不写一行代码,轻松看懂 Redux 原理。 原文
如果你有任何疑惑,不妨在 Issues 中提出。
Flux 架构已然让人觉得有些迷惑,而比 Flux 更让人摸不着头脑的是 Flux 与 Redux 的区别。Redux 是一个基于 Flux 思想的新架构方式,本文将探讨它们的区别。
如果你还没有看过这篇关于 Flux 的文章(译者注:也可以参考这篇),你应该先阅读一下。
Redux 解决的问题和 Flux 一样,但 Redux 能做的还有更多。
和 Flux 一样,Redux 让应用的状态变化变得更加可预测。如果你想改变应用的状态,就必须 dispatch 一个 action。你没有办法直接改变应用的状态,因为保存这些状态的东西(称为 store)只有 getter 而没有 setter。对于 Flux 和 Redux 来说,这些概念都是相似的。
那么为什么要新设计一种架构呢?Redux 的创造者 Dan Abramov 发现了改进 Flux 架构的可能。他想要一个更好的开发者工具来调试 Flux 应用。他发现如果稍微对 Flux 架构进行一些调整,就可以开发出一款更好用的开发者工具,同时依然能享受 Flux 架构带给你的可预测性。
确切的说,他想要的开发者工具包含了代码热替换(hot reload)和时间旅行(time travel)功能。然而要想在 Flux 架构上实现这些功能,确实有些麻烦。
在 Flux 中,store 包含了两样东西:
- 改变状态的逻辑
- 当前的状态
在一个 store 中同时保存这两样东西将会导致代码热替换功能出现问题。当你热替换掉 store 的代码想要看看新的状态改变逻辑是否生效时,你就丢失了 store 中保存的当前状态。此外,你还把 store 与 Flux 架构中其它组件产生关系的事件系统搞乱了。
解决方案
将这两样东西分开处理。让一个对象来保存状态,这个对象在热替换代码的时候不会受到影响。让另一个对象包含所有改变状态的逻辑,这个对象可以被热替换因为它不用关心任何保存状态相关的事情。
时间旅行调试法的特性是:你能掌握状态对象的每一次变化,这样的话,你就能轻松的跳回到这个对象之前的某个状态(想象一个撤销功能)。
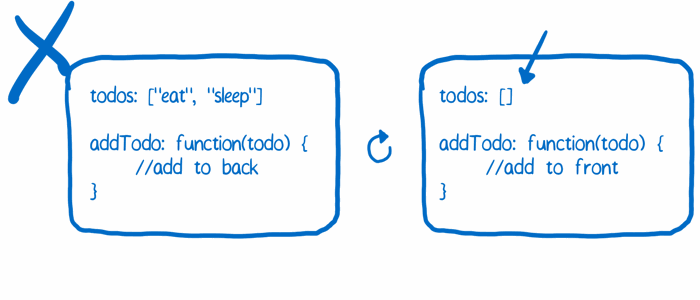
要实现这样的功能,每次状态改变之后,你都需要把旧的状态保存在一个数组中。但是由于 JavaScript 的对象引用特性,简单的把一个对象放进数组中并不能实现我们需要的功能。这样做不能创建一个快照(snapshot),而只是创建了一个新的指针指向同一个对象。
