Implementation of the NELI leader election protocol for Go and Kafka. goNELI encapsulates the 'fast' variation of the protocol, running in exclusive mode over a group of contending processes.
Leader election is a straightforward concept, long-standing in the academic papers on distributed computing. For a set of competing processes, select one process that is a notional leader, ensuring that at-most one process may bear the leader status at any point in time, and that this status is unanimously agreed upon among the remaining processes. Conceptually, leader election is depicted below.
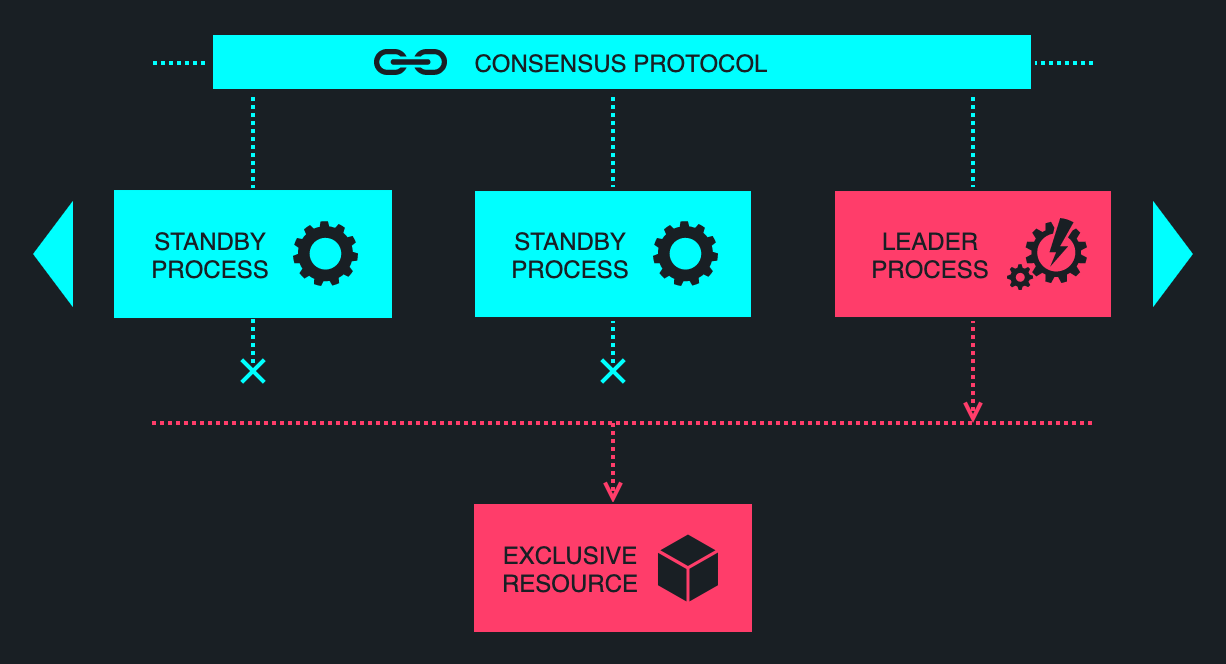
As straightforward as the concept might appear, the implementation is considerably more nuanced, owing to the myriad of edge cases that must be accounted for — such as spurious process failures and network partitions. Leader election also requires additional infrastructure to provide for centralised coordination, increasing the complexity of the overall architecture.
Meanwhile, many event-driven microservices have come to rely upon Apache Kafka for their messaging needs, and Kafka has an internal leader election mechanism for assigning the cluster controller as well as the group and transaction coordinators. Wouldn't it be nice if we could somehow 'borrow' this coveted feature for our own leader election needs?
This is where NELI comes in. Rather than dragging in additional infrastructure components and dependencies, NELI makes do with what's already there.
go get -u github.com/obsidiandynamics/goneliimport "github.com/obsidiandynamics/goneli"This is the easiest way of getting started with leader election. A task will be continuously invoked in the background while the Neli instance is the leader of its group.
// Create a new Neli curator.
neli, err := New(Config{
KafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
LeaderGroupID: "my-app-name.group",
LeaderTopic: "my-app-name.topic",
})
if err != nil {
panic(err)
}
// Starts a pulser Goroutine in the background, which will automatically terminate when Neli is closed.
p, _ := neli.Background(func() {
// An activity performed by the client application if it is the elected leader. This task should
// perform a small amount of work that is exclusively attributable to a leader, and return immediately.
