV3或InceptionV4作为编码器,结果差距不大,使用InceptionV3模型效果稍好。
Flickr8k数据集上Show and Tell模型训练结果指标如下所示:

从上表中可以看出,使用InceptionV3或InceptionV4作为编码器,结果差距不大,使用InceptionV3模型效果稍好。
MSCOCO数据集上各模型训练结果指标如下所示:
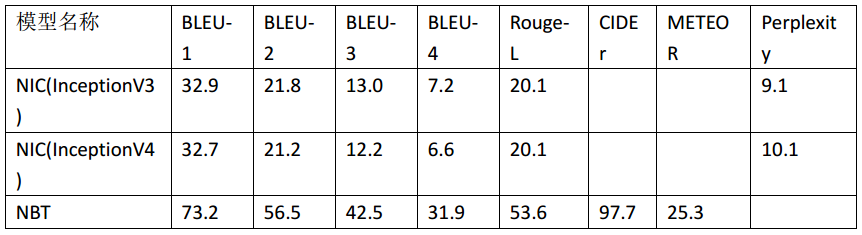
从上表中可以看出,Neural Baby Talk模型明显优于Show and Tell模型。

对于上图Show and Tell各模型得到结果如下表所示:
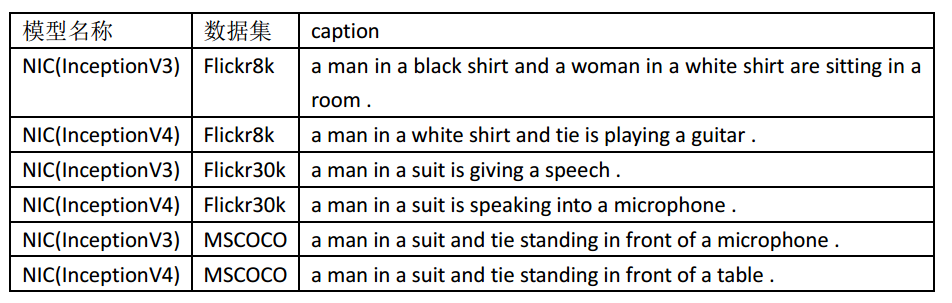
从上表可以看出:
-
在Flickr8k数据集上训练出的模型,得到的结果较差,只能识别出图中人物和服装颜色,无法正确识别出人物的行为;
-
Flickr30k数据集上训练出的模型,得到的结果还不错,可以识别出人物穿着西装(而不是简单的服装颜色),以及人物的行为,在麦克风前做演讲;
-
MSCOCO数据集上训练出的模型,未能描述出人物演讲的行为,但整句描述也并没有错误,并且识别出人物穿着西装还打着领带,站在桌子/麦克风前。

对于上图,各模型得到的caption如下表所示:
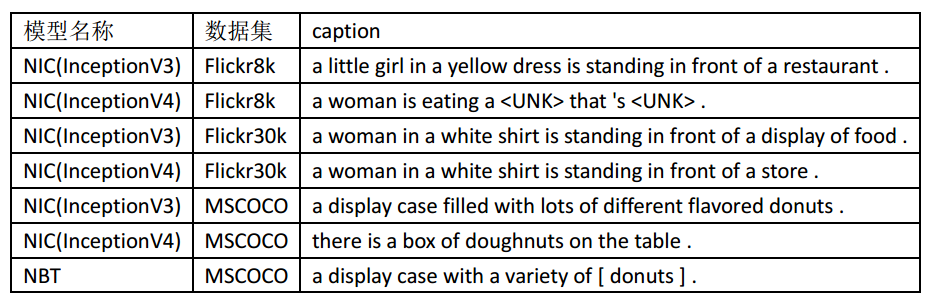
从上表可以看出:
-
在Flickr8k数据集上训练出的Show and Tell模型,得到的结果很差,可能因为词汇量和训练样本过少;
-
Flickr30k数据集上训练出的Show and Tell模型,得到的结果也比较差,只识别对了food食物,并错误第识别出了图中并不存在的人物,可能因为训练样本中人物出现次数很多;
-
MSCOCO数据集上训练出的Show and Tell模型,得到的结果还不错,正确地识别出了展示柜中放置的各种味道的甜甜圈。
-
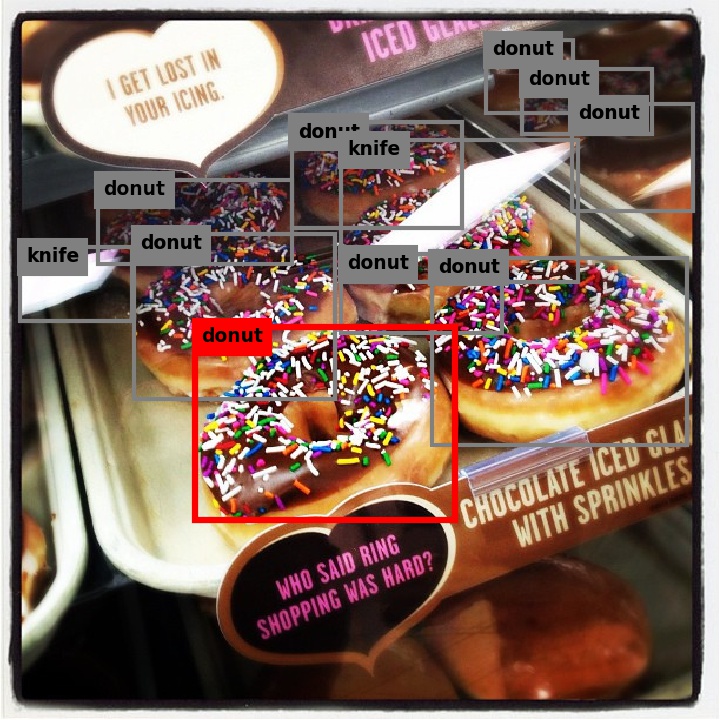
MSCOCO数据集上训练出的Neural Baby Talk模型,得到的结果很好,言简意赅地描述清楚了图中物体,其中“[]”框起来的是视觉词汇(目标检测器在图中区域识别的结果),并对视觉词汇甜甜圈做了复数处理,目标检测结果如下图所示,其中彩色的框是采用了的视觉词汇,灰色的框为舍弃掉的视觉词汇。

对于上图,各模型得到的caption如下表所示:
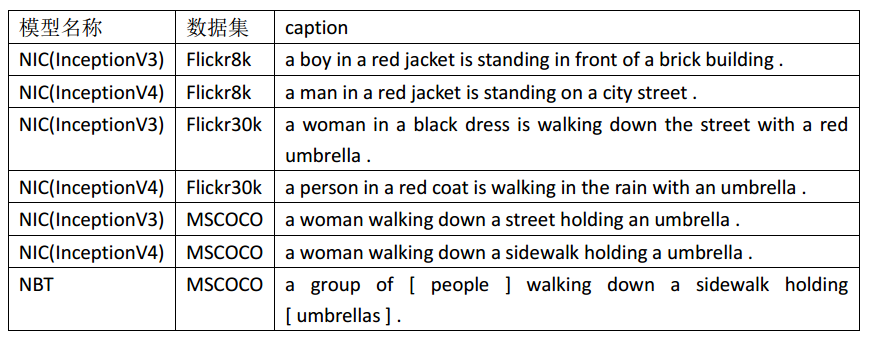
从上表可以看出:
-
在Flickr8k数据集上训练出的Show and Tell模型,得到的结果较差,女孩识别成了男孩,只识别对了brick building砖体建筑,黑白的图片错误地识别出人物穿着的颜色为红色;
-
Flickr30k数据集上训练出的Show and Tell模型,得到的结果还可以,识别出了图中的一位女性,并且识别出人物拿着伞在街上/雨中走,但是对于黑白图片错误的别处出其衣着颜色;
-
MSCOCO数据集上训练出的Show and Tell模型,得到的结果还不错,正确地识别出了图中女性拿着伞在街上/人行道走,但是只识别出了一个人物,而图中有多个人物。
-
MSCOCO数据集上训练出的Neural Baby Talk模型,得到的结果很好,言简意赅地描述清楚了图中人物及其行为,一群人拿着伞走在人行道上,其中“[]”框起来的是视觉词汇(目标检测器在图中区域识别的结果),并对视觉词汇伞做了复数处理。

国内外很多厂商有云端服务器可用,各厂商服务器均可,本例子中使用vultr的云服务器,价格较低。
vultr网址:https://my.vultr.com
注册后需要充值10美金,这里感觉还是挺实惠的……在该页面选取服务器类型:

(1)推荐亚洲地区选择日本新加坡等地,延迟会比较低。
(2)操作系统选择比较熟悉的,我这里选择了和程序运行环境相匹配的ubuntu18.04
(3)服务器规模选择了3.5美金的,2.5美金的只有IPV6协议,后续还需要额外链接IPV4就很不方便。(在上面运行较大的程序时512m的内存并不充足,我们需要自己设置交换区增加虚拟内存,后续会详细说明)
(4)下面其他选项不需要填选任何东西,直接确定就行。(如果不是你的第一个服务器,你也可以直接更一些设置比如防火墙,ssh秘钥等)。
接下来我们需要配置防火墙设置,暴露端口,并且根据系统需要,在服务器上安装运行环境。
进入服务器页面,观察到服务器已经在运行,之后进入防火墙选项卡(Firewall)进行设置。
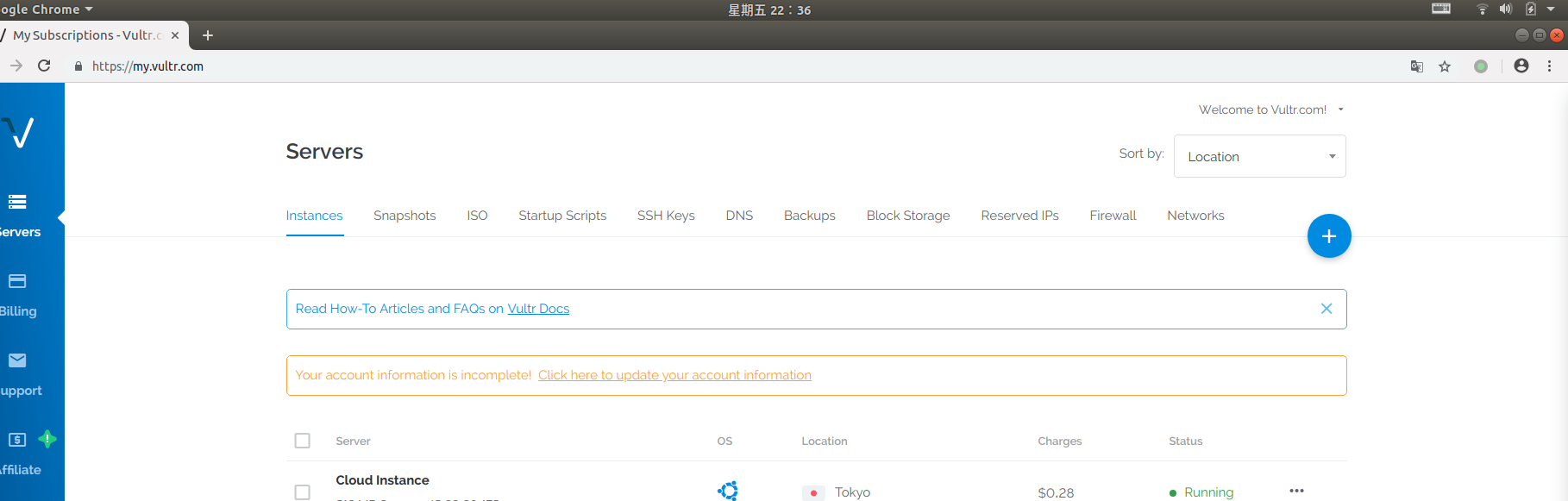

(1)第一步,配以一个防火墙规则组:进入后Firewall选项卡之后,ssh协议默认端口为22(vultr网站的默认设置,且无法更改),点击加号增加规则到防火墙规则组中。图中我们额外增加了http协议的5000端口作为系统的端口来使用(系统启动时默认端口为5000),其他端口视情况可自行增加。其中anywhere选项(0.0.0.0/0)意味着任何地点任何ip都可以使用你刚刚启用的端口。(这里ssh协议用来连接服务器配置服务器,所以为了安全起见,可以把允许访问的ip地址设置为本机ip)。
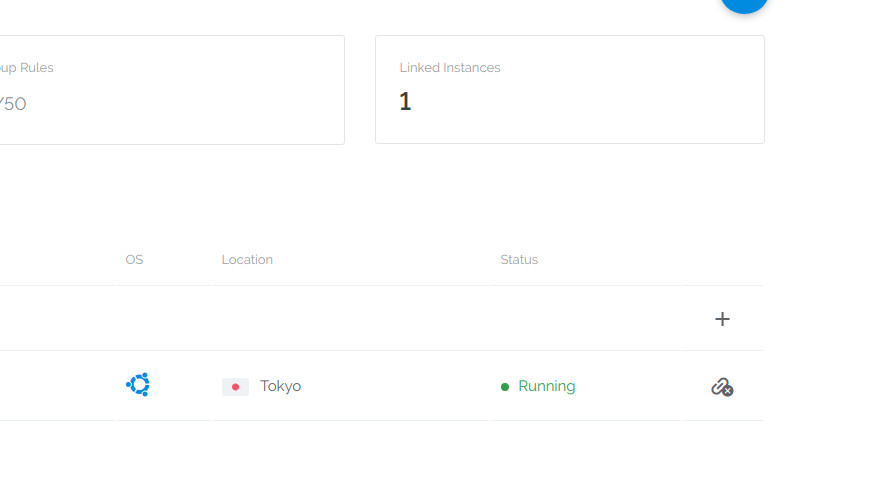
(2)第二步,点击下方的linked instances,将防火墙规则组配置到你的服务器,如下图所示,即为配置成功。
这里我们使用ubuntu链接服务器,你也可以使用其他系统连接服务器。
(1)连接服务器,使用我们刚才开放的ssh协议22号端口。首先确认服务器在运行状态,我们要使用IP地址,用户名,服务器密码,在本地ubuntu系统上打开终端,假设服务器地址为8.8.8.8使用命令:
sudo ssh -t root@8.8.8.8 -p 22连接上之后会有警告,属于正常,在提示后输入你的密码,回车即可登录到你的服务器。(如果无法连接,请检查是否输入错误,密码过于复杂可直接复制,右键粘贴)
