
The web has evolved. Finally, web scraping has too.


A new version has been released, with performance boost. To update please run python -m pip install bota botasaurus botasaurus-api botasaurus-requests botasaurus-driver bota botasaurus-proxy-authentication botasaurus-server --upgrade.
How wonderful that of all the web scraping tools out there, you chose to learn about Botasaurus. Congratulations!
And now that you are here, you are in for an exciting, unusual and rewarding journey that will make your web scraping life a lot, lot easier.
Now, let me tell you in bullet points about Botasaurus. (Because as per the marketing gurus, YOU as a member of Developer Tribe have a VERY short attention span.)
So, what is Botasaurus?
Botasaurus is an all-in-one web scraping framework that enables you to build awesome scrapers in less time, less code, and with more fun.
A Web Scraping Magician has put all his web scraping experience and best practices into Botasaurus to save you hundreds of hours of Development Time!
Now, for the magical powers awaiting you after learning Botasaurus:
- Convert any Web Scraper to a UI-based Scraper in minutes, which will make your Customer sing praises of you.
- In terms of humaneness, what Superman is to Man, Botasaurus is to Selenium and Playwright. Easily pass every (Yes E-V-E-R-Y) bot test, no need to spend time finding ways to access a website.
-
Save up to 97%, yes 97% on browser proxy costs by using browser-based fetch requests.
-
Easily save hours of Development Time with easy parallelization, profiles, extensions, and proxy configuration. Botasaurus makes asynchronous, parallel scraping a child's play.
-
Use Caching, Sitemap, Data cleaning, and other utilities to save hours of time spent in writing and debugging code.
-
Easily scale your scraper to multiple machines with Kubernetes, and get your data faster than ever.
And those are just the highlights. I Mean!
There is so much more to Botasaurus, that you will be amazed at how much time you will save with it.
Let's dive right in with a straightforward example to understand Botasaurus.
In this example, we will go through the steps to scrape the heading text from https://www.omkar.cloud/.
First things first, you need to install Botasaurus. Run the following command in your terminal:
python -m pip install botasaurusNext, let's set up the project:
- Create a directory for your Botasaurus project and navigate into it:
mkdir my-botasaurus-project
cd my-botasaurus-project
code . # This will open the project in VSCode if you have it installedNow, create a Python script named main.py in your project directory and paste the following code:
from botasaurus.browser import browser, Driver
@browser
def scrape_heading_task(driver: Driver, data):
# Visit the Omkar Cloud website
driver.get("https://www.omkar.cloud/")
# Retrieve the heading element's text
heading = driver.get_text("h1")
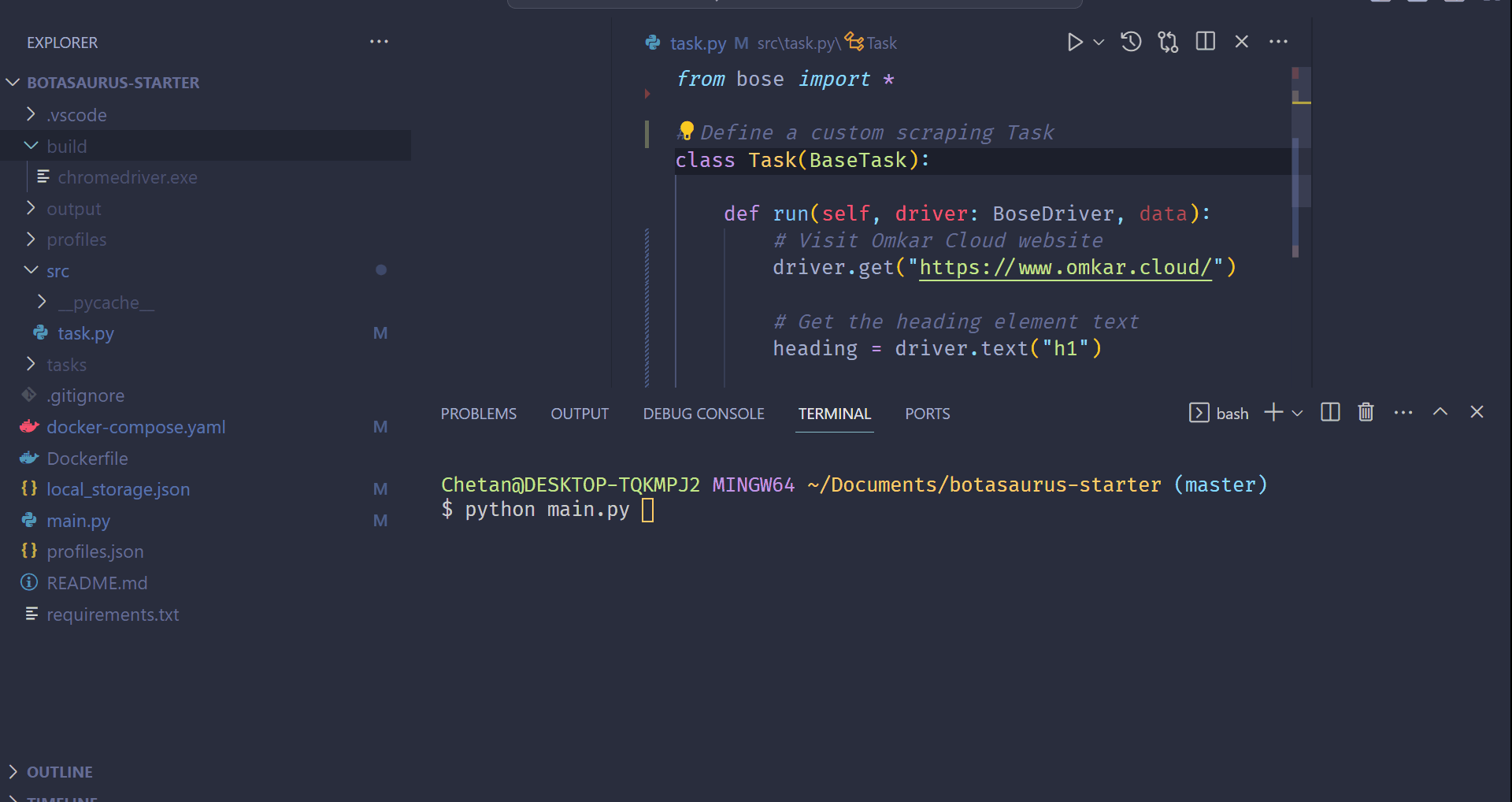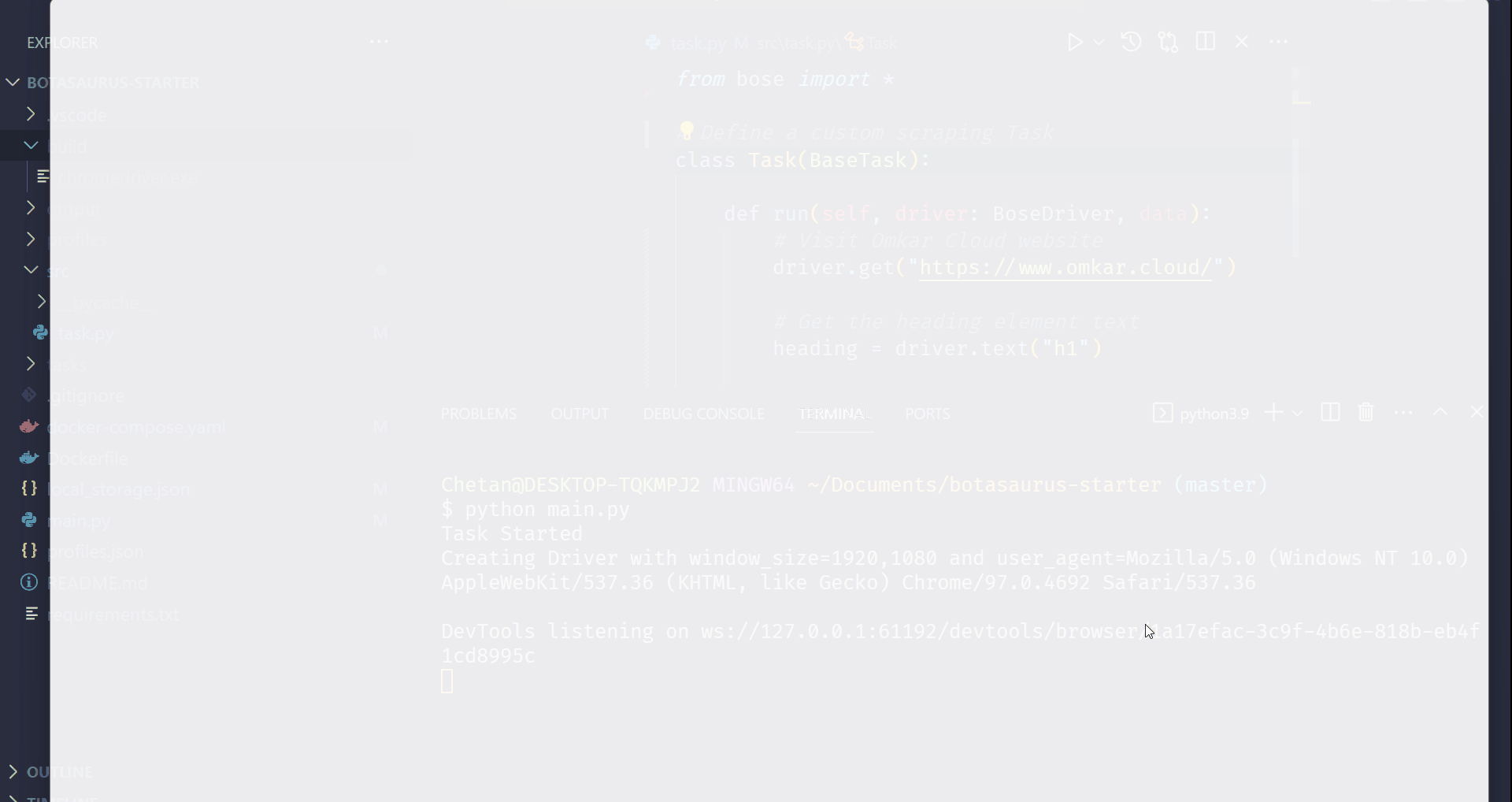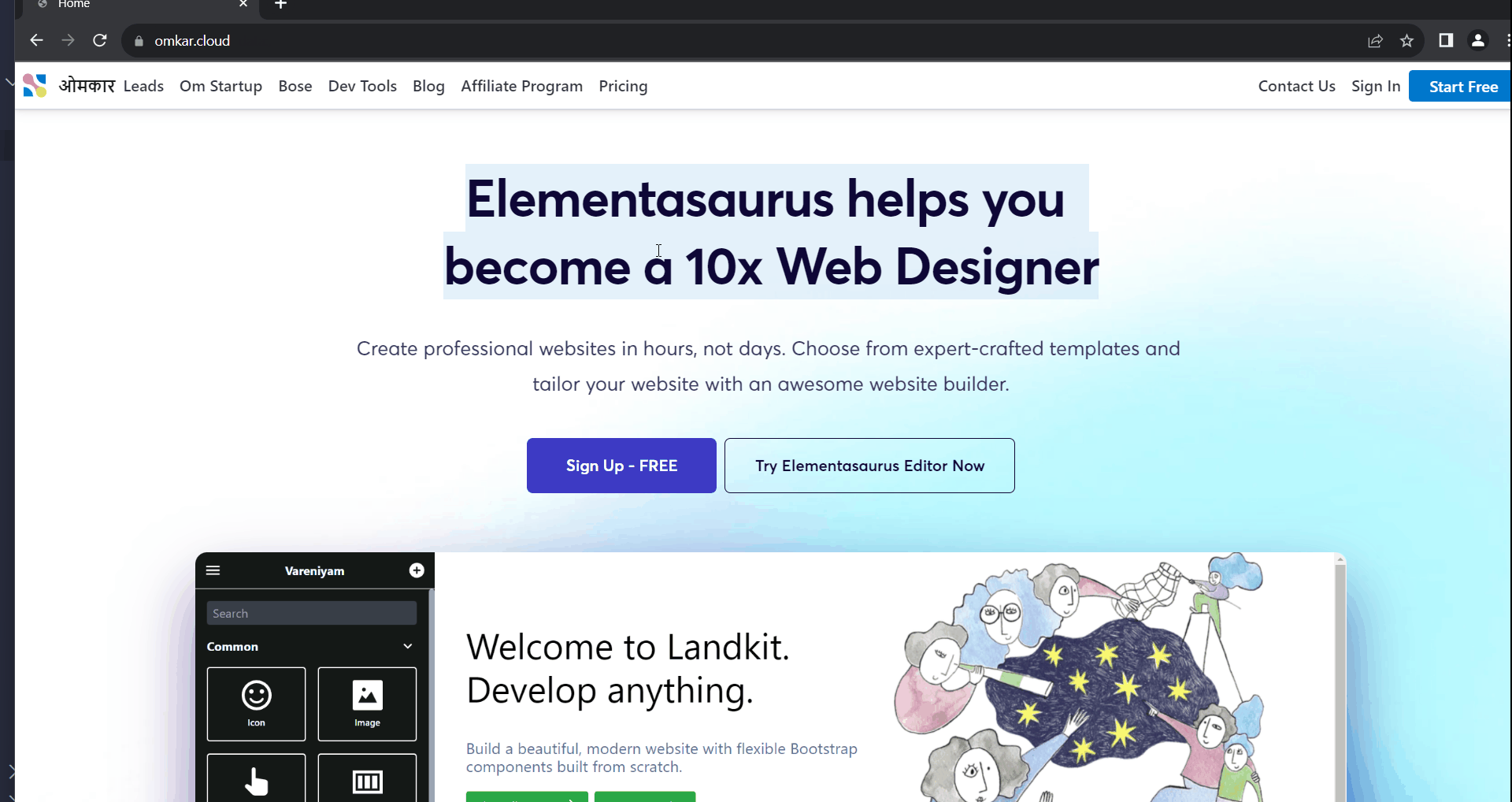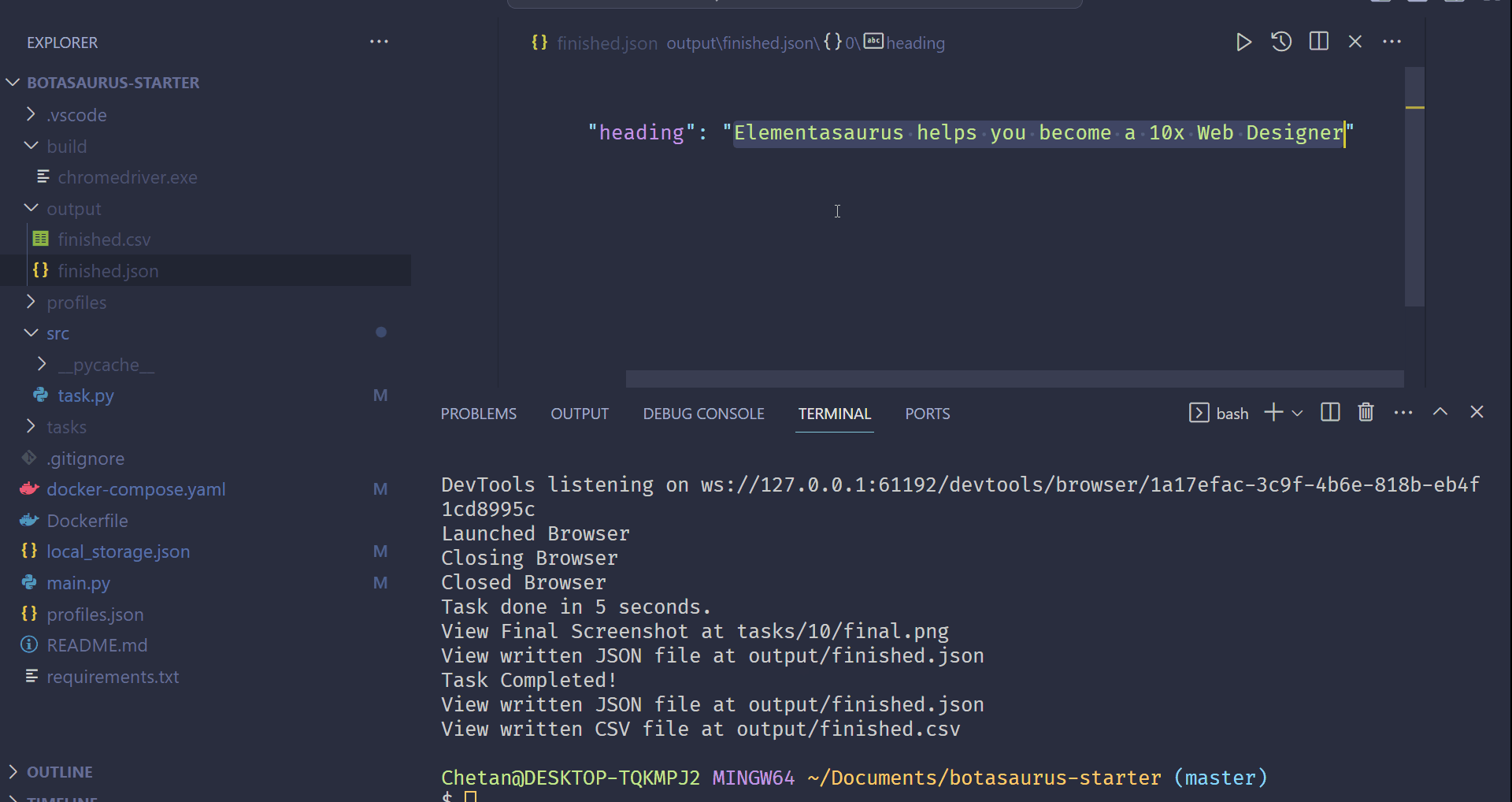
# Save the data as a JSON file in output/scrape_heading_task.json
return {
"heading": heading
}
# Initiate the web scraping task
scrape_heading_task()Let's understand this code:
- We define a custom scraping task,
scrape_heading_task, decorated with@browser:
@browser
def scrape_heading_task(driver: Driver, data):- Botasaurus automatically provides an Humane Driver to our function:
def scrape_heading_task(driver: Driver, data):- Inside the function, we:
- Visit Omkar Cloud
- Extract the heading text
- Return the data to be automatically saved as
scrape_heading_task.jsonby Botasaurus:
driver.get("https://www.omkar.cloud/")
heading = driver.get_text("h1")
return {"heading": heading}- Finally, we initiate the scraping task:
# Initiate the web scraping task
scrape_heading_task()Time to run it:
python main.pyAfter executing the script, it will:
- Launch Google Chrome
- Visit omkar.cloud
- Extract the heading text
- Save it automatically as
output/scrape_heading_task.json.
Now, let's explore another way to scrape the heading using the request module. Replace the previous code in main.py with the following:
from botasaurus.request import request, Request
from botasaurus.soupify import soupify
@request
def scrape_heading_task(request: Request, data):
# Visit the Omkar Cloud website
response = request.get("https://www.omkar.cloud/")
# Create a BeautifulSoup object
soup = soupify(response)
# Retrieve the heading element's text
heading = soup.find('h1').get_text()
# Save the data as a JSON file in output/scrape_heading_task.json
return {
"heading": heading
}
# Initiate the web scraping task
scrape_heading_task()In this code:
- We scrape the HTML using
request, which is specifically designed for making browser-like humane requests. - Next, we parse the HTML into a
BeautifulSoupobject usingsoupify()and extract the heading.
Finally, run it again:
python main.pyThis time, you will observe the exact same result as before, but instead of opening a whole Browser, we are making browser-like humane HTTP requests.
Botasaurus Driver is a web automation driver like Selenium, and the single most important reason to use it is because it is truly humane, and you will not, and I repeat NOT, have any issues with accessing any website.
Plus, it is super fast to launch and use, and the API is designed by and for web scrapers, and you will love it.
Cloudflare is the most popular protection system on the web. So, let's see how Botasaurus can help you solve various Cloudflare challenges.
Connection Challenge
This is the single most popular challenge and requires making a browser-like connection with appropriate headers. It's commonly used for:
- Product Pages
- Blog Pages
- Search Result Pages
Example Page: https://www.g2.com/products/github/reviews
- Visiting the website via Google Referrer (which makes is seems as if the user has arrived from google search).
from botasaurus.browser import browser, Driver
@browser
def scrape_heading_task(driver: Driver, data):
# Visit the website via Google Referrer
driver.google_get("https://www.g2.com/products/github/reviews")
driver.prompt()
heading = driver.get_text('.product-head__title [itemprop="name"]')
return heading
scrape_heading_task()- Use the request module. The Request Object is smart and, by default, visits any link with a Google Referrer. Although it works, you will need to use retries.
from botasaurus.request import request, Request
@request(max_retry=10)
def scrape_heading_task(request: Request, data):
response = request.get('https://www.g2.com/products/github/reviews')
print(response.status_code)
response.raise_for_status()
return response.text
scrape_heading_task()JS with Captcha Challenge
This challenge requires performing JS computations that differentiate a Chrome controlled by Selenium/Puppeteer/Playwright from a real Chrome. It also involves solving a Captcha. It's used to for pages which are rarely but sometimes visited by people, like:
- 5th Review page
- Auth pages
Example Page: https://www.g2.com/products/github/reviews.html?page=5&product_id=github
Using @request does not work because although it can make browser-like HTTP requests, it cannot run JavaScript to solve the challenge.
Pass the bypass_cloudflare=True argument to the google_get method.
from botasaurus.browser import browser, Driver
@browser
def scrape_heading_task(driver: Driver, data):
driver.google_get("https://www.g2.com/products/github/reviews.html?page=5&product_id=github", bypass_cloudflare=True)
driver.prompt()
heading = driver.get_text('.product-head__title [itemprop="name"]')
return heading
scrape_heading_task()Here are some benefits of creating a scraper with a user interface:
- Simplify your scraper usage for customers, eliminating the need to teach them how to modify and run your code.
- Protect your code by hosting the scraper on the web and offering a monthly subscription, rather than providing full access to your code. This approach:
- Safeguards your Python code from being copied and reused, increasing your customer's lifetime value.
- Generate monthly recurring revenue via subscription from your customers, surpassing a one-time payment.
- Enable sorting, filtering, and downloading of data in various formats (JSON, Excel, CSV, etc.).
- Provide access via a REST API for seamless integration.
- Create a polished frontend, backend, and API integration with minimal code.