// For as long as the associated Neli instance is the leader, this task will be invoked repeatedly;
// therefore, it should break down any long-running work into bite-sized chunks that can be safely
// performed without causing excessive blocking.
log.Printf("Do important leader stuff")
time.Sleep(100 * time.Millisecond)
})
// Blocks until Neli is closed or an unrecoverable error occurs.
panic(p.Await())Sometimes more control is needed. For example —
- Configuring a custom logger, based on your application's needs.
- Setting up a barrier to synchronize leadership transition, so that the new leader does not step in until the outgoing leader has completed all of its backlogged work.
- Pulsing of the
Neliinstance from your own Goroutine.
// Additional imports for the logger and Scribe bindings.
import (
scribelogrus "github.com/obsidiandynamics/libstdgo/scribe/logrus"
logrus "github.com/sirupsen/logrus"
)// Bootstrap a custom logger.
log := logrus.StandardLogger()
log.SetLevel(logrus.TraceLevel)
// Configure Neli.
config := Config{
KafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
Scribe: scribe.New(scribelogrus.Bind()),
LeaderGroupID: "my-app-name.group",
LeaderTopic: "my-app-name.topic",
}
// Handler of leader status updates. Used to initialise state upon leader acquisition, and to
// wrap up in-flight work upon loss of leader status.
barrier := func(e Event) {
switch e.(type) {
case LeaderAcquired:
// The application may initialise any state necessary to perform work as a leader.
log.Infof("Received event: leader elected")
case LeaderRevoked:
// The application may block the Barrier callback until it wraps up any in-flight
// activity. Only upon returning from the callback, will a new leader be elected.
log.Infof("Received event: leader revoked")
case LeaderFenced:
// The application must immediately terminate any ongoing activity, on the assumption
// that another leader may be imminently elected. Unlike the handling of LeaderRevoked,
// blocking in the Barrier callback will not prevent a new leader from being elected.
log.Infof("Received event: leader fenced")
}
}
// Create a new Neli curator, supplying the barrier as an optional argument.
neli, err := New(config, barrier)
if err != nil {
panic(err)
}
// Pulsing is done in a separate Goroutine. (We don't have to, but it's often practical to do so.)
go func() {
defer neli.Close()
for {
// Pulse our presence, allowing for some time to acquire leader status.
// Will return instantly if already leader.
isLeader, err := neli.Pulse(10 * time.Millisecond)
if err != nil {
// Only fatal errors are returned from Pulse().
panic(err)
}
if isLeader {
// We hold leader status... can safely do some work.
// Avoid blocking for too long, otherwise we may miss a poll and lose leader status.
log.Infof("Do important leader stuff")
time.Sleep(100 * time.Millisecond)
}
}
}()
// Blocks until Neli is closed.
neli.Await()There are handful of parameters that control goNELI's behaviour, assigned via the Config struct:
| Parameter | Default value | Description |
|---|---|---|
KafkaConfig |
Map containing bootstrap.servers=localhost:9092. |
Configuration shared by the underlying Kafka producer and consumer clients. |
LeaderGroupID |
Assumes the filename of the application binary. | A unique identifier shared by all instances in a group of competing processes. The LeaderGroupID is used as Kafka group.id property under the hood, when subscribing to the leader election topic. |
LeaderTopic |
Assumes the value of LeaderGroupID, suffixed with the string .neli. |
The name of the Kafka topic used for orchestrating leader election. Competing processes subscribe to the same topic under an identical consumer group ID, using Kafka's exclusive partition assignment as a mechanism for arbitrating leader status. |
Scribe |
Scribe configured with bindings for log.Printf(); effectively the result of running scribe.New(scribe.StandardBinding()). |
The logging façade used by the library, preconfigured with your logger of choice. See Scribe GoDocs. |
Name |
A string in the form {hostname}_{pid}_{time}, where {hostname} is the result of invoking os.Hostname(), {pid} is the process ID, and {time} is the UNIX epoch time, in seconds. |
The symbolic name of this instance. This field is informational only, accompanying all log messages. |
MinPollInterval |
100 ms | The lower bound on the poll interval, preventing the over-polling of Kafka on successive Pulse() invocations. Assuming Pulse() is called repeatedly by the application, NELI may poll Kafka at a longer interval than MinPollInterval. (Regular polling is necessary to prove client's liveness and maintain internal partition assignment, but polling excessively is counterproductive.) |
HeartbeatTimeout |
5 s | The period that a leader will maintain its status, not having received a heartbeat message on the leader topic. After the timeout elapses, the leader will assume a network partition and will voluntarily yield its status, signalling a LeaderFenced event to the application. |
Traditionally, leader election is performed using an Atomic Broadcast protocol, which provides a consistent view across a set of processes. Given that implementing consensus protocols is not trivial (even with the aid of libraries), most applications will defer to an external Group Management Service (GMS) or a Distributed Lock Manager (DLM) for arbitrating leadership among contending processes.