如果确认输入正确依旧无法连接,可能是ip地址延迟过高或者被墙掉,可以使用ping+ip地址的命令来查看服务器地址是否可以连通,若IP地址为8.8.8.8命令如下:
ping 8.8.8.8如果无法连通,请返回第一步,重新建立其他国家服务器进行后续操作。
(2)配置程序需要的环境,(ubuntu18.04自带python3,如果用其他程序,请先安装python3)自行安装tensorflow,OpenCV2,flask
安装时使用命令:
pip3 install --no-cache-dir tensorflow opencv-python flask我们使用pip3来将程序安装到python3的环境下。这里面的参数--no-cache-dir是因为服务器内存很小,所以我们采用不保存pip缓存的模式来安装,否则可能会报错。如果运行行为缺少模块,可尝试安装相应模块后再运行,也可使用”pip3 install --no-cache-dir 软件包名字“的安装命令来安装补齐。
由于我们启动的服务器内存较小,因此我们通过设置虚拟内存来增大内存空间,运行本系统大概需要4G空间,依次执行下列命令:
解决方案 :swap 设置虚拟内存
ubuntu18.04默认的swap文件在根目录/下,名字是swapfile
1.查看交换分区大小
free -m
在创建完毕后也可以用这个命令查看内存情况
2.创建一个swap文件
sudo dd if=/dev/zero of=swap bs=1024 count=4000000
创建的交换文件名是swap,后面的40000000是4g的意思,可以按照自己的需要更改
3.创建swap文件系统
sudo mkswap -f swap
4.开启swap
sudo swapon swap
5.关闭和删除原来的swapfile
sudo swapoff swapfile
sudo rm /swapfile
6.设置开机启动
sudo vim /etc/fstab
按一下i键,进入插入编辑模式,将里面的swapfile改为swap vim编辑器编辑完毕之后,按一下esc键,再按shift+;(冒号),输入qw,回车即可保存退出。
系统的文件置于im2txt文件中假设将其下载的地址为/download/im2txt.gz,使用下列命令将压缩包上传至服务器的workspace目录下:
mkdir workspace
scp /download/im2txt.gz root@8.8.8.8 /workspace使用如下命令对压缩包进行解压:
tar -zxvf 压缩文件名在例子中,我们将系统布置到workspace文件夹中
执行cd命令,进入im2txt文件夹中:
cd /workspace/im2txt执行python文件display.py:
nohup python3 display.py &
这里我们使用python3运行程序,利用nohup命令使程序命令无视终端挂起信号,可以后台运行。
运行成功后,程序显示暴露端口为5000.