Let's run the Botasaurus Starter Template (the recommended template for greenfield Botasaurus projects), which scrapes the heading of the provided link by following these steps:
-
Clone the Starter Template:
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project cd my-botasaurus-project -
Install dependencies (will take a few minutes):
python -m pip install -r requirements.txt python run.py install -
Run the scraper:
python run.py
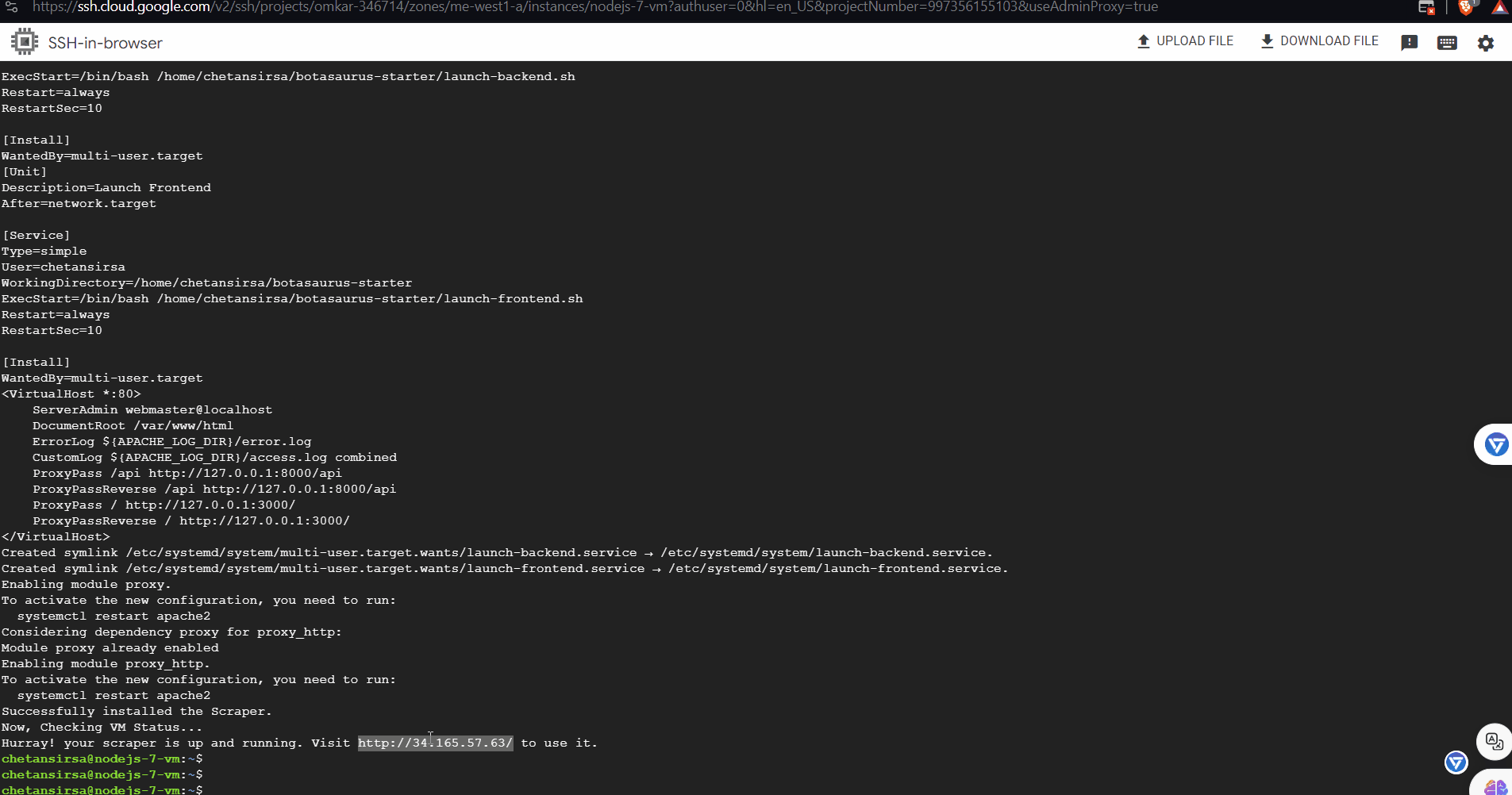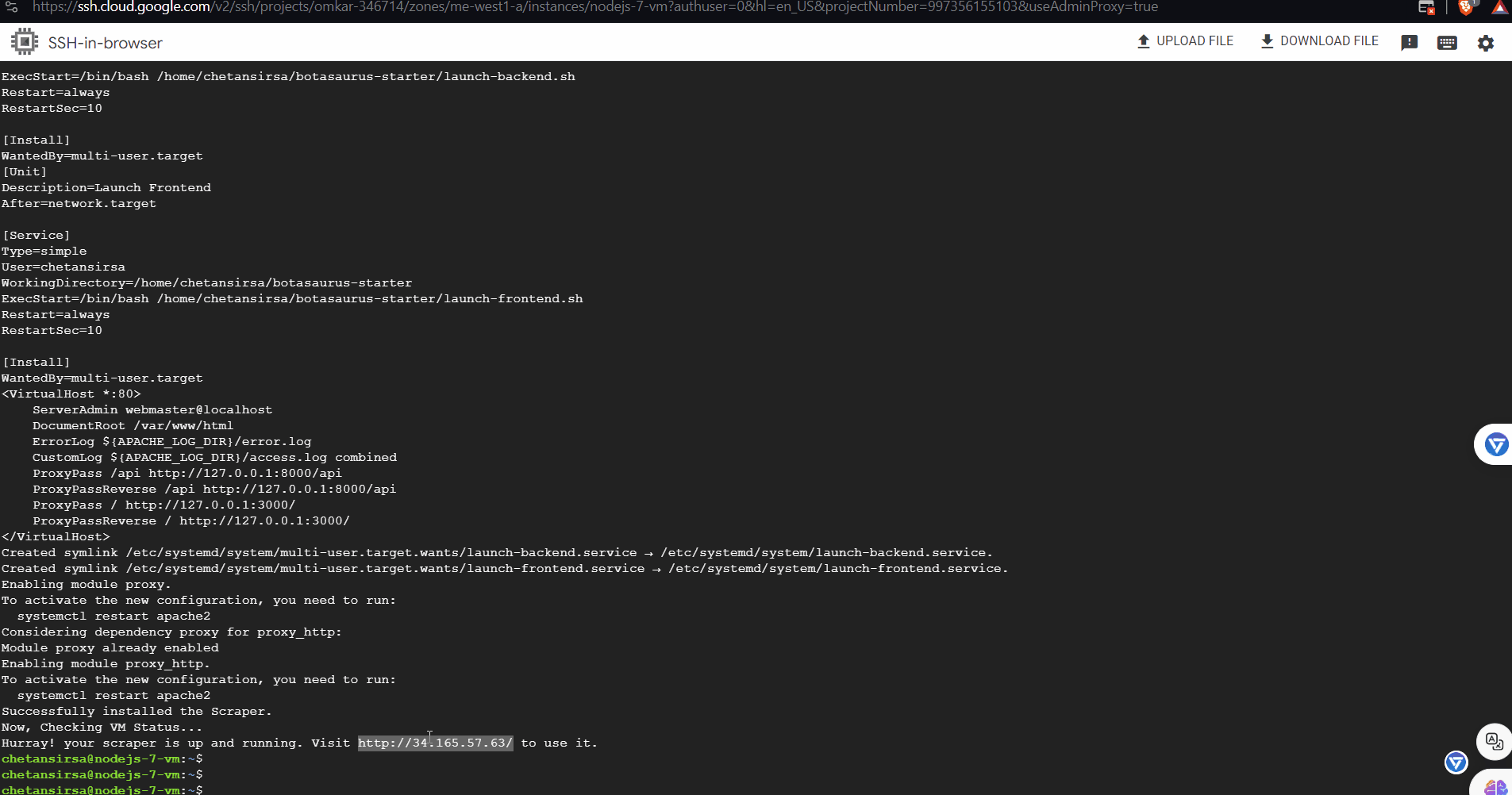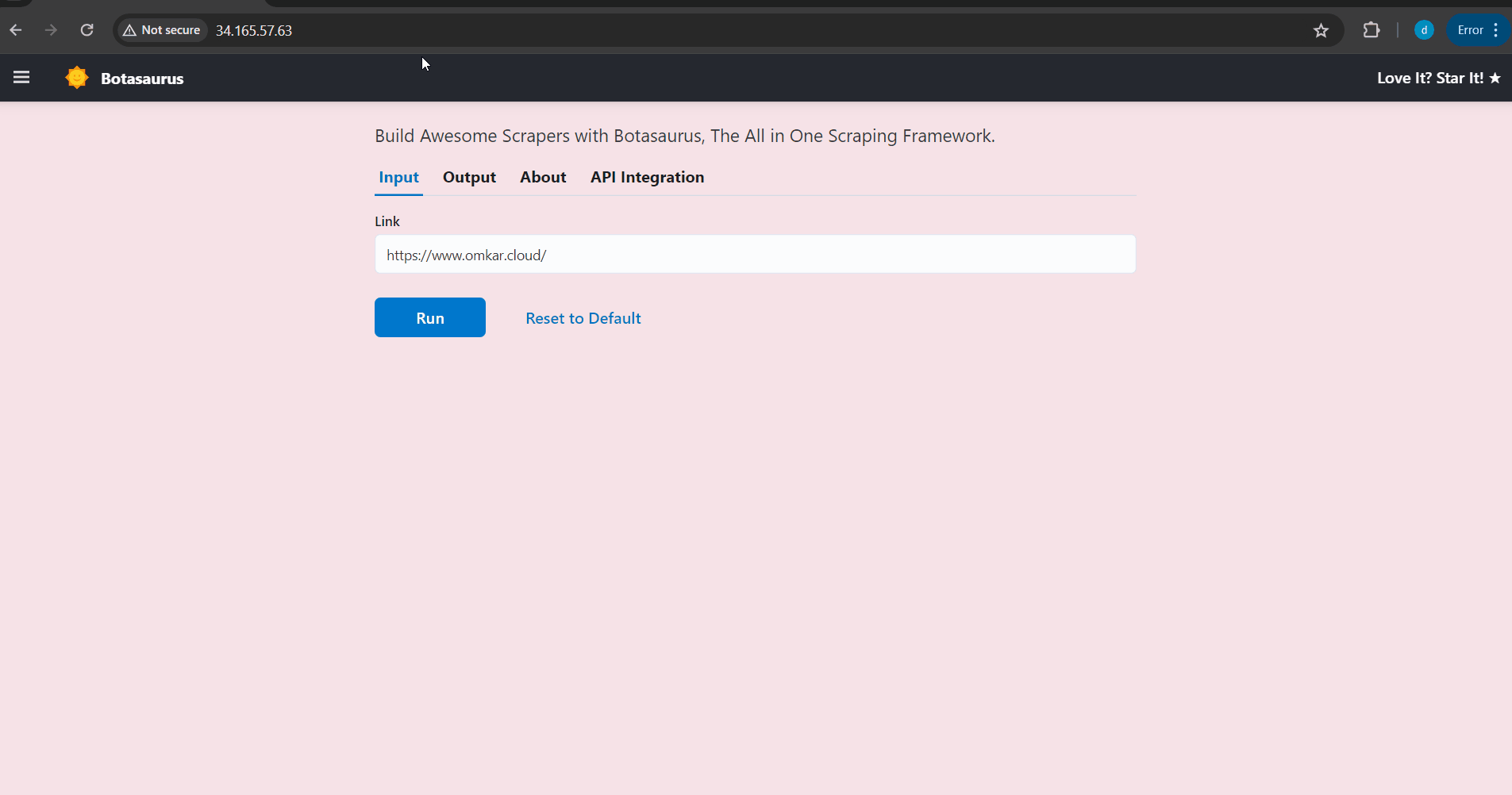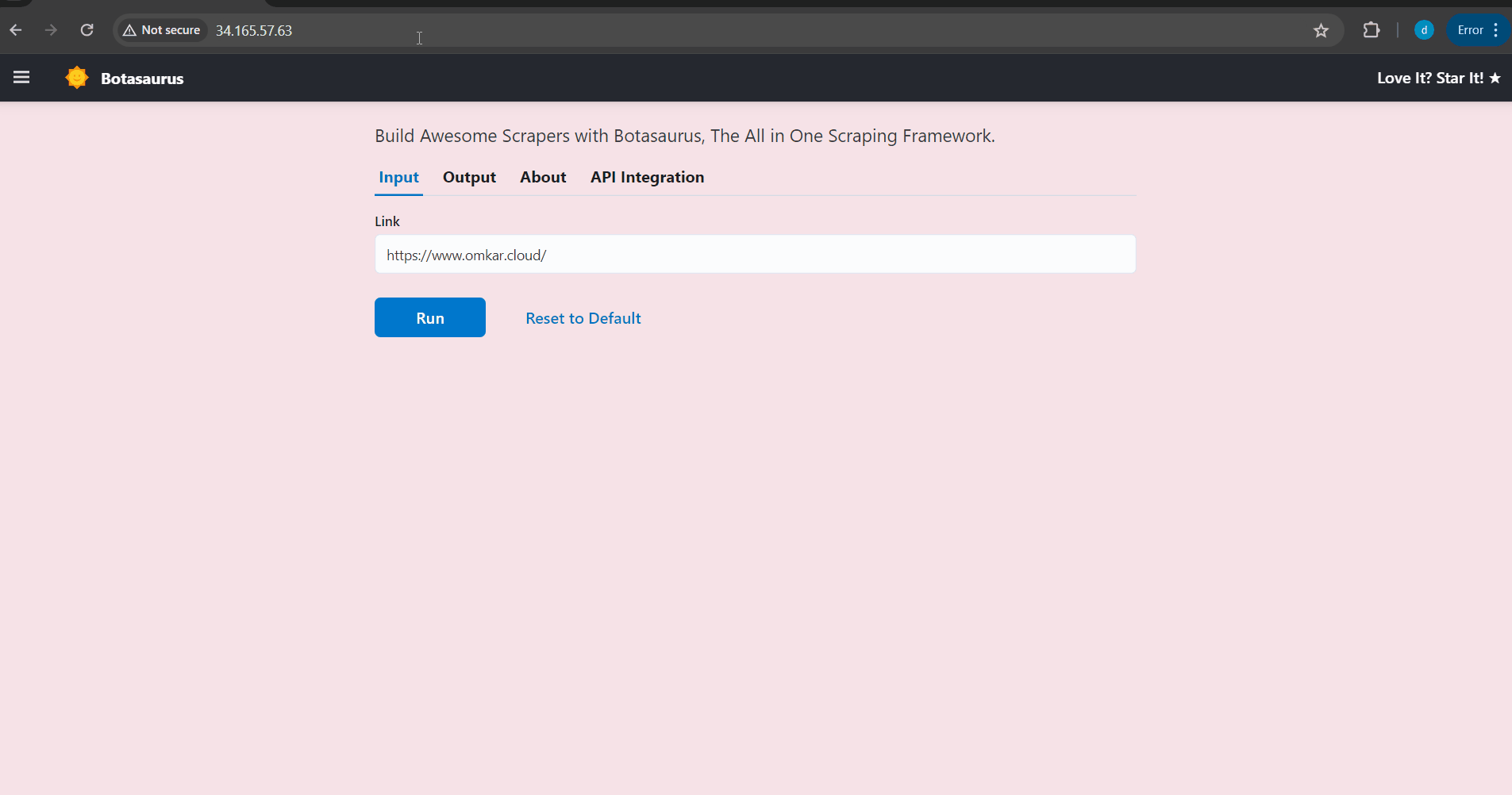
Your browser will automatically open up at http://localhost:3000/. Then, enter the link you want to scrape (e.g., https://www.omkar.cloud/) and click on the Run Button.
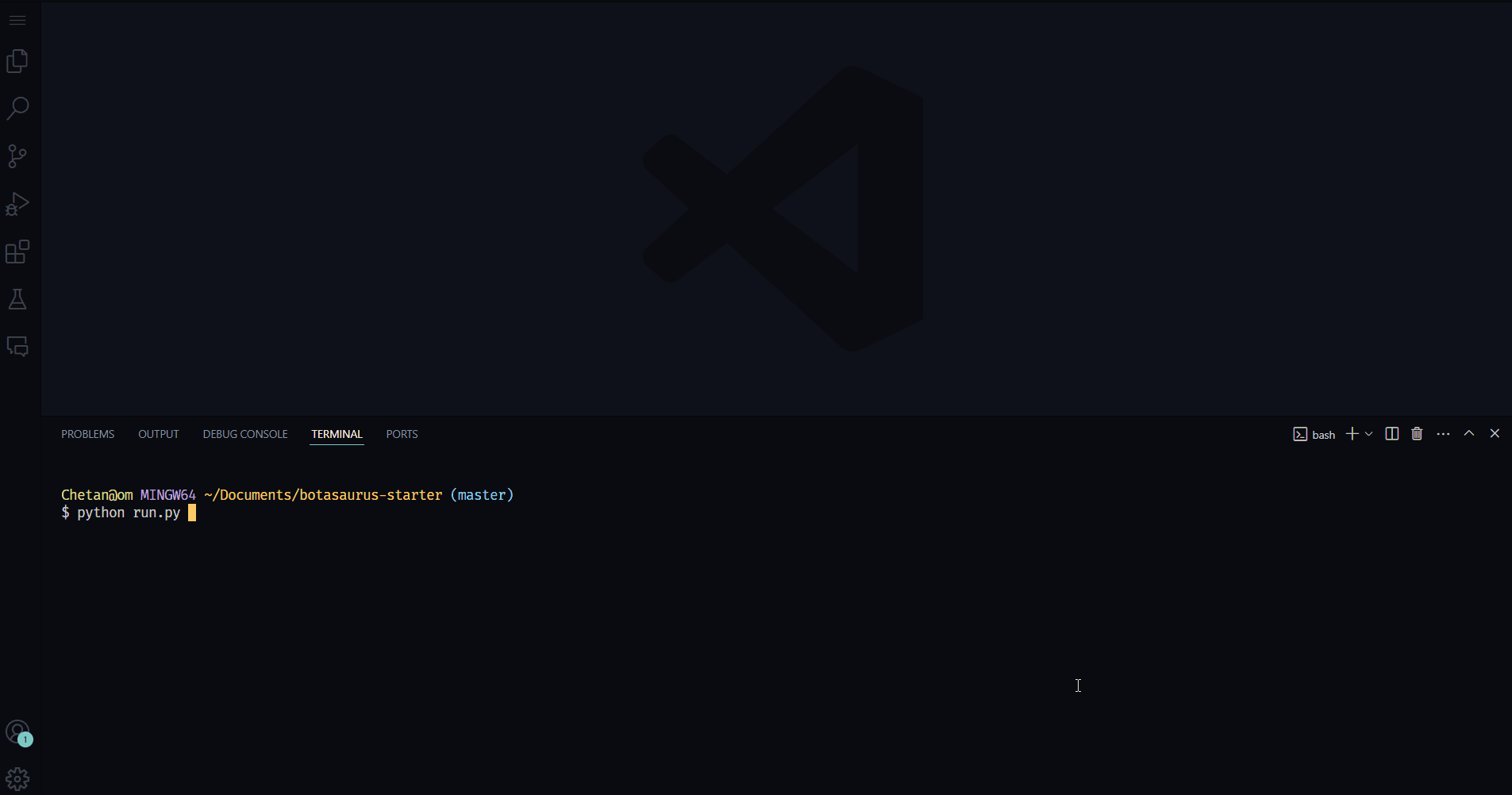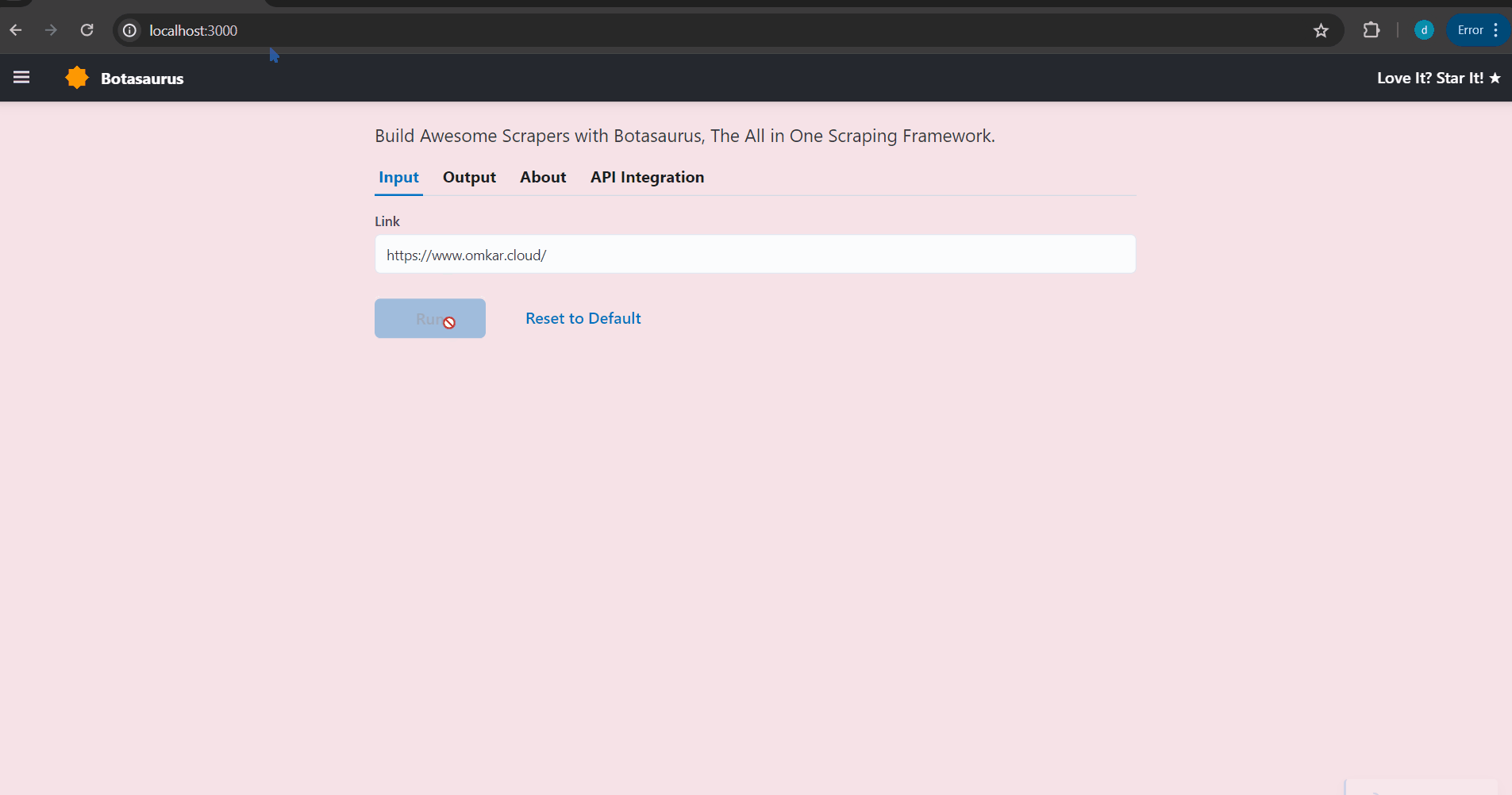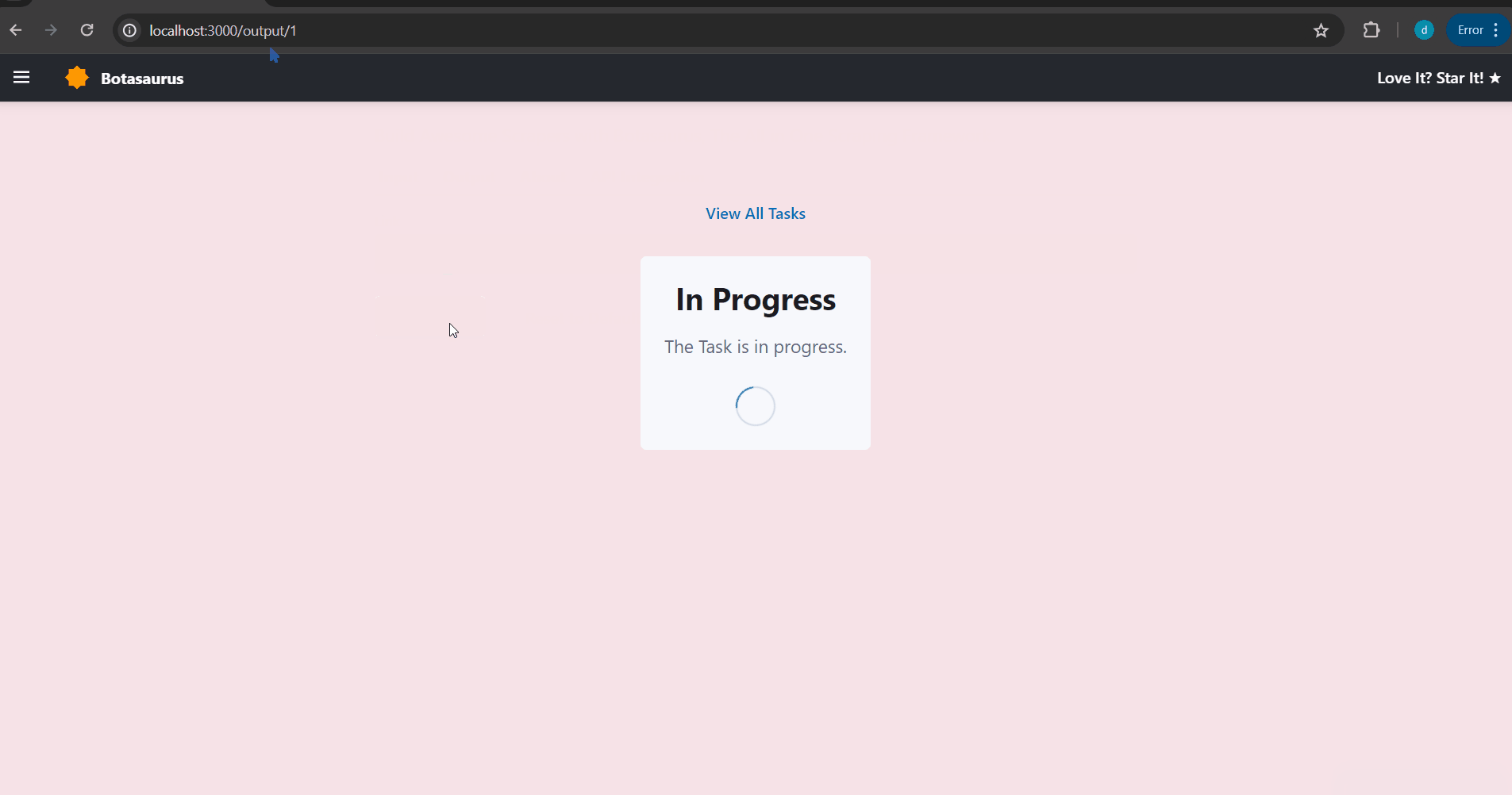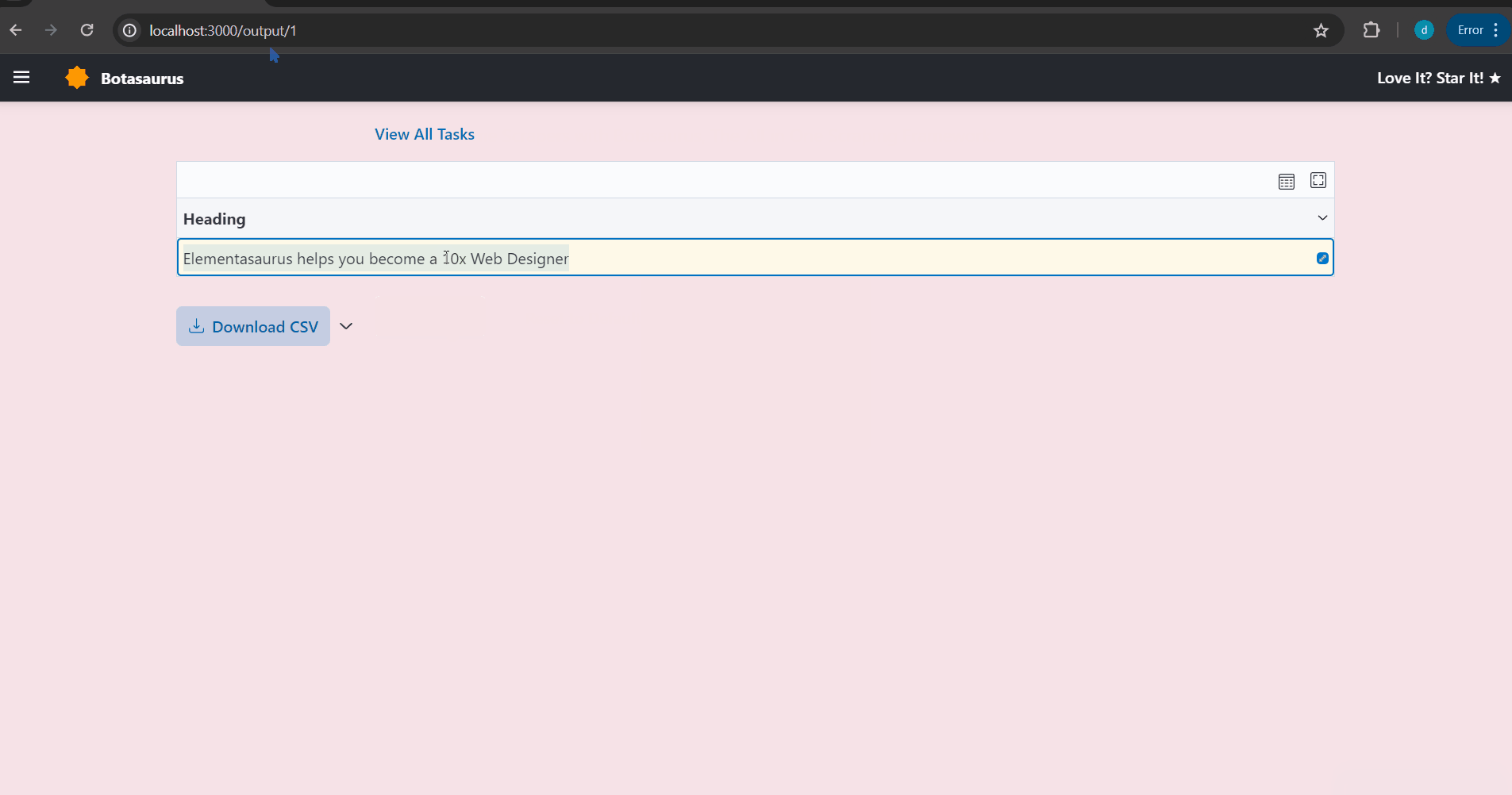
After some seconds, the data will be scraped.
