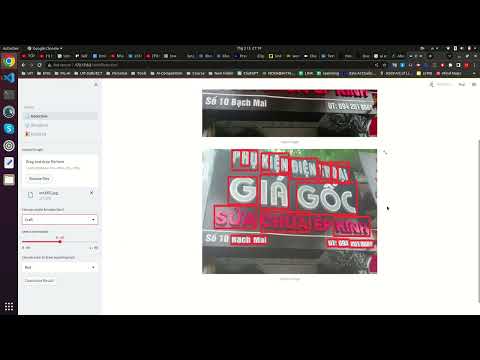
I have developed a small application to address the scene text problem in the Vietnamese language. Scene text is a part of OCR that focuses on processing images containing text appearing on signs, traffic signs, and various other data sources. This is a challenging problem, especially due to environmental noise, diverse font styles, and varied backgrounds.
With my experience participating in several scene text-related competitions and achieving significant rankings in those competitions, I have compiled the source code in this repository to create a small demo application. During the competitions, we usually ran the application on the command line interface (CLI) to generate quick results. However, in this repository, I have created an intuitive user interface to assist in visualizing the data after prediction, in order to identify any weaknesses in the model.
Video Demo:
The problem model

For the Detection model, I use 2 models:
-
YOLOv8: YOLOv8 is an Object Detection model used to detect various objects. Applying YOLOv8 to scene text processing may seem unusual. However, if we consider each word as an object, theory suggests that we can still utilize this model. One of the advantages of YOLOv8 is its fast prediction speed and easy fine-tuning, especially for cases with less noise and simpler testing scenarios, where the model performs fairly well. However, compared to specialized models for text detection, YOLOv8 falls short. One drawback of YOLO is that it predicts rectangular bounding boxes for the text. For italicized or rotated characters at 45 degrees, it may not accurately encompass the text and might include more background. This indirectly affects the results of the text recognition process.
-
CRAFT: CRAFT is a specialized model for text detection. Unlike YOLOv8, CRAFT focuses on generating regions that contain individual characters instead of rectangular bounding boxes. This enables CRAFT to achieve more accurate coverage for inclined and irregular-shaped characters. CRAFT utilizes deep learning architectures like VGG16 or ResNet to extract features from the input image. Subsequently, a two-branch network is applied to predict character regions and determine the boundary points of each character. CRAFT employs fixed-point techniques to generate precise character contours. One of the significant advantages of CRAFT is its ability to accurately detect text while preserving the shape and details of each character. This is particularly useful in the subsequent text recognition process. However, CRAFT may require more computational time and demand more powerful computing resources compared to YOLOv8.
For the Recognition part, I also use 2 models:
- VietOCR: VietOCR is a text recognition model specifically designed for processing Vietnamese text. It utilizes deep learning techniques, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), to extract and recognize text from images. VietOCR is trained on a large dataset of Vietnamese text samples, enabling it to accurately recognize and interpret Vietnamese characters and words. One of the key advantages of VietOCR is its language-specific capabilities. It has been fine-tuned specifically for the nuances and characteristics of the Vietnamese language, making it highly accurate in recognizing and transcribing Vietnamese text. VietOCR also supports various font styles and sizes commonly found in Vietnamese documents, making it versatile and adaptable to different text sources. VietOCR can be
integrated into larger applications or used as a standalone tool.
- Parseq: It is a deep learning model specifically designed for text recognition tasks. It is trained on a large dataset, resulting in impressive performance. It excels at recognizing straight text, italicized text, text rotated more than 90 degrees, and even upside-down text. Due to its excellent training on Latin datasets, when fine-tuned for Vietnamese, it achieves significantly faster and higher-quality results compared to VietOCR.
For 3 out of 4 models: YOLOv8, VietOCR, and Parseq, I have fine-tuned them on Vietnamese data.
Pull docker images:
docker pull lynguyenminh/scenetext-api:v1
Git clone source code:
git clone https://github.com/lynguyenminh/vietnamese-scenetext-detection-recognition-api.git
Run container:
docker run -it --name scenetext-api-v1 -p 5000:5000 -v ./vietnamese-scenetext-detection-recognition-api/:/vietnamese-scenetext-detection-recognition-api lynguyenminh/scenetext-api:v1
Download weights:
cd vietnamese-scenetext-detection-recognition-api
sh download_models.sh
Download source code and install environment:
git clone https://github.com/lynguyenminh/vietnamese-scenetext-detection-recognition-api.git
cd vietnamese-scenetext-detection-recognition-api
sh download_models.sh
pip install -r requirements.txt
cd parseq
pip install -r requirements.txt
pip install -e .
pip install torch==1.10.0 torchtext==0.11.0
streamlit run 01_Home.py --server.port 5000
[1]. https://bamblebam.medium.com/how-to-deploy-your-machine-learning-model-using-streamlit-925368b266ad