在任意浏览器中,打开如下格式的网址,假设服务器地址为8.8.8.8:
首先选择翻译语言,本系统支持中英两种语言。
其次选择上传的照片点击上传,上传会花费一定的时间,请耐心等待。
最后页面会输出结果。
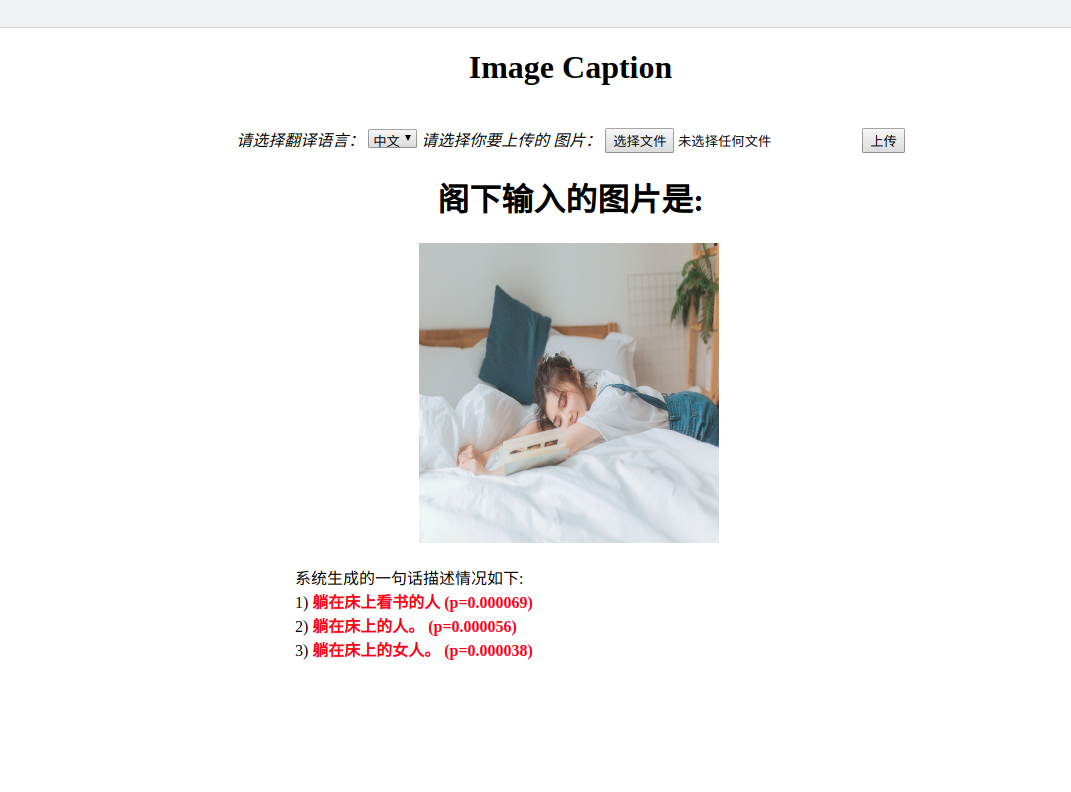
注:支持上传的文件格式为jpg格式,如果格式错误将会提示请上传正确格式的文件。
因为代码中学习速率设定为8个epoch下降50%,但是一个epoch需要多少步均是按照COCO数据集的训练部分图片数量计算的,因此使用Flickr8k或Flickr30k数据集时要相应地进行修改和处理。
此参数的含义是每个epoch中examples的数量,即训练数据集中图片数量。
原代码使用的数据集是MSCOCO,训练数据集数量为117215,而原代码此参数设为586363,约为训练数据数量的5倍。
此参数的主要作用是用来计算学习速率衰减。
原代码在建立CNN模型时,调用image_embedding.py的inception_v3()接口实现。
我们希望将inception_v3替换为inception_v4,故在image_embedding.py代码中仿照inception_v3()实现inception_v4()接口。
出现错误:
Traceback (most recent call last):
File "./train.py", line 25, in <module>
from im2txt import show_and_tell_model
File "C:\Users\YuRong\AI实战\Image Caption看图说话机器人\Code\im2txt\im2txt\show_and_tell_model.py", line 29, in <module>
from im2txt.ops import image_embedding
File "C:\Users\YuRong\AI实战\Image Caption看图说话机器人\Code\im2txt\im2txt\ops\image_embedding.py", line 27, in <module>
from tensorflow.contrib.slim.python.slim.nets.inception_v4 import inception_v4_base
ModuleNotFoundError: No module named 'tensorflow.contrib.slim.python.slim.nets.inception_v4'
原因:
查看python的site-packages下slim的nets里,没有inception_v4,故报此错误。
解决方案:
将slim下的nets和preprocessing文件夹拷贝到代码所在路径下,通过代码
from nets import inception
导入inception包,而inception.py中,会通过其代码
from nets.inception_v4 import inception_v4
from nets.inception_v4 import inception_v4_arg_scope
from nets.inception_v4 import inception_v4_base
导入inception_v4_base。
进入eval阶段后,循环进行eval问题
模型运行日志如下:
################eval################
INFO:tensorflow:Creating eval directory: /output/eval
INFO:tensorflow:Prefetching values from 1 files matching /data/fandichao1998/flickr8k/val-00000-of-00001
INFO:tensorflow:Starting evaluation at 2018-11-10-19:38:39
2018-11-10 19:38:40.003090: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:898] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-11-10 19:38:40.003584: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1356] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:00:04.0
totalMemory: 11.17GiB freeMemory: 11.09GiB
2018-11-10 19:38:40.003661: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-11-10 19:38:40.324242: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-11-10 19:38:40.324356: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-11-10 19:38:40.324374: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-11-10 19:38:40.324744: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10750 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)
INFO:tensorflow:Loading model from checkpoint: /output/ckpt/model.ckpt-5049
INFO:tensorflow:Restoring parameters from /output/ckpt/model.ckpt-5049
INFO:tensorflow:Successfully loaded model.ckpt-5049 at global step = 5049.
INFO:tensorflow:Computed losses for 1 of 32 batches.
INFO:tensorflow:Perplexity = 17.806959 (13 sec)
INFO:tensorflow:Finished processing evaluation at global step 5049.
INFO:tensorflow:Starting evaluation at 2018-11-10-19:48:39
2018-11-10 19:48:39.924730: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-11-10 19:48:39.924860: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-11-10 19:48:39.924902: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-11-10 19:48:39.924918: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-11-10 19:48:39.925054: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10750 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)
INFO:tensorflow:Loading model from checkpoint: /output/ckpt/model.ckpt-5049
INFO:tensorflow:Restoring parameters from /output/ckpt/model.ckpt-5049
INFO:tensorflow:Successfully loaded model.ckpt-5049 at global step = 5049.
INFO:tensorflow:Computed losses for 1 of 32 batches.
INFO:tensorflow:Perplexity = 17.800203 (13 sec)
INFO:tensorflow:Finished processing evaluation at global step 5049.
INFO:tensorflow:Starting evaluation at 2018-11-10-19:58:40
2018-11-10 19:58:40.014333: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-11-10 19:58:40.014438: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-11-10 19:58:40.014500: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-11-10 19:58:40.014563: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-11-10 19:58:40.014802: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10750 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)
INFO:tensorflow:Loading model from checkpoint: /output/ckpt/model.ckpt-5049
INFO:tensorflow:Restoring parameters from /output/ckpt/model.ckpt-5049
INFO:tensorflow:Successfully loaded model.ckpt-5049 at global step = 5049.
INFO:tensorflow:Computed losses for 1 of 32 batches.
INFO:tensorflow:Perplexity = 17.800204 (13 sec)
INFO:tensorflow:Finished processing evaluation at global step 5049.
