Releases: jhu-lcsr/good_robot
"Good Robot!" paper
minor copyright fix, working version of "Good Robot!" paper, about to update with additional newer work.
2020 "Good Robot!" Paper Release - Stack and Row Models
"Good Robot!" Efficient Reinforcement Learning for Multi-Step Visual Tasks with Sim to Real Transfer
Andrew Hundt, Benjamin Killeen, Nicholas Greene, Hongtao Wu, Heeyeon Kwon, Chris Paxton, and Gregory D. Hager
Click the image to watch the video:

Paper, Abstract, and Citations
Good Robot! Paper on IEEE Xplore,
Good Robot! Paper on ArXiV
@article{hundt2020good,
title="“Good Robot!”: Efficient Reinforcement Learning for Multi-Step Visual Tasks with Sim to Real Transfer",
author="Andrew {Hundt} and Benjamin {Killeen} and Nicholas {Greene} and Hongtao {Wu} and Heeyeon {Kwon} and Chris {Paxton} and Gregory D. {Hager}",
journal="IEEE Robotics and Automation Letters (RA-L)",
volume="5",
number="4",
pages="6724--6731",
year="2020",
url={https://arxiv.org/abs/1909.11730}
}
Abstract— Current Reinforcement Learning (RL) algorithms struggle with long-horizon tasks where time can be wasted exploring dead ends and task progress may be easily reversed. We develop the SPOT framework, which explores within action safety zones, learns about unsafe regions without exploring them, and prioritizes experiences that reverse earlier progress to learn with remarkable efficiency.
The SPOT framework successfully completes simulated trials of a variety of tasks, improving a baseline trial success rate from 13% to 100% when stacking 4 cubes, from 13% to 99% when creating rows of 4 cubes, and from 84% to 95% when clearing toys arranged in adversarial patterns. Efficiency with respect to actions per trial typically improves by 30% or more, while training takes just 1-20k actions, depending on the task.
Furthermore, we demonstrate direct sim to real transfer. We are able to create real stacks in 100% of trials with 61% efficiency and real rows in 100% of trials with 59% efficiency by directly loading the simulation-trained model on the real robot with no additional real-world fine-tuning. To our knowledge, this is the first instance of reinforcement learning with successful sim to real transfer applied to long term multi-step tasks such as block-stacking and row-making with consideration of progress reversal. Code is available at https://github.com/jhu-lcsr/good_robot.
Raw data for key final models
Stacking Run Model with Trial Reward and SPOT-Q

SIM TO REAL TESTING STACK - TEST - SPOT-Q-MASKED - COMMON SENSE - TRIAL REWARD - FULL FEATURED RUN - SORT TRIAL REWARD - REWARD SCHEDULE 0.1, 1, 1 - costar 2020-05-13 - test on costar 2020-06-05
----------------------------------------------------------------------------------------
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --num_obj 8 --push_rewards --experience_replay --explore_rate_decay --trial_reward --common_sense --check_z_height --place --future_reward_discount 0.65 --is_testing --random_seed 1238 --max_test_trials 10 --save_visualizations --random_actions --snapshot_file /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-05-13-12-51-39_Sim-Stack-SPOT-Trial-Reward-Masked-Training/models/snapshot.reinforcement_action_efficiency_best_value.pth
/media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-05-13-12-51-39_Sim-Stack-SPOT-Trial-Reward-Masked-Training/models/snapshot.reinforcement_action_efficiency_best_value.pth
Commit: cb55d6b8a6e8abfb1185dd945c0689ddf40546b0
Creating data logging session: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-05-18-28-46_Real-Stack-SPOT-Trial-Reward-Masked-Testing
Testing Complete! Dir: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-05-18-28-46_Real-Stack-SPOT-Trial-Reward-Masked-Testing
Testing results:
{'trial_success_rate_best_value': 1.0, 'trial_success_rate_best_index': 108, 'grasp_success_rate_best_value': 0.703125, 'grasp_success_rate_best_index': 108, 'place_success_rate_best_value': 0.8888888888888888, 'place_success_rate_best_index': 110, 'action_efficiency_best_value': 0.6111111111111112, 'action_efficiency_best_index': 110}
Row Model with Progress Reward and SPOT-Q
SIM TO REAL ROW - TEST - Task Progress SPOT-Q MASKED - REWARD SCHEDULE 0.1, 1, 1 - workstation named spot 2020-06-03 - test on costar 2020-06-07
----------------------------------------------------------------------------------------