A DLM/GMS, such as Consul, Etcd, Chubby or ZooKeeper, is an appropriate choice in many cases. A crucial point raised by the NELI paper (and the main reason for its existence) is that infrastructure may not be readily available to provide this capability. Further to that point, someone needs to configure and maintain this infrastructure, and ensure its continuous availability — otherwise it becomes a point of failure in itself. This problem is exacerbated in a µ-services architecture, where it is common-practice for services to own their dependencies. Should DLMs be classified as service-specific dependencies, or should they be shared? Either approach has its downsides.
Rather than embedding a separate consensus protocol such as PAXOS or Raft, or using an external service, NELI piggy-backs on Kafka's existing leader election mechanism — the same mechanism used for electing internal group and transaction coordinators within Kafka. NELI provides the necessary consensus without forcing application developers to deal with the intricacies of group management and atomic broadcast, and without introducing additional infrastructure dependencies.
Under NELI, leaders aren't agreed upon directly, but induced through other phenomena that are observable by the affected group members, allowing them to individually infer leadership. A member of a group can autonomously determine whether it is a leader or not. In the latter case, it cannot determine which process is the real leader, only that it is a process other than itself. While the information carried through NELI is not as comprehensive as an equivalent Atomic Broadcast, it is sufficient for leader election.
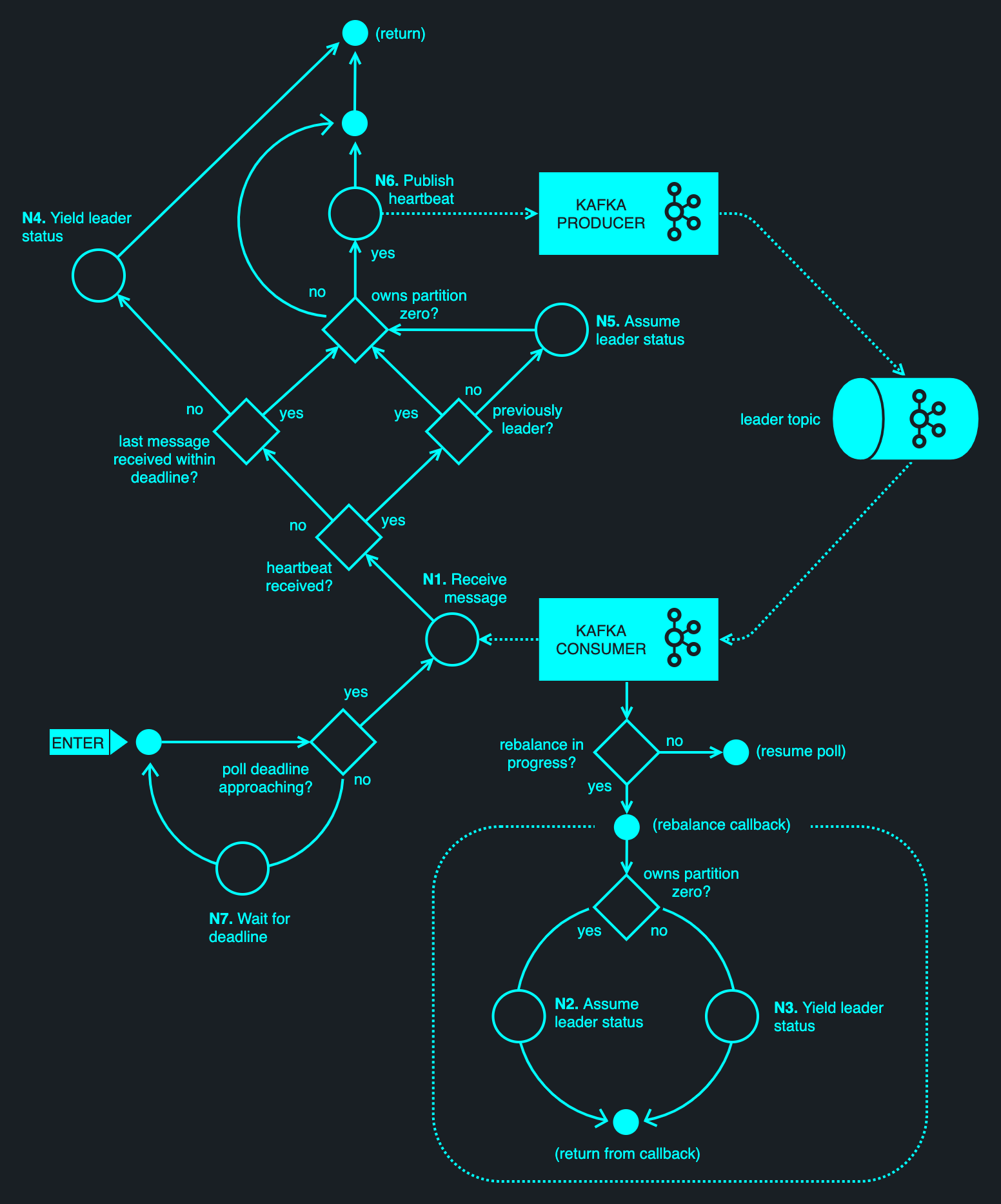
When a NELI client starts, it has no knowledge of whether it is a leader or a standby process. It uses an internal Kafka consumer client to subscribe to a topic specified by Config.LeaderTopic, using the Config.LeaderGroupID consumer group. These parameters may be chosen arbitrarily; however, they must be shared by all members of the encompassing process group, and may not be shared with members of unrelated process groups. As part of the subscription, a rebalance listener callback is registered with the Kafka consumer — to be notified of partition reassignments.
No matter the chosen topic, it will always (by definition) have at least one partition — partition zero. It may carry other partitions too — indexes 1 through to N-1, where N is the topic width, but these may be disregarded. Ultimately, Kafka will assign at most one owner to any given partition — picking one consumer from the encompassing consumer group. (We say 'at most' because all consumers might be offline.) For partition zero, one process will be assigned ownership; others will be kept in a holding pattern — waiting for the current assignee to depart.