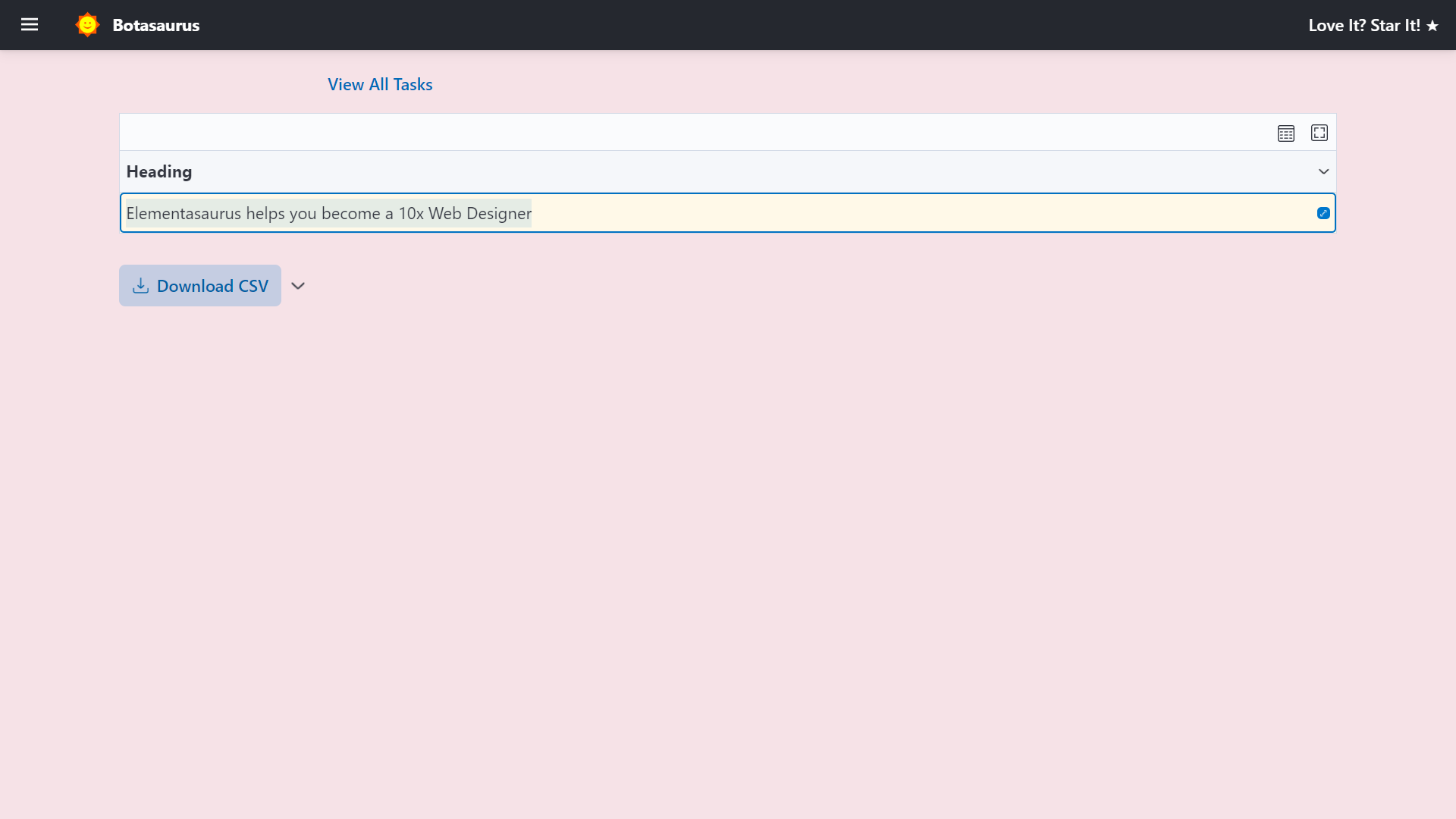
Visit http://localhost:3000/output to see all the tasks you have started.
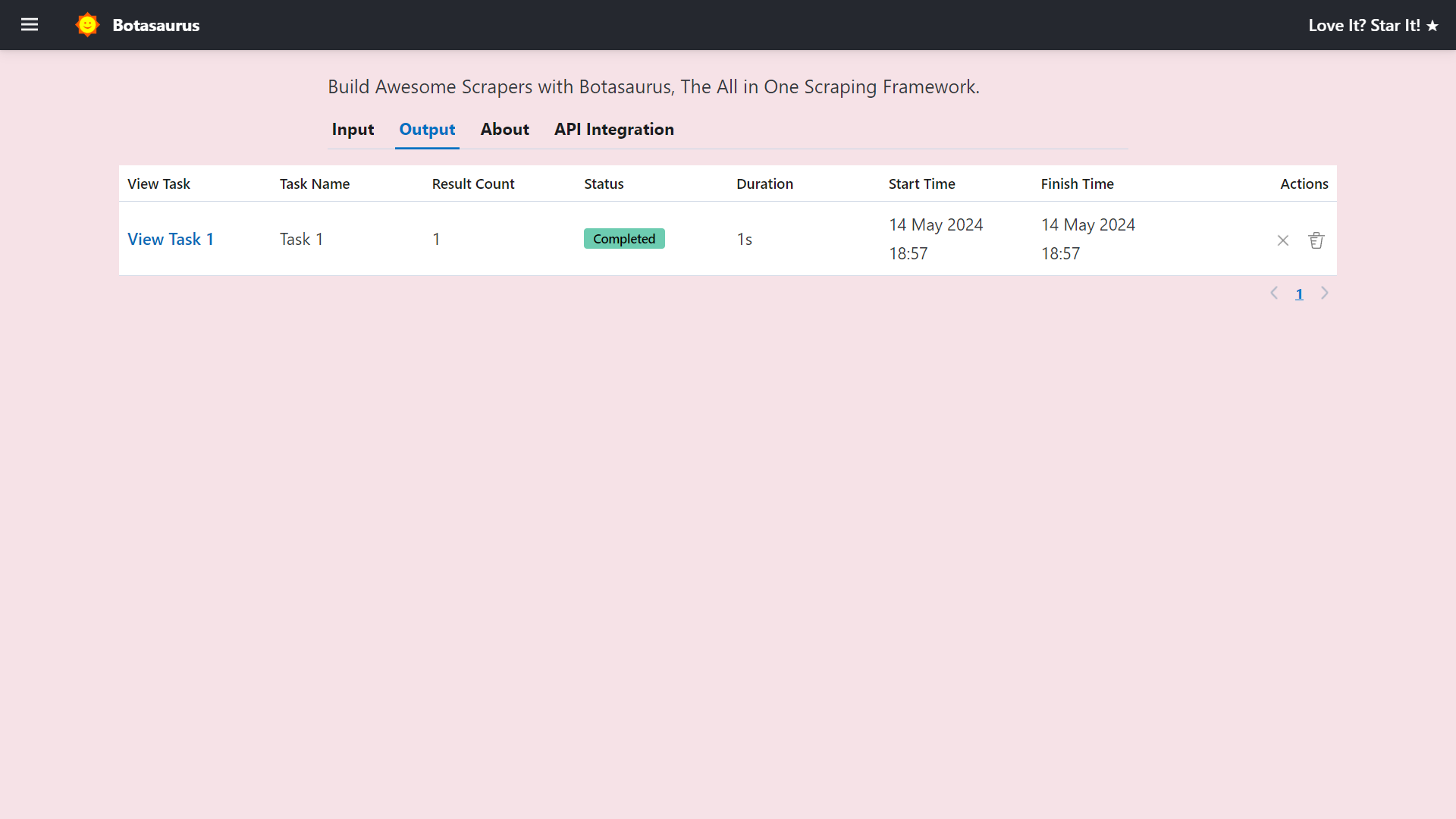
Go to http://localhost:3000/about to see the rendered README.md file of the project.
Finally, visit http://localhost:3000/api-integration to see how to access the Scraper via API.
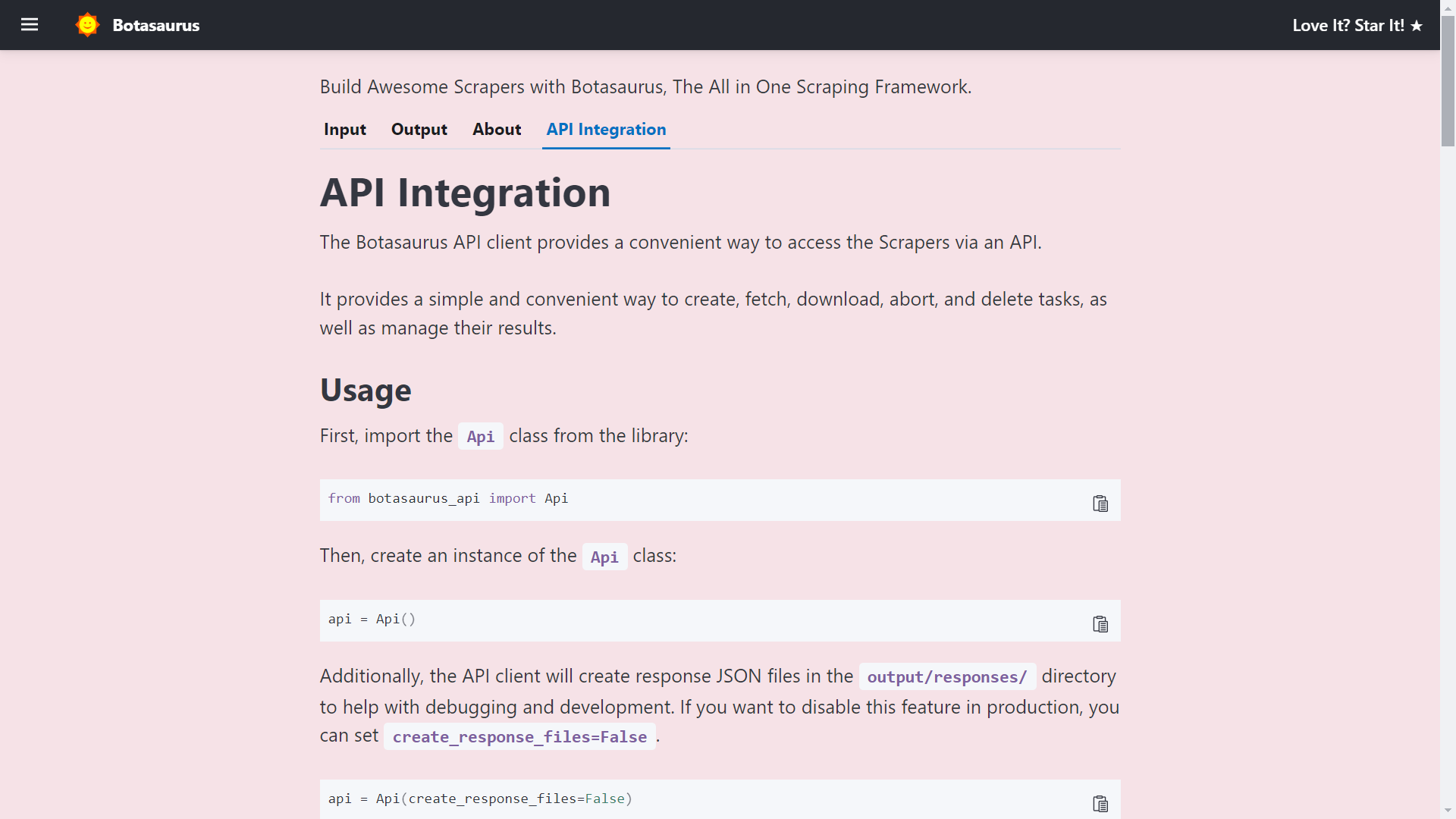
The API Documentation is generated dynamically based on your Scraper's Inputs, Sorts, Filters, etc., and is unique to your Scraper.
So, whenever you need to run the Scraper via API, visit this tab and copy the code specific to your Scraper.
Creating a UI Scraper with Botasaurus is a simple 3-step process:
- Create your Scraper function
- Add the Scraper to the Server using 1 line of code
- Define the input controls for the Scraper
To understand these steps, let's go through the code of the Botasaurus Starter Template that you just ran.
In src/scrape_heading_task.py, we define a scraping function which basically does the following:
- Receives a
dataobject and extracts the "link". - Retrieves the HTML content of the webpage using the "link".
- Converts the HTML into a BeautifulSoup object.
- Locates the heading element, extracts its text content and returns it.
from botasaurus.request import request, Request
from botasaurus.soupify import soupify
@request
def scrape_heading_task(request: Request, data):
# Visit the Link
response = request.get(data["link"])
# Create a BeautifulSoup object
soup = soupify(response)
# Retrieve the heading element's text
heading = soup.find('h1').get_text()
# Save the data as a JSON file in output/scrape_heading_task.json
return {
"heading": heading
}In backend/scrapers.py, we:
- Import our scraping function
- Use
Server.add_scraper()to register the scraper
from botasaurus_server.server import Server
from src.scrape_heading_task import scrape_heading_task
# Add the scraper to the server
Server.add_scraper(scrape_heading_task)In backend/inputs/scrape_heading_task.js we:
- Define a
getInputfunction that takes the controls parameter - Add a link input control to it
- Use comments to enable intellisense in VSCode (Very Very Important)
/**
* @typedef {import('../../frontend/node_modules/botasaurus-controls/dist/index').Controls} Controls
*/
/**
* @param {Controls} controls
*/
function getInput(controls) {
controls
// Render a Link Input, which is required, defaults to "https://www.omkar.cloud/".
