Perkembangan pasar saham dan investasi semakin menarik minat banyak orang. Salah satu tantangan yang dihadapi oleh para investor adalah memprediksi pergerakan harga saham di masa depan untuk mengambil keputusan investasi yang lebih baik. Dalam proyek ini, dilakukan prediksi harga saham perusahaan Unilever Indonesia menggunakan metode LSTM (Long Short-Term Memory) berdasarkan data historis yang diperoleh dari Yahoo Finance open dataset. Tujuan utama proyek ini adalah membantu investor dalam mengoptimalkan keputusan investasi mereka dengan memberikan prediksi harga saham yang lebih akurat.
LSTM digunakan dalam proyek ini karena dapat mengatasi data time series yang kompleks, seperti harga saham, dan mampu menangkap pola dan tren jangka panjang dalam data historis. Penelitian dalam beberapa tahun terakhir juga telah menunjukkan bahwa model jaringan LSTM sangat efektif dalam prediksi harga saham. LSTM mampu menangkap pola yang kompleks dalam data time series, termasuk pergerakan harga saham yang cenderung berubah-ubah dan dipengaruhi oleh banyak faktor.
Beberapa penelitian dalam beberapa tahun terakhir telah menunjukkan efektivitas model jaringan LSTM dalam prediksi harga saham. Sebagai contoh, penelitian [1] menggunakan LSTM untuk prediksi saham dan mencapai nilai RMSE sebesar 0.00918 pada parameter Open/Close dengan epoch 500. Penelitian [2] juga menggunakan LSTM untuk prediksi saham dan memperoleh nilai MSE sebesar 0.0015. Selain itu, penelitian [3] membandingkan model LSTM, ARIMA, dan ANN untuk prediksi saham dengan hasil yang menunjukkan bahwa LSTM memberikan performa yang lebih baik.
Dengan memanfaatkan metode LSTM, proyek ini bertujuan untuk memberikan prediksi harga saham Unilever Indonesia yang lebih akurat, terutama dalam jangka waktu yang lebih panjang. Hal ini akan membantu para investor dalam membuat keputusan investasi yang lebih baik dan mengoptimalkan hasil investasi mereka.
Proyek ini bertujuan untuk mengembangkan model prediksi harga saham perusahaan Unilever Indonesia menggunakan metode LSTM. Model ini akan dilatih menggunakan data historis harga saham Unilever Indonesia dari IHGS untuk memprediksi pergerakan harga saham di masa depan pada data uji.
Dengan menggunakan model prediksi yang akurat, investor dapat memperoleh wawasan mendalam tentang pergerakan harga saham Unilever Indonesia. Informasi ini membantu investor dalam pengambilan keputusan investasi yang lebih cerdas, menghindari keputusan impulsif, serta mengendalikan risiko secara efektif. Selain itu, dengan prediksi yang akurat, investor dapat mengoptimalkan hasil investasi mereka.
Secara keseluruhan, penggunaan model prediksi harga saham yang akurat memiliki dampak positif yang signifikan. Investor dapat membuat keputusan investasi yang lebih cerdas, mengendalikan risiko dengan lebih baik, dan meningkatkan potensi keuntungan dalam pasar saham. Selain itu, hal ini juga meningkatkan kepercayaan investor terhadap keputusan investasi mereka, membantu mereka mencapai tujuan investasi, dan meningkatkan hasil investasi secara keseluruhan.
- Bagaimana cara mengembangkan model prediksi harga saham yang akurat menggunakan metode LSTM agar dapat membantu investor dalam mengambil keputusan investasi yang lebih baik berdasarkan prediksi harga saham yang akurat?
- Bagaimana cara membantu investor memprediksi harga saham Unilever Indonesia di masa depan dengan lebih baik?
- Mengembangkan model prediksi harga saham yang akurat menggunakan metode LSTM.
- Membantu investor dalam membuat keputusan investasi yang lebih baik berdasarkan prediksi harga saham yang akurat.
- Melakukan tuning parameter pada model LSTM, seperti ukuran lapisan LSTM, dropout rate, dan jumlah neuron pada hidden layer.
- Mengimplementasikan model LSTM yang lebih kompleks, dengan menambahkan lapisan LSTM tambahan, peningkatan jumlah neuron pada hidden layer.
- Melakukan preprocessing data dengan menggunakan MinMaxScaler untuk melakukan Feature Scaling pada data harga saham. Dengan menggunakan MinMaxScaler, skala data harga saham dapat disesuaikan sehingga nilainya berada dalam rentang 0 hingga 1. Hal ini membantu menghindari perbedaan skala yang signifikan antara fitur-fitur dan memastikan pengaruh yang seimbang terhadap model LSTM.
Dataset yang digunakan berasal dari Yahoo Finance Dataset. Dataset ini berisi data historis harian saham Unilever Indonesia dari 3 Januari 2005 hingga 9 Juni 2023. Dataset terdiri dari 4563 baris data dan 7 kolom, yaitu:
- Date = Tanggal dan waktu transaksi saham
- Open = Harga pembukaan
- Low = Harga terendah dalam rentang waktu
- High = Harga tertinggi dalam rentang waktu
- Close = Harga penutupan
- Adj Close = Harga penutupan setelah penyesuaian untuk semua pemisahan dan pembagian dividen yang berlaku
- Volume = Total volume yang diperdagangkan dalam rentang waktu tersebu
Pada proyek ini, fokus prediksi akan difokuskan pada harga Close saham. Model LSTM akan dilatih menggunakan data historis ini untuk memprediksi harga Close saham di masa depan pada data uji. Grafik dari harga Close saham dapat dilihat pada Gambar 1. untuk melihat pergerakan harga seiring waktu dan membantu dalam melihat tren dan pola pergerakan harga saham perusahaan.
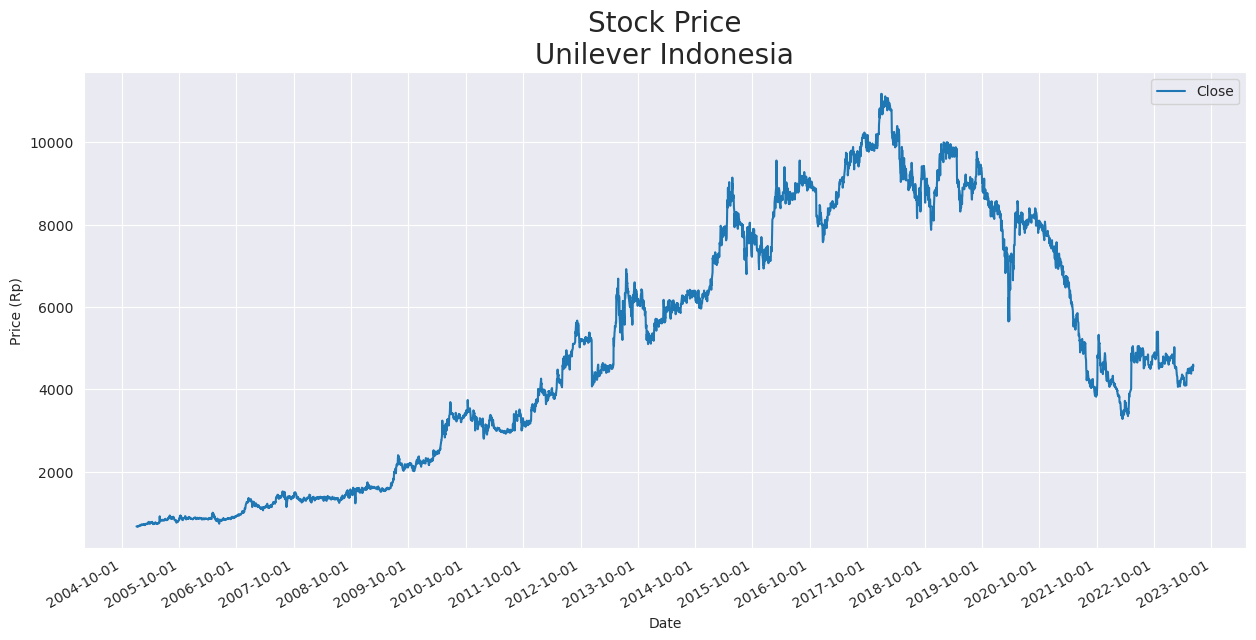 Gambar 1. Grafik pergerakan harga close saham Unilever Indonesia dari Januari 2005 hingga Juni 2023
Gambar 1. Grafik pergerakan harga close saham Unilever Indonesia dari Januari 2005 hingga Juni 2023
Data historis harga saham Unilever Indonesia dari IHGS diimpor menggunakan library Pandas dan disajikan dalam bentuk DataFrame. Grafik harga saham Unilever Indonesia dari waktu ke waktu ditampilkan untuk memahami pergerakan harga seperti pada Gambar 1.
Selanjutnya, dilakukan Feature Scaling menggunakan MinMaxScaler untuk menormalkan data harga saham sebelum dimasukkan ke dalam model LSTM. Hal ini membantu menghindari perbedaan skala yang signifikan antara fitur-fitur dan memastikan pengaruh yang seimbang terhadap model LSTM.
Data kemudian dibagi menjadi data latih (train) dan data uji (test) dengan perbandingan 80:20 menggunakan fungsi split_data. Dengan menggunakan 80% data sebagai data latih, model dapat belajar dari sebagian besar pola dan tren dalam data yang tersedia. Hal ini membantu dalam membangun model yang lebih mampu melakukan generalisasi pada data baru. Dan dengan menyisihkan 20% data sebagai data uji, kita memiliki set data yang independen untuk menguji kinerja model yang telah dilatih. Data uji yang tidak digunakan dalam proses pelatihan memberikan ukuran yang lebih objektif tentang seberapa baik model dapat menggeneralisasi pada data yang belum pernah dilihat sebelumnya dan dapat mengidentifikasi apakah model memiliki masalah overfitting atau tidak.
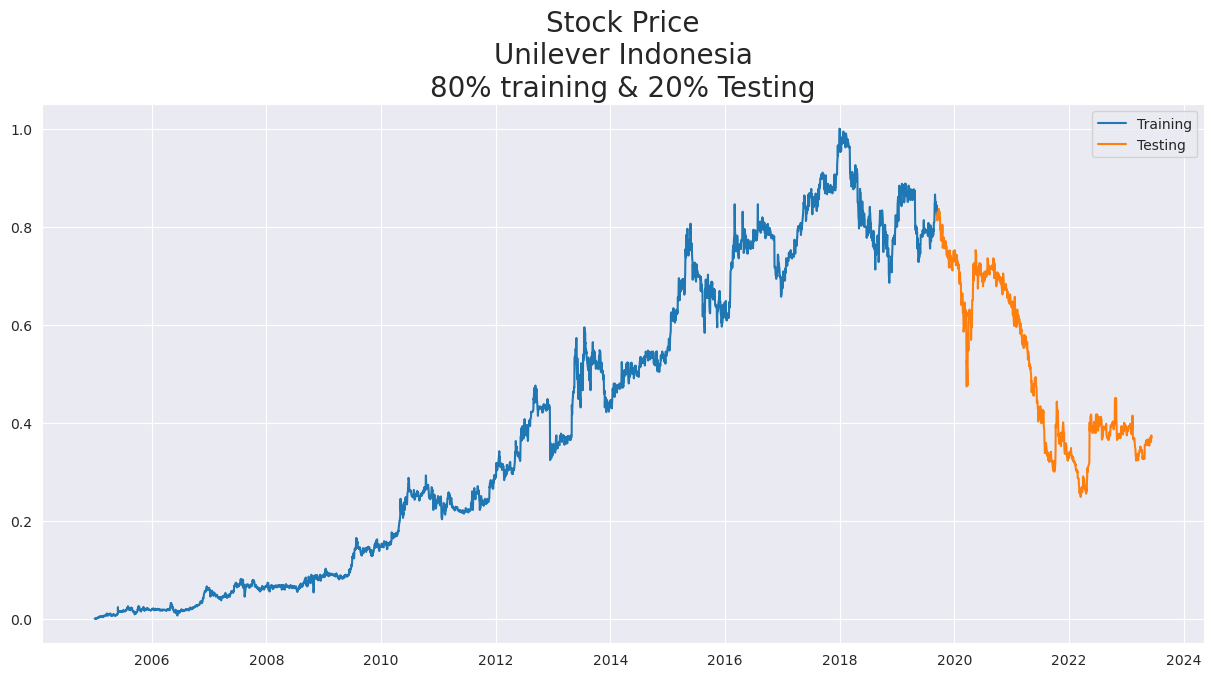 Gambar 2. Grafik pembagian data pelatihan (80%0 dan data uji (20%)
Gambar 2. Grafik pembagian data pelatihan (80%0 dan data uji (20%)
Proyek ini menggunakan model LSTM (Long Short-Term Memory) untuk memprediksi harga saham Unilever Indonesia. Model ini dikembangkan menggunakan TensorFlow dengan Sequential API. LSTM adalah jenis arsitektur jaringan saraf rekurensi (RNN) yang secara khusus dirancang untuk memproses data berurutan, seperti data harga saham. Keunggulan LSTM terletak pada kemampuannya dalam menangani masalah memori jangka panjang, di mana ia dapat mengingat dan menggunakan informasi masa lalu untuk memprediksi masa depan. Dalam LSTM, terdapat sel memori yang menggantikan neuron tradisional di lapisan tersembunyi jaringan. Dengan adanya sel memori ini, jaringan mampu menghubungkan informasi jarak jauh dalam urutan waktu, memungkinkan pemahaman yang dinamis terhadap struktur data dari waktu ke waktu, serta memberikan kemampuan prediksi yang lebih akurat.
Dalam model LSTM yang dikembangkan, terdapat tiga jenis layer yang digunakan, yaitu lapisan LSTM, Dropout, dan Dense. Lapisan LSTM adalah komponen inti dari model LSTM, yang bertanggung jawab untuk memproses dan memahami data berurutan dengan memanfaatkan informasi memori jangka panjang. Lapisan Dropout digunakan untuk mengurangi overfitting dengan secara acak mengabaikan sebagian output dari lapisan sebelumnya selama proses pelatihan. Lapisan Dense, sebagai lapisan terakhir, bertanggung jawab untuk mengubah output dari lapisan sebelumnya menjadi bentuk yang sesuai dengan jumlah neuron output yang diinginkan.
Konfigurasi model mencakup tuning parameter seperti ukuran lapisan LSTM, dropout rate, dan jumlah neuron pada hidden layer. Proses tuning ini bertujuan untuk mencari kombinasi yang optimal untuk meningkatkan performa prediksi harga saham. Ukuran lapisan LSTM perlu dipertimbangkan dengan memperhatikan kompleksitas data dan kebutuhan pemrosesan informasi jangka panjang. Dropout rate yang tepat dapat membantu menghindari overfitting dan meningkatkan generalisasi pada data uji. Jumlah neuron pada hidden layer juga dapat mempengaruhi kemampuan model dalam mempelajari pola dan membuat prediksi yang akurat. Konfigurasi ini digunakan setelah melakukan beberapa pengujian.
Proses pelatihan model melibatkan kompilasi model menggunakan optimizer Adam dengan learning rate 0.001 dan loss function Huber. Optimizer Adam digunakan untuk mengoptimalkan proses pelatihan dengan mengatur laju pembelajaran adaptif. Loss function Huber digunakan sebagai metrik evaluasi untuk mengukur kesalahan prediksi model. Callback EarlyStopping digunakan untuk menghentikan pelatihan jika mean absolute error (mae) pada data validasi sudah mencapai tingkat yang cukup kecil, sehingga mencegah model dari overfitting.
Dengan menggunakan konfigurasi model yang optimal dan proses pelatihan yang tepat, diharapkan model LSTM dapat memberikan prediksi harga saham Unilever Indonesia yang akurat dan dapat digunakan untuk pengambilan keputusan investasi yang lebih baik.
Pelatihan menggunakan batch size sebesar 32 dan berlangsung selama 11 epoch. Model menggunakan EarlyStopping callback dengan kondisi berhenti jika MAE (Mean Absolute Error) mencapai nilai < 0.0001. Grafik loss dan MAE yang diperoleh saat pelatihan dapat dilihat pada Gambar 3. Grafik loss dan MAE saat pelatihan model digunakan untuk memantau kinerja pelatihan. Pada awal pelatihan, loss cenderung tinggi karena model masih belum memiliki pemahaman yang baik tentang data. Namun, seiring berjalannya epoch, loss cenderung menurun karena model mulai mempelajari pola dalam data. Grafik MAE juga menunjukkan perubahan nilai MAE yang menurun seiring dengan berjalannya epoch. MAE mengukur selisih absolut rata-rata antara nilai yang diprediksi oleh model dan nilai yang diamati.
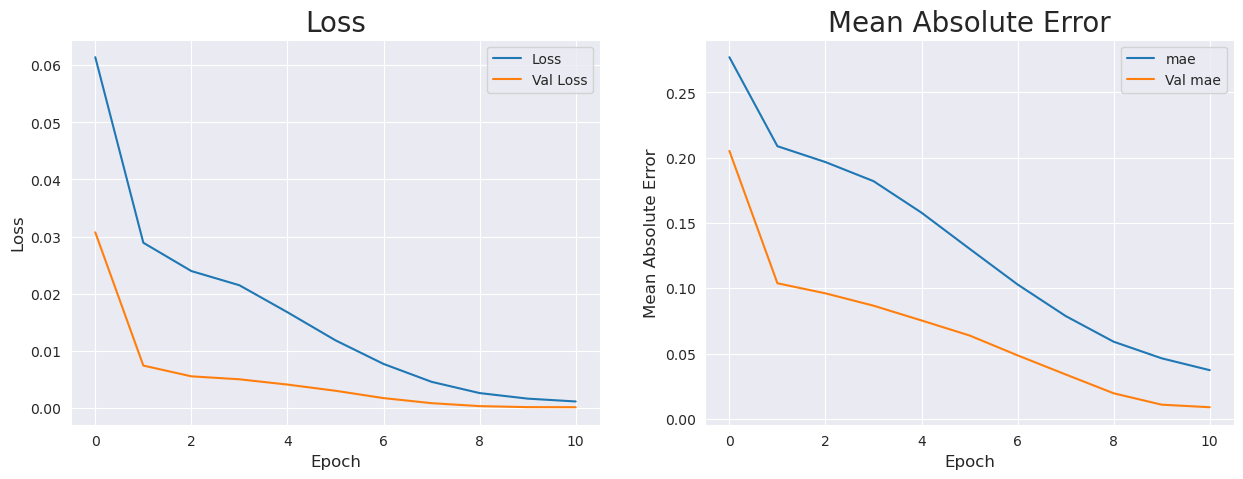 Gambar 3. Loss dan MAE saat pelatihan
Gambar 3. Loss dan MAE saat pelatihan
Evaluasi model dilakukan menggunakan data uji. Prediksi harga saham dilakukan pada data uji dan hasilnya dibandingkan dengan harga saham aktual, serta dilakukan plotting grafik harga saham aktual dan harga saham yang diprediksi.
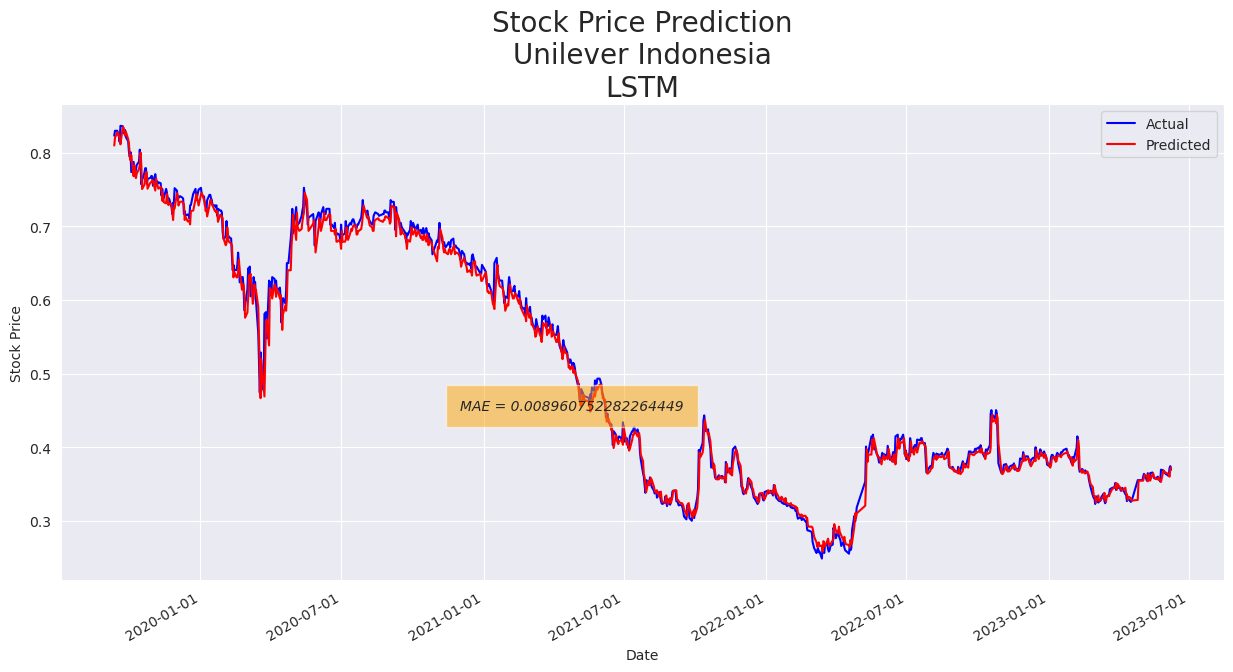 Gambar 4. Hasil prediksi pada data uji
Gambar 4. Hasil prediksi pada data uji
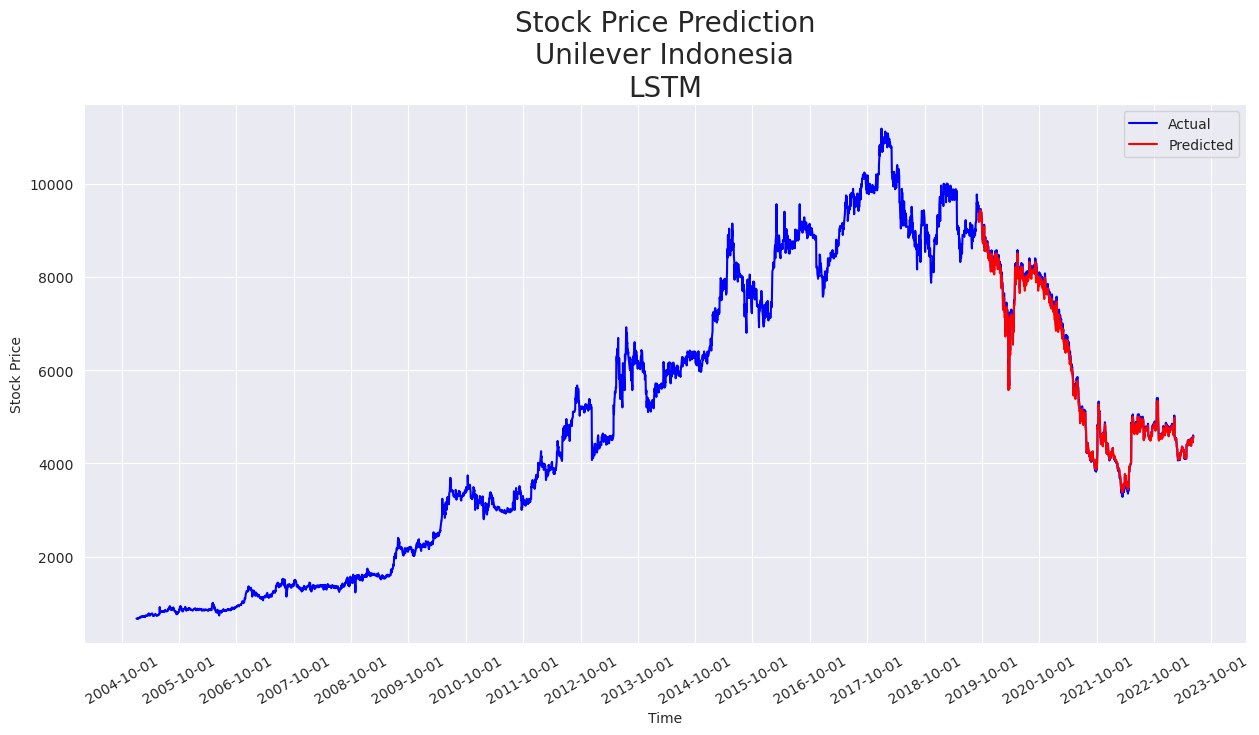 Gambar 5. Hasil prediksi pada data uji menggunakan seluruh data dengan nilai harga sebenarnya
Gambar 5. Hasil prediksi pada data uji menggunakan seluruh data dengan nilai harga sebenarnya
Beberapa metrik evaluasi digunakan untuk mengukur performa model prediksi harga saham seperti Mean Absolute Error (MAE), Root Mean Square Error (RMSE), dan Mean Absolute Percentage Error (MAPE).
- Mean Absolute Error (MAE): selisih absolut rata-rata antara nilai yang diprediksi oleh model (prediksi dalam sampel satu langkah ke depan) dan data historis yang diamati.
- Root Mean Square Error (RMSE): Akar kuadrat dari MSE. MSE adalah jumlah selisih kuadrat antara nilai yang diprediksi oleh model dan nilai yang diamati, yang kemudian dibagi dengan jumlah titik data historis dikurangi jumlah parameter dalam model.
- MAPE (Mean Absolute Percentage Error): Selisih persentase absolut rata-rata antara nilai yang diprediksi oleh model dan nilai data yang diamati.
Metrik evaluasi ini memberikan gambaran sejauh mana model dapat memprediksi harga saham Unilever Indonesia dengan akurat. Semakin rendah nilai MAE, RMSE, dan MAPE semakin baik performa model dalam melakukan prediksi yang akurat.
Hasil evaluasi yang diperoleh adalah sebagai berikut:
Tabel 1. Hasil evaluasi model pada data uji
| Metrics | Value |
|---|---|
| MAE (Mean Avsolute Error) | 0.008960752282264449 |
| RSME (Root Mean Squared Error) | 0.012929452282302365 |
| MAPE (Mean Absolute Percent Error) | 0.01839643243171354 |
Berdasarkan hasil evaluasi yang diperoleh, model prediksi harga saham Unilever Indonesia telah menghasilkan performa yang baik. MAE, RMSE, dan MAPE yang rendah menunjukkan bahwa model memiliki tingkat kesalahan yang rendah dan mampu mendekati nilai sebenarnya dengan akurasi yang baik. Hal ini mengindikasikan bahwa model berhasil memprediksi harga saham dengan tingkat kesalahan yang rendah dan mendekati nilai sebenarnya, sesuai dengan harapan yang telah ditetapkan.
Hasil evaluasi menunjukkan bahwa model yang telah dibangun memiliki performa yang baik dalam memprediksi harga saham. Metrik evaluasi yang digunakan, seperti MAE, RMSE, dan MAPE, menunjukkan tingkat kesalahan yang rendah dan kemampuan model dalam mendekati nilai sebenarnya.
Sehingga dapat disimpulkan bahwa model prediksi harga saham Unilever Indonesia telah mencapai tujuan yang diharapkan. Model tersebut dapat digunakan untuk memprediksi harga saham dengan akurasi yang baik, sehingga dapat memberikan informasi berharga dalam pengambilan keputusan investasi.
[1] M. Roondiwala, H. Patel, and S. Varma, “Predicting Stock Prices Using LSTM,” International Journal of Science and Research (IJSR) ISSN, vol. 6, no. 4, pp. 2319–7064, 2017, Available: https://www.ijsr.net/archive/v6i4/ART20172755.pdf
[2] A. Arfan and D. Lussiana, “Prediksi Harga Saham Di Indonesia Menggunakan Algoritma Long Short-Term Memory,” Universitas Gunadarma Jl. Margonda Raya No, vol. 3, no. 1, pp. 2581–2327, 2019, Accessed: Jun. 16, 2023. [Online]. Available: https://core.ac.uk/download/pdf/270292706.pdf
[3] Q. Ma, “Comparison of ARIMA, ANN and LSTM for Stock Price Prediction,” E3S Web of Conferences, vol. 218, p. 01026, 2020, doi: https://doi.org/10.1051/e3sconf/202021801026.
[4] G. Van Houdt, C. Mosquera, and G. Nápoles, “A review on the long short-term memory model,” Artificial Intelligence Review, May 2020, doi: https://doi.org/10.1007/s10462-020-09838-1.
[5] Y. Gal and Z. Ghahramani, “A Theoretically Grounded Application of Dropout in Recurrent Neural Networks,” 2016. Accessed: Jun. 16, 2023. [Online]. Available: https://arxiv.org/pdf/1512.05287.pdf