- Mark Bauer
- Chidi Ezeolu
- Ho Hsieh
- Nathan Williamson
-
The notebooks can be found in the teabook folder.
-
The website for this repo can be found here: boba-nyc.datalife.nyc

- Introduction
- Prerequisites
- Data
- Analysis
- Open Source Applications Used in Project
- Resources
- Say Hello!
In this workshop, we explore and develop insights about NYC's Bubble Tea Shops using the Yelp Fusion API. Sections include:
- How to use the Yelp Fusion API
- Data Cleaning, Wrangling and Visualizations in Python
- A demo of our web app created in Jupyter Book and Streamlit.
Additionally, questions we’ll explore include bubble tea locations, Yelp ratings, review counts and price.
After an initial introduction of each section, participants will join break-out groups depending on which topic they would like to learn more about. These break-out sessions will be hands-on and interactive. Participants will then reconvene for a Q&A and final thoughts. Attendees will gain a better understanding of the data analysis workflow and will leave with skills and a template to uncover insights with any dataset.
This workshop recommends beginner-level proficiency with Python and is focused on applying Python to data analysis; however, those new to Python are gladly welcome!
- Basics of Python or other programming languages (R, SQL, etc.)
- Basic knowledge of Data Analysis
- Basics of Jupyter Notebooks
This project recommends beginner-level proficiency with Python and is focused on applying Python to data analysis.
-
Install Anaconda
-
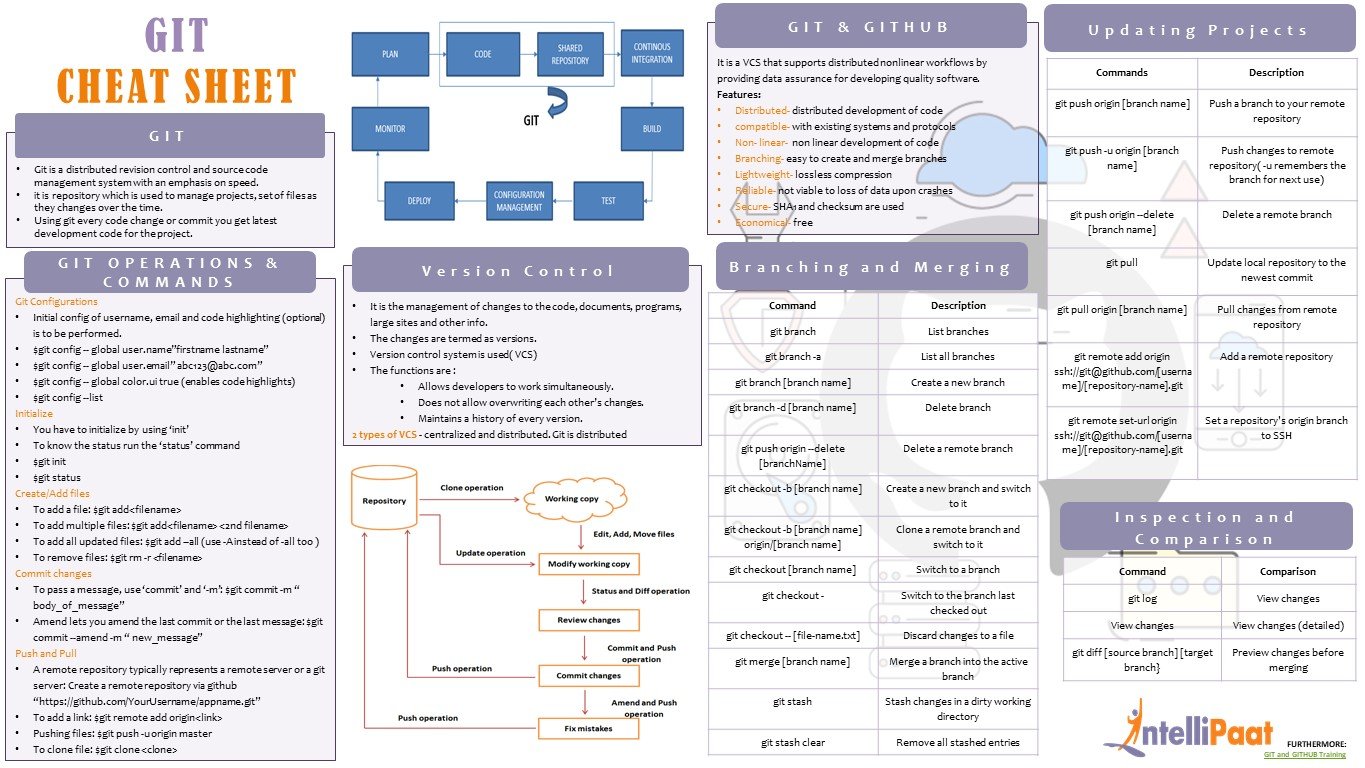
Install Git
-
Clone boba-nyc repo
git clone https://github.com/mebauer/boba-nyc.git
-
Enter directory of local repo
cd boba-nyc -
Install requirements
conda env create -f environment_detail.yml
conda issues # 4339: Exporting clean environment to environment.yml
conda env export --from-history | grep -v "prefix" > environment.ymlgit push originConfiguring a remote for a fork
git remote -v
git remote add upstream https://github.com/mebauer/boba-nyc.git
git remote -vSyncing a fork from the command line
main: name of local default branch
upstream/master: name of remote parent (orginal) repo branch
git fetch upstream
git checkout main
git merge upstream/masterjupyter-book build --all teabook/streamlit run <app.py>Note: the Yelp Fusion API is a free API on Yelp's Developer Site. Details from the Yelp Fusion page:
Create an app on Yelp's Developers site In order to set up your access to Yelp Fusion API, you need to create an app with Yelp. This app represents the application you'll build using our API and includes the credentials you'll need to gain access. Here are the steps for creating an app:
- Go to Create App
- In the create new app form, enter information about your app, then agree to Yelp API Terms of Use and Display Requirements. Then click the Submit button.
- You will now have an API Key.
Please keep the API Key 🔑 to yourself since it is the credential for your call to Yelp's API.