.link('link', { isRequired: true, defaultValue: "https://www.omkar.cloud/" })
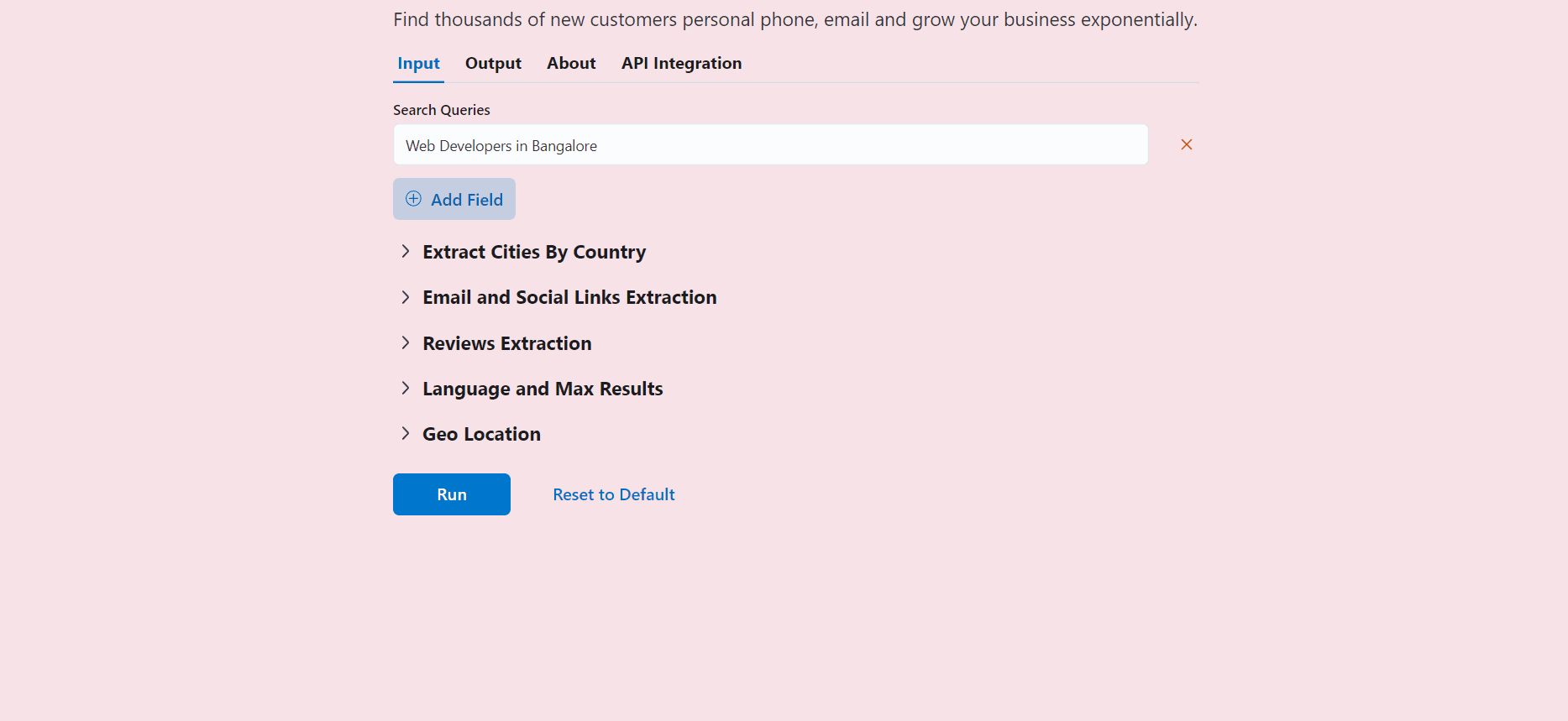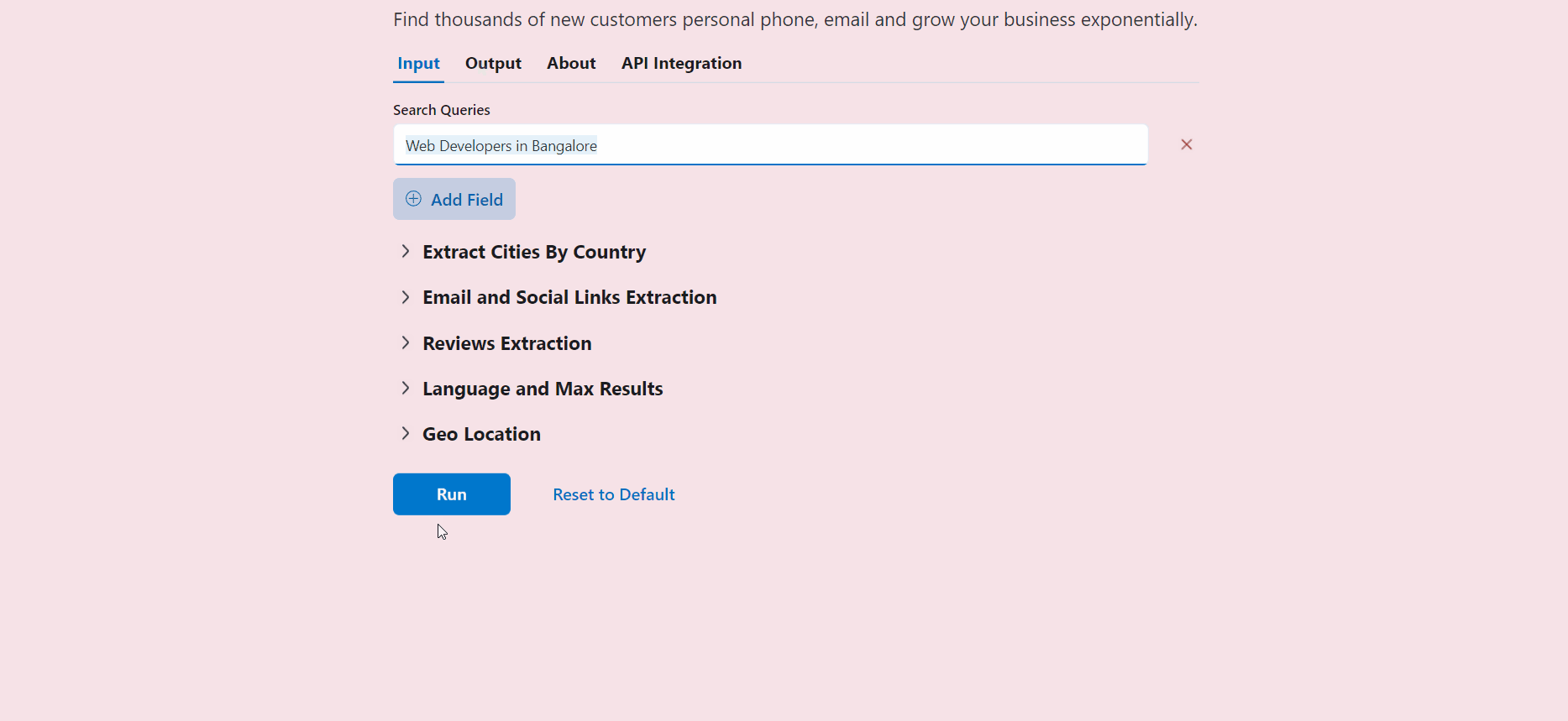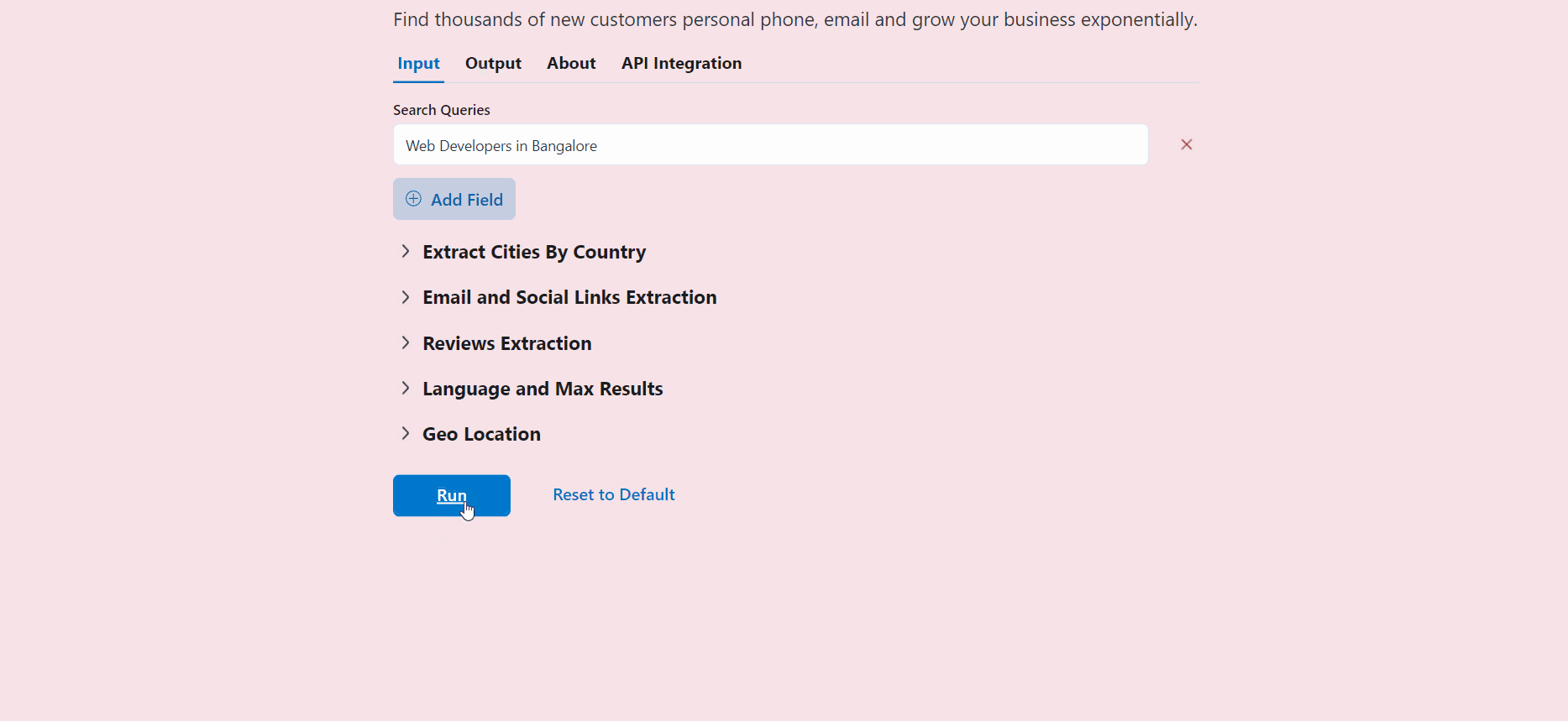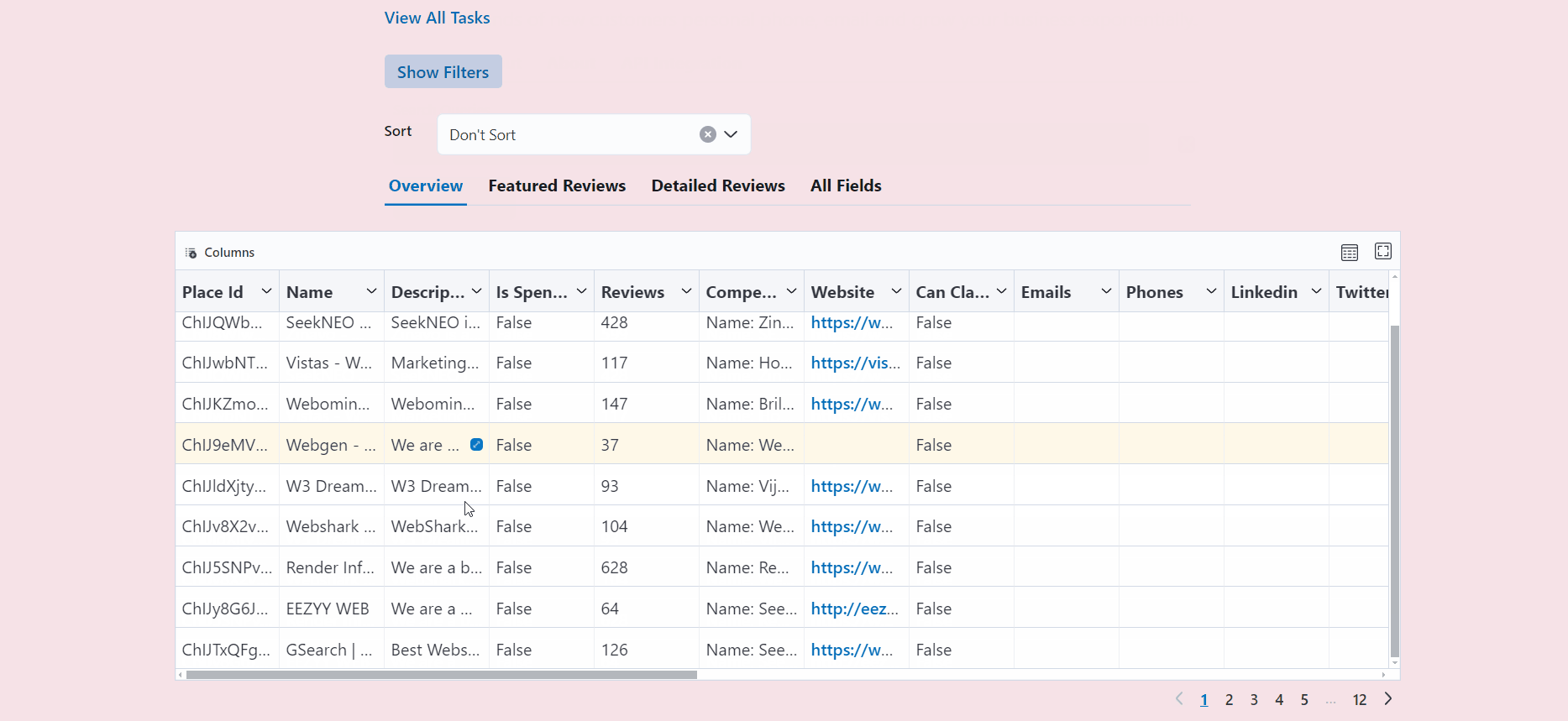
}Above was a simple example; below is a real-world example with multi-text, number, switch, select, section, and other controls.
/**
* @typedef {import('../../frontend/node_modules/botasaurus-controls/dist/index').Controls} Controls
*/
/**
* @param {Controls} controls
*/
function getInput(controls) {
controls
.listOfTexts('queries', {
defaultValue: ["Web Developers in Bangalore"],
placeholder: "Web Developers in Bangalore",
label: 'Search Queries',
isRequired: true
})
.section("Email and Social Links Extraction", (section) => {
section.text('api_key', {
placeholder: "2e5d346ap4db8mce4fj7fc112s9h26s61e1192b6a526af51n9",
label: 'Email and Social Links Extraction API Key',
helpText: 'Enter your API key to extract email addresses and social media links.',
})
})
.section("Reviews Extraction", (section) => {
section
.switch('enable_reviews_extraction', {
label: "Enable Reviews Extraction"
})
.numberGreaterThanOrEqualToZero('max_reviews', {
label: 'Max Reviews per Place (Leave empty to extract all reviews)',
placeholder: 20,
isShown: (data) => data['enable_reviews_extraction'], defaultValue: 20,
})
.choose('reviews_sort', {
label: "Sort Reviews By",
isRequired: true, isShown: (data) => data['enable_reviews_extraction'], defaultValue: 'newest', options: [{ value: 'newest', label: 'Newest' }, { value: 'most_relevant', label: 'Most Relevant' }, { value: 'highest_rating', label: 'Highest Rating' }, { value: 'lowest_rating', label: 'Lowest Rating' }]
})
})
.section("Language and Max Results", (section) => {
section
.addLangSelect()
.numberGreaterThanOrEqualToOne('max_results', {
placeholder: 100,
label: 'Max Results per Search Query (Leave empty to extract all places)'
})
})
.section("Geo Location", (section) => {
section
.text('coordinates', {
placeholder: '12.900490, 77.571466'
})
.numberGreaterThanOrEqualToOne('zoom_level', {
label: 'Zoom Level (1-21)',
defaultValue: 14,
placeholder: 14
})
})
}I encourage you to paste the above code into backend/inputs/scrape_heading_task.js and reload the page, and you will see a complex set of input controls like the image shown.
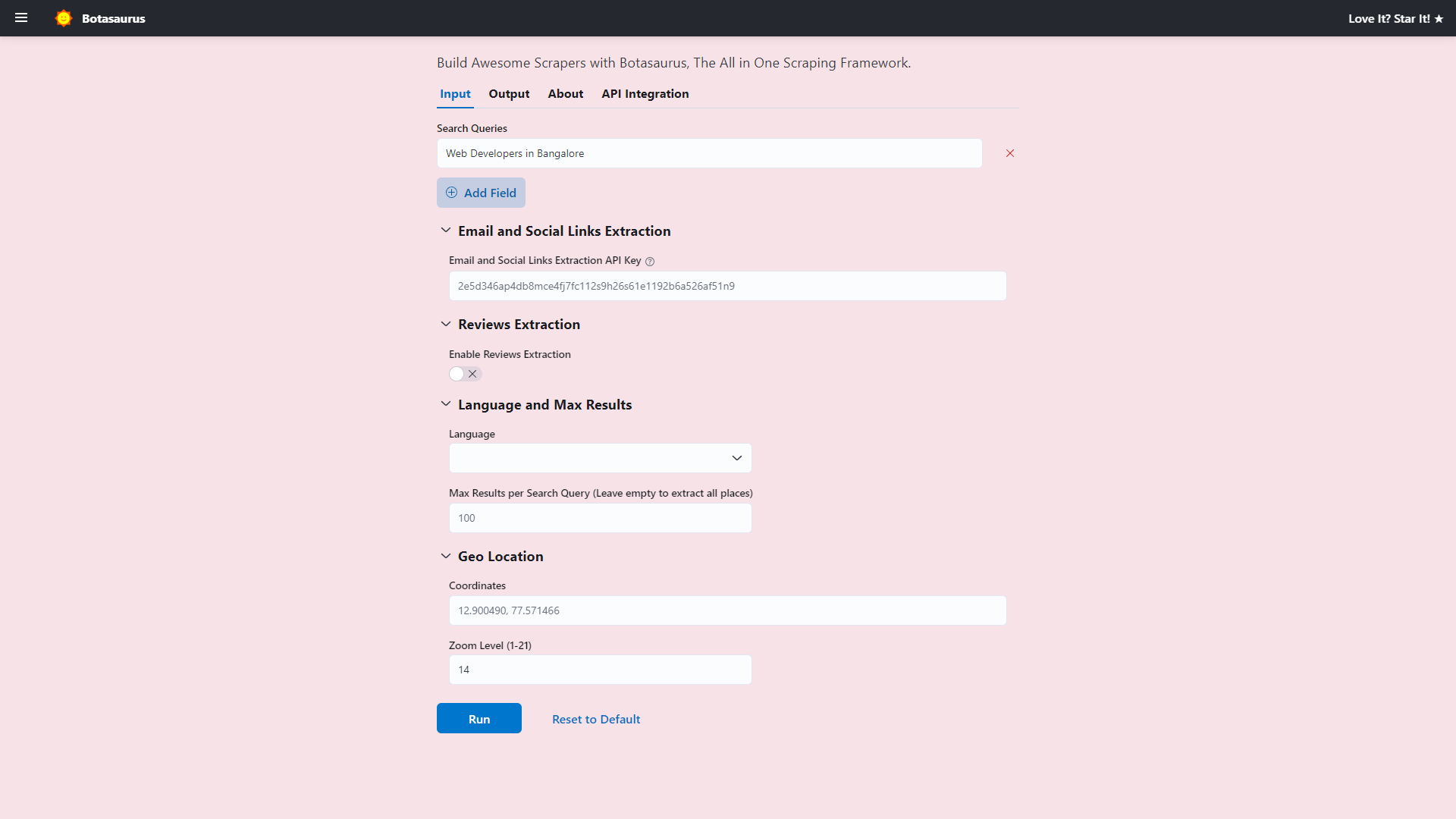
Now, to use Botasaurus UI for adding new scrapers, remember these points:
- Create a
backend/inputs/{your_scraping_function_name}.jsfile for each scraping function. - Define the
getInputfunction in the file with the necessary controls. - Add comments to enable intellisense in VSCode, as you won't be able to remember all the controls.
Use this template as a starting point for new scraping function's input controls js file:
/**
* @typedef {import('../../frontend/node_modules/botasaurus-controls/dist/index').Controls} Controls
*/
/**
* @param {Controls} controls
*/
function getInput(controls) {
// Define your controls here.
}That's it! With these simple steps, you can create a fully functional UI Scraper using Botasaurus.
Later, you will learn how to add sorts and filters to make your UI Scraper even more powerful and user-friendly.
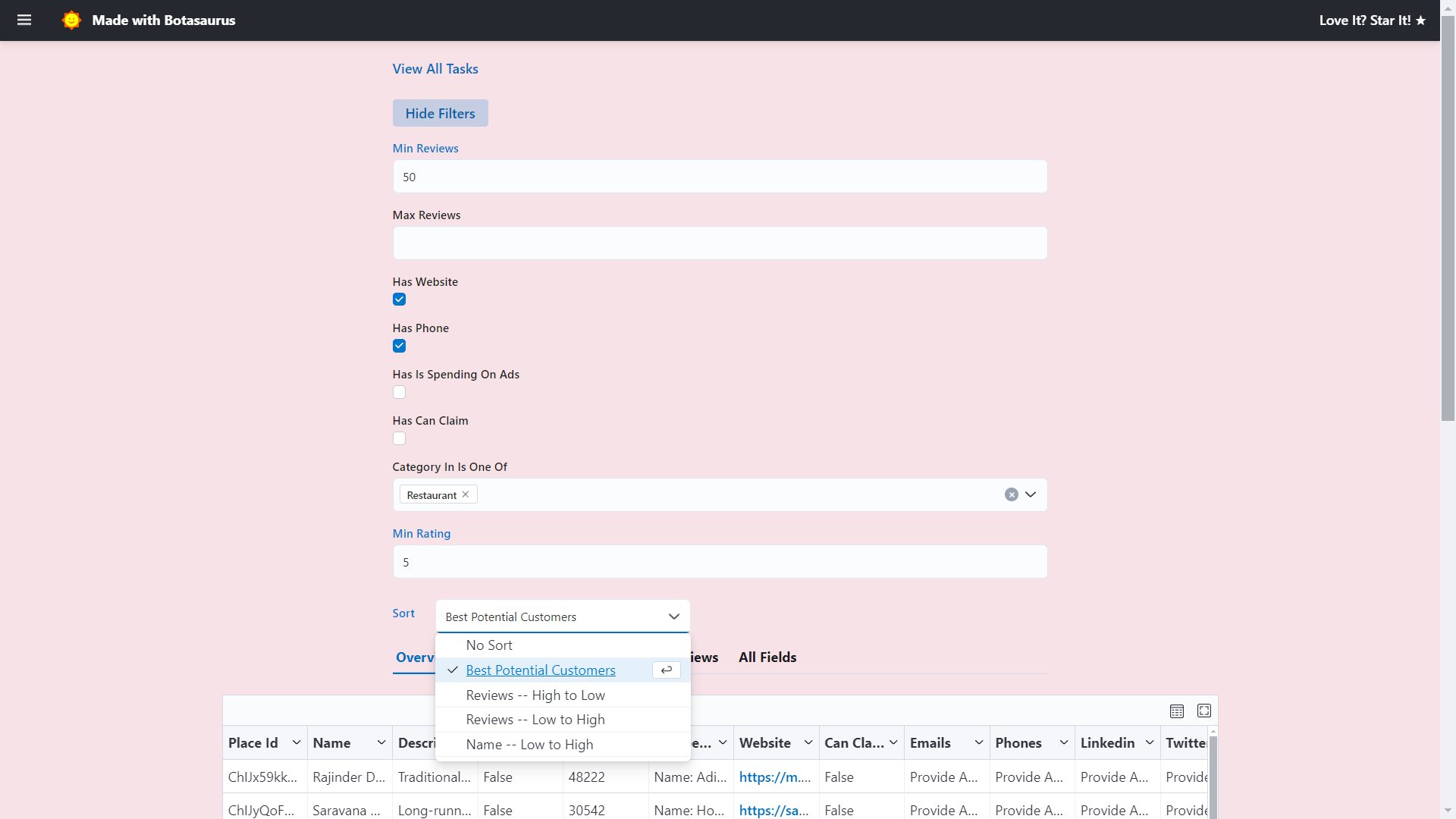
Botasaurus is an all-in-one web scraping framework designed to achieve two main goals:
- Provide common web scraping utilities to solve the pain points of web scraping.
- Offer a user interface to make it easy for your non-technical customers to run web scrapers.
To accomplish these goals, Botasaurus gives you 3 decorators:
@browser: For scraping web pages using a humane browser.@request: For scraping web pages using lightweight and humane HTTP requests.@task:- For scraping web pages using third-party libraries like
playwrightorselenium. - or, For running non-web scraping tasks, such as data processing (e.g., converting video to audio). Botasaurus is not limited to web scraping tasks; any Python function can be made accessible with a stunning UI and user-friendly API.
- For scraping web pages using third-party libraries like
In practice, while developing with Botasaurus, you will spend most of your time in the following areas:
- Configuring your scrapers via decorators with settings like:
- Which proxy to use
- How many scrapers to run in parallel, etc.
- Writing your core web scraping logic using BeautifulSoup (bs4) or the Botasaurus Driver.
Additionally, you will utilize the following Botasaurus utilities for debugging and development:
bt: Mainly for writing JSON, EXCEL, and HTML temporary files, and for data cleaning.Sitemap: For accessing the website's links and sitemap.- Minor utilities like:
LocalStorage: For storing scraper state.soupify: For creating BeautifulSoup objects from Driver, Requests response, Driver Element, or HTML string.IPUtils: For obtaining information (IP, country, etc.) about the current IP address.Cache: For managing the cache.
By simply configuring these three decorators (@browser, @request, and @task) with arguments, you can easily create real-time scrapers and large-scale datasets, thus saving you countless hours that would otherwise be spent writing and debugging code from scratch.
Decorators are the heart of Botasaurus. To use a decorator function, you can call it with:
- A single item
- A list of items
If a scraping function is given a list of items, it will sequentially call the scraping function for each data item.
For example, if you pass a list of three links to the scrape_heading_task function:
from botasaurus.browser import browser, Driver
@browser
def scrape_heading_task(driver: Driver, link):
driver.get(link)
heading = driver.get_text("h1")
return heading
scrape_heading_task(["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"]) # <-- list of itemsThen, Botasaurus will launch a new browser instance for each item, and the final results will be stored in output/scrape_heading_task.json.