所以要想实现时间旅行特性,每一个状态改变的版本都需要保存在不同的 JavaScript 对象中,这样你才不会不小心改变了某个历史版本的状态。
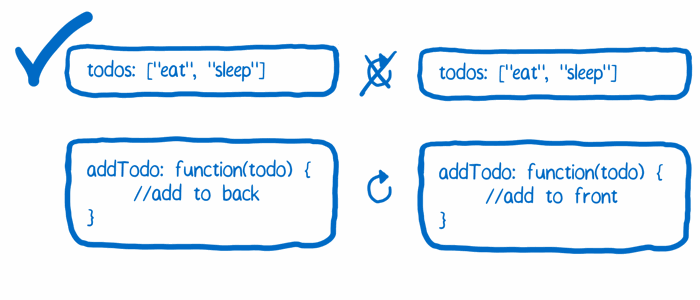
解决方案
当一个 action 需要 store 响应时,不要直接修改 store 中的状态,而是将状态拷贝一份并在这份拷贝的状态上做出修改。
当你在写一些调试性工具时,你希望它们能够更加通用。一个使用该工具的用户应该可以直接引入这个工具而不需要做额外的包装或桥接。
要实现这样的特性,Flux 架构需要一个扩展点。
一个简单的例子就是日志。比如说你希望 console.log() 每一个触发的 action 同时 console.log() 这个 action 被响应完成后的状态。在 Flux 中,你只能订阅(subscribe) dispatcher 的更新和每一个 store 的变动。但是这样就侵入了业务代码,这样的日志功能不是一个第三方插件能够轻易实现的。

解决方案
将这个架构的部分功能包装进其他的对象中将使得我们的需求变得更容易实现。这些「其他对象」在架构原有的功能基础之上添加了自己的功能。你可以把这种扩展点看做是一个增强器(enhancers)或者高阶对象(higher order objects),亦或者中间件(middleware)。
此外,使用一个树形结构来组织所有改变状态的逻辑,这样当状态发生改变的时候 store 只会触发一个事件来通知视图层(view),而这一个事件会被整棵树中的所有逻辑处理(译者注:「处理」不代表一定会改变状态,这些改变状态的逻辑本质上是函数,函数内部会根据 action 的类型等来确定是否对状态进行改变)。
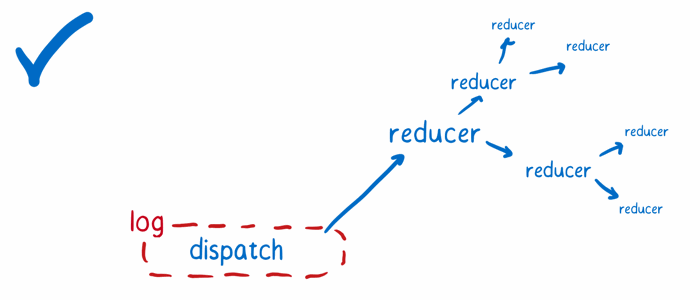
*注意:就上述这些问题和解决方案来说,我主要在关注开发者工具这一使用场景。实际上,对 Flux 做出的这些改变在其他场景中也非常有帮助。在上述三点之外,Flux 和 Redux 还有更多的不同点。比如,相比于 Flux,Redux 精简了整个架构的冗余代码,并且复用 store 的逻辑变得更加简单。这里有一个 Redux 优点的列表可供参考。
那么让我们来看看 Redux 是怎么让这些特性变为现实的。
从 Flux 演进到 Redux,整个架构中的角色发生了些许的变化。
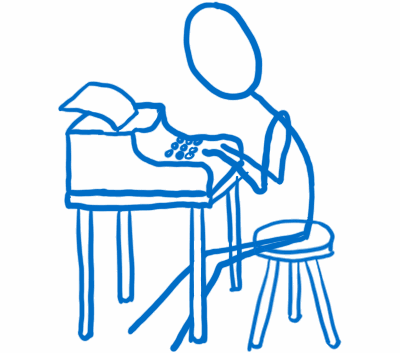
Redux 保留了 Flux 中 action creator 的概念。每当你想要改变应用中的状态时,你就要 dispatch 一个 action,这也是唯一改变状态的方法。