原因:
evaluate.py的run()函数中,实际运行eval过程的代码的写在一个while ture死循环中,目的是令eval过程每间隔指定时间后evaluate一次。
while True:
start = time.time()
tf.logging.info("Starting evaluation at " + time.strftime("%Y-%m-%d-%H:%M:%S", time.localtime()))
run_once(model, saver, summary_writer, summary_op)
time_to_next_eval = start + FLAGS.eval_interval_secs - time.time()
if time_to_next_eval > 0:
time.sleep(time_to_next_eval)
解决方案:
代码改为,若命令行输入参数eval_interval_secs为0,则只evaluate一次。
eval_once = (FLAGS.eval_interval_secs == 0)
# Run a new evaluation run every eval_interval_secs.
while True:
start = time.time()
tf.logging.info("Starting evaluation at " + time.strftime(
"%Y-%m-%d-%H:%M:%S", time.localtime()))
run_once(model, saver, summary_writer, summary_op)
if eval_once:
break
time_to_next_eval = start + FLAGS.eval_interval_secs - time.time()
if time_to_next_eval > 0:
time.sleep(time_to_next
错误信息:
INFO:tensorflow:Restoring parameters from E:\01人工智能学习\0数据\output\train\model.ckpt-0
2018-11-12 10:23:55.239769: W T:\src\github\tensorflow\tensorflow\core\framework\op_kernel.cc:1275] OP_REQUIRES failed at save_restore_v2_ops.cc:184 : Not found: Key InceptionV4/Conv2d_1a_3x3/BatchNorm/beta not found in checkpoint
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.NotFoundError'>, Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Key InceptionV4/Conv2d_1a_3x3/BatchNorm/beta not found in checkpoint
[[Node: save_1/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, ..., DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save_1/Const_0_0, save_1/RestoreV2/tensor_names, save_1/RestoreV2/shape_and_slices)]]
[[Node: save_1/RestoreV2/_231 = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_312_save_1/RestoreV2", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]]
Caused by op 'save_1/RestoreV2', defined at:
File "./train.py", line 122, in <module>
tf.app.run()
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\platform\app.py", line 125, in run
_sys.exit(main(argv))
File "./train.py", line 107, in main
saver = tf.train.Saver(max_to_keep=training_config.max_checkpoints_to_keep)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 1281, in __init__
self.build()
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 1293, in build
