Tutorial ~ Motivation
In the Introduction section, we've seen how ildl can transform pairs of integers to long integers, saving as much as 56 bytes for each pair. In this context, a natural question to ask is:
####Why is there so much wasted memory?
In Scala, tuples are generic classes:
case class Tuple2[@specialized(...) +T1, @specialized(...) +T2](_1: T1, _2: T2)Now, disregarding specialization, the heap footprint for object (1,2) is 64 bytes:
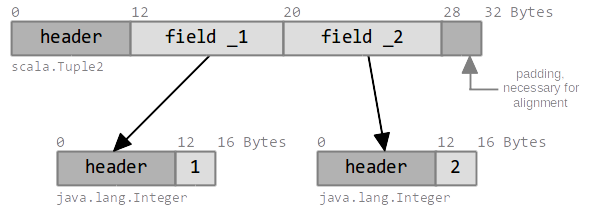
Surprisingly, even if with specialization or miniboxing the memory footprint doesn't get much closer to the 8 bytes of useful information the tuple is carrying: 36 (rounded to 64) bytes for the specialized case and 30 (rounded to 32) bytes for miniboxing. This means that, even in the best case, with miniboxing, we're wasting three quarters of the memory. Furthermore, there are currently no plans to support multi-parameter value classes in Scala.
The underlying problem is that Scala tuples come with the full power of:
- genericity, abstracting over the type of data they store
- variance, which requires special treatment from specialization and miniboxing (limiting their benefits)
- case class support, such as automatic structural equality, easy construction and pattern matching and so on...
Unfortunately, we're paying a lot for this flexibility. And this is typical of many abstractions we use: collections, frameworks, domain-specific libraries -- they all come with every possible feature users may need, covering even the most remote use cases. Yet, each piece of extra functionality comes at the price of adding overhead and increasing the memory footprint.
Still, this wouldn't be a problem if we could optimize all of the extra features away when they're not needed... Yet, even the most advanced backends, optimizers and just-in-time compilers can't fully recover the performance loss compared to hand-optimized code, since analyses are difficult, especially when we expect to mix and match different libraries as we please, without recompiling everything (like in C++).
So we end up paying for all the features, even if we only use a subset. This begs the question:
####What can be done to fix this?
This is where the ildl transformation can help: if you, as a programmer, know a better representation, you can let the compiler improve the code by using it.
Let us go back to the original example, where we give the full IntPairAsLong transformation description object:
/**
* Encodes pairs of integers as long integers, saving
* as much as 64 - 8 = 56 bytes for each pair on the
* standard Oracle Java Virtual Machine version 7.
*/
object IntPairAsLong extends TransformationDescription {
// coercions:
def toRepr(pair: (Int, Int)): Long @high = ...
def toHigh(long: Long @high): (Int, Int) = ...
// tuple constructor:
def ctor_Tuple2(_1: Int, _2: Int) = ...
// extension methods:
def extension__1(recv: Long @high): Int = ...
def extension__2(recv: Long @high): Int = ...
}We will later follow the transformation in detail, but for now, let us look at a simple example:
adrt(IntPairAsLong) {
def add(t1: (Int, Int), t2: (Int, Int)): (Int, Int) =
(t1._1 + t2._1, t1._2 + t2._2)
}The add method will be transformed to:
def add(t1: Long, t2: Long): Long =
ctor_Tuple2(
extension__1(t1) + extension__1(t2),
extension__2(t1) + extension__2(t2)
) In the actual translation, the object IntPairAsLong appears as the receiver of all method calls, but in our translations we omit this for brevity.
Looking closely at the transformed add method, we notice it completely avoids the allocation of (Int, Int) objects. Instead, both the method arguments and its return value are encoded into long integers. This means, following our transformation and our decision to apply it to method add, ildl plugin transformed all values to long integers. Furthermore, all calls the values previously received (such as t1._1) and all new operators have been redirected to the improved representation.
Now, assuming outside code wants to call this method, either from the current file or from a different one (or maybe even from a later compilation run):
val x1 = (1,2)
val x2 = (2,3)
println(add(x1, x2).toString)The snippet will be automatically transformed to:
val x1 = (1,2)
val x2 = (2,3)
println(toHigh(add(toRepr(x1), toRepr(x2))).toString)The ildl transformation keeps track of the transformation applied to the add method and adapts the arguments and return type, maintaining program consistency even across separate files and compilations. It also keeps track of object inheritance, multiple nested transformation scopes and generics, all with their own complex interactions with the transformation.
You may be wondering what would happen if the snippet of code was also transformed:
adrt(IntPairAsLong) {
val x1 = (1,2)
val x2 = (2,3)
println(add(x1, x2).toString)
}Interestingly, the resulting code would still create an (Int, Int) object. Can you guess why?
This compiler warning may explain that:
example.scala:32: warning: The method toString can be
optimized if you define a public, non-overloaded and
matching extension method for it in object IntPairAsLong,
with the name extension_toString:
println(add(x1, x2).toString)
^
In our transformation, we did not intercept the toString method, so the ildl plugin needs to decode the long integer into an actual tuple object:
adrt(IntPairAsLong) {
val x1: Long = ctor_Tuple2(1,2)
val x2: Long = ctor_Tuple2(2,3)
println(toHigh(add(x1, x2)).toString)
}This is the "pay as you go" part of the ildl plugin: if the transformation description does not explain how to transform a method, it will need to use the more expensive representation (the high-level type, thus the name toHigh for the coercion) instead of the encoded representation (the representation type, thus the name toRepr for the coercion).
We glossed over many aspects in the presentation, but we will develop them as we go. There is one specific point in the Transformation Description section which we should state up-front: targeting objects for which identity matters (for example, for synchronization) or which contain mutable state is more difficult and limits what the ildl transformations can do. However, targeting immutable objects with value semantics, which means pretty much any functional collection, can be done at will, following the example we've already seen.

The rest of this page is under construction.
The "pay as you go" can extend both ways: in one direction, if you did not cover some use-cases, it will
####What if I know something more about my library?
You can embed that knowledge into the transformation. The main problem with libraries and frameworks is that by the time they are compiled, many optimization opportunities are already gone. Let us look at a different problem now:
val v1 = Vector(1,2,3)
val v2 = v1.map(_ + 1)
val v3 = v2.map(_ + 1)By the time a
####This could be done by hand...
Yes, it could.
####This could be done with macros...
Yes, it could.
In general, the problem is programmers want all the bells and whistles, such as the nice toString output, the Product abstraction and the easy construction and deconstruction of value classes. Even more, programmers want collections that can append, prepent and index in linear time
...
In the [[next section|Tutorial-~-Getting-Started]] we will look at a concrete example: the Gaussian Integer encoding.
- if you want to see an example and learn more about the motivation behind
ildl, see the >> Motivation section of the tutorial - if you want to see the transformation in action, see the >> Transformation section of the tutorial
- or get back to the [[>> home page|Home]].
**Return to the main page** or **return to the OOPSLA Step by Step Guide**