就像我在这篇关于 Flux 的文章中提到的一样,我把 action creator 看做是一个报务员(负责发电报的人,telegraph operator),你找到 action creator 告诉他你大致上想要传达什么信息,action creator 则会把这些信息格式化为一种标准的格式,以便系统中的其他部分能够理解。
与 Flux 不同的是,Redux 中的 action creator 不会直接把 action 发送给 dispatcher,而是返回一个格式化好的 JavaScript 对象。
我把 Flux 中 store 的那一套机制描述为一种控制过度的官僚体系。你不能简单直接的修改状态,而是要求所有的状态改变都必须由 store 亲自产生,还必须要经历 action 分发那种套路。在 Redux 中,store 依然是这么的充满控制欲和官僚主义,但是又有些不一样。

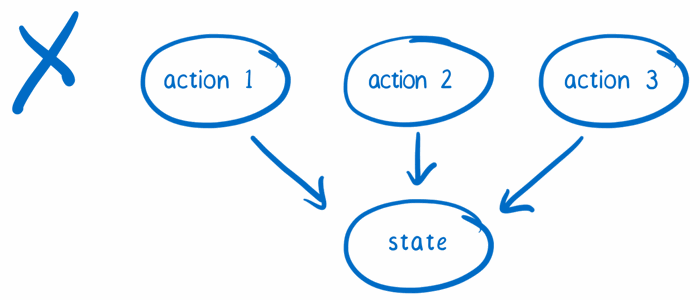
在 Flux 中,你可以拥有多个 store,每一个 store 都有自己的统治权。每个 store 都保存着自己对应的那部分状态,以及所有修改这些状态的逻辑。
而 Redux 中的 store 更喜欢将权力下放,事实上不得不这么做。因为在 Redux 中,你只能有一个 store……所以如果你打算像 Flux 那样让 store 完全独立处理自己的事情,那么在 Redux 中,store 里的工作量将变得非常大。
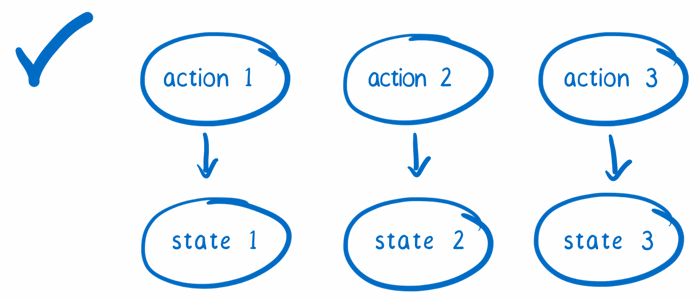
因此,Redux 中的 store 首先会保存整个应用的所有状态,然后将「判断哪一部分状态需要改变」的任务分配下去。而以根 reducer(root reducer)为首的 reducer 们将会承担这个任务。
你可能发现这里好像没有 dispatcher 什么事。是的,虽然看起来有点儿越权,但 Redux 里的 store 已经完全接管了 dispatcher 相关的工作。
当 store 需要知道一个 action 触发后状态需要怎么改变时,他会去询问 reducer。根 reducer 会根据状态对象的键(key)将整个状态树进行拆分,然后将拆分后的每一块子状态传到知道该怎么对这块状态进行响应的子 reducer 那里处理。
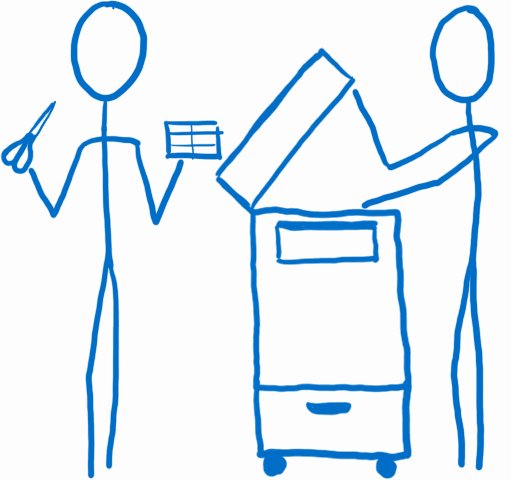
我把 reducers 看做是对复印情有独钟的白领们。他们不希望把任何事搞砸,因此他们不会修改任何传递给他们的文件。取而代之的是,他们会对这些文件进行复印,然后在复印件上进行修改。(译者注:当然,当这些修改后的复印件定稿后,他们也不会再去修改这些复印件。)
这是 Redux 的核心思想之一。不直接修改整个应用的状态树,而是将状态树的每一部分进行拷贝并修改拷贝后的部分,然后将这些部分重新组合成一颗新的状态树。
子 reducers 会把他们创建的副本传回给根 reducer,而根 reducer 会把这些副本组合起来形成一颗新的状态树。最后根 reducer 将新的状态树传回给 store,store 再将新的状态树设为最终的状态。
如果你有一个小型应用,你可能只有一个 reducer 对整个状态树进行拷贝并作出修改。又或者你有一个超大的应用,你可能会有若干个 reducers 对整个状态树进行修改。这也是 Flux 和 Redux 的另一处区别。在 Flux 中,store 并不需要与其他 store 产生关联,而且 store 的结构是扁平的。而在 Redux 中,reducers 是有层级结构的。这种层级结构可以有若干层,就像组件的层级结构那样。
Flux 拥有控制型视图(controller views) 和常规型视图(regular views)。控制型视图就像是一个经理一样,管理着 store 和子视图(child views)之间的通信。

在 Redux 中,也有一个类似的概念:智能组件和木偶组件。(译者注:在最新的 Redux 文档中,它们分别叫做容器型组件 Container component 和展示型组件 Presentational component)智能组件的职责就像经理一样,但是比起 Flux 中的角色,Redux 对经理的职责有了更多的定义:
- 智能组件负责所有的 action 相关的工作。如果智能组件里包含的一个木偶组件需要触发一个 action,智能组件会通过 props 传一个 function 给木偶组件,而木偶组件可以在需要触发 action 时调用这个 function。
- 智能组件不定义 CSS 样式。
- 智能组件几乎不会产生自己的 DOM 节点,他的工作是组织若干的木偶组件,由木偶组件来生成最终的 DOM 节点。
木偶组件不会直接依赖 action(译者注:即不会在木偶组件里 require action 相关的文件),因为所有的 action 都会当做 props 传下来。这意味着木偶组件可以被任何一个逻辑不同的 App 拿去使用。同时木偶组件也需要有一定的样式来让自己变得好看一些(当然你可以让木偶组件接受某些 props 作为设置样式的变量)。