Having subscribed to the topic, the client will repeatedly poll Kafka for new messages. Polling is essential, as Kafka uses the polling mechanism as a way of verifying consumer liveness. (Under the hood, a Kafka client sends periodic heartbeats, which are tied to topic polling.) Should a consumer stop polling, heartbeats will stop flowing and Kafka's group coordinator will presume the client has died — reassigning partition ownership among the remaining clients. The client issues a poll at an interval specified by Config.MinPollInterval, defaulting to 100 ms.
Once the client discovers that it has been assigned partition zero, it will set a pair of internal flags isAssigned and isLeader. The former indicating that the client owns partition zero; the latter indicating that it is the assumed leader. It will also invoke the optionally supplied Barrier callback with a LeaderAcquired event, allowing the application to handle the leadership assignment. (For example, to initialise the necessary state before commencing its work.)
Kafka's group coordinator may later choose to reassign the partition to another process. This occurs if the current leader times out, or if the population of contending processes changes. Either way, a leadership change is picked up via the rebalance callback. If the current leader sees that partition zero has been revoked, it will clear both flags and invoke the Barrier callback with a LeaderRevoked event.
The rebalance callback straightforwardly determines leadership through partition assignment, where the latter is managed by Kafka's group coordinator. The use of the callback requires a stable network connection to the Kafka cluster; otherwise, if a network partition occurs, another client may be granted partition ownership behind the scenes — an event which is not synchronized with the outgoing leader. (Kafka's internal heartbeats are used to signal client presence to the broker, but they are not generally suitable for identifying network partitions.)
In addition to observing partition assignment changes, the owner of partition zero periodically publishes a heartbeat message to Config.LeaderTopic. The client also consumes messages from that topic — effectively observing its own heartbeats, and thereby asserting that it is connected to the cluster and still owns the partition in question. If no heartbeat is received within the period specified by Config.ReceiveDeadline (5 seconds by default), the leader will clear the isLeader lag, while maintaining isAssigned. It will then forward a LeaderFenced event to the Barrier callback, taking the worst-case assumption that the partition will be reassigned. If connectivity is later resumed while the process is still the owner of the partition on the broker, it will again receive a heartbeat, allowing it to resume the leader role. If the partition has been subsequently reassigned, no heartbeat messages will be received upon reconnection and the client will be forced to rejoin the group — the act of which will invoke the rebalance callback, effectively resetting the client.
The diagram below illustrates the Fast NELI algorithm.