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --check_row --check_z_height --place --future_reward_discount 0.65 --is_testing --random_seed 1238 --max_test_trials 10 --random_actions --save_visualizations --common_sense --snapshot_file "/home/costar/src/real_good_robot/logs/2020-06-03-12-05-28_Sim-Rows-Two-Step-Reward-Masked-Training/models/snapshot.reinforcement_trial_success_rate_best_value.pth"
SIM export CUDA_VISIBLE_DEVICES="1" && python3 main.py --is_sim --obj_mesh_dir objects/blocks --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --check_row --tcp_port 19998 --place --future_reward_discount 0.65 --max_train_actions 20000 --random_actions --common_sense
SIM on spot workstation Creating data logging session: /home/ahundt/src/real_good_robot/logs/2020-06-03-12-05-28_Sim-Rows-Two-Step-Reward-Masked-Training
SIM Commit: 12d9481717486342dbfcaff191ddb1428f102406 release tag:v0.16.1
SIM GPU 1, Tab 1, port 19998, center left v-rep window, v-rep tab 8
SIM Random Testing Complete! Dir: /home/ahundt/src/real_good_robot/logs/2020-06-03-12-05-28_Sim-Rows-Two-Step-Reward-Masked-Training/2020-06-06-21-34-07_Sim-Rows-Two-Step-Reward-Masked-Testing
SIM Random Testing results: {'trial_success_rate_best_value': 1.0, 'trial_success_rate_best_index': 667, 'grasp_success_rate_best_value': 0.850415512465374, 'grasp_success_rate_best_index': 667, 'place_success_rate_best_value': 0.7752442996742671, 'place_success_rate_best_index': 667, 'action_efficiency_best_value': 0.9265367316341829, 'action_efficiency_best_index': 667}
"snapshot_file": "/home/ahundt/src/real_good_robot/logs/2020-06-03-12-05-28_Sim-Rows-Two-Step-Reward-Masked-Training/models/snapshot.reinforcement_trial_success_rate_best_value.pth"
Pre-trained model snapshot loaded from: /home/costar/src/real_good_robot/logs/2020-06-03-12-05-28_Sim-Rows-Two-Step-Reward-Masked-Training/models/snapshot.reinforcement_trial_success_rate_best_value.pth
Creating data logging session: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing
Note on trial 8 or 9 a row was completed correctly, but the sensor didn't pick it up, so I slid the blocks into the middle of the space while maintaining the exact relative position so it would be scored correctly by the row detector (one extra action took place).
> STACK: trial: 11 actions/partial: 3.0714285714285716 actions/full stack: 7.818181818181818 (lower is better) Grasp Count: 52, grasp success rate: 0.6538461538461539 place_on_stack_rate: 0.8235294117647058 place_attempts: 34 partial_stack_successes: 28 stack_successes: 11 trial_success_rate: 1.0 stack goal: None current_height: 0.3236363636363636
> Move to Home Position Complete
> Move to Home Position Complete
> trial_complete_indices: [ 7. 9. 17. 21. 30. 50. 54. 59. 69. 73. 85.]
> Max trial success rate: 1.0, at action iteration: 82. (total of 84 actions, max excludes first 82 actions)
> Max grasp success rate: 0.68, at action iteration: 83. (total of 84 actions, max excludes first 82 actions)
> Max place success rate: 0.8181818181818182, at action iteration: 83. (total of 84 actions, max excludes first 82 actions)
> Max action efficiency: 0.8780487804878049, at action iteration: 84. (total of 85 actions, max excludes first 82 actions)
> saving trial success rate: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/transitions/trial-success-rate.log.csv
> saving grasp success rate: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/transitions/grasp-success-rate.log.csv
> saving place success rate: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/transitions/place-success-rate.log.csv
> saving action efficiency: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/transitions/action-efficiency.log.csv
> saving plot: 2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing-Real-Rows-Two-Step-Reward-Masked-Testing_success_plot.png
> saving best stats to: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/data/best_stats.json
> saving best stats to: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing/best_stats.json
> Testing Complete! Dir: /media/costar/f5f1f858-3666-4832-beea-b743127f1030/real_good_robot/logs/2020-06-07-17-19-34_Real-Rows-Two-Step-Reward-Masked-Testing
> Testing results:
> {'trial_success_rate_best_value': 1.0, 'trial_success_rate_best_index': 82, 'grasp_success_ra...
Test Rows - v0.12.0 - 92% success
Rows test - train with situation removal - test with situation removal disabled 92% success rate.

