
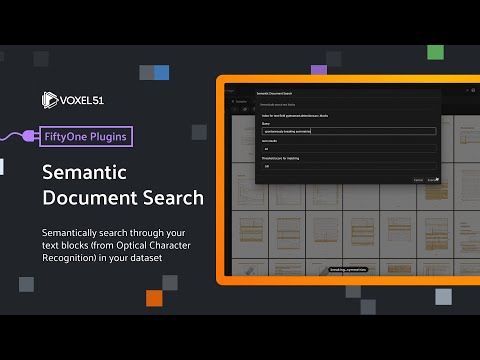
This plugin is a Python plugin that allows you to semantically search through your text blocks (from Optical Character Recognition) in your dataset.
It uses a Qdrant index, with the GTE-base model from Hugging Face's Sentence Transformers library.
You will need to have text blocks in your dataset. You can do this with the PyTesseract OCR plugin.
Create a vector index for your text blocks with the create_semantic_document_index operator. You can then use the semantically_search_documents operator to search through your text blocks.
If you have multiple detections with text blocks, you can create multiple indexes. The index is stored in Qdrant with the collection name <dataset_name>_sds_<field_name>. When you use the semantically_search_documents operator, you can specify which index to use.
Download the plugin with the following command:
fiftyone plugins download https://github.com/jacobmarks/semantic-document-search-pluginYou will need to install the Sentence Transformers library, and the Qdrant client Python library, which can be achieved with
fiftyone plugins requirements @jacobmarks/semantic_document_search --installYou will also need to have a Qdrant instance running. You can do this with Docker once you have your Docker daemon running:
docker run -p "6333:6333" -p "6334:6334" -d qdrant/qdrantThis semantic search plugin is in many ways analogous to the keyword search plugin, and is likewise designed to be used with the PyTesseract OCR plugin.
You can install the PyTesseract OCR plugin with the following command:
fiftyone plugins download https://github.com/jacobmarks/pytesseract-ocr-plugin
Description: Create a Qdrant index for the specified text field within a detections label field.

Description: Semantically search for text in your dataset. Only labels matching your query will be shown.
You can specify the number of results to return, and the threshold for the similarity score.