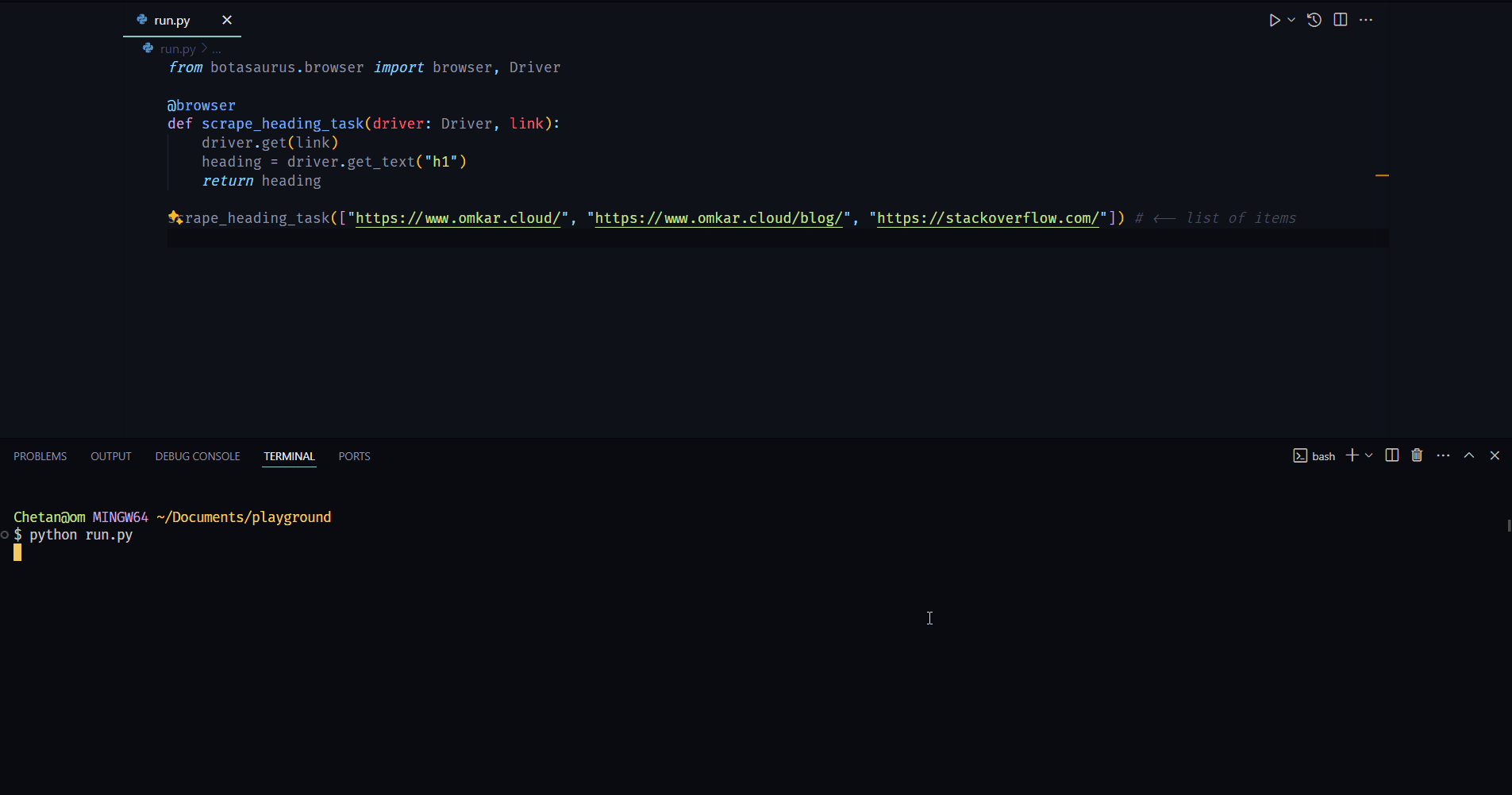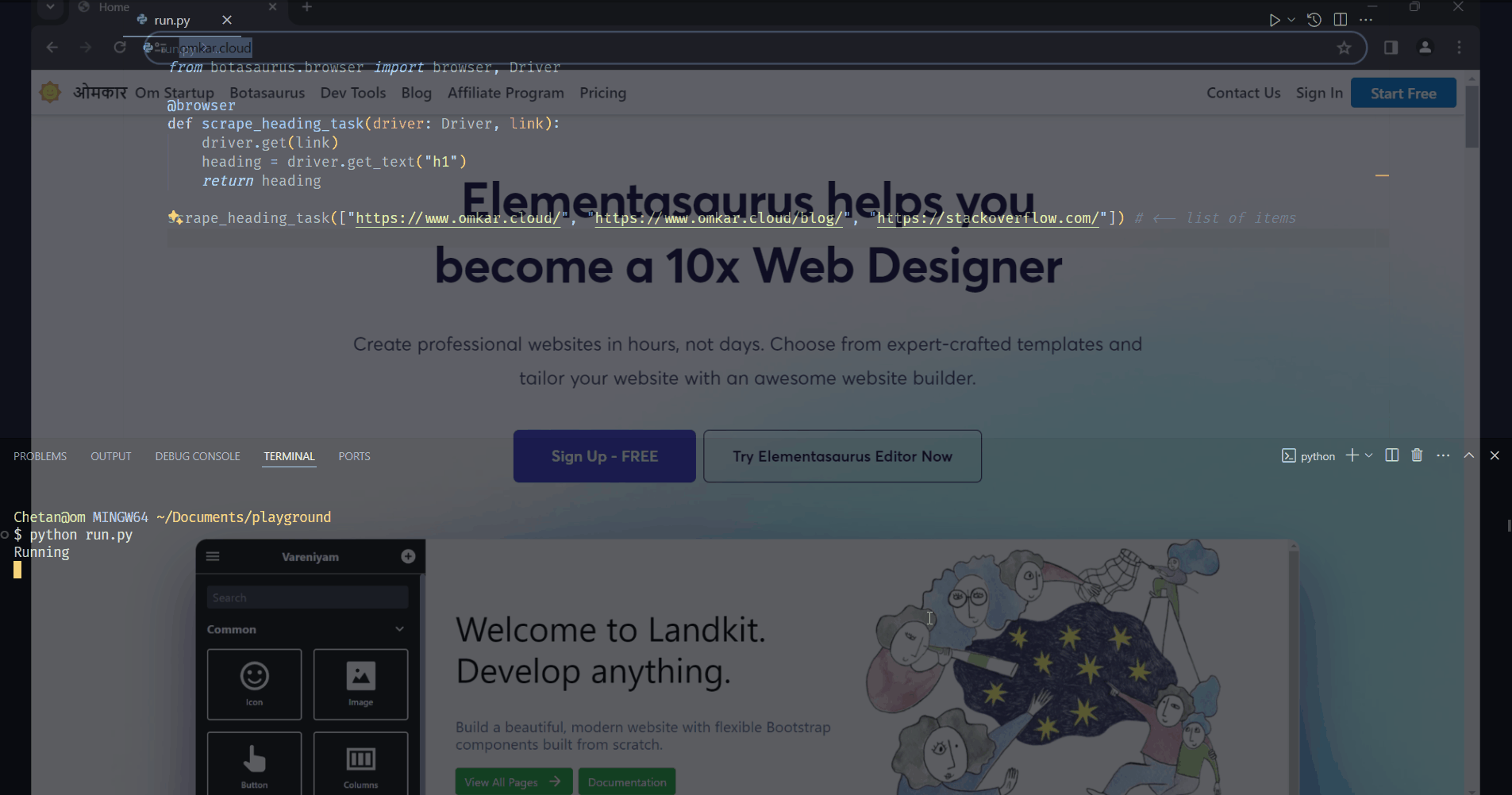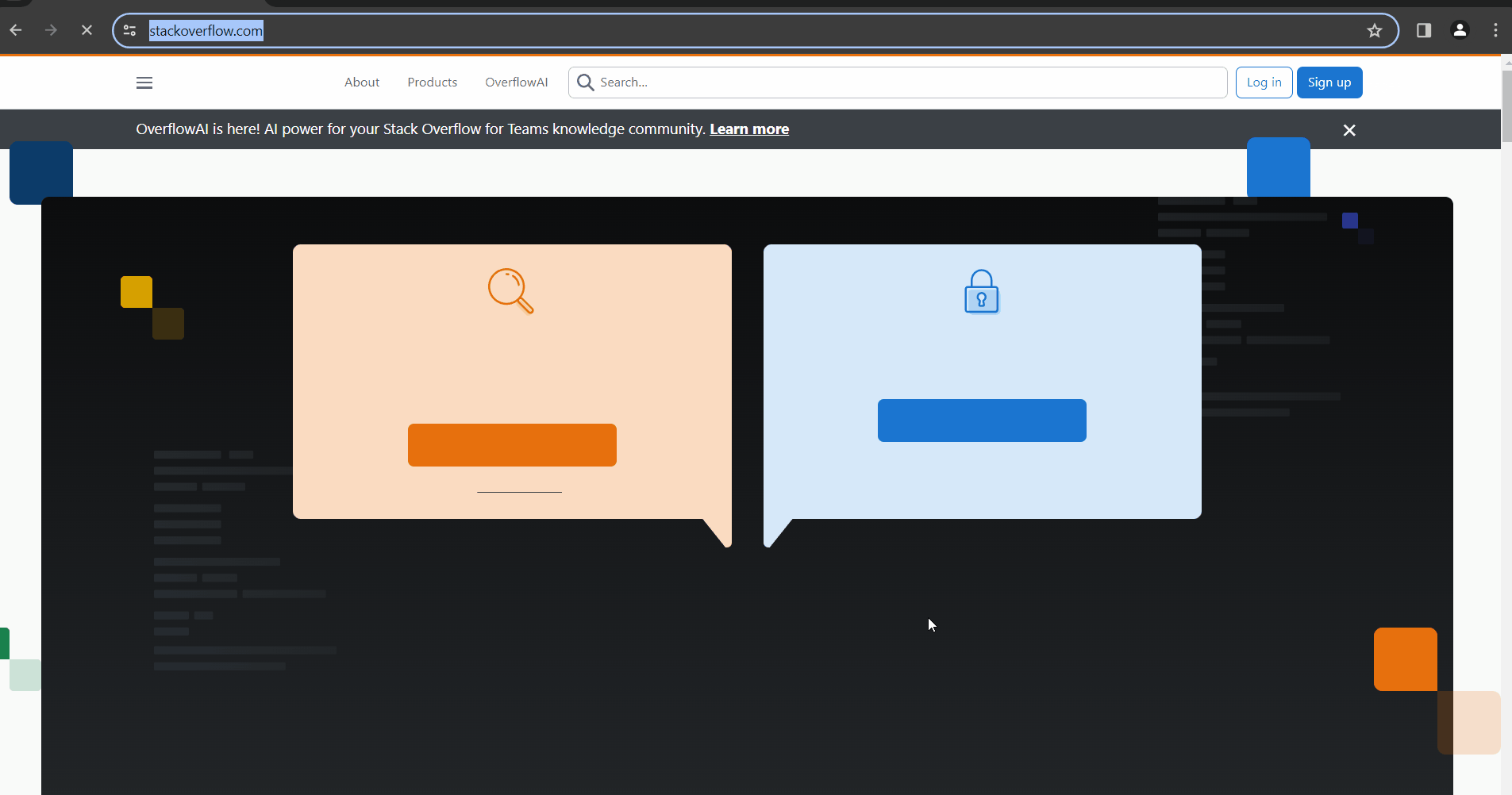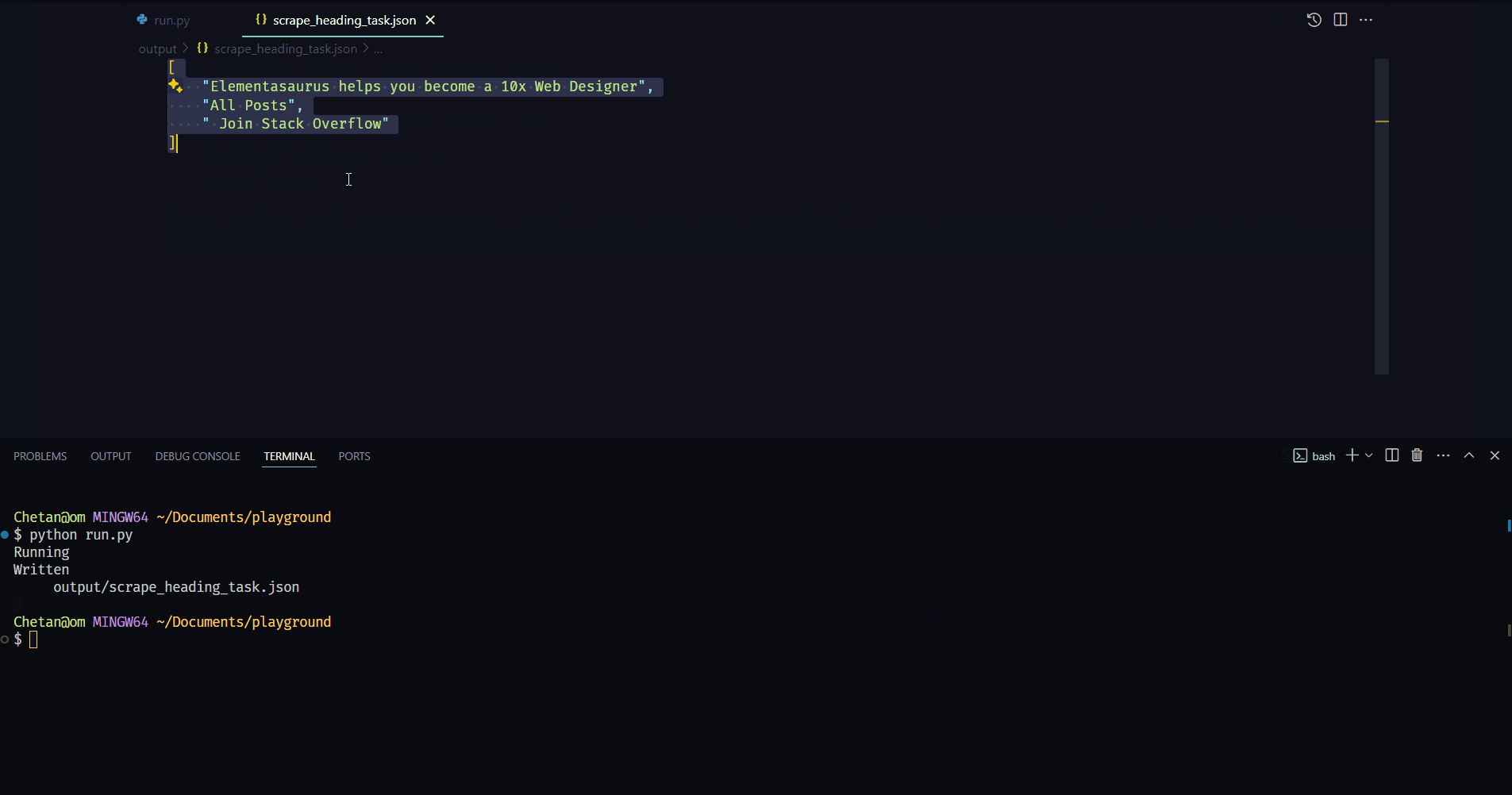
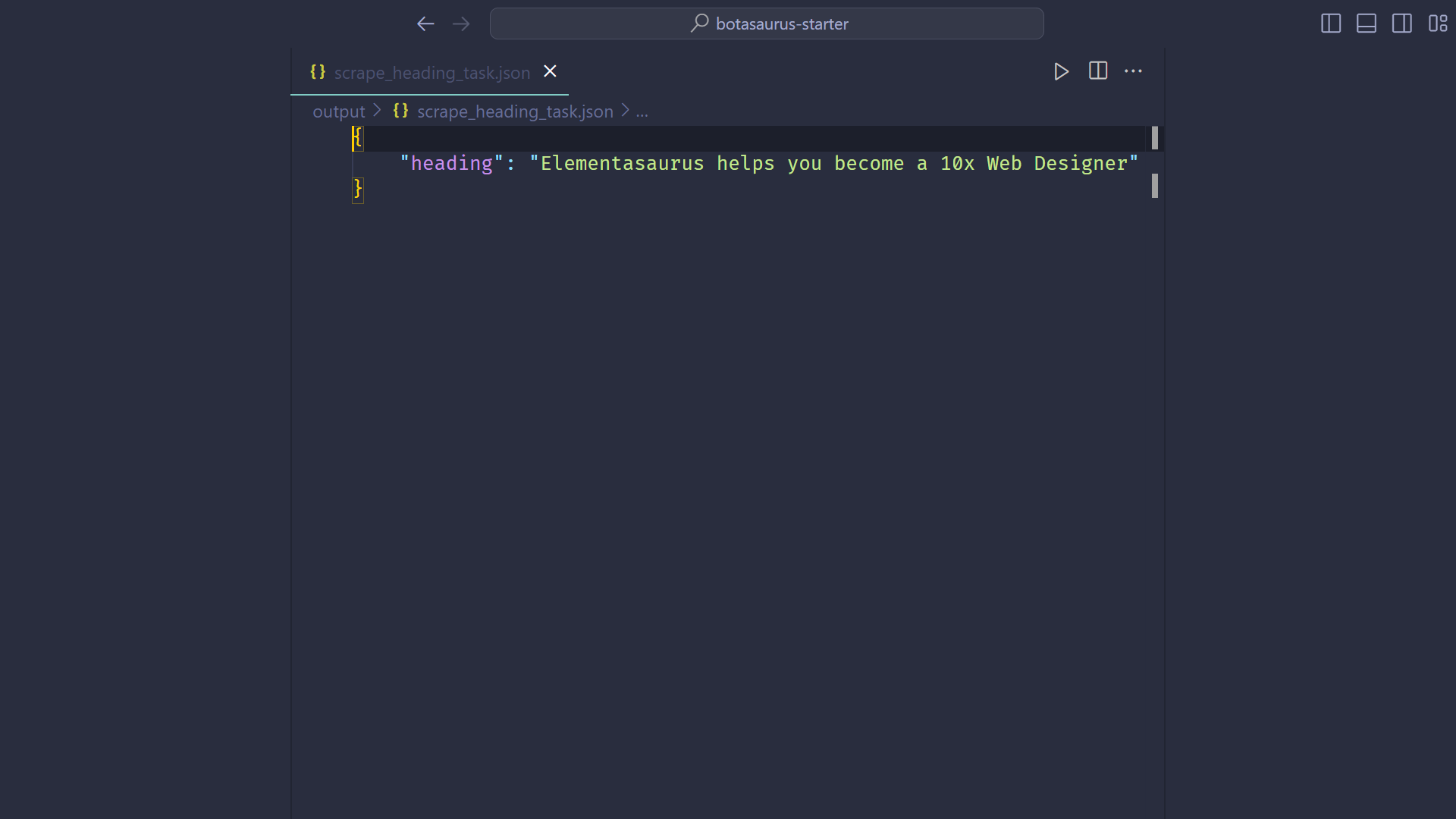
Botasaurus helps you in debugging by:
- Easily viewing the result of the scraping function, as it is saved in
output/{your_scraping_function_name}.json. Say goodbye to print statements.
- Bringing your attention to errors in browser mode with a beep sound and pausing the browser, allowing you to debug the error on the spot.
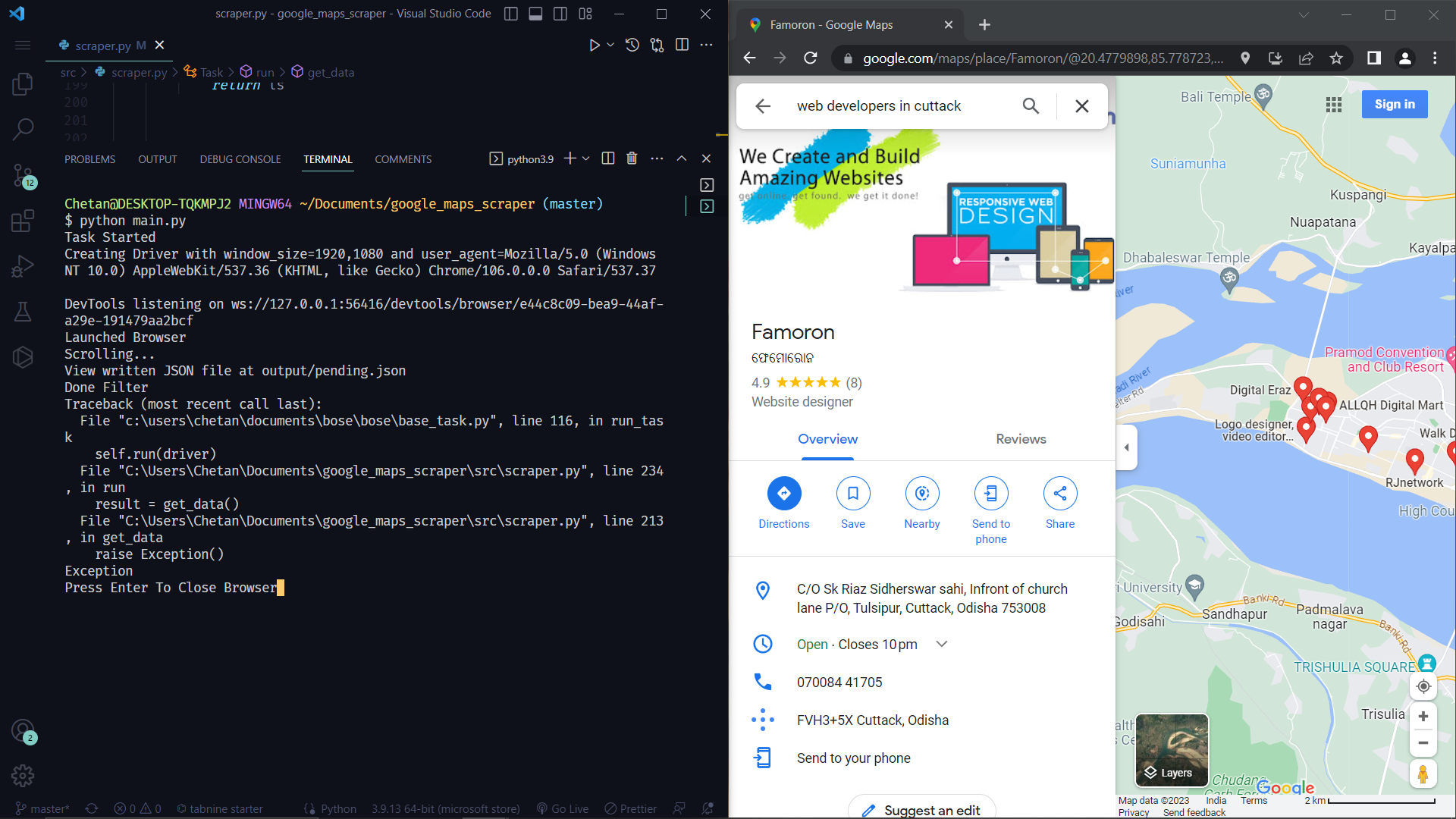
- Even if an exception is raised in headless mode, it will still open the website in your default browser, making it easier to debug code in a headless browser. (Isn't it cool?)
The Browser Decorator allows you to easily configure various aspects of the browser, such as:
- Blocking images and CSS
- Setting up proxies
- Specifying profiles
- Enabling headless mode
- Using Chrome extensions
- Selecting language
- Passing Arguments to Chrome
Blocking images is one of the most important configurations when scraping at scale. Blocking images can significantly:
- Speed up your web scraping tasks
- Reduce bandwidth usage
- And save money on proxies. (Best of All!)
For example, a page that originally takes 4 seconds and 12 MB to load might only take one second and 100 KB after blocking images and CSS.
To block images, use the block_images parameter:
@browser(
block_images=True,
)To block both images and CSS, use block_images_and_css:
@browser(
block_images_and_css=True,
) To use proxies, simply specify the proxy parameter:
@browser(
proxy="http://username:password@proxy-provider-domain:port"
)
def visit_ipinfo(driver: Driver, data):
driver.get("https://ipinfo.io/")
driver.prompt()
visit_ipinfo()You can also pass a list of proxies, and the proxy will be automatically rotated:
@browser(
proxy=[
"http://username:password@proxy-provider-domain:port",
"http://username2:password2@proxy-provider-domain:port"
]
)
def visit_ipinfo(driver: Driver, data):
driver.get("https://ipinfo.io/")
driver.prompt()
visit_ipinfo() Easily specify the Chrome profile using the profile option:
@browser(
profile="pikachu"
) However, each Chrome profile can become very large (e.g., 100 MB) and can eat up all your computer storage.
To solve this problem, use the tiny_profile option, which is a lightweight alternative to Chrome profiles.
When creating hundreds of Chrome profiles, it is highly recommended to use the tiny_profile option because:
- Creating 1000 Chrome profiles will take at least 100 GB, whereas 1000 tiny profiles will take up only 1 MB of storage, making tiny profiles easy to store and back up.
- Tiny profiles are cross-platform, meaning you can create profiles on a Linux server, copy the
./profilesfolder to a Windows PC, and easily run them.
Under the hood, tiny profiles persist cookies from visited websites, making them extremely lightweight (around 1 KB) while providing the same session persistence.
Here's how to use the tiny profile:
@browser(
tiny_profile=True,
profile="pikachu",
) Enable headless mode with headless=True:
@browser(
headless=True
) Note that using headless mode makes the browser much easier to identify by services like Cloudflare and Datadome. So, use headless mode only when scraping websites that don't use such services.
Botasaurus allows the use of ANY Chrome Extension with just 1 line of code. The example below shows how to use the AdBlocker Chrome Extension:
from botasaurus.browser import browser, Driver
from chrome_extension_python import Extension
@browser(
extensions=[
Extension(
"https://chromewebstore.google.com/detail/adblock-%E2%80%94-best-ad-blocker/gighmmpiobklfepjocnamgkkbiglidom"
)
],
)
def scrape_while_blocking_ads(driver: Driver, data):
driver.prompt()
scrape_while_blocking_ads()In some cases, an extension may require additional configuration, such as API keys or credentials. For such scenarios, you can create a custom extension. Learn more about creating and configuring custom extensions here.
Specify the language using the lang option:
from botasaurus.lang import Lang
@browser(
lang=Lang.Hindi,
)To make the browser really humane, Botasaurus does not change browser fingerprints by default, because using fingerprints makes the browser easily identifiable by running CSS tests to find mismatches between the provided user agent and the actual user agent.
However, if you need fingerprinting, use the user_agent and window_size options:
from botasaurus.browser import browser, Driver
from botasaurus.user_agent import UserAgent
from botasaurus.window_size import WindowSize
@browser(
user_agent=UserAgent.RANDOM,
window_size=WindowSize.RANDOM,
)
def visit_whatsmyua(driver: Driver, data):
driver.get("https://www.whatsmyua.info/")
driver.prompt()
visit_whatsmyua()When working with profiles, you want the fingerprints to remain consistent. You don't want the user's user agent to be Chrome 106 on the first visit and then become Chrome 102 on the second visit.