Testing iteration: 1273
Change detected: True (value: 624)
Primitive confidence scores: 3.098449 (push), 3.570703 (grasp), 6.244108 (place)
Action: place at (12, 181, 42)
Executing: place at (-0.640000, 0.138000, 0.000995)
gripper position: 0.0007762610912322998
gripper position: 0.0007658600807189941
Trainer.get_label_value(): Current reward: 2.343750 Current reward multiplier: 3.000000 Predicted Future reward: 6.230157 Expected reward: 2.343750 + 0.650000 x 6.230157 = 6.393352
Training loss: 0.862810
current_position: [-0.64910257 0.13522317 0.02600006]
current_obj_z_location: 0.05600005827844143
goal_position: 0.06099496489586487 goal_position_margin: 0.16099496489586487
has_moved: True near_goal: True place_success: True
check_row: True | row_size: 4 | blocks: ['blue' 'green' 'yellow' 'red']
check_stack() stack_height: 4 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
TRIAL 101 SUCCESS!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
STACK: trial: 101 actions/partial: 4.378006872852234 actions/full stack: 13.698924731182796 (lower is better) Grasp Count: 707, grasp success rate: 0.6817538896746818 place_on_stack_rate: 0.610062893081761 place_attempts: 477 partial_stack_successes: 291 stack_successes: 93 trial_success_rate: 0.9207920792079208 stack goal: [2 3 1 0] current_height: 4
Time elapsed: 14.448621
Trainer iteration: 1274.000000
Testing iteration: 1274
Change detected: True (value: 3645)
Trainer.get_label_value(): Current reward: 1.031250 Current reward multiplier: 1.000000 Predicted Future reward: 5.253522 Expected reward: 1.031250 + 0.650000 x 5.253522 = 4.446039
Trial logging complete: 100 --------------------------------------------------------------
Training loss: 0.391659
video:

We also did an additional few trials with the visualization reconfigured to a 0-8 range to better show the Q values:
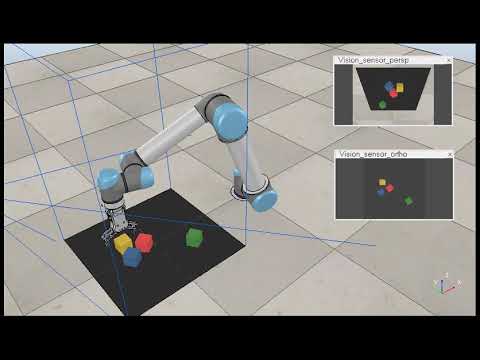
Testing iteration: 176
Change detected: True (value: 1596)
Primitive confidence scores: 3.454333 (push), 4.110956 (grasp), 6.303567 (place)
Strategy: exploit (exploration probability: 0.000000)
Action: grasp at (8, 67, 116)
Executing: grasp at (-0.492000, -0.090000, 0.001000)
Trainer.get_label_value(): Current reward: 2.250000 Current reward multiplier: 3.000000 Predicted Future reward: 6.740332 Expected reward: 2.250000 + 0.650000 x 6.740332 = 6.631216
Training loss: 2.596855
gripper position: 0.05303570628166199
gripper position: 0.03606218099594116
gripper position: 0.0313781201839447
Grasp successful: False
check_row: True | row_size: 3 | blocks: ['blue' 'green' 'red']
check_stack() stack_height: 3 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
STACK: trial: 8 actions/partial: 7.695652173913044 actions/full stack: 25.285714285714285 (lower is better) Grasp Count: 98, grasp success rate: 0.7244897959183674 place_on_stack_rate: 0.323943661971831 place_attempts: 71 partial_stack_successes: 23 stack_successes: 7 trial_success_rate: 0.875 stack goal: [1 0 3 2] current_height: 3
Time elapsed: 8.795416
Trainer iteration: 177.000000
Making block rows experiment - Efficientnet - B0 - NO trial reward - 45k
This is a comparatively long run at 45k iterations with no trial reward.
Status printout:
Training iteration: 45065
Primitive confidence scores: 4.550461 (push), 4.225641 (grasp), 5.490469 (place)
Strategy: exploit (exploration probability: 0.100000)
check_row: True | row_size: 2 | blocks: ['blue' 'green']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
Push motion successful (no crash, need not move blocks): True
STACK: trial: 10575 actions/partial: 3.5070817120622566 actions/full stack: 37.680602006688964 (lower is better) Grasp Count: 8485, grasp success rate: 0.6603417796110784 place_on_stack_rate: 2.32579185520362 place_attempts: 5525 partial_stack_successes: 12850 stack_successes: 1196 trial_success_rate: 0.11309692671394798 stack goal: [3 0 2] current_height: 2
Primitive confidence scores: 4.615572 (push), 3.978644 (grasp), 5.760473 (place)
Strategy: exploit (exploration probability: 0.100000)
check_row: True | row_size: 2 | blocks: ['green' 'red']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
Push motion successful (no crash, need not move blocks): True
STACK: trial: 10575 actions/partial: 3.50715953307393 actions/full stack: 37.6814381270903 (lower is better) Grasp Count: 8485, grasp success rate: 0.6603417796110784 place_on_stack_rate: 2.32579185520362 place_attempts: 5525 partial_stack_successes: 12850 stack_successes: 1196 trial_success_rate: 0.11309692671394798 stack goal: [3 0 2] current_height: 2
check_stack() stack_height: 3 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
Training loss: 0.127804
check_row: True | row_size: 3 | blocks: ['blue' 'green' 'red']
check_stack() stack_height: 3 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
Push motion successful (no crash, need not move blocks): True
STACK: trial: 9048 actions/partial: 3.9553521907931226 actions/full stack: 43.706843718079675 (lower is better) Grasp Count: 5073, grasp success rate: 0.6136408436822393 place_on_stack_rate: 3.5272253015976522 place_attempts: 3067 partial_stack_successes: 10818 stack_successes: 979 trial_success_rate: 0.10820070733863837 stack goal: [2 1 3 0] current_height: 3
Time elapsed: 75.341604
Trainer iteration: 42789.000000
Training iteration: 42789
WARNING variable mismatch num_trials + 1: 5688 nonlocal_variables[stack].trial: 9048
Change detected: True (value: 1341)
Primitive confidence scores: 4.360327 (push), 2.633780 (grasp), 4.680840 (place)
Strategy: exploit (exploration probability: 0.100000)
Trainer.get_label_value(): Current reward: 2.250000 Current reward multiplier: 3.000000 Predicted Future reward: 4.569565 Expected reward: 2.250000 + 0.500000 x 4.569565 = 4.534783
Action: push at (4, 66, 100)
Executing: push at (-0.524000, -0.092000, 0.001000)
Training loss: 0.007398
Experience replay 118955: history timestep index 123, action: place, surprise value: 3.521547
Training loss: 0.000000
check_row: True | row_size: 2 | blocks: ['yellow' 'red']
check_stack() stack_height: 2 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 3 and current workspace stack height: 2, RESETTING the objects, goals, and action success to FALSE...