self._build(self._filename, build_save=True, build_restore=True)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 1330, in _build
build_save=build_save, build_restore=build_restore)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 778, in _build_internal
restore_sequentially, reshape)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 397, in _AddRestoreOps
restore_sequentially)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 829, in bulk_restore
return io_ops.restore_v2(filename_tensor, names, slices, dtypes)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_io_ops.py", line 1546, in restore_v2
shape_and_slices=shape_and_slices, dtypes=dtypes, name=name)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\util\deprecation.py", line 454, in new_func
return func(*args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 3155, in create_op
op_def=op_def)
File "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 1717, in __init__
self._traceback = tf_stack.extract_stack()
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Key InceptionV4/Conv2d_1a_3x3/BatchNorm/beta not found in checkpoint
[[Node: save_1/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, ..., DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save_1/Const_0_0, save_1/RestoreV2/tensor_names, save_1/RestoreV2/shape_and_slices)]]
[[Node: save_1/RestoreV2/_231 = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_312_save_1/RestoreV2", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]]
初步判断为代码建立的图和checkpoint中的不匹配,因此初始化数据加载不进去。
在本地加载ckpt报错,在tinymind上可以正常加载和运行。
原因:
本地环境之前运行过InceptionV3模型,在TrainDir中自动保存了CheckPoint,因此,在我运行代码时,创建的是InceptionV4的网络结构,而加载的是TrainDir最新训练得到的InceptionV3的CheckPoint,因此,加载失败。
解决方案:
清空TrainDir下的CheckPoint。
sudo snap install docker
error: cnanot perform the following tasks:
- download snap "docker" (321) from channel "stable"
解决方案 :打开VPN
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
zsh: command not found: curl
gpg: 找不到有效的 OpenPGP 数据。
解决方法: 重新下载安装curl,sudo apt-get install curl
$ sudo apt-get install -y nvidia-docker2
正在读取软件包列表... 完成
正在分析软件包的依赖关系树
正在读取状态信息... 完成
有一些软件包无法被安装。如果您用的是 unstable 发行版,这也许是因为系统无法达到您要求的状态造成的。该版本中可能会有一些您需要的软件包尚未被创建或是它们已被从新到(Incoming)目录移出。下列信息可能会对解决问题有所帮助:
下列软件包有未满足的依赖关系:
nvidia-docker2 : 依赖: docker-ce (= 5:18.09.0~3-0~ubuntu-bionic) 但无法安装它 或
docker-ee (= 5:18.09.0~3-0~ubuntu-bionic) 但无法安装它
E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破坏了软件包间的依赖关系。
原因: 安装的是 docker-ce 18.06 与需要的 docker-ce 18.09 不相符,需要安装 docker 18.09
使用 apt-cache madison docker-ce 没有可用的版本
解决方法: 根据自己的源,找到需要的docker-ce的版本所有修改的sourcelist的方法。
https://www.cnblogs.com/Dicky-Zhang/p/7693416.html
我用的是阿里云,修改正确的阿里云的源地址
使用下面的语句进行安装
sudo apt-get install docker-ce=5:18.09.0~3-0~ubuntu-bionic
删除 --queit 否则无法 状态
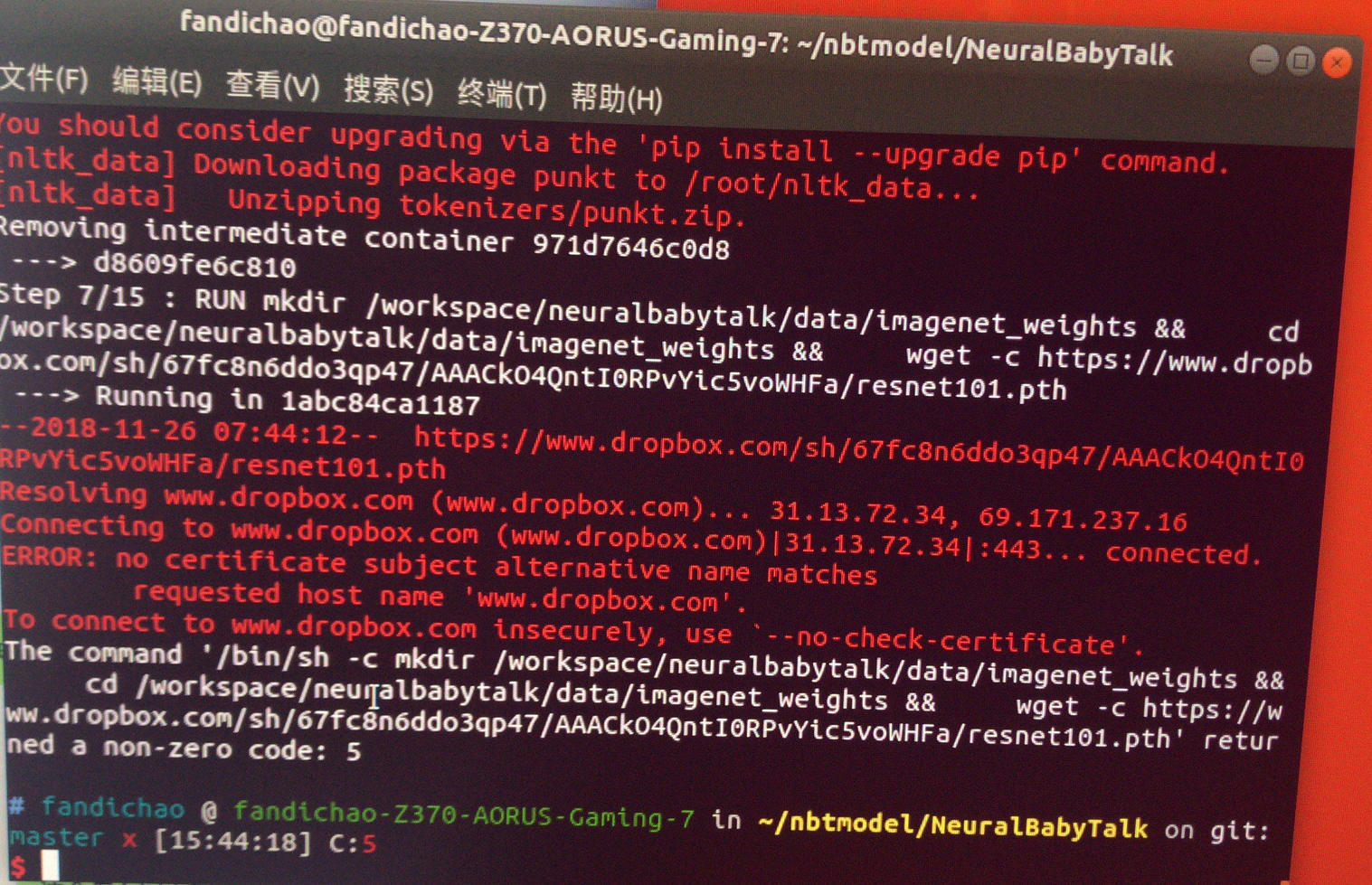
修改DockerFile文件,注释五条wget 语句,在环境中创建相应的文件夹,拷贝对应的文件到制定的文件夹中。
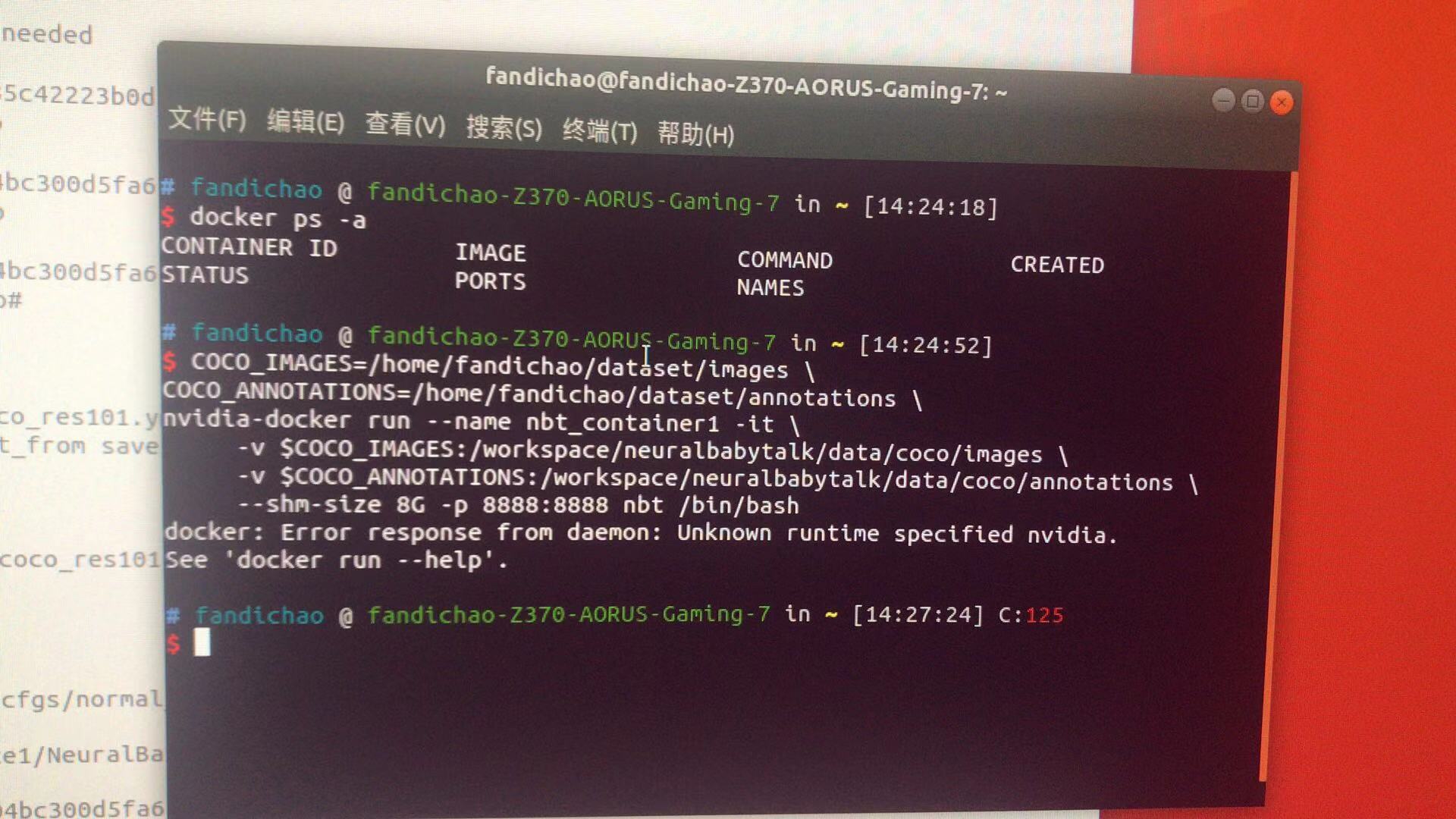
解决方法 :
安装成功时候,执行下面的命令即可:
sudo docker service docker restart
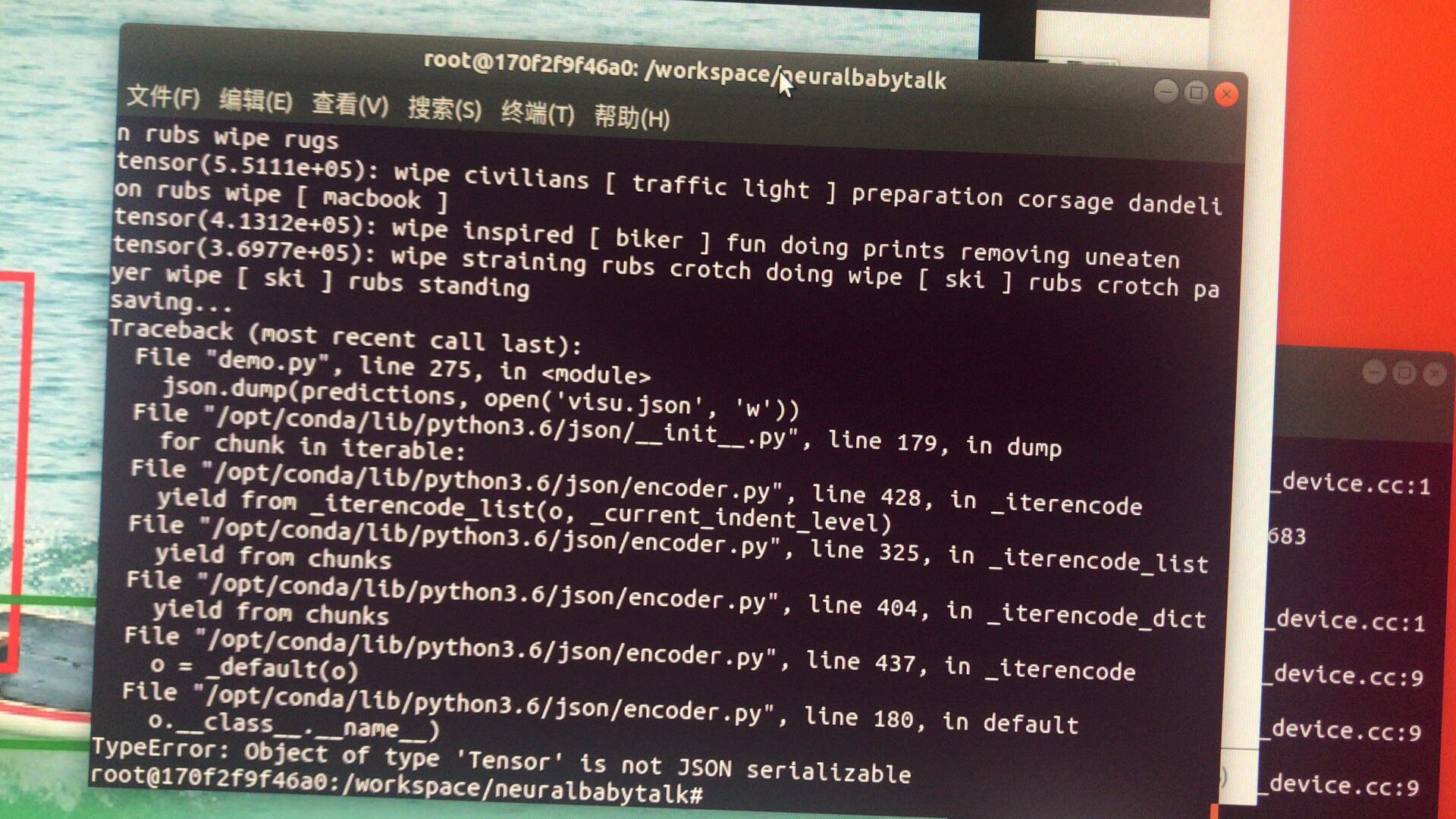
原因:
代码中进行 json dump 的list prediction 中的存储的元素中有tensor 对象,不能被序列化
解决方案:
修改 demo.py 不存入 tensor 对象,存入 string 对象就可以了
运行 main.py 代码中由于调试,具有pdb 代码,会中断程序。 找到删除就行了
需要 对encoding 进行正确选择,encoding='iso-8859-1' 。
读取和写入需要rb、wb的方式。
File "main.py", line 363, in <module>
lang_stats = eval(opt)
File "main.py", line 175, in eval
lang_stats = utils.noc_eval(predictions, str(1), opt.val_split, opt)
File "/workspace/neuralbabytalk/misc/utils.py", line 316, in noc_eval
out = score_dcc(gt_template_novel, gt_template_train, pred, noc_object, split, cache_path)
File "tools/sentence_gen_tools/coco_eval.py", line 109, in score_dcc
gt_json_novel = read_json(gt_template_novel % (word, dset))
File "tools/sentence_gen_tools/coco_eval.py", line 29, in read_json
j_file = open(t_file).read()
FileNotFoundError: [Errno 2] No such file or directory: 'data/coco_noc/annotations/captions_split_set_bus_val_test_novel2014.json'
出现这种问题, 可能是没有创建 coco_noc/annotations 目录导致,所以创建目录。但是没有相关的文件,导致了这个错误。可能是在创建的时候出现了一些问题,而且之前环境创建的时候,没有创建captions_split_set_bus_val_test_novel2014.json等相关文件。
Exception ignored in: <bound method _DataLoaderIter.__del__ of <torch.utils.data.dataloader._DataLoaderIter object at 0x7f8469426940>>
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 349, in __del__
self._shutdown_workers()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 328, in _shutdown_workers
self.worker_result_queue.get()
File "/opt/conda/lib/python3.6/multiprocessing/queues.py", line 337, in get
return _ForkingPickler.loads(res)