So, when using profiles, use the HASHED option to generate a consistent user agent and window size based on the profile's hash:
from botasaurus.browser import browser, Driver
from botasaurus.user_agent import UserAgent
from botasaurus.window_size import WindowSize
@browser(
profile="pikachu",
user_agent=UserAgent.HASHED,
window_size=WindowSize.HASHED,
)
def visit_whatsmyua(driver: Driver, data):
driver.get("https://www.whatsmyua.info/")
driver.prompt()
visit_whatsmyua()
# Everytime Same UserAgent and WindowSize
visit_whatsmyua()To pass arguments to Chrome, use the add_arguments option:
@browser(
add_arguments=['--headless=new'],
)To dynamically generate arguments based on the data parameter, pass a function:
def get_arguments(data):
return ['--headless=new']
@browser(
add_arguments=get_arguments,
)By default, Botasaurus waits for all page resources (DOM, JavaScript, CSS, images, etc.) to load before calling your scraping function with the driver.
However, sometimes the DOM is ready, but JavaScript, images, etc., take forever to load.
In such cases, you can set wait_for_complete_page_load to False to interact with the DOM as soon as the HTML is parsed and the DOM is ready:
@browser(
wait_for_complete_page_load=False,
)Consider the following example:
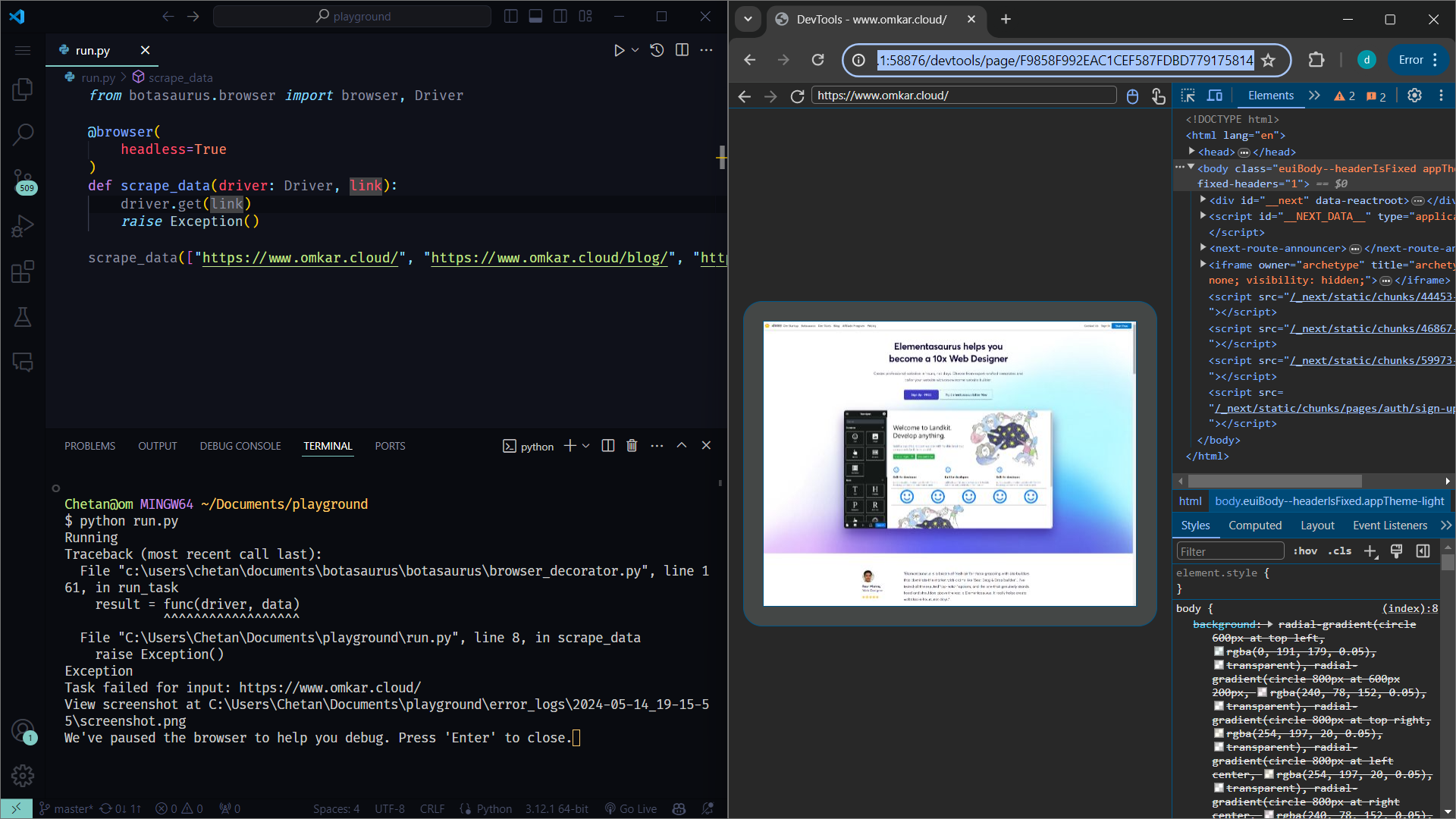
from botasaurus.browser import browser, Driver
@browser
def scrape_data(driver: Driver, link):
driver.get(link)
scrape_data(["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])If you run this code, the browser will be recreated on each page visit, which is inefficient.
To solve this problem, use the reuse_driver option which is great for cases like:
- Scraping a large number of links and reusing the same browser instance for all page visits.
- Running your scraper in a cloud server to scrape data on demand, without recreating Chrome on each request.
Here's how to use reuse_driver which will reuse the same Chrome instance for visiting each link.
from botasaurus.browser import browser, Driver
@browser(
reuse_driver=True
)
def scrape_data(driver: Driver, link):
driver.get(link)
scrape_data(["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])Result
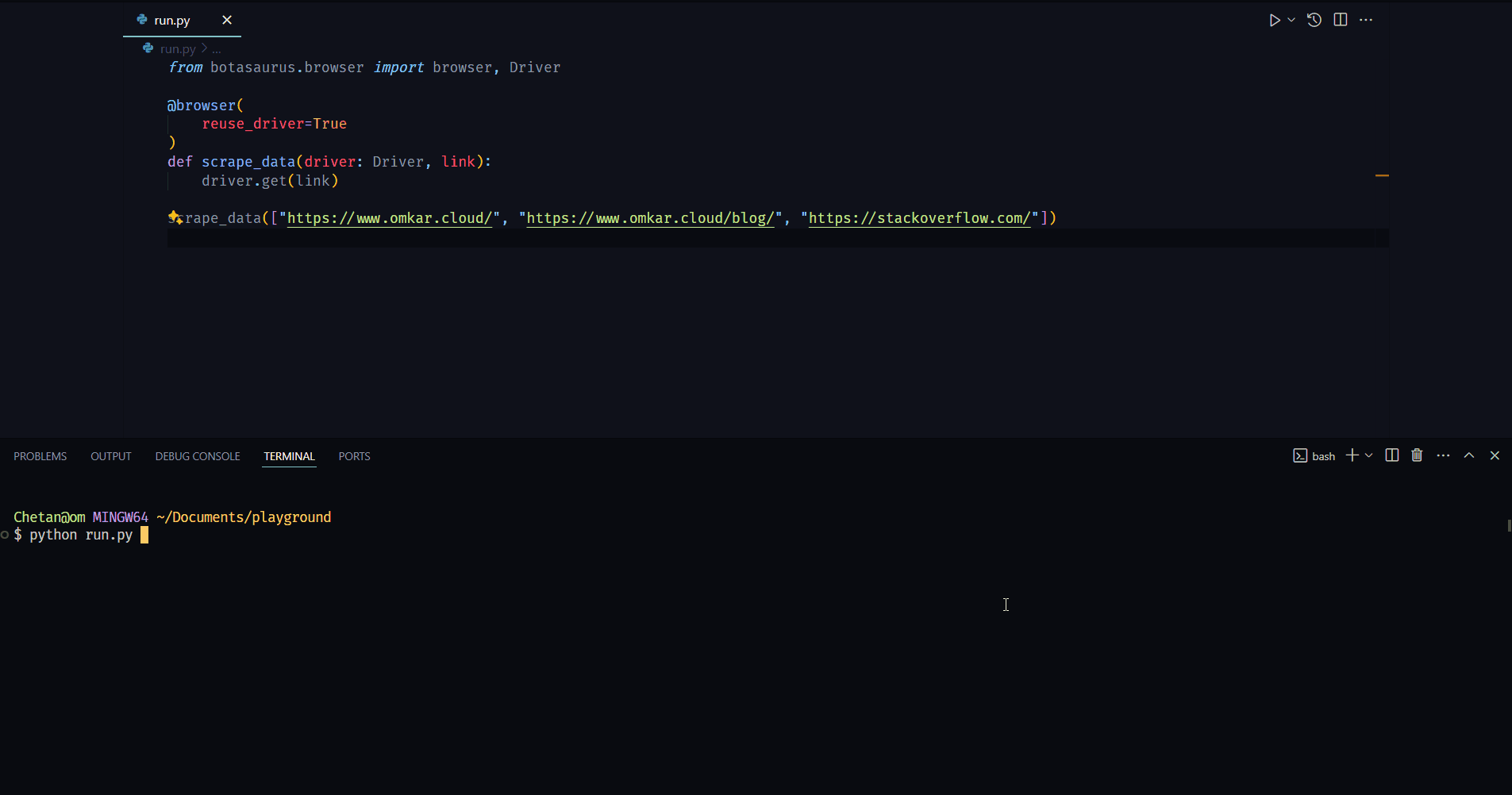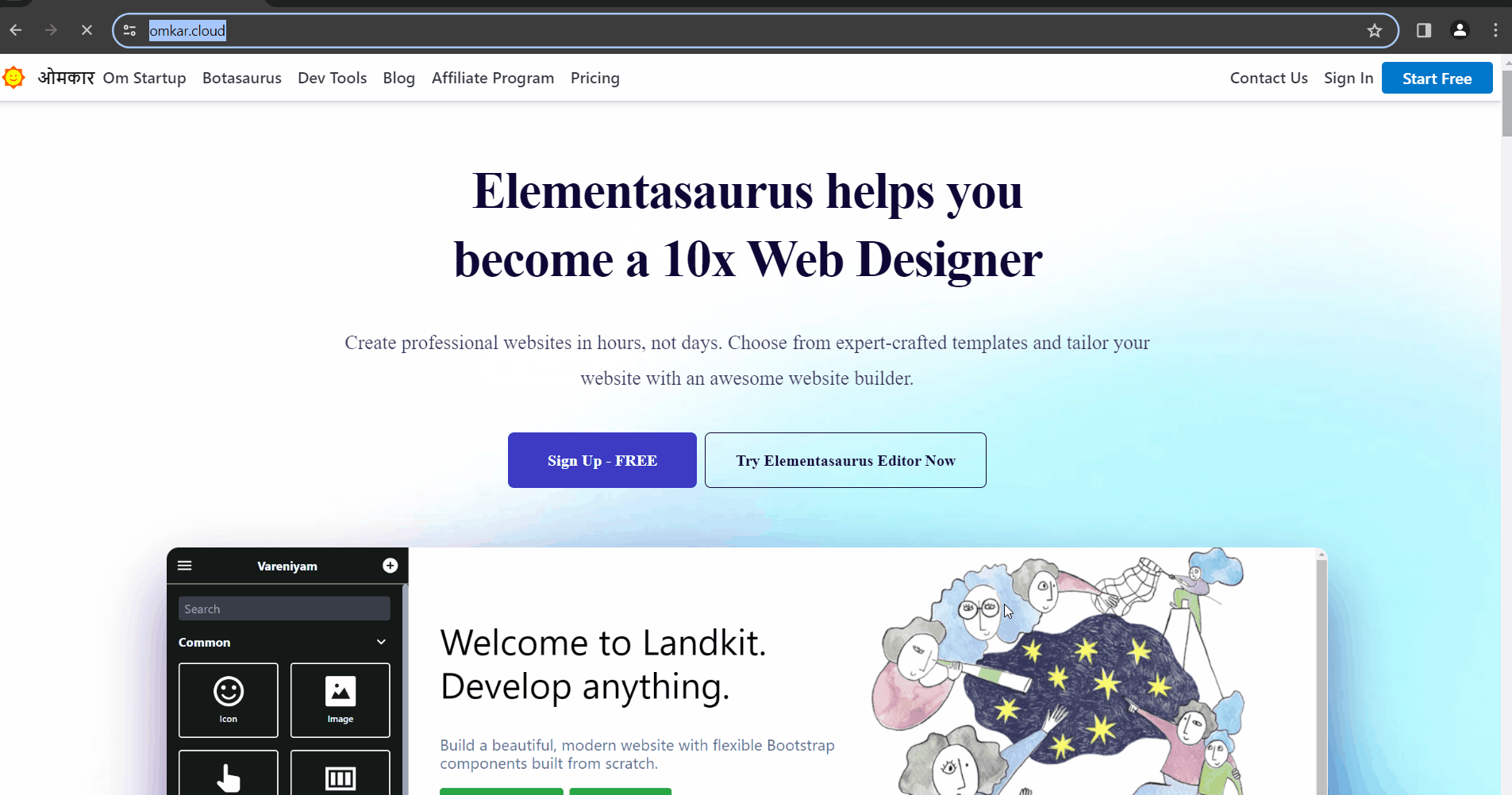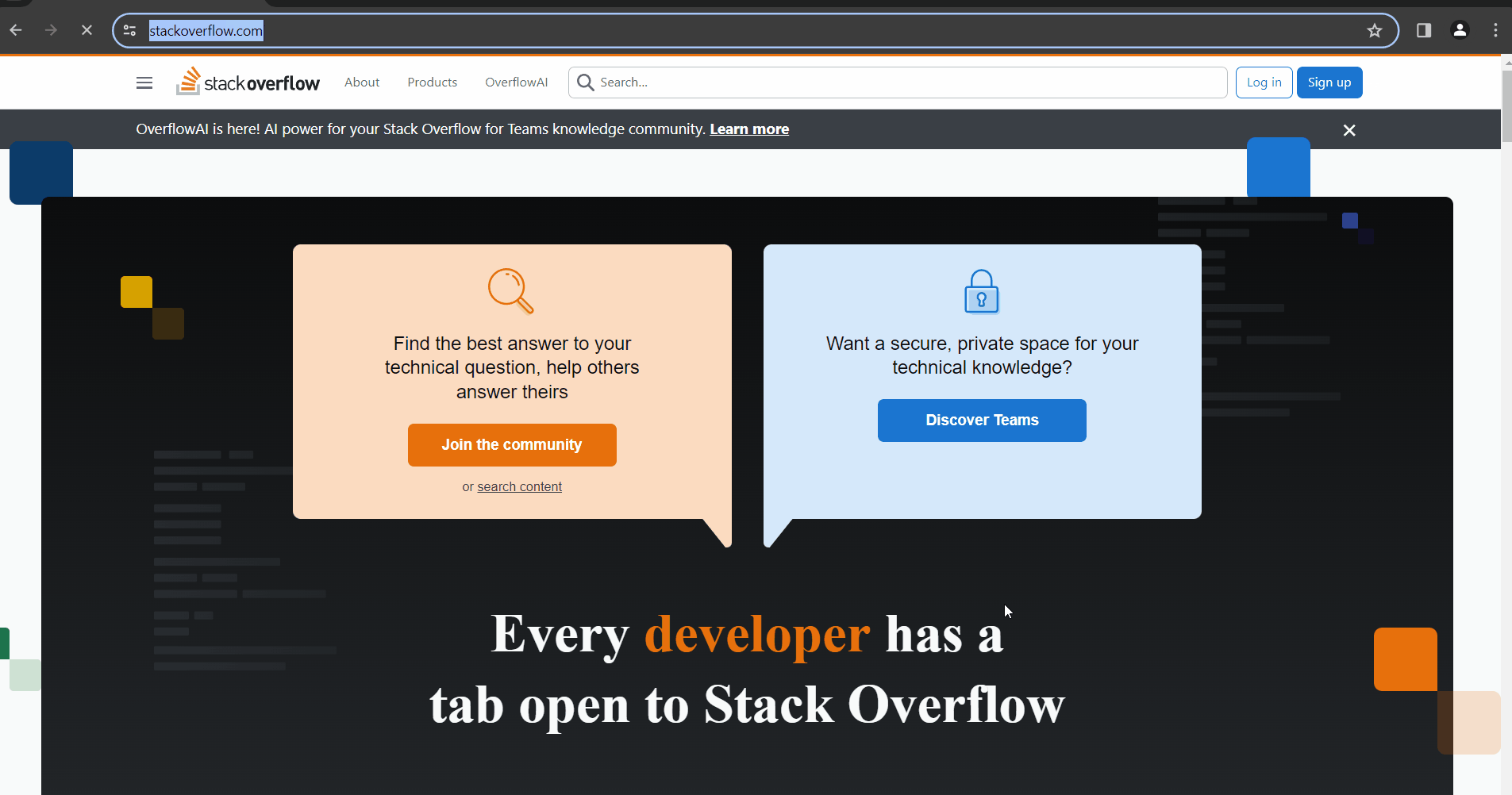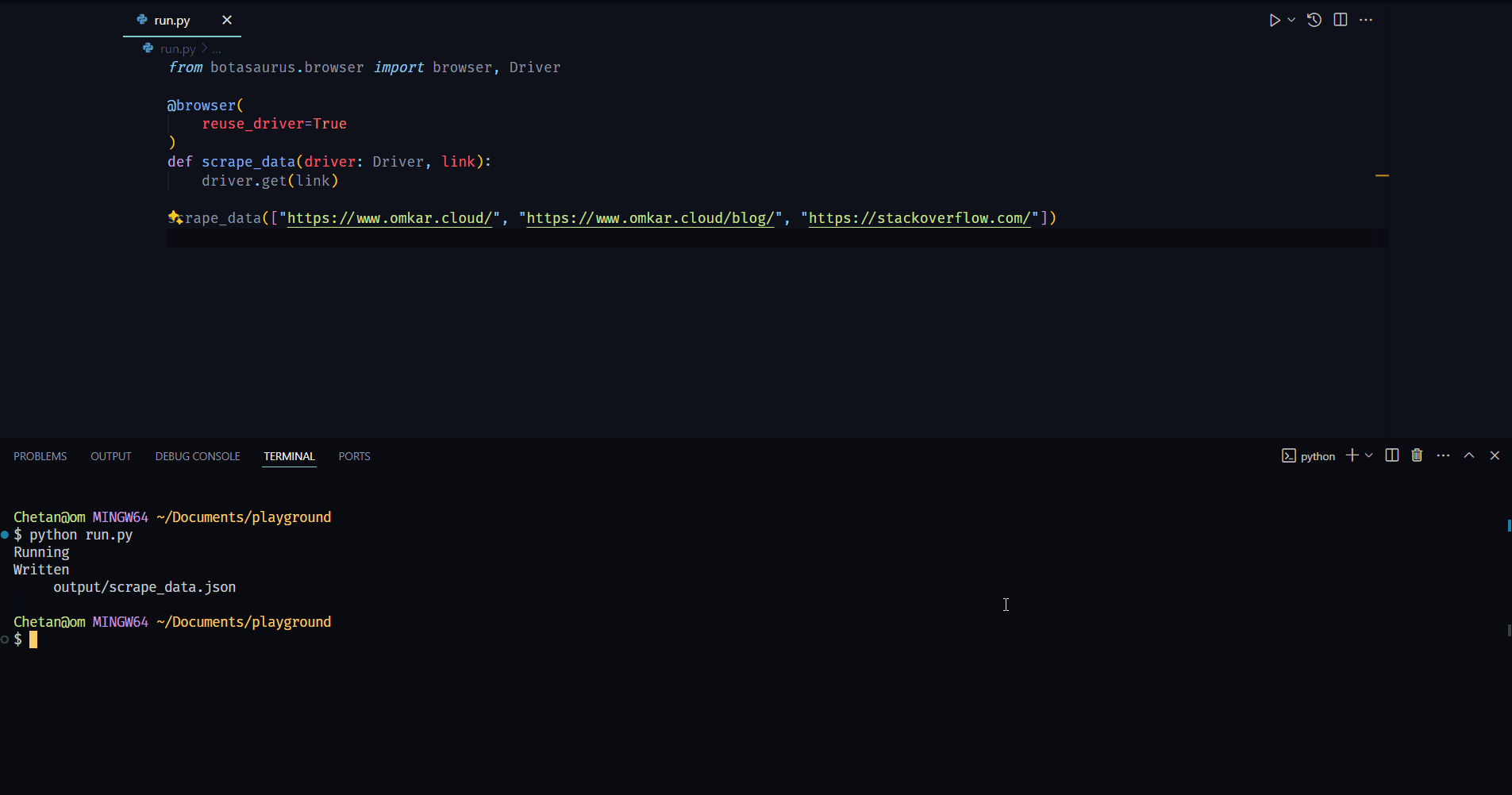
Also, by default, whenever the program ends or is canceled, Botasaurus smartly closes any open Chrome instances, leaving no instances running in the background.
In rare cases, you may want to explicitly close the Chrome instance. For such scenarios, you can use the .close() method on the scraping function:
scrape_data.close()This will close any Chrome instances that remain open after the scraping function ends.
Recently, we had a project requiring access to around 100,000 pages from a well-protected website, necessitating the use of Residential Proxies.
Even after blocking images, we still required 250GB of proxy bandwidth, costing approximately $1050 (at $4.2 per GB with IP Royal).
This was beyond our budget :(
To solve this, we implemented a smart strategy:
- We first visited the website normally.
- We then made requests for subsequent pages using the browser's
fetchAPI.
Since we were only requesting the HTML, which was well compressed by the browser, we reduced our proxy bandwidth needs to just 5GB, costing only $30.
This resulted in savings of around $1000!
Here's an example of how you can do something similar in Botasaurus:
from botasaurus.browser import browser, Driver
from botasaurus.soupify import soupify
@browser(
reuse_driver=True, # Reuse the browser
max_retry=5, # Retry up to 5 times on failure
)
def scrape_data(driver: Driver, link):
# If the browser is newly opened, first visit the link
if driver.config.is_new:
driver.google_get(link, bypass_cloudflare=True)
# Make requests using the browser fetch API
response = driver.requests.get(link)
response.raise_for_status() # Ensure the request was successful
html = response.text
# Parse the HTML to extract the desired data
heading = soupify(html).select_one('.product-head__title [itemprop="name"]').get_text()
return {
"heading": heading,
}
# List of URLs to scrape
links = [
"https://www.g2.com/products/stack-overflow-for-teams/reviews",
"https://www.g2.com/products/jenkins/reviews",
"https://www.g2.com/products/docker-inc-docker/reviews",
]
# Execute the scraping function for the list of links
scrape_data(links)Note:
-
Dealing with 429 (Too Many Requests) Errors
If you encounter a 429 error, add a delay before making another request. Most websites using Nginx, setting a rate limit of 1 request per second. To respect this limit, a delay of 1.13 seconds is recommended.
driver.sleep(1.13) # Delay to respect the rate limit response = driver.requests.get(link)
-
Handling 400 Errors Due to Large Cookies
If you encounter a 400 error with a "cookie too large" message, delete the cookies and retry the request.
response = driver.requests.get(link) if response.status_code == 400: driver.delete_cookies() # Delete cookies to resolve the error driver.short_random_sleep() # Short delay before retrying response = driver.requests.get(link)
-
You can also use
driver.requests.get_mank(links)to make multiple requests in parallel, which is faster than making them sequentially.
How to Configure the Browser's Chrome Profile, Language, and Proxy Dynamically Based on Data Parameters?
The decorators in Botasaurus are really flexible, allowing you to pass a function that can derive the browser configuration based on the data item parameter. This is particularly useful when working with multiple Chrome profiles.
You can dynamically configure the browser's Chrome profile and proxy using decorators in two ways:
-
Using functions to extract configuration values from data:
- Define functions to extract the desired configuration values from the
dataparameter. - Pass these functions as arguments to the
@browserdecorator.
Example:
from botasaurus.browser import browser, Driver def get_profile(data): return data["profile"] def get_proxy(data): return data["proxy"] @browser(profile=get_profile, proxy=get_proxy) def scrape_heading_task(driver: Driver, data): profile, proxy = driver.config.profile, driver.config.proxy print(profile, proxy) return profile, proxy data = [ {"profile": "pikachu", "proxy": "http://142.250.77.228:8000"}, {"profile": "greyninja", "proxy": "http://142.250.77.229:8000"}, ] scrape_heading_task(data)
- Define functions to extract the desired configuration values from the
-
Directly passing configuration values when calling the decorated function:
- Pass the profile and proxy values directly as arguments to the decorated function when calling it.