check_row: True | row_size: 2 | blocks: ['yellow' 'red']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 1 and current workspace stack height: 2, RESETTING the objects, goals, and action success to FALSE...
STACK: trial: 9050 actions/partial: 3.955444629321501 actions/full stack: 43.70786516853933 (lower is better) Grasp Count: 5073, grasp success rate: 0.6136408436822393 place_on_stack_rate: 3.5272253015976522 place_attempts: 3067 partial_stack_successes: 10818 stack_successes: 979 trial_success_rate: 0.1081767955801105 stack goal: [2 1 3 0] current_height: 2
Time elapsed: 97.845186
Trainer iteration: 42790.000000
Command to replicate:
export CUDA_VISIBLE_DEVICES="1" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --place --check_row --tcp_port 19995
Any stack test v0.2.2 situation removal disabled
This is an any stack test which got 85% out of 100 trials successfully, where situation removal was disabled for the testing phase. Note that there was one stack which was completed successfully, but the stack check didn't detect it correctly.
Testing iteration: 1332
WARNING variable mismatch num_trials + 1: 99 nonlocal_variables[stack].trial: 100
Change detected: True (value: 697)
Primitive confidence scores: 2.217880 (push), 2.889425 (grasp), 4.069210 (place)
Action: place at (4, 140, 58)
Executing: place at (-0.608000, 0.056000, 0.154977)
gripper position: 0.0036427080631256104
gripper position: 0.003579080104827881
Trainer.get_label_value(): Current reward: 2.343750 Current reward multiplier: 3.000000 Predicted Future reward: 4.044539 Expected reward: 2.343750 + 0.500000 x 4.044539 = 4.366020
Training loss: 0.267459
current_position: [-0.61089891 0.050615 0.18193844]
current_obj_z_location: 0.21193843960762024
goal_position: 0.21497650269592167 goal_position_margin: 0.3149765026959217
has_moved: True near_goal: True place_success: True
check_stack() current detected stack height: 4
check_stack() stack_height: 4 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
TRIAL 101 SUCCESS!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
STACK: trial: 101 actions/partial: 4.760714285714286 actions/full stack: 15.869047619047619 (lower is better) Grasp Count: 638, grasp success rate: 0.8636363636363636 place_on_stack_rate: 0.5100182149362478 place_attempts: 549 partial_stack_successes: 280 stack_successes: 84 trial_success_rate: 0.8316831683168316 stack goal: [2 1 0 3] current_height: 4
Time elapsed: 12.173556
Trainer iteration: 1333.000000
Testing iteration: 1333
WARNING variable mismatch num_trials + 1: 100 nonlocal_variables[stack].trial: 101
Change detected: True (value: 3468)
Trainer.get_label_value(): Current reward: 1.031250 Current reward multiplier: 1.000000 Predicted Future reward: 2.306686 Expected reward: 1.031250 + 0.500000 x 2.306686 = 2.184593
Trial logging complete: 99 --------------------------------------------------------------
Training loss: 0.591320
Note that we needed to comment the following line in robot.py grasp():
self.move_to(self.sim_home_position, None)
This issue can be avoided by training a new model from scratch with the current settings.
Command to run:
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --place --load_snapshot --snapshot_file '/home/costar/Downloads/snapshot.reinforcement-best-stack-rate.pth' --random_seed 1238 --is_testing --save_visualizations --disable_situation_removal
Cube stacking training - Efficientnet-B0 - trial reward
Note that this is a brief run (6k iterations) compared to most others (20-30k iterations), and we cannot yet know if it will become the best stacking nn model. However, the progress is promising.
Command:
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --trial_reward --place
Output:
Training iteration: 6209
WARNING variable mismatch num_trials + 1: 583 nonlocal_variables[stack].trial: 584
Change detected: True (value: 645)
Primitive confidence scores: 1.990686 (push), 3.271586 (grasp), 3.296898 (place)
Action: place at (0, 116, 75)
Executing: place at (-0.574000, 0.008000, 0.102957)
gripper position: 0.0036782920360565186
gripper position: 0.003635406494140625
Trainer.get_label_value(): Current reward: 1.562500 Current reward multiplier: 2.000000 Predicted Future reward: 3.760068 Expected reward: 1.562500 + 0.500000 x 3.760068 = 3.442534
Training loss: 0.325041
Experience replay 11110: history timestep index 3430, action: place, surprise value: 2.583875
current_position: [-0.48557281 -0.14327906 0.03296793]
current_obj_z_location: 0.0629679325222969
goal_position: 0.16295654107920776 goal_position_margin: 0.26295654107920774
has_moved: True near_goal: False place_success: False
check_stack() False, not enough nearby objects for a successful stack! expected at least 3 nearby objects, but only counted: 1
check_stack() current detected stack height: 1
check_stack() stack_height: 1 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 2 and current workspace stack height: 1, RESETTING the objects, goals, and action success to FALSE...
Training loss: 0.660970
Experience replay 11111: history timestep index 177, action: push, surprise value: 2.441809
Training loss: 0.015068
Experience replay 11112: history timestep index 459, action: place, surprise value: 2.292749
STACK: trial: 585 actions/partial: 7.446043165467626 actions/full stack: 69.7752808988764 (lower is better) Grasp Count: 2360, grasp success rate: 0.6029661016949153 place_on_stack_rate: 0.5919091554293825 place_attempts: 1409 partial_stack_successes: 834 stack_successes: 89 trial_success_rate: 0.15213675213675212 stack goal: [1 2 0] current_height: 1
Training loss: 0.001867
Time elapsed: 12.592669
Trainer iteration: 6210.000000
Row stacking experiment - Efficientnet-B0 - trial reward
Note that this is a brief run (7k iterations) compared to most others (20-30k iterations), and we cannot yet know if it will become the best stacking nn model. However, the progress is promising.
Training iteration: 7019
WARNING variable mismatch num_trials + 1: 1011 nonlocal_variables[stack].trial: 1520
Change detected: True (value: 2302)
Primitive confidence scores: 4.232723 (push), 2.963957 (grasp), 3.558189 (place)
Strategy: exploit (exploration probability: 0.122838)
Action: push at (15, 157, 66)
Executing: push at (-0.592000, 0.090000, 0.000997)
Trainer.get_label_value(): Current reward: 1.500000 Current reward multiplier: 2.000000 Predicted Future reward: 4.407584 Expected reward: 1.500000 + 0.500000 x 4.407584 = 3.703792
Training loss: 0.014585
check_row: True | row_size: 2 | blocks: ['blue' 'red']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
check_row: True | row_size: 2 | blocks: ['blue' 'red']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
Push motion successful (no crash, need not move blocks): True
STACK: trial: 1520 actions/partial: 4.505776636713736 actions/full stack: 74.68085106382979 (lower is better) Grasp Count: 1734, grasp success rate: 0.486159169550173 place_on_stack_rate: 1.9402241594022416 place_attempts: 803 partial_stack_successes: 1558 stack_successes: 94 trial_success_rate: 0.06184210526315789 stack goal: [3 2 0] current_height: 2
Experience replay 13416: history timestep index 114, action: push, surprise value: 6.176722
Training loss: 0.044944
Time elapsed: 6.129107
Trainer iteration: 7020.000000
Ran with the --trial_reward --check_row flags:
export CUDA_VISIBLE_DEVICES="1" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --trial_reward --place --check_row
Test + Training to 16k -- Arrange in Rows -- blocks -- trial_reward -- EfficientNet -- B0 --V0.8.0
This is training progress for arranging in rows, using trial reward, as well as testing. It contains several bugs which have affected logged success rates but not recorded values, improperly delaying trial reset. This requires detecting the first stack (row) height of 4 and removing subsequent 4s until a stack height of 1 is reached, meaning a new trial.
Grasping an offset block when trying to create a row:

Status printout from training:
Training iteration: 16573
WARNING variable mismatch num_trials + 1: 2772 nonlocal_variables[stack].trial: 3141
Change detected: True (value: 609)
Primitive confidence scores: 3.177647 (push), 4.219032 (grasp), 3.461217 (place)
Strategy: exploit (exploration probability: 0.100000)
Action: grasp at (6, 66, 165)
Executing: grasp at (-0.394000, -0.092000, 0.051009)
Trainer.get_label_value(): Current reward: 0.000000 Current reward multiplier: 2.000000 Predicted Future reward: 4.146331 Expected reward: 0.000000 + 0.650000 x 4.146331 = 2.695115
gripper position: 0.030596047639846802
gripper position: 0.025395959615707397
gripper position: 0.004252210259437561
Training loss: 0.590193
Experience replay 31550: history timestep index 12357, action: grasp, surprise value: 0.554012
Training loss: 0.243598
gripper position: 0.0034487545490264893
Grasp successful: True
check_row: True | row_size: 2 | blocks: ['yellow' 'red']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
STACK: trial: 3141 actions/partial: 7.379341050756901 actions/full stack: 78.54976303317535 (lower is better) Grasp Count: 9240, grasp success rate: 0.6172077922077922 place_on_stack_rate: 0.40035650623885916 place_attempts: 5610 partial_stack_successes: 2246 stack_successes: 211 trial_success_rate: 0.06717605858007004 stack goal: [3 0 1] current_height: 2
Experience replay 31551: history timestep index 7990, action: grasp, surprise value: 0.665486
Training loss: 1.295654
Time elapsed: 9.935521
Trainer iteration: 16574.000000
Status printout from testing:
Testing iteration: 1647
Change detected: True (value: 150)
Primitive confidence scores: 3.304538 (push), 3.193036 (grasp), 3.259273 (place)
Strategy: exploit (exploration probability: 0.000000)
Action: push at (4, 149, 181)
Executing: push at (-0.362000, 0.074000, 0.001005)
Trainer.get_label_value(): Current reward: 0.000000 Current reward multiplier: 3.000000 Predicted Future reward: 3.470774 Expected reward: 0.000000 + 0.650000 x 3.470774 = 2.256003
Training loss: 0.307084
gripper position: 0.033294931054115295
gripper position: 0.026271313428878784
gripper position: 0.00115203857421875
gripper position: -0.02354462444782257
gripper position: -0.04312487691640854
check_row: True | row_size: 2 | blocks: ['blue' 'red']
check_stack() stack_height: 2 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 3 and current workspace stack height: 2
check_row: True | row_size: 2 | blocks: ['yellow' 'red']
check_stack() stack_height: 2 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 3 and current workspace stack height: 2
STACK: trial: 100 actions/partial: 6.699186991869919 actions/full stack: 32.96 (lower is better) Grasp Count: 909, grasp success rate: 0.8360836083608361 place_on_stack_rate: 0.34405594405594403 place_attempts: 715 partial_stack_successes: 246 stack_successes: 50 trial_success_rate: 0.5 stack goal: [1 3 0 2] current_height: 2
Time elapsed: 5.650612
Trainer iteration: 1648.000000
Testing iteration: 1648
Change detected: True (value: 2058)
Primitive confidence scores: 2.721774 (push), 3.686786 (grasp), 3.710173 (place)
Strategy: exploit (exploration probability: 0.000000)
Action: grasp at (7, 206, 156)
Executing: grasp at (-0.412000, 0.188000, 0.050982)
Trainer.get_label_value(): Current reward: 1.500000 Current reward multiplier: 2.000000 Predicted Future reward: 3.740939 Expected reward: 1.500000 + 0.650000 x 3.740939 = 3.931610
Training loss: 1.153573
gripper position: 0.029423266649246216
gripper position: 0.024983912706375122
gripper position: 0.0034950077533721924
gripper position: 0.004140764474868774
gripper position: 0.003972411155700684
Grasp successful: True
check_row: True | row_size: 2 | blocks: ['yellow' 'red']
check_stack() stack_height: 2 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: True
main.py check_stack() DETECTED A MISMATCH between the goal height: 3 and current workspace stack height: 2
STACK: trial: 100 actions/partial: 6.703252032520325 actions/full stack: 32.98 (lower is better) Grasp Count: 910, grasp success rate: 0.8362637362637363 place_on_stack_rate: 0.34405594405594403 place_attempts: 715 partial_stack_successes: 246 stack_successes: 50 trial_success_rate: 0.5 stack goal: [1 3 0 2] current_height: 2
Time elapsed: 8.114762
Trainer iteration: 1649.000000
Testing iteration: 1649
There have not been changes to the objects for for a long time [push, grasp]: [0, 0], or there are not enough objects in view (value: 699)! Repositioning objects.
Testing iteration: 1649
Change detected: True (value: 3746)
Trainer.get_label_value(): Current reward: 1.562500 Current reward multiplier: 2.000000 Predicted Future reward: 4.563211 Expected reward: 1.562500 + 0.650000 x 4.563211 = 4.528587
Trial logging complete: 100 --------------------------------------------------------------
Training loss: 0.256596
Command to run training:
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --place --future_reward_discount 0.65 --trial_reward --check_row
Command to run testing:
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/blocks' --num_obj 4 --push_rewards --experience_replay --explore_rate_decay --trial_reward --future_reward_discount 0.65 --place --check_row --is_testing --tcp_port 19996 --load_snapshot --snapshot_file '/home/costar/Downloads/snapshot-backup.reinforcement-best-stack-rate.pth' --random_seed 1238 --disable_situation_removal --save_visualizations
v0.8.-1 Rows SPOT
This is rows training with SPOT. (not SPOTT aka trial spot). This is an old version that gets paired with 0.8.0, but it came before 0.8.0.
Training iteration: 8899
WARNING variable mismatch num_trials + 1: 324 nonlocal_variables[stack].trial: 356
Change detected: True (value: 2515)
Primitive confidence scores: 1.680751 (push), 1.530364 (grasp), 1.380125 (place)
Strategy: exploit (exploration probability: 0.100000)
Action: push at (5, 103, 120)
Executing: push at (-0.484000, -0.018000, 0.001001)
Trainer.get_label_value(): Current reward: 0.000000 Current reward multiplier: 1.000000 Predicted Future reward: 1.449887 Expected reward: 0.000000 + 0.650000 x 1.449887 = 0.942427
Trial logging complete: 323 --------------------------------------------------------------
Training loss: 0.007599
check_row: True | row_size: 2 | blocks: ['blue' 'yellow']
check_stack() stack_height: 2 stack matches current goal: True partial_stack_success: True Does the code think a reset is needed: False
check_row: True | row_size: 2 | blocks: ['blue' 'yellow']
check_stack() stack_height: 2 stack matches current goal: False partial_stack_success: False Does the code think a reset is needed: False
Push motion successful (no crash, need not move blocks): True
STACK: trial: 356 actions/partial: 47.340425531914896 actions/full stack: 4450.0 (lower is better) Grasp Count: 4790, grasp success rate: 0.6632567849686848 place_on_stack_rate: 0.05985354982489653 place_attempts: 3141 partial_stack_successes: 188 stack_successes: 2 trial_success_rate: 0.0056179775280898875 stack goal: [0 2] current_height: 2
Experience replay 18909: history timestep index 4254, action: place, surprise value: 0.319586
Training loss: 0.208083
Time elapsed: 6.687322
Trainer iteration: 8900.000000
note there may be a couple bugs in this, we will want to do a future run in this configuration to verify.
Training + Testing - grasp and push with trial reward - EfficientNet-B0 - v0.7.1
export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/toys' --num_obj 10 --push_rewards --experience_replay --explore_rate_decay --trial_reward --future_reward_discount 0.65 --tcp_port 19996
The trial ended because a failure of the simulator to return the numpy array of data at iteration 16k, but the results are quite good for the low number of iterations.
Training iteration: 16685
Change detected: True (value: 1261)
Primitive confidence scores: 0.967202 (push), 1.646582 (grasp)
Strategy: exploit (exploration probability: 0.100000)
Action: grasp at (7, 83, 107)
Executing: grasp at (-0.510000, -0.058000, 0.051002)
Trainer.get_label_value(): Current reward: 0.500000 Current reward multiplier: 1.000000 Predicted Future reward: 1.596124 Expected reward: 0.500000 + 0.650000 x 1.596124 = 1.537481
Training loss: 0.428985
Experience replay 63188: history timestep index 54, action: push, surprise value: 6.170048
Training loss: 0.071536
gripper position: 0.05317854881286621
gripper position: 0.034931570291519165
gripper position: 0.0285988450050354
Experience replay 63189: history timestep index 565, action: grasp, surprise value: 1.438415
Training loss: 0.018565
Experience replay 63190: history timestep index 12019, action: grasp, surprise value: 0.444365
Training loss: 0.134922
Experience replay 63191: history timestep index 1633, action: grasp, surprise value: 0.568288
Training loss: 0.011571
Experience replay 63192: history timestep index 15569, action: grasp, surprise value: 0.642771
Grasp successful: False
Training loss: 0.465558
Grasp Count: 14151, grasp success rate: 0.8217793795491485
Experience replay 63193: history timestep index 1054, action: push, surprise value: 1.732153
Training loss: 0.016847
Time elapsed: 18.942974
Trainer iteration: 16686.000000
Training iteration: 16686
Change detected: True (value: 134)
Primitive confidence scores: 1.140632 (push), 1.452001 (grasp)
Strategy: exploit (exploration probability: 0.100000)
Action: grasp at (15, 83, 91)
Executing: grasp at (-0.542000, -0.058000, 0.050999)
Trainer.get_label_value(): Current reward: 0.000000 Current reward multiplier: 1.000000 Predicted Future reward: 1.316792 Expected reward: 0.000000 + 0.650000 x 1.316792 = 0.855915
Training loss: 0.009576
Experience replay 63194: history timestep index 5062, action: grasp, surprise value: 0.308253
Training loss: 0.106279
Experience replay 63195: history timestep index 7109, action: grasp, surprise value: 0.205714
Training loss: 0.453820
gripper position: 0.030108928680419922
gripper position: 0.026779592037200928
gripper position: 0.0063852667808532715
Experience replay 63196: history timestep index 1226, action: grasp, surprise value: 1.184422
Training loss: 0.017869
Experience replay 63197: history timestep index 347, action: grasp, surprise value: 0.265588
Training loss: 0.030336
Experience replay 63198: history timestep index 778, action: grasp, surprise value: 1.168766
Training loss: 0.008899
Experience replay 63199: history timestep index 6223, action: push, surprise value: 0.247791
Training loss: 0.817960
gripper position: 0.00013843178749084473
gripper position: 5.0634145736694336e-05
Experience replay 63200: history timestep index 14762, action: grasp, surprise value: 0.546939
Grasp successful: True
Training loss: 0.038645
ERROR: PROBLEM DETECTED IN SCENE, NO CHANGES FOR OVER 20 SECONDS, RESETTING THE OBJECTS TO RECOVER...
Traceback (most recent call last):
File "main.py", line 1078, in <module>
parser.add_argument('--test_preset_cases', dest='test_preset_cases', action='store_true', default=False)
File "main.py", line 831, in main
trainer.model = trainer.model.cuda()
File "main.py", line 892, in get_and_save_images
prev_color_success = nonlocal_variables['grasp_color_success']
File "/home/ahundt/src/costar_visual_stacking/robot.py", line 420, in get_camera_data
color_img.shape = (resolution[1], resolution[0], 3)
IndexError: list index out of range
Note: There were bugs in multi-step tasks code at the time this was started, but we are fairly certain they did not affect this run since it was pushing and grasping only.
test command and log dir:
± export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/toys' --num_obj 10 --push_rewards --experience_replay --explore_rate_decay --trial_reward --future_reward_discount 0.65 --tcp_port 19996 --is_testing --random_seed 1238 --load_snapshot --snapshot_file '/home/ahundt/src/costar_visual_stacking/logs/2019-09-12.18:21:37-push-grasp-16k-trial-reward/models/snapshot.reinforcement.pth'
Connected to simulation.
CUDA detected. Running with GPU acceleration.
Loaded pretrained weights for efficientnet-b0
Loaded pretrained weights for efficientnet-b0
DILATED EfficientNet models created, num_dilation: 1
/home/ahundt/.local/lib/python3.5/site-packages/torch/nn/_reduction.py:46: UserWarning: size_average and reduce args will be deprecated, please use reduction='none' instead.
warnings.warn(warning.format(ret))
Pre-trained model snapshot loaded from: /home/ahundt/src/costar_visual_stacking/logs/2019-09-12.18:21:37-push-grasp-16k-trial-reward/models/snapshot.reinforcement.pth
Adversarial test:
Average % clearance: 92.7
Average % grasp success per clearance: 79.2
Average % action efficiency: 54.6
Average grasp to push ratio: 77.0
ahundt@femur|~/src/costar_visual_stacking on trial_reward!?
± python3 evaluate.py --session_directory /home/ahundt/src/costar_visual_stacking/logs/2019-09-16.02:11:25 --method reinforcement --num_obj_complete 6 --preset
Random test:
Testing iteration: 1160
Change detected: True (value: 679)
Primitive confidence scores: 1.414877 (push), 2.010269 (grasp)
Strategy: exploit (exploration probability: 0.000000)
Action: grasp at (13, 75, 157)
Executing: grasp at (-0.410000, -0.074000, 0.037545)
Trainer.get_label_value(): Current reward: 0.000000 Current reward multiplier: 1.000000 Predicted Future reward: 1.946442 Expected reward: 0.000000 + 0.650000 x 1.946442 = 1.265187
Training loss: 0.018206
gripper position: 0.030663982033729553
gripper position: 0.026504114270210266
gripper position: 0.003155328333377838
gripper position: 0.0009501874446868896
Grasp successful: True
Grasp Count: 1098, grasp success rate: 0.8697632058287796
Time elapsed: 16.090325
Trainer iteration: 1161.000000
Testing iteration: 1161
There have not been changes to the objects for for a long time [push, grasp]: [0, 0], or there are not enough objects in view (value: 0)! Repositioning objects.
Testing iteration: 1161
Change detected: True (value: 6463)
Trainer.get_label_value(): Current reward: 1.000000 Current reward multiplier: 1.000000 Predicted Future reward: 2.221963 Expected reward: 1.000000 + 0.650000 x 2.221963 = 2.444276
Trial logging complete: 100 --------------------------------------------------------------
Training loss: 0.225644
ahundt@femur|~/src/costar_visual_stacking on trial_reward!?
± export CUDA_VISIBLE_DEVICES="0" && python3 main.py --is_sim --obj_mesh_dir 'objects/toys' --num_obj 10 --push_rewards --experience_replay --explore_rate_decay --trial_reward --future_reward_discount 0.65 --tcp_port 19996 --is_testing --random_seed 1238 --load_snapshot --snapshot_file '/home/ahundt/src/costar_visual_stacking/logs/2019-09-12.18:21:37-push-grasp-16k-trial-reward/models/snapshot.reinforcement.pth' --max_test_trials 10 --test_preset_cases