要把 store 绑定到视图上,Redux 还需要一点帮助。如果你在使用 React,那么你需要使用 react-redux。
视图绑定工作有点像为组件树服务的 IT 部门。IT 部门确保所有的组件都正确的绑定到 store 上,并处理各种技术上的细节,以确保余下层级的组件对绑定相关的操作毫无感知。
视图层绑定引入了三个概念:
<Provider>组件: 这个组件需要包裹在整个组件树的最外层。这个组件让根组件的所有子孙组件能够轻松的使用connect()方法绑定 store。connect():这是react-redux提供的一个方法。如果一个组件想要响应状态的变化,就把自己作为参数传给 connect() 的结果(译者注:connect() 返回的依然是一个函数),connect() 方法会处理与 store 绑定的细节,并通过 selector 确定该绑定 store 中哪一部分的数据。selector:这是你自己编写的一个函数。这个函数声明了你的组件需要整个 store 中的哪一部分数据作为自己的 props。

所有的 React 应用都存在一个根组件(root component)。他其实就是整个组件树最外层的那个组件,但是在 Redux 中,根组件还要承担额外的任务。
根组件承担的角色有点像企业中的高管,他将整个团队整合到一起来完成某项任务。他会创建 store,并告诉 store 使用哪些 reducers,并最终完成视图层的绑定。
当完成整个应用的初始化工作后,根组件的就不再插手整个应用的运行过程了。每一次重新渲染(re-render)都没有根组件什么事,这些活儿都由根组件下面的子组件完成,当然也少不了视图层绑定的功劳。
让我们看看上述各个部分是怎样组合成一个可以运行的应用的。
应用中的不同部分需要在配置环节中整合到一起。
(1) **准备好 store。**根组件会创建 store,并通过 createStore(reducer) 方法告诉 store 该使用哪个根 reducer。与此同时,根 reducer 也通过 combineReducers() 方法组建了一只向自己汇报的 reducer 团队。

(2) **设置 store 和组件之间的通信。**根组件将它所有的子组件包裹在 <Provider> 组件中,并建立了 Provider 与 store 之间的联系。
Provider 本质上创建了一个用于更新视图组件的网络。那些智能组件通过 connect() 方法连入这个网络,以此确保他们能够获取到状态的更新。