File "/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/opt/conda/lib/python3.6/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/opt/conda/lib/python3.6/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/opt/conda/lib/python3.6/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/opt/conda/lib/python3.6/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/opt/conda/lib/python3.6/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/opt/conda/lib/python3.6/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/opt/conda/lib/python3.6/multiprocessing/connection.py", line 383, in _recv
raise EOFError
EOFError:
这种是内部出现的问题,不知道是什么
出现“EOFError Python”,就意味着发现了一个不期望的文件尾,而这个文件尾通常是Ctrl-d引起的。
https://blog.csdn.net/u011961856/article/details/78043831
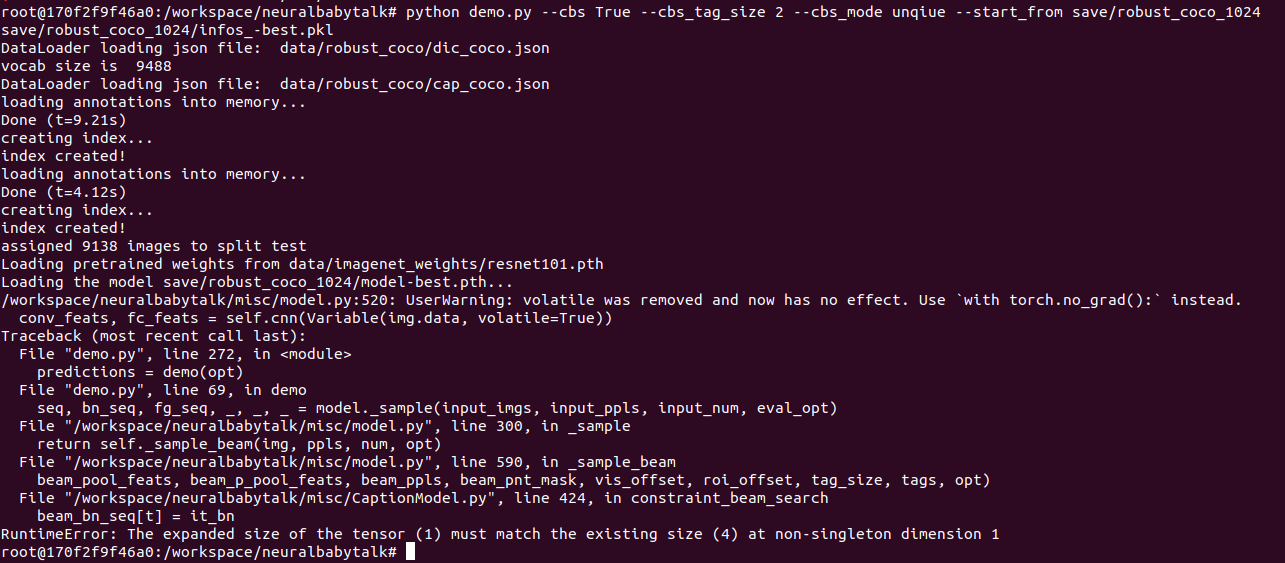
pytorch 中的广播 shape 不一致
解决方式:在安装的时候使用--no-cache-dir的命令,不保存安装缓存。
解决方式,设置虚拟内存:
ubuntu18.04默认的swap文件在根目录/下,名字是swapfile
1.查看交换分区大小
free -m
在创建完毕后也可以用这个命令查看内存情况
2.创建一个swap文件
sudo dd if=/dev/zero of=swap bs=1024 count=4000000
创建的交换文件名是swap,后面的40000000是4g的意思,可以按照自己的需要更改
3.创建swap文件系统
sudo mkswap -f swap
4.开启swap
sudo swapon swap
5.关闭和删除原来的swapfile
sudo swapoff swapfile
sudo rm /swapfile
6.设置开机启动
sudo vim /etc/fstab
解决方式:使用如下命令忽略挂起命令:
nohup python3 display.py &解决方式:直接使用官方维护的安装脚本进行安装
1.首先安装curl:
sudo apt-get install -y curl
2.然后使用docker自行维护的脚本来安装docker:
$ curl -fsSL https://get.docker.com -o get-docker.sh
$ sudo sh get-docker.sh
使用如下命令:
代理服务器可以在启动并运行后阻止与Web应用程序的连接。如果您位于代理服务器后面,请使用以下ENV命令将以下行添加到Dockerfile中,以指定代理服务器的主机和端口:
# Set proxy server, replace host:port with values for your servers
ENV http_proxy host:port
ENV https_proxy host:port
-
Show and Tell 模型运行结果指标分数与原论文有差距,例如,论文中在Flickr8k数据集上训练模型的BLEU-1值为63,本项目为59.7;
-
因时间不足,Neural Baby Talk 模型保存结果为pth类型,与Show and Tell 的ckpt类型文件不同,且NBT需要Docker框架支持,因此,未能集成进产品中。
-
因为项目时间和机器性能有限,没有在ImageNet上训练Densenet作为预训练模型,所以,使用Densenet的NIC模型没有可加载的预训练模型,导致训练结果并不好。
-
将评价指标融入到模型的目标函数中;
-
Neural Baby Talk 模型训练了10个epochs,而论文中是50个epochs,因此可以考虑加大训练步数;
-
优化产品,制作移动app,随手拍照,即可识别图片内容。
-
项目开始时先制定好开发计划,然后按计划进行执行,执行过程中合理地规划每天学习时间;
-
遇到不懂的问题,首先执行666法则,未解决的问题与组员及时进行讨论,未讨论出结果的再向老师和助教提问,避免在一个问题上死磕浪费时间和精力;
-
多学习几种主流的框架和语言,使得能够在不同环境中进行编程,以免要使用的代码包基于别的框架编写,导致程序看不懂;
-
团队协作非常重要,组员之间要及时沟通和交流,加大知识分享,避免重复工作。