{kind=link}
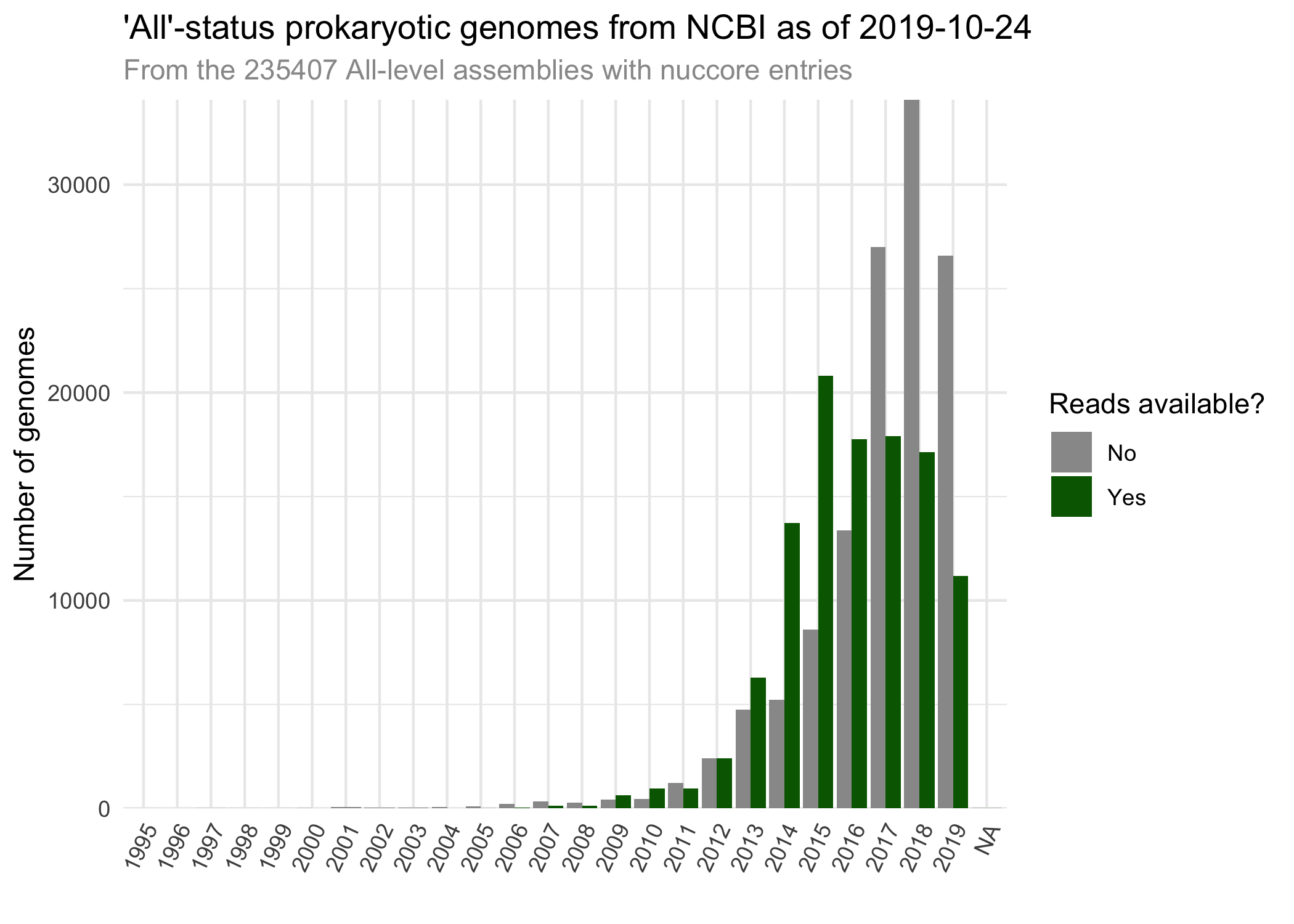
sraFind is a tool create a much-needed database: one that relates NCBI's prokaryotic genome records in the nucleotide, SRA, assembly, and biosample. This database is stored as sraFind.tab.
In short it uses a list of biosample accessions from NCBI's prokaryotes.txt file that it periodically updates to run a whole bunch of entrez edirect searches, downloading the XML for hits where a link is found between the biosample and the SRA database.
We chose to include the results in the repo to allow for quicker rerunning. No empty files are commited -- this is to avoid false negatives where a link may exist but was not downloaded due to network connectivity, etc.
Note those looking for results/version0.0.1_results.txt or results/sraFind-CompleteGenome-biosample-with-SRA-hits.txt should now use sraFind.tab.
- GNU parallel
- NCBI's entrez direct
- R
- get an NCBI API key
Using a conda env might make things easier, just be aware that the cmds called my parallel will not use that env without some adjusting.
conda create -n sraFind r-base parallel r-r.utils perl-io-socket-ssl perl-net-ssleay perl-lwp-protocol-https entrez-direct
The script for fetching data is ./scripts/get_accs.R, which:
- orchestrates the downloading of a
prokaryotes.txtfile, if one is not found in the current working directory - writing out a file of all the commands to run
# USAGE: Rscript get_accs.R /output/dir/
Rscript scripts/get_accs.R ./output/
This will write out a file called sraFind-fetch-cmds.txt, containing the entrez calls. make sure you have NCBI_API_KEY set, and then parallel as follows:
parallel -j <ncores> --progress :::: sraFind-fetch-cmds.txt
(use j < 10, as API limits requests to 10/s with a key)
If you are trying to get the full dataset of all prokaryotic genomes, you should consider using a computing cluster or being patient. We include a scripts/sge_run.sh as a template script for how to execute on a cluster with SGE.
In short:
Rscript get_accs.R ./output/
# make sure you have an api key set:
parallel -j <ncores> --progress :::: output/sraFind-fetch-cmds.txt
Rscript scripts/parse_results.R ./output/ncbi_dump_clean/
./scripts/commit.sh
When updating the database, ensure to pull the latest version of this repo from git, which includes the current database as a tar'ed ./output/ncbi_dump. Uncompress this, then run Rscript get_accs.R ./output/. This will look through prokaryotes.txt and try to get the XML links for any biosample not in the database. Keep in mind that this will not get updates to Biosamples for which a link has already been saved. Also keep in mind NCBI's API limit: no more than 3 per second, or 10 per second with an API key. So this can take a long time.
Then, the parse_results.R script extracts the relavent data from the XML into a pretty tabular format.
Once this has been completed, use the scripts/commit.sh to remove empty files, commit the resulting compressed database, and clean up.
The scripts/parse_results.R script takes care of the following:
- selecting the subset of the results you are interested in based on genome assembly completeness
- calling the extrez commands to parse the hits
- merging together SRA runs with multiple datasets
- saving the output
Sometimes there are parsing errors if a field is missing from the XML files. We try to correct some, but those that we cant, we remove from the final hits file and save as parser_errors.txt.
But who are we kidding, you're probably not going to use /my/ plotting scripts are you? parse_results.R saved a nice csv that you can use with your plotting library of choice.
Don't put too much faith in the nuccore first chromosome columns. This is created with a bunch of regexes of the "replicon" column, which is filled with bad metadata. This also ignores the genomes in the list where the chromosome is categorized as a plasmid; there are about 100 of these that list no chromosome, but a megabase-scale plasmid. If someone couldn't get that bit of metadata sorted out, I am hesitant to trust their sequence...
We cheat. Because Entrez will retry links that fail (and most assemblies dont have SRAs, so most links fail), we use the following two sed one-liners to modify the edirect.pl script to (a) change from 3 retries to 2, and (b) remove the 3 second sleep cmds from those retries.
eutilsbin=$(dirname `which efetch`)
cp $eutilsbin/edirect.pl $eutilsbin/old_edirect.pl
sed s/"tries < 3"/"tries < 2"/g $eutilsbin/old_edirect.pl | sed s/"sleep 3"/"sleep 0"/g > $eutilsbin/edirect.pl