(3) **准备好 action callback。**为了让木偶组件更好的处理 action,智能组件可以用 bindActionCreators() 方法来创建 action callback。这样做之后,智能组件就能给木偶组件传入一个回调(callback)。对应的 action 会在木偶组件调用这个回调时被自动 dispatch。(译者注:使用 bindActionCreators() 使得木偶组件无需关心 action 的 type 等信息,只用调用 props 中的某个方法传入需要的参数作为 action 的 payload 即可)

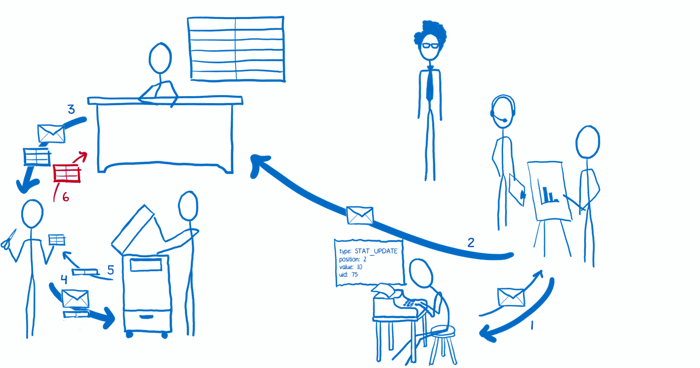
现在我们的应用已经配置完成,用户可以开始操作了。让我们触发一个 action,看看数据是怎样流动的。
(1) 视图发出了一个 action,action creator 将这个 action 格式化并返回。

(2) 这个 action 要么被自动 dispatch(如果我们在配置阶段使用了 bindActionCreators()),要么由视图层手动 dispatch。
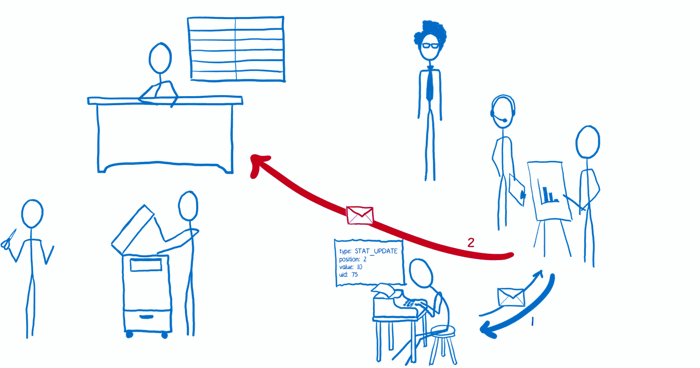
(3) store 接受到这个 action 后,将当前的状态树和这个 action 传给根 reducer。
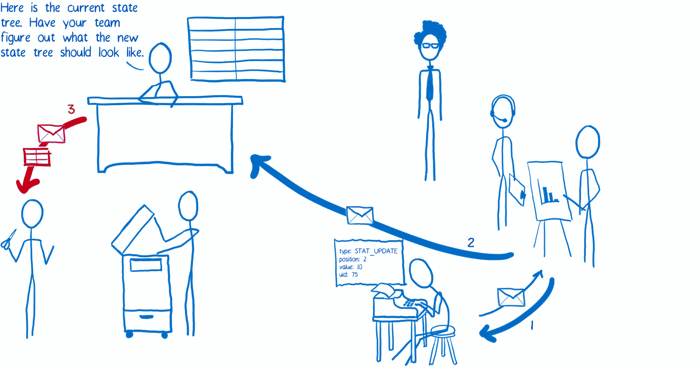
(4) 根 reducer 将整个状态树切分成一个个小块,然后将某一个小块分发给知道怎么处理这部分内容的子 reducer。
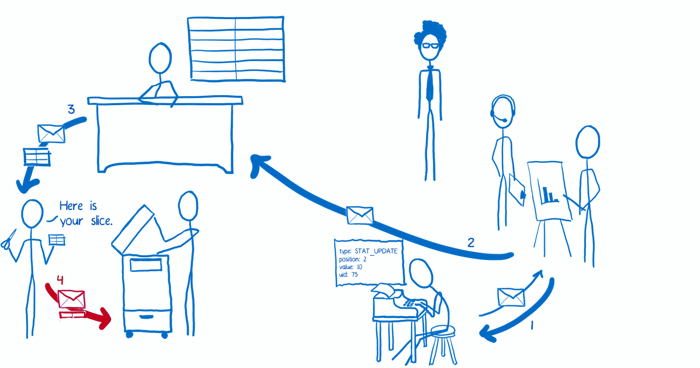
(5) 子 reducer 将传入的一小块状态树进行拷贝,然后在副本上进行修改,并最终将修改后的副本返回根 reducer。
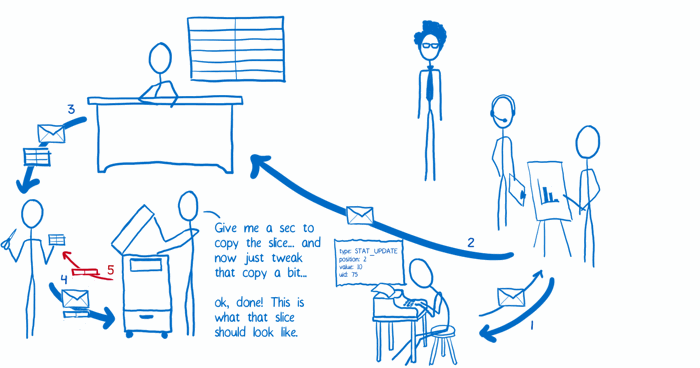
(6) 当所有的子 reducer 返回他们修改的副本之后,根 reducer 将这些部分再次组合起来形成一颗新的状态树。然后根 reducer 将这个新的状态树交还给 store,store 再把自己的状态置为这个最新的状态树。
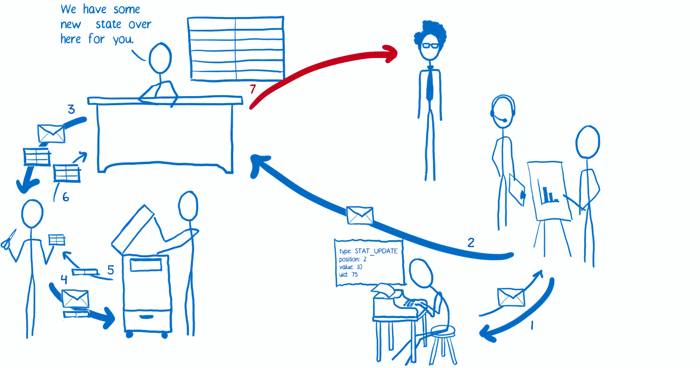
(7) store 告诉视图层绑定:「状态更新啦」
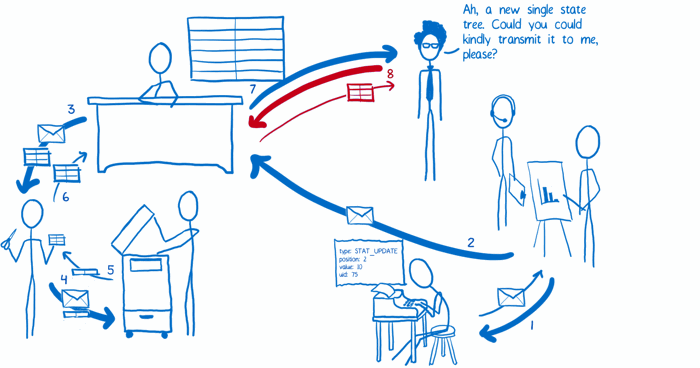
(8) 视图层绑定让 store 把更新的状态传过来
(9) 视图层绑定触发了一个重新渲染的操作(re-render)
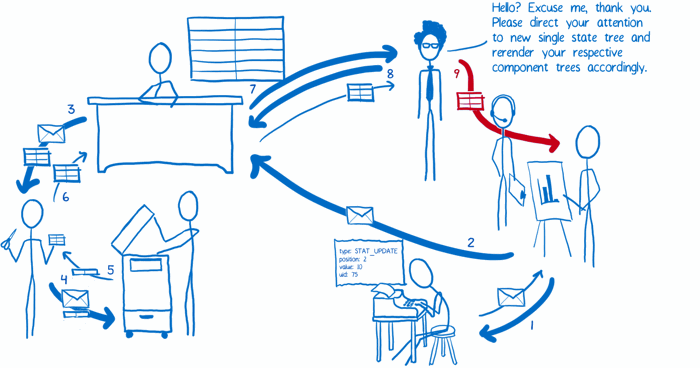
这就是我所理解的 Redux,希望对你有所帮助。