Source: Get started with the Yelp Fusion API
| Dataset | Description |
|---|---|
| Yelp Fusion API - Business Search | This endpoint returns up to 1000 businesses based on the provided search criteria. |
| NYC Borough Boundaries | GIS data of NYC boroughs. |
The output data retrieved from the Yelp Fusion API query is titled boba-nyc.csv and is saved as a CSV file.
You can view these notebooks through your browser by clicking View under the Static Webpage column.
| File Name | Description | Static Webpage |
|---|---|---|
| socrata-api-demo.ipynb | Intro to the Socrata API with the NYC Dog Licensing Dataset & Python | Demo |
| boba-analysis-nyc.ipynb | Analyzing Bubble Tea shops in NYC. | Demo |
| data-wrangling.ipynb | Query and data cleaning workflow from the Yelp Fusion API's Business Search endpoint. | Demo |

- Anaconda: A distribution of the Python and R programming languages for scientific computing (data science, machine learning applications, large-scale data processing, predictive analytics, etc.), that aims to simplify package management and deployment.
- Project Jupyter: Project Jupyter is a non-profit, open-source project, born out of the IPython Project in 2014 as it evolved to support interactive data science and scientific computing across all programming languages.
- Jupyter Notebook: The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text.
- Jupyter Book: Jupyter Book is an open source project for building beautiful, publication-quality books and documents from computational material
- nbviewer: A web application that lets you enter the URL of a Jupyter Notebook file, renders that notebook as a static HTML web page, and gives you a stable link to that page which you can share with others.
- Binder: The Binder Project is an open community that makes it possible to create sharable, interactive, reproducible environments.
- Socrata: The Socrata Open Data API allows you to programmatically access a wealth of open data resources from governments, non-profits, and NGOs around the world.
- Plotly: The front end for ML and data science models.
- Google Cloud Storage: Storage service used to host static website files.
- About Open Data Week: Open Data Week is organized and produced by the NYC Open Data Program and BetaNYC. This annual festival takes place during the first week of March to celebrate New York City’s Open Data Law, which was signed into law on March 7, 2012, and International Open Data Day which is typically the first Saturday in March.
- NYC Open Data: Open Data is free public data published by New York City agencies and other partners.
- File:Matcha green tea.jpg by BubbleManiaCZ is under the Creative Commons Attribution-Share Alike 3.0 Unported license.
{kind=link}
Bubble Tea Logo: Photo at ViVi Bubble Tea - 49 Bayard St, New York, NY 10013
{kind=link}
We can be reached at:
| Presenter | GitHub | ||
|---|---|---|---|
| Mark Bauer |  |
 |
|
| Chidi Ezeolu |  |
||
| Ho Hsieh |  |
||
| Nathan Williamson |  |