Example:
from botasaurus.browser import browser, Driver @browser def scrape_heading_task(driver: Driver, data): profile, proxy = driver.config.profile, driver.config.proxy print(profile, proxy) return profile, proxy scrape_heading_task( profile='pikachu', # Directly pass the profile proxy="http://142.250.77.228:8000", # Directly pass the proxy )
PS: Most Botasaurus decorators allow passing functions to derive configurations from data parameters. Check the decorator's argument type hint to see if it supports this functionality.
To store data related to the active profile, use driver.profile. Here's an example:
from botasaurus.browser import browser, Driver
def get_profile(data):
return data["profile"]
@browser(profile=get_profile)
def run_profile_task(driver: Driver, data):
# Set profile data
driver.profile = {
'name': 'Amit Sharma',
'age': 30
}
# Update the name in the profile
driver.profile['name'] = 'Amit Verma'
# Delete the age from the profile
del driver.profile['age']
# Print the updated profile
print(driver.profile) # Output: {'name': 'Amit Verma'}
# Delete the entire profile
driver.profile = None
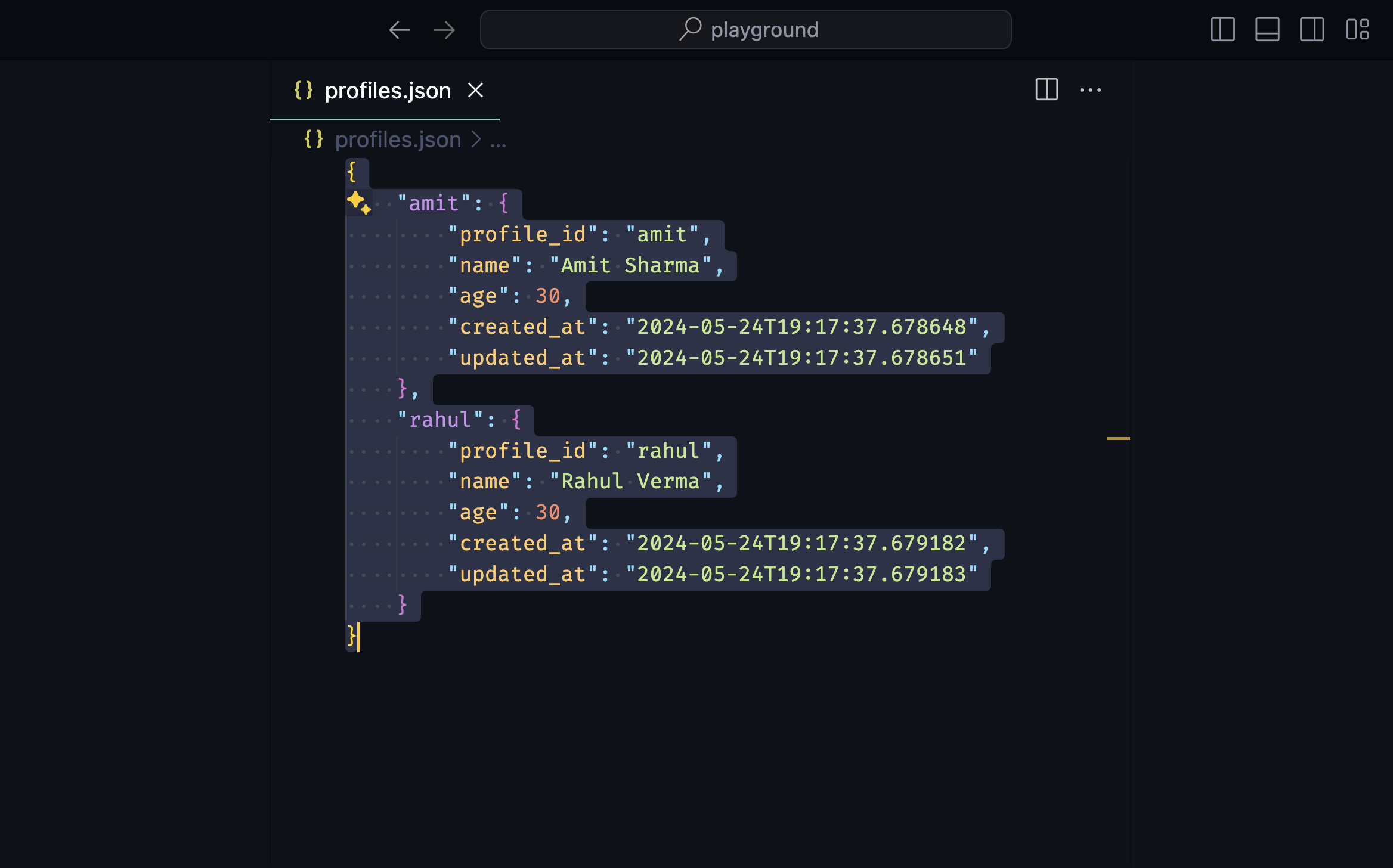
run_profile_task([{"profile": "amit"}])For managing all profiles, use the Profiles utility. Here's an example:
from botasaurus.profiles import Profiles
# Set profiles
Profiles.set_profile('amit', {'name': 'Amit Sharma', 'age': 30})
Profiles.set_profile('rahul', {'name': 'Rahul Verma', 'age': 30})
# Get a profile
profile = Profiles.get_profile('amit')
print(profile) # Output: {'name': 'Amit Sharma', 'age': 30}
# Get all profiles
all_profiles = Profiles.get_profiles()
print(all_profiles) # Output: [{'name': 'Amit Sharma', 'age': 30}, {'name': 'Rahul Verma', 'age': 30}]
# Get all profiles in random order
random_profiles = Profiles.get_profiles(random=True)
print(random_profiles) # Output: [{'name': 'Rahul Verma', 'age': 30}, {'name': 'Amit Sharma', 'age': 30}] in random order
# Delete a profile
Profiles.delete_profile('amit')Note: All profile data is stored in the profiles.json file in the current working directory.
Botasaurus Driver provides several handy methods for web automation tasks such as:
-
Visiting URLs:
driver.get("https://www.example.com") driver.google_get("https://www.example.com") # Use Google as the referer [Recommended] driver.get_via("https://www.example.com", referer="https://duckduckgo.com/") # Use custom referer driver.get_via_this_page("https://www.example.com") # Use current page as referer
-
For finding elements:
from botasaurus.browser import Wait search_results = driver.select(".search-results", wait=Wait.SHORT) # Wait for up to 4 seconds for the element to be present, return None if not found all_links = driver.select_all("a") # Get all elements matching the selector search_results = driver.wait_for_element(".search-results", wait=Wait.LONG) # Wait for up to 8 seconds for the element to be present, raise exception if not found hello_mom = driver.get_element_with_exact_text("Hello Mom", wait=Wait.VERY_LONG) # Wait for up to 16 seconds for an element having the exact text "Hello Mom"
-
Interact with elements:
driver.type("input[name='username']", "john_doe") # Type into an input field driver.click("button.submit") # Clicks an element element = driver.select("button.submit") element.click() # Click on an element
-
Retrieve element properties:
header_text = driver.get_text("h1") # Get text content error_message = driver.get_element_containing_text("Error: Invalid input") image_url = driver.select("img.logo").get_attribute("src") # Get attribute value
-
Work with parent-child elements:
parent_element = driver.select(".parent") child_element = parent_element.select(".child") child_element.click() # Click child element
-
Execute JavaScript:
result = driver.run_js("return document.title") text_content = element.run_js("(el) => el.textContent")
-
Working with iframes:
driver.get("https://www.freecodecamp.org/news/using-entity-framework-core-with-mongodb/") iframe = driver.get_iframe_by_link("www.youtube.com/embed") # OR following works as well # iframe = driver.select(".embed-wrapper iframe") freecodecamp_youtube_subscribers_count = iframe.select(".ytp-title-expanded-subtitle").text
-
Execute CDP Command:
from botasaurus.browser import browser, Driver, cdp driver.run_cdp_command(cdp.page.navigate(url='https://stackoverflow.com/'))
-
Miscellaneous:
form.type("input[name='password']", "secret_password") # Type into a form field container.is_element_present(".button") # Check element presence page_html = driver.page_html # Current page HTML driver.select(".footer").scroll_into_view() # Scroll element into view driver.close() # Close the browser
To pause the scraper and wait for user input before proceeding, use driver.prompt():
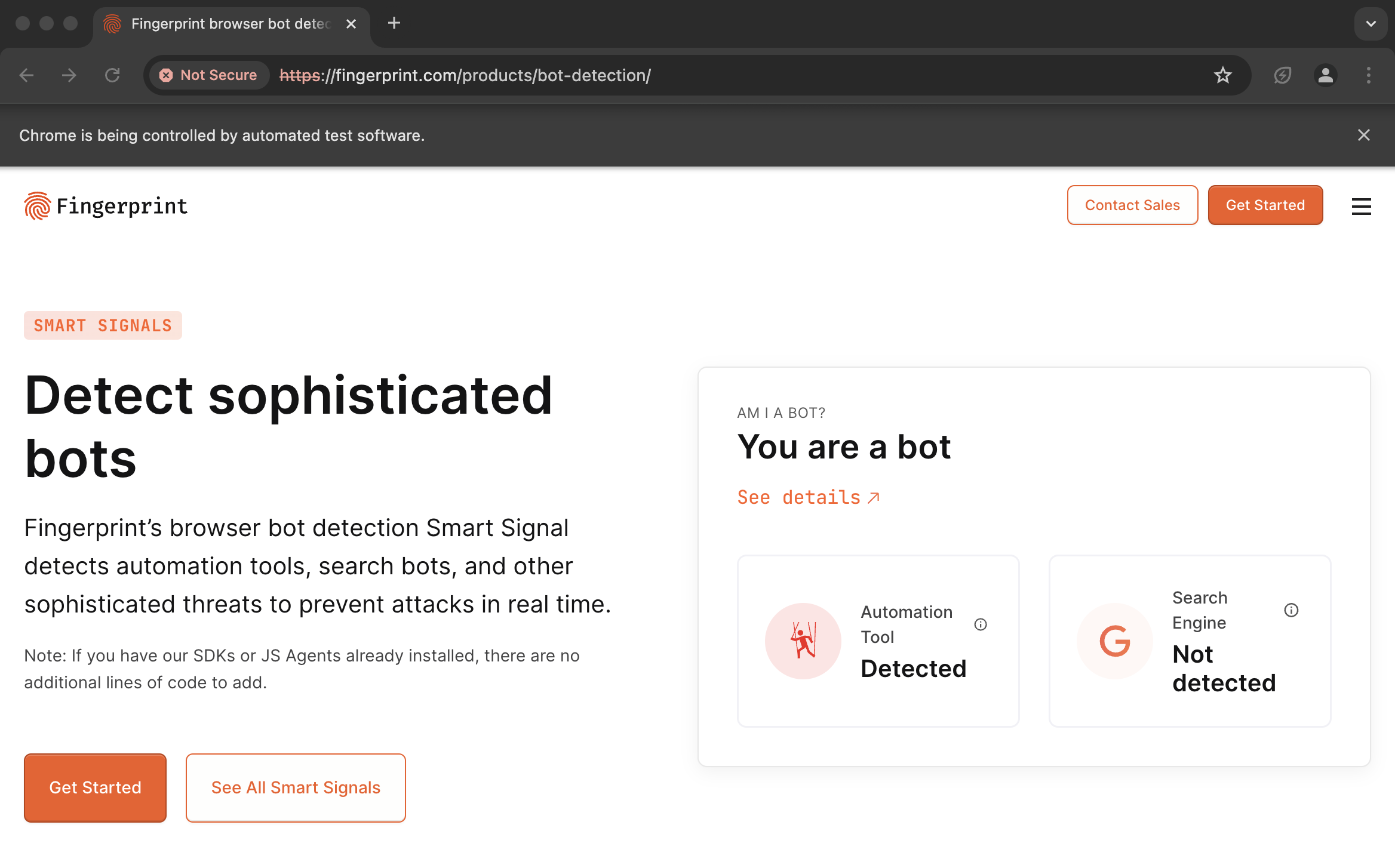
driver.prompt()Proxy providers like BrightData, IPRoyal, and others typically provide authenticated proxies in the format "http://username:password@proxy-provider-domain:port". For example, "http://greyninja:awesomepassword@geo.iproyal.com:12321".
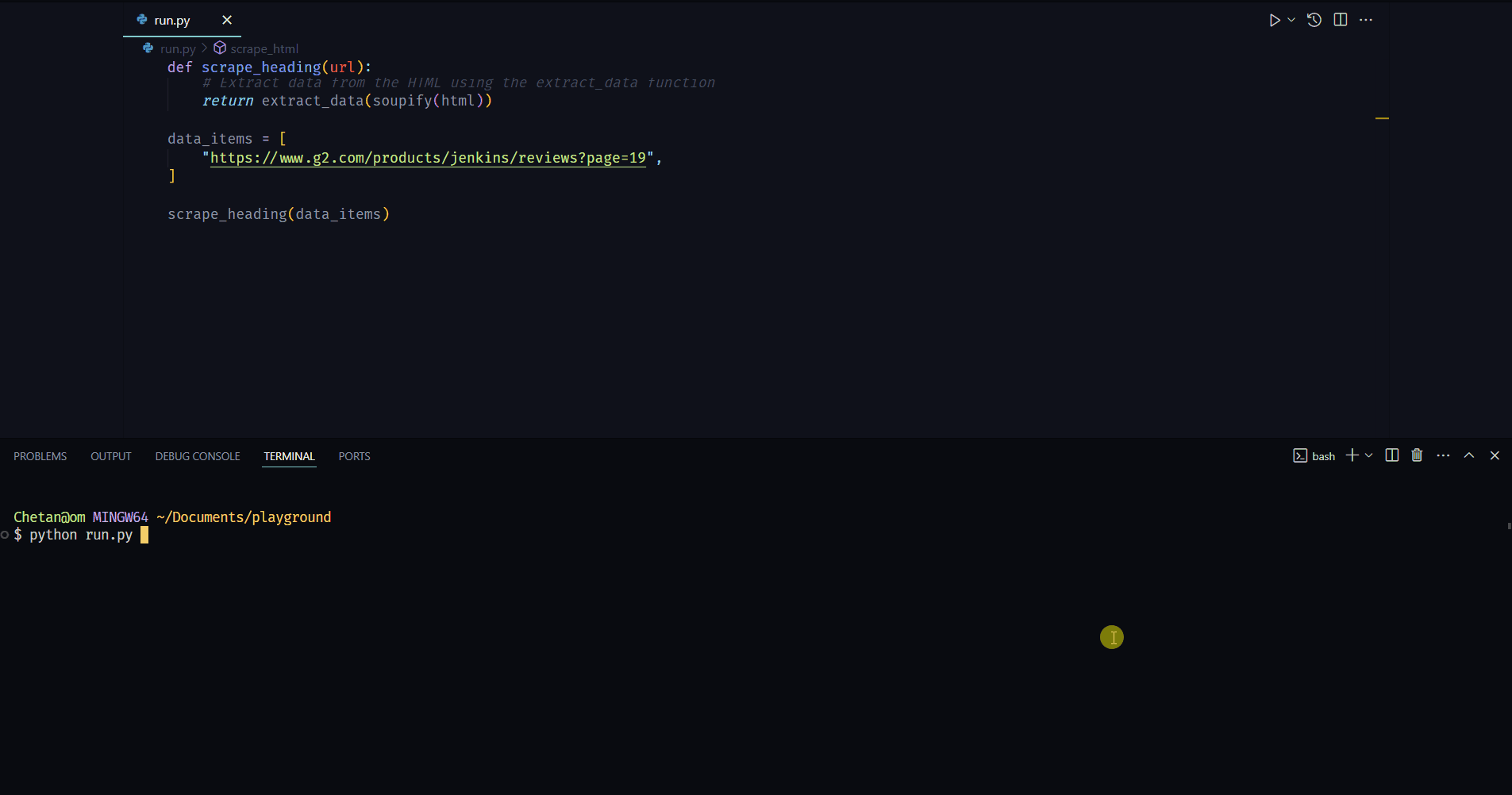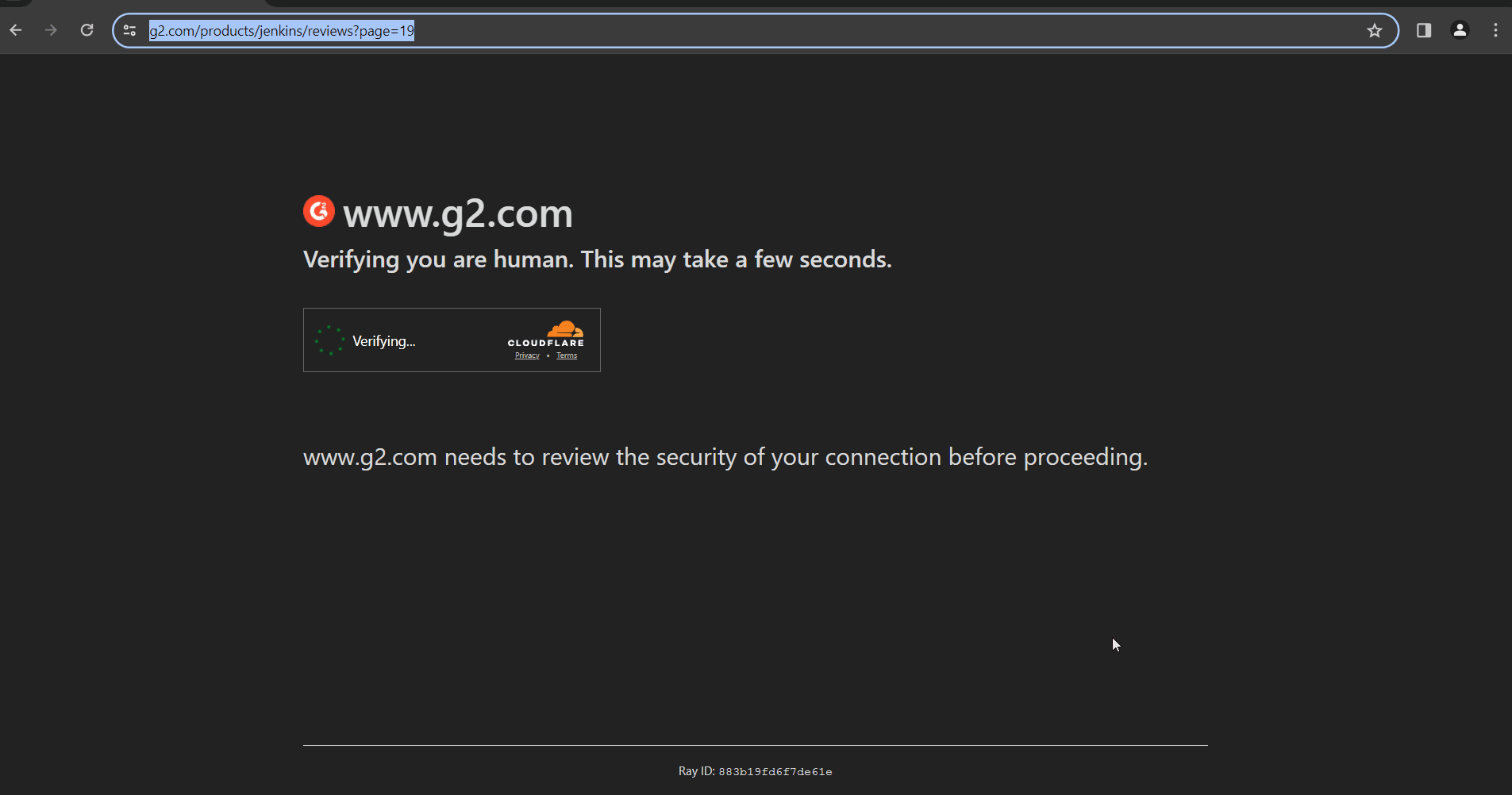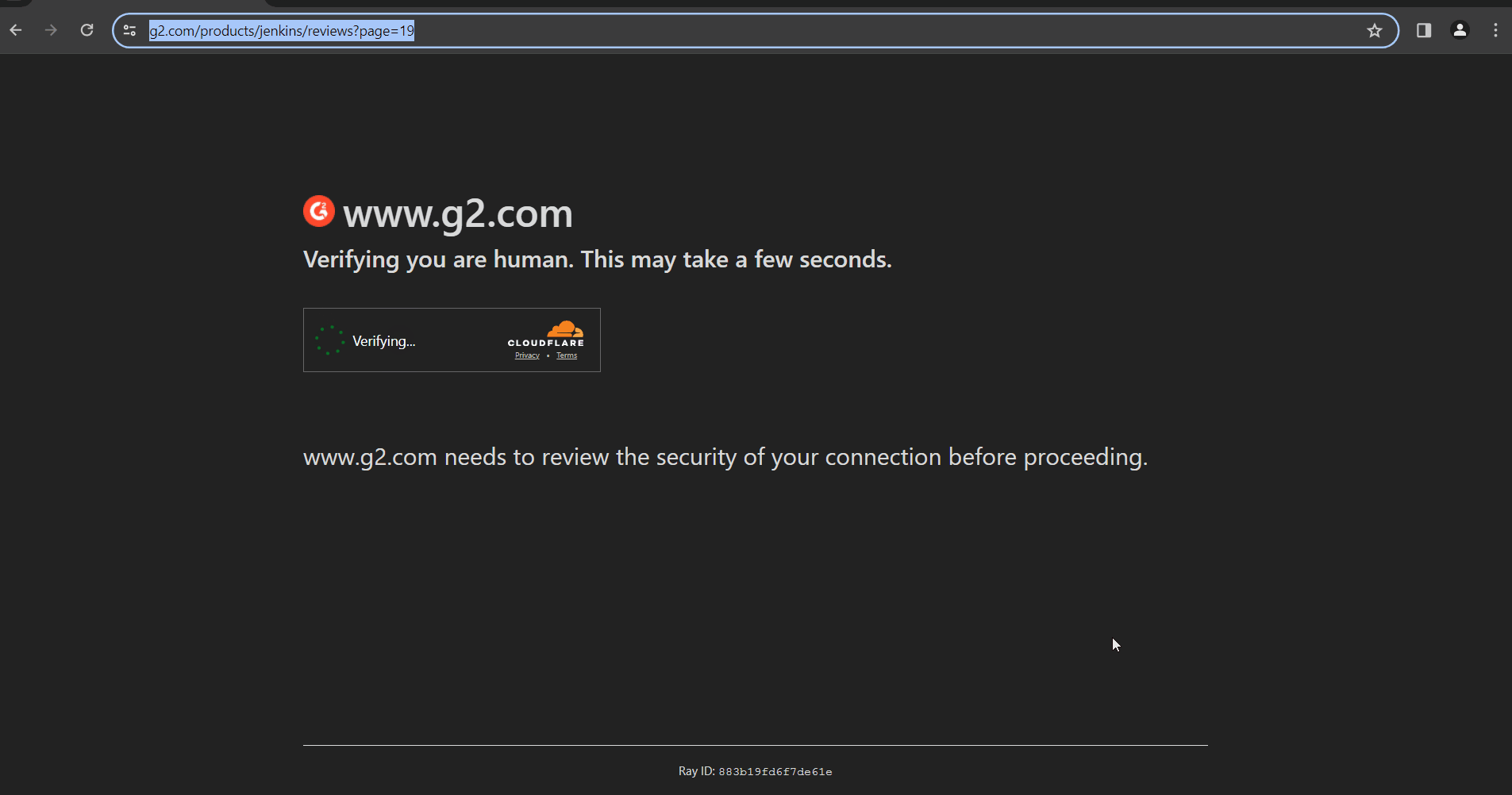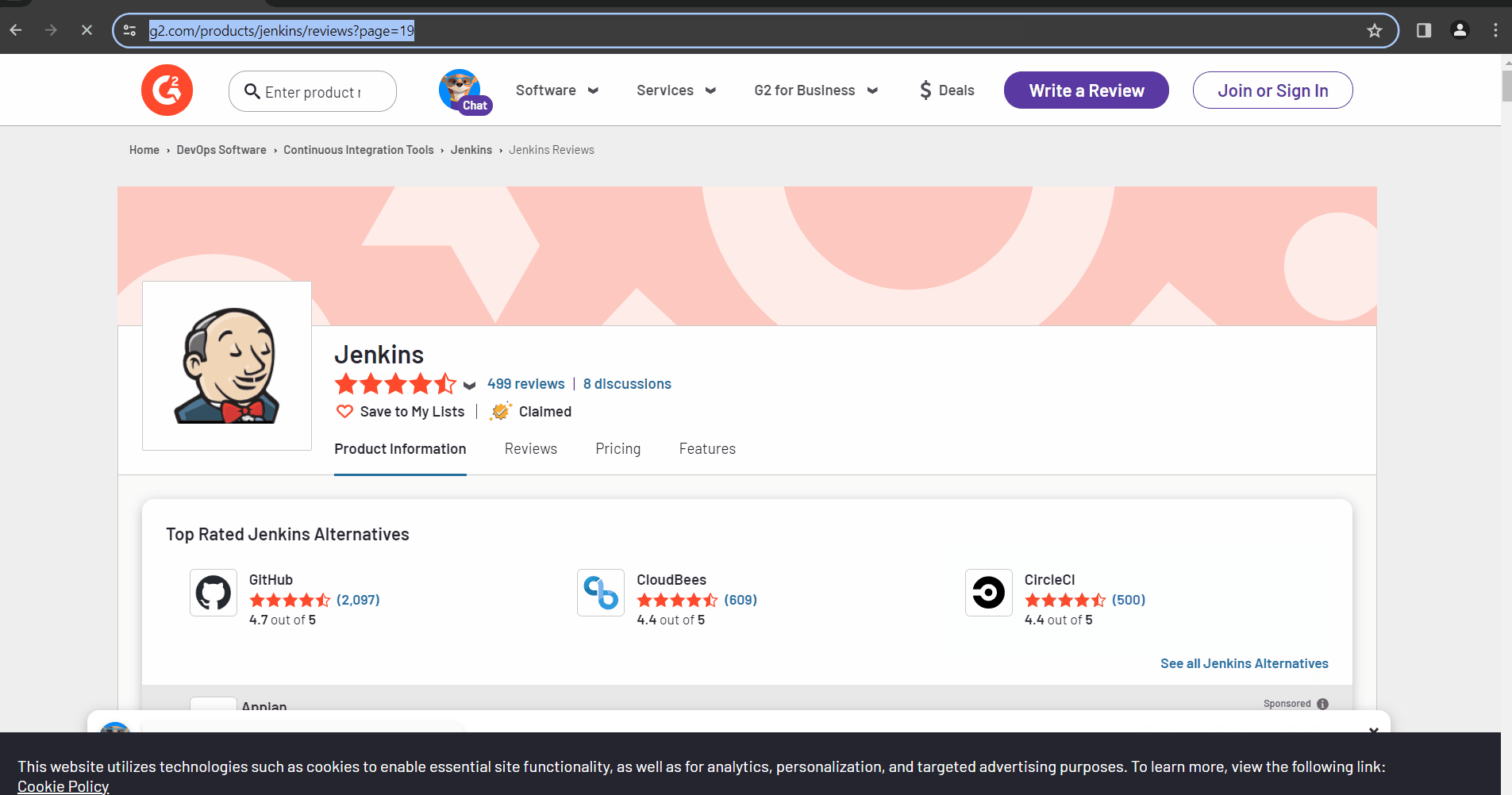
However, if you use an authenticated proxy with a library like seleniumwire to visit a website using Cloudflare like G2.com, you are GUARANTEED to be identified because you are using a non-SSL connection.
To verify this, run the following code:
First, install the necessary packages:
python -m pip install selenium_wire chromedriver_autoinstaller_fixThen, execute this Python script:
from seleniumwire import webdriver
from chromedriver_autoinstaller_fix import install
# Define the proxy
proxy_options = {
'proxy': {
'http': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
'https': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
}
}
# Install and set up the driver
driver_path = install()
driver = webdriver.Chrome(driver_path, seleniumwire_options=proxy_options)
# Visit the desired URL
link = 'https://www.g2.com/products/github/reviews'
driver.get("https://www.google.com/")
driver.execute_script(f'window.location.href = "{link}"')
# Prompt for user input
input("Press Enter to exit...")
# Clean up
driver.quit()You will SURELY be identified:
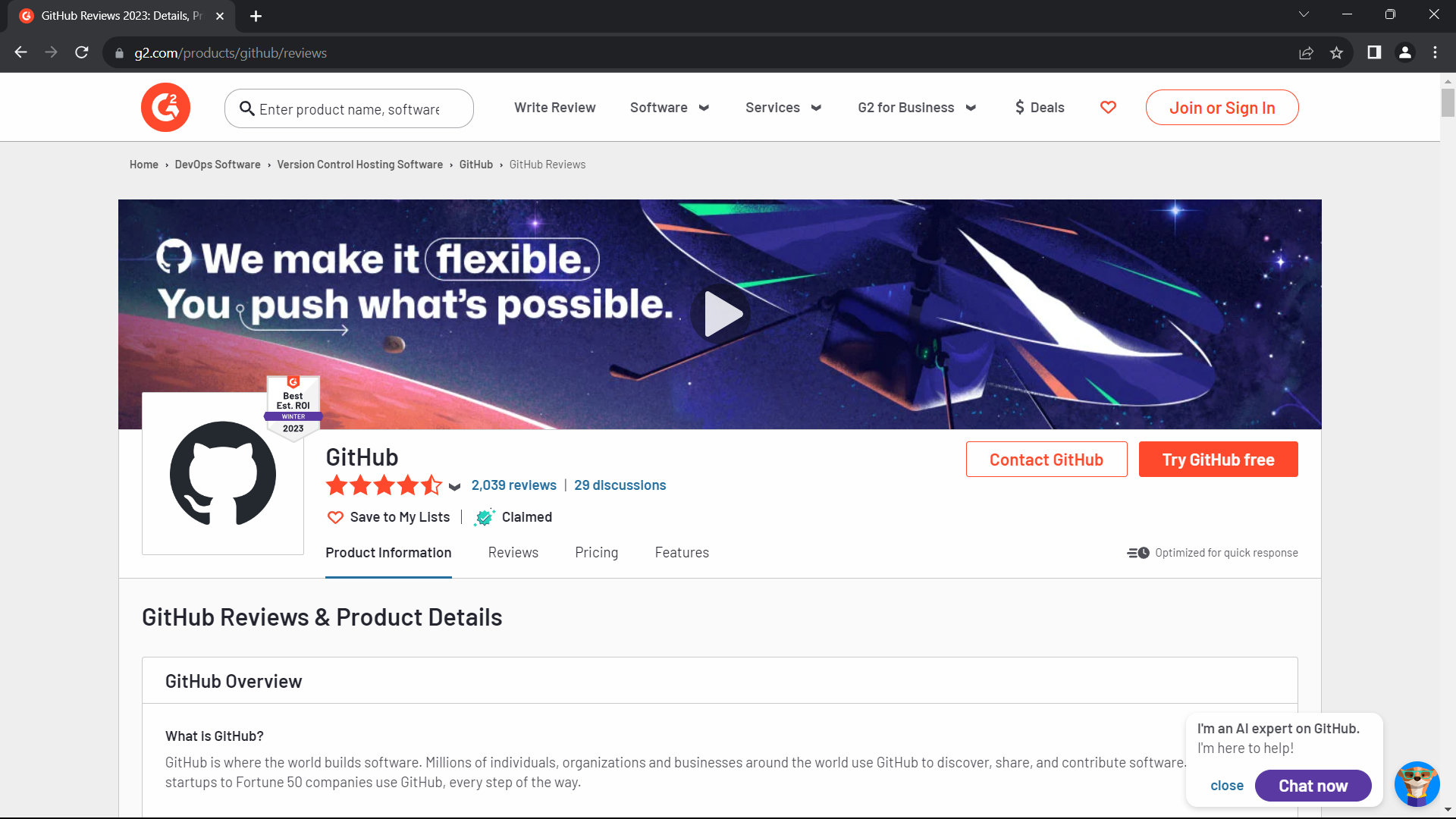
However, using proxies with Botasaurus solves this issue. See the difference by running the following code:
from botasaurus.browser import browser, Driver
@browser(proxy="http://username:password@proxy-provider-domain:port") # TODO: Replace with your own proxy
def scrape_heading_task(driver: Driver, data):
driver.google_get("https://www.g2.com/products/github/reviews")
driver.prompt()
scrape_heading_task() Result:
Important Note: To run the code above, you will need Node.js installed.
Certain proxy providers like BrightData will block access to specific websites. To determine if this is the case, run the following code:
from botasaurus.browser import browser, Driver
@browser(proxy="http://username:password@proxy-provider-domain:port") # TODO: Replace with your own proxy
def visit_ipinfo(driver: Driver, data):
driver.get("https://ipinfo.io/")
driver.prompt()
visit_ipinfo()If you can successfully access the ipinfo website but not the website you're attempting to scrape, it means the proxy provider is blocking access to that particular website.
In such situations, the only solution is to switch to a different proxy provider.
Some good proxy providers we personally use are:
- For Rotating Datacenter Proxies: BrightData Datacenter Proxies, which cost around $0.6 per GB on a pay-as-you-go basis. No KYC is required.
- For Rotating Residential Proxies: IPRoyal Royal Residential Proxies, which cost around $7 per GB on a pay-as-you-go basis. No KYC is required.
As always, nothing good in life comes free. Proxies are expensive, and will take up almost all of your scraping costs.
So, use proxies only when you need them, and prefer request-based scrapers over browser-based scrapers to save bandwidth.
Note: BrightData and IPRoyal have not paid us. We are recommending them based on our personal experience.
The United States is often the best choice because:
- The United States has a highly developed internet infrastructure and is home to numerous data centers, ensuring faster internet speeds.
- Most global companies host their websites in the US, so using a US proxy will result in faster scraping speeds.
ONLY IF you encounter IP blocks.
Sadly, most scrapers unnecessarily use proxies, even when they are not needed. Everything seems like a nail when you have a hammer.
We have seen scrapers which can easily access hundreds of thousands of protected pages using the @browser module on home Wi-Fi without any issues.
So, as a best practice scrape using the @browser module on your home Wi-Fi first. Only resort to proxies when you encounter IP blocks.
This practice will save you a considerable amount of time (as proxies are really slow) and money (as proxies are expensive as well).
The Request Decorator is used to make humane requests. Under the hood, it uses botasaurus-requests, a library based on hrequests, which incorporates important features like:
- Using browser-like headers in the correct order.
- Makes a browser-like connection with correct ciphers.
- Uses
google.comreferer by default to make it appear as if the user has arrived from google search.
Also, The Request Decorator allows you to configure proxy as follows:
@request(
proxy="http://username:password@proxy-provider-domain:port"
) All 3 decorators allow you to configure the following options:
- Parallel Execution:
- Caching Results
- Passing Common Metadata
- Asynchronous Queues
- Asynchronous Execution
- Handling Crashes
- Configuring Output
- Exception Handling
Let's dive into each of these options and in later sections we will see their real-world applications.
The parallel option allows you to scrape data in parallel by launching multiple browser/request/task instances simultaneously. This can significantly speed up the scraping process.
Run the example below to see parallelization in action:
from botasaurus.browser import browser, Driver
@browser(parallel=3, data=["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])
def scrape_heading_task(driver: Driver, link):
driver.get(link)
heading = driver.get_text('h1')
return heading
scrape_heading_task() The cache option enables caching of web scraping results to avoid re-scraping the same data. This can significantly improve performance and reduce redundant requests.
Run the example below to see how caching works:
from botasaurus.browser import browser, Driver
@browser(cache=True, data=["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])
def scrape_heading_task(driver: Driver, link):
driver.get(link)
heading = driver.get_text('h1')
return heading
print(scrape_heading_task())
print(scrape_heading_task()) # Data will be fetched from cache immediately Note: Caching is one of the most important features of Botasaurus.
The metadata option allows you to pass common information shared across all data items. This can include things like API keys, browser cookies, or any other data that remains constant throughout the scraping process.
It is commonly used with caching to exclude details like API keys and browser cookies from the cache key.
Here's an example of how to use the metadata option:
from botasaurus.task import task
@task()
def scrape_heading_task(driver: Driver, data, metadata):
print("metadata:", metadata)
print("data:", data)
data = [
{"profile": "pikachu", "proxy": "http://142.250.77.228:8000"},
{"profile": "greyninja", "proxy": "http://142.250.77.229:8000"},
]
scrape_heading_task(
data,
metadata={"api_key": "BDEC26..."}
)In the world of web scraping, there are only two types of scrapers:
-
Dataset Scrapers: These extract data from websites and store it as datasets. Companies like Bright Data use them to build datasets for Crunchbase, Indeed, etc.
-
Real-time Scrapers: These fetch data from sources in real-time, like SERP APIs that provide Google and DuckDuckGo search results.
When building real-time scrapers, speed is paramount because customers are waiting for requests to complete. The async_queue feature is incredibly useful in such cases.
async_queue allows you to run scraping tasks asynchronously in a queue and gather the results using the .get() method.
A great use case for async_queue is scraping Google Maps. Instead of scrolling through the list of places and then scraping the details of each place sequentially, you can use async_queue to:
- Scroll through the list of places.
- Simultaneously make HTTP requests to scrape the details of each place in the background.
By executing the scrolling and requesting tasks concurrently, you can significantly speed up the scraper.
Run the code below to see browser scrolling and request scraping happening concurrently (really cool, must try!):
from botasaurus.browser import browser, Driver, AsyncQueueResult
from botasaurus.request import request, Request
import json
def extract_title(html):
return json.loads(
html.split(";window.APP_INITIALIZATION_STATE=")[1].split(";window.APP_FLAGS")[0]
)[5][3][2][1]
@request(
parallel=5,
async_queue=True,
max_retry=5,
)
def scrape_place_title(request: Request, link, metadata):
cookies = metadata["cookies"]
html = request.get(link, cookies=cookies, timeout=12).text
title = extract_title(html)
print("Title:", title)
return title
def has_reached_end(driver):
return driver.select('p.fontBodyMedium > span > span') is not None
def extract_links(driver):
return driver.get_all_links('[role="feed"] > div > div > a')
@browser()
def scrape_google_maps(driver: Driver, link):
driver.google_get(link, accept_google_cookies=True) # accepts google cookies popup
scrape_place_obj: AsyncQueueResult = scrape_place_title() # initialize the async queue for scraping places
cookies = driver.get_cookies_dict() # get the cookies from the driver
while True:
links = extract_links(driver) # get the links to places
scrape_place_obj.put(links, metadata={"cookies": cookies}) # add the links to the async queue for scraping
print("scrolling")
driver.scroll_to_bottom('[role="feed"]') # scroll to the bottom of the feed
if has_reached_end(driver): # we have reached the end, let's break buddy
break
results = scrape_place_obj.get() # get the scraped results from the async queue
return results
scrape_google_maps("https://www.google.com/maps/search/web+developers+in+bangalore")Similarly, the run_async option allows you to execute scraping tasks asynchronously, enabling concurrent execution.
Similar to async_queue, you can use the .get() method to retrieve the results of an asynchronous task.
Code Example:
from botasaurus.browser import browser, Driver
from time import sleep
@browser(run_async=True)
def scrape_heading(driver: Driver, data):
sleep(5)
return {}
if __name__ == "__main__":
result1 = scrape_heading() # Launches asynchronously
result2 = scrape_heading() # Launches asynchronously
result1.get() # Wait for the first result
result2.get() # Wait for the second resultThe close_on_crash option determines the behavior of the scraper when an exception occurs:
- If set to
False(default):- The scraper will make a beep sound and pause the browser.
- This makes debugging easier by keeping the browser open at the point of the crash.
- Use this setting during development and testing.
- If set to
True:- The scraper will close the browser and continue with the rest of the data items.
- This is suitable for production environments when you are confident that your scraper is robust.
- Use this setting to avoid interruptions and ensure the scraper processes all data items.
from botasaurus.browser import browser, Driver
@browser(
close_on_crash=False # Determines whether the browser is paused (default: False) or closed when an error occurs
)
def scrape_heading_task(driver: Driver, data):
raise Exception("An error occurred during scraping.")
scrape_heading_task() By default, Botasaurus saves the result of scraping in the output/{your_scraping_function_name}.json file. Let's learn about various ways to configure the output.
- Change Output Filename: Use the
outputparameter in the decorator to specify a custom filename for the output.
from botasaurus.task import task
@task(output="my-output")
def scrape_heading_task(data):
return {"heading": "Hello, Mom!"}
scrape_heading_task()- Disable Output: If you don't want any output to be saved, set
outputtoNone.
from botasaurus.task import task
@task(output=None)
def scrape_heading_task(data):
return {"heading": "Hello, Mom!"}
scrape_heading_task()- Dynamically Write Output: To dynamically write output based on data and result, pass a function to the
outputparameter:
from botasaurus.task import task
from botasaurus import bt
def write_output(data, result):
json_filename = bt.write_json(result, 'data')
excel_filename = bt.write_excel(result, 'data')
bt.zip_files([json_filename, excel_filename]) # Zip the JSON and Excel files for easy delivery to the customer
@task(output=write_output)
def scrape_heading_task(data):
return {"heading": "Hello, Mom!"}
scrape_heading_task()- Upload File to S3: Use
bt.upload_to_s3to upload file to S3 bucket.
from botasaurus.task import task
from botasaurus import bt
def write_output(data, result):
json_filename = bt.write_json(result, 'data')
bt.upload_to_s3(json_filename, 'my-magical-bucket', "AWS_ACCESS_KEY", "AWS_SECRET_KEY")
@task(output=write_output)
def scrape_heading_task(data):
return {"heading": "Hello, Mom!"}
scrape_heading_task()5.Save Outputs in Multiple Formats: Use the output_formats parameter to save outputs in different formats like JSON and EXCEL.
from botasaurus.task import task
@task(output_formats=[bt.Formats.JSON, bt.Formats.EXCEL])
def scrape_heading_task(data):
return {"heading": "Hello, Mom!"}
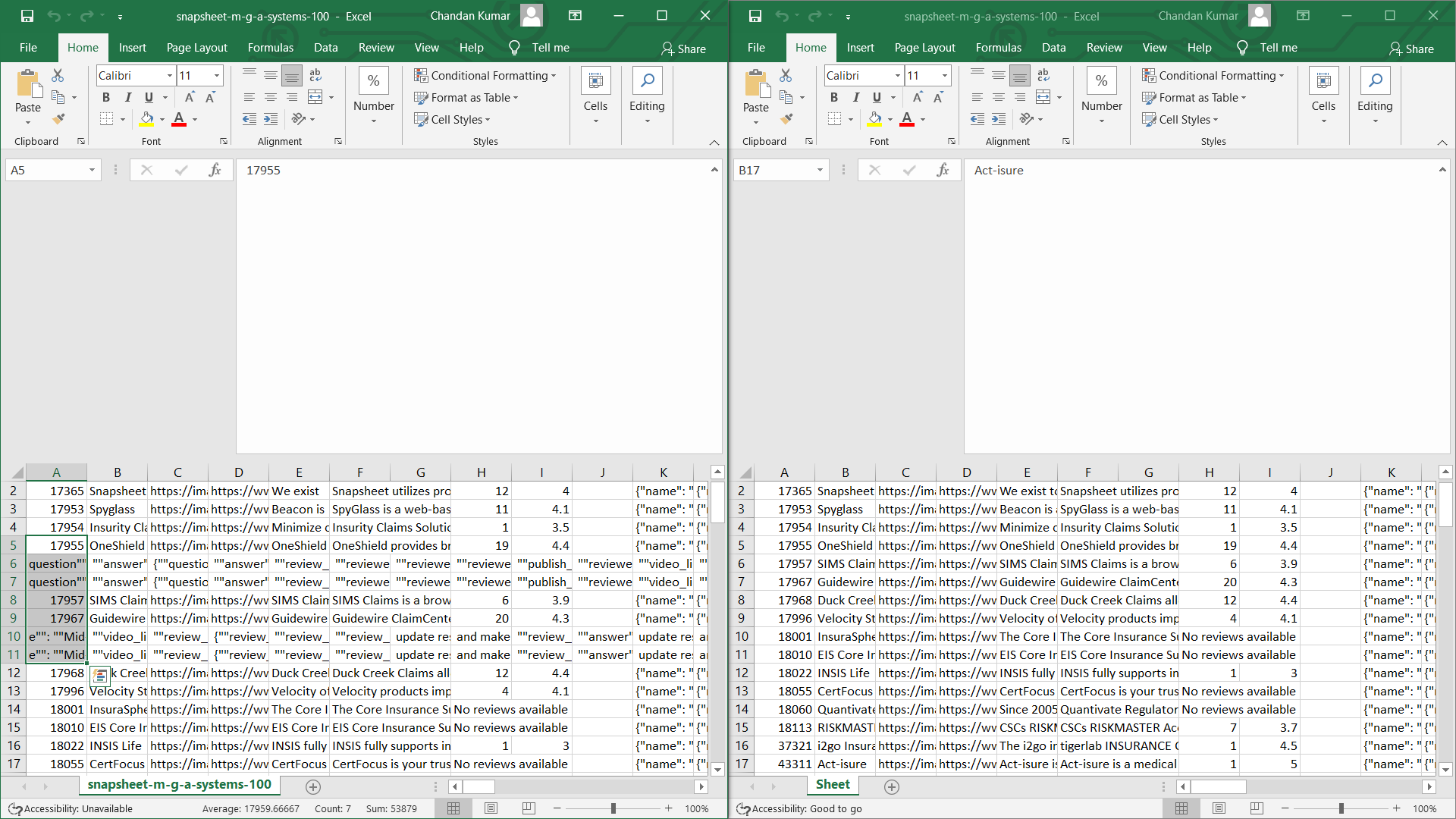
scrape_heading_task()PRO TIP: When delivering data to customers, provide the dataset in JSON and Excel formats. Avoid CSV unless the customer asks, because Microsoft Excel has a hard time rendering CSV files with nested JSON.
CSV vs Excel
Botasaurus provides various exception handling options to make your scrapers more robust:
max_retry: By default, any failed task is not retried. You can specify the maximum number of times to retry scraping when an error occurs using themax_retryoption.retry_wait: Specifies the waiting time between retries.raise_exception: By default, Botasaurus does not raise an exception when an error occurs during scraping, because let's say you are keeping your PC running overnight to scrape 10,000 links. If one link fails, you really don't want to stop the entire scraping process, and ruin your morning by seeing an unfinished dataset.must_raise_exceptions: Specifies exceptions that must be raised, even ifraise_exceptionis set toFalse.create_error_logs: Determines whether error logs should be created when exceptions occur. In production, when scraping hundreds of thousands of links, it's recommended to setcreate_error_logstoFalseto avoid using computational resources for creating error logs.
@browser(
raise_exception=True, # Raise an exception and halt the scraping process when an error occurs
max_retry=5, # Retry scraping a failed task a maximum of 5 times
retry_wait=10, # Wait for 10 seconds before retrying a failed task
must_raise_exceptions=[CustomException], # Definitely raise CustomException, even if raise_exception is set to False
create_error_logs=False # Disable the creation of error logs to optimize scraper performance
)
def scrape_heading_task(driver: Driver, data):
# ...What are some examples of common web scraping utilities provided by Botasaurus that make scraping easier?
The bt utility provides helper functions for:
- Writing and reading JSON, EXCEL, and CSV files
- Data cleaning
Some key functions are:
bt.write_jsonandbt.read_json: Easily write and read JSON files.
from botasaurus import bt
data = {"name": "pikachu", "power": 101}
bt.write_json(data, "output")
loaded_data = bt.read_json("output")bt.write_excelandbt.read_excel: Easily write and read EXCEL files.
from botasaurus import bt
data = {"name": "pikachu", "power": 101}
bt.write_excel(data, "output")
loaded_data = bt.read_excel("output")bt.write_csvandbt.read_csv: Easily write and read CSV files.
from botasaurus import bt
data = {"name": "pikachu", "power": 101}
bt.write_csv(data, "output")
loaded_data = bt.read_csv("output")bt.write_htmlandbt.read_html: Write HTML content to a file.
from botasaurus import bt
html_content = "<html><body><h1>Hello, Mom!</h1></body></html>"
bt.write_html(html_content, "output")bt.write_temp_json,bt.write_temp_csv,bt.write_temp_html: Write temporary JSON, CