Information extraction from English Wikipedia. The approach used is the one presented in Integrating Syntactic and Semantic Analysis into the Open Information Extraction Paradigm. Moro, Navigli (2013) with some variations due to the different goal.
Third homework of the Natural Language Processing course, prof. Roberto Navigli.
University project • 2017 - Natural Language Processing - MSc in Computer Science, I year
The statement of the problem is in Homework3.pdf. The source code is is accompanied by a report (report.pdf), I strongly suggest you read it to understand the solution code. The Moro & Navigli article can be found here.
We want to extract couples of concepts that are linked by a specific type of relation (Material, Generalization, Specialization, Part, Time). The corpus is a semi-structured version of the English Wikipedia, each page corresponds to a xml file organized in a part containing the raw text already split in sentences (one line per sentence) and a second part with annotations of words corresponding to concepts in the text, included the hyperlinks.
The extracted triples are then used to generate question-answer pairs.
For the extraction of those triples (p1, relation, p2) we follow the approach of Moro and Navigli [2013] with some variations since we need to label the relations to assign them to one of the five possible classes. In particular the task is accomplished in two steps, the relation extraction and the filtering of the extracted relations to the types of relation chosen. The strengths of this approach are the integration of the syntax in the IE workflow, we are going to use it in both steps, and the similarity measure that combines syntax and distributional semantics, we are going to use it in the second step.
The presented adaptation of the algorithm described in Moro and Navigli [2013] has been proved powerful. The results are satisfactory, we have extracted all the requested triples from the five chosen classes with an high precision in most of the cases. We have generated a large number of question-answer pairs.
See the report for a detailed discussion of the results.
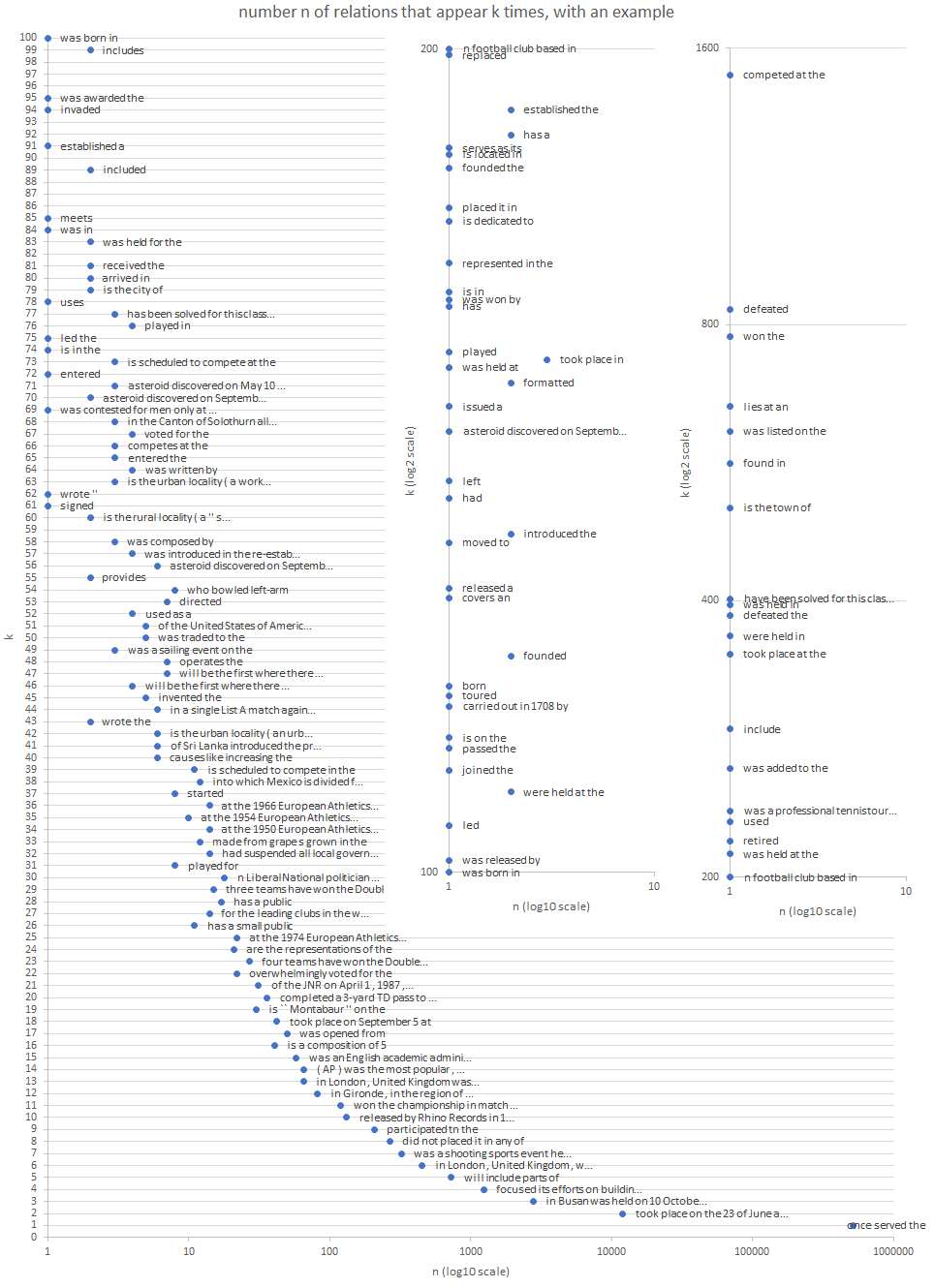
Length of pi in words. (pi = words expressing the relation. e.g. Concert took place at the auditorium )

Number n of relations that appear k times, with an example.