Home
A pure-pony Raft implementation
Pony-raft is modular and versatile. The main goal is to implement a hierarchical, persistent, distributed KV store, ala etcd. However, I chose a modular design so that any program that need a consensus can cherry-pick parts of pony-raft and implement their own logic on top. I believe it's a better approach than forcing the user to mess with the provided KV Store.
The main (read mandatory) part is Raft consensus implementation itself. From this point the user can plug the transport layer and the "state machine" (as in Raft terminology). Some more plugable layers may be added in the future, such as the persistence layer or the authentication layers (authentication of the client and of new raft nodes).
Raft is designed to guarantee that any committed state machine command will eventually be applied to every state-machine in the cluster, in the same order. If a number of Raft clients need to share exactly the same data, they must only query the Raft leader. The client protocol (blue lines below) must then implement some kind of redirection to the leader and retry (possibly with round-robin) if no leader can be found at some point.
Sometimes, retrieving slightly outdated data is OK. In that case, a raft server is able to tell how much outdated the data is. A client can then query any server, possibly with round-robin too if the answer is too much outdated. This also distributes the query workload. This strategy is better when the ratio query/update is high.
The core implementation of the Raft algorithm is in raft/core package.
TODO: class model schema
core is designed to abstract out the transport and the state-machine layers.
raft/core/_test.pony implements a full raft cluster into a single program,
each node being an actor. There is no transport layer. At least none that I
implemented myself, because we rely on Pony messages. The state-machine is
minimal, it just implements interface State (pony-raft's state machine
protocol) and does nothing when asked to apply a command (thus, the client
can't really retrieve data).
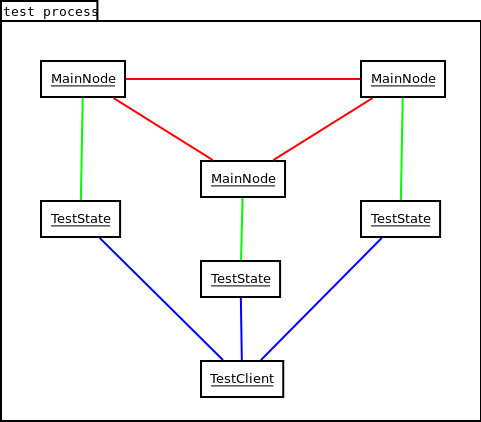
The red lines represent raft consensus protocol, green lines is pony-raft
state-machine protocol. Those two protocols are defined as behaviours on
interface Node and interface State.
The blue lines represent user-defined protocol.
This setup is useless in a practical program, as there is no need to synchronise data access amongst actors in Pony, the compiler takes care of this. However, it challenges pony-raft and eases the test of Node API. I will probably make fuzzing tests using the same kind of setup to validate Raft consensus correctness.
Here's the planned architecture of the key value store. Note that within a
server process, the MainNodes actors communicate with NodeProxies the exact
same way they did with other MainNodes in the testing architecture.
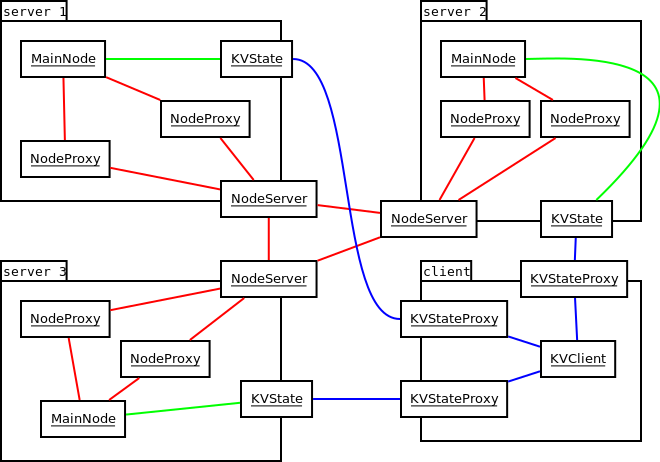
Suppose you're writing a distributed application and need a way to have a reliable consensus. Either you need precise up-to-date data, and you must implement a client that always query the master, as we did in the key-value store, or slightly stale data is OK, and this kind of setup is enough:
