This is an implementation of a clever pooling architecture for prediciting human trajectories. I wanted to see how well neural nets could capture human motion in crowds. Here are some interesting papers on predicting human trajectories:
Human Trajectory Prediction in Crowded Spaces
Social Force Model for Pedestrian Dynamics
Learning Social Etiquette: Human Trajectory Prediction in European Conference on Computer Vision
The first paper is really intresting. It uses deep learning to train models on how humans move relative to one another. It's dataset, UCY and ETH, only consist of pedestrian crowds. The third paper uses non-deep learning, approaches to model human behavior but a far more interesting dataset: The Stanford Drone Dataset taken by a Drone above Stanford University's campus. This dataset contains not only pedestrians, but bikers, golf carts, skaters, etc. The footage of the Circle of Death at Stanford contains highly-packed scene rich with human-human interaction. I wanted to see how well deep learning was able to capture the social rules and conventions humans use to navigate through a sea of pedestrians, bikers, skaters, and carts.
Here is a like to the Stanford Drone Dataset:
Stanford Drone Dataset
Predicting a person's trajectory is treated as a sequence generation problem. We observe a person's trajectory for 18 frames (around 10 seconds of a person's path) and predict the next 18 frames of the path.
*The videos run at around 28 frames/second. Only every 16th frame is read. Of these read frames, I look at the 18th frame.
Each person in the scene is assigned an RNN (according to their class i.e. pedestrian, biker, etc.). Members of the same class share the same RNN weights because pedestrians hava a set of common navigation rules, bikers hava set of common navigation rules, etc. Also, the hidden state of a person corresponds to the trajectory of a person's path thus far.
At each time step, a pooling layer gathers neighboring trajectories. A person's neighborhood is defined as the 160 x 160 pixel area around them. This grid is split into a 20 x 20 grid. Then, I use a 20 x 20 x hidden_state_dim pooling tensor, H, where H(m,n,:) is the hidden state of the the person at grid square (m,n). If there are two or more people in the same grid, then their hidden states are pooled (it indicate couples or micro-crowds of higher density). Then, I embed this into a vector and feed it into the RNN.
Here is a graphic on pooling:
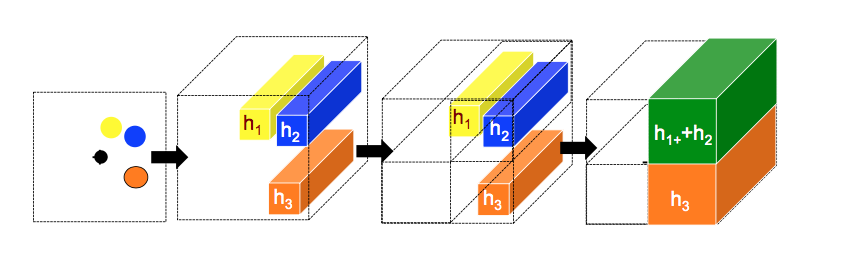
After observing the past 18 frames, the RNN can spit out the expected position at the next frame.
The code uses Theano. I implemented a GRU as opposed to an LSTM (located in pooling_gru.py). Hidden state dimension is 128. In training, I use mean squared error for an objective to evaluate a prediction. Learning rate was initially 0.003 and annealed. I only use 1 GRU layer to save training time. Scripts are in Python2.7
I also added a naive implementation that doesn't look at neighboring trajectories to use as a baseline.
Reading data from annotations:
python read_data.py
Running the training script (for naive and w/ pooling_:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python train.py naive
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python train.py pooling
*the naive script only trains on Bikers (since there is no need to look at different neighbors and theres more biker data)
I found this to be pretty cool. The first image is the trajectory actually taken by the biker. The second is what the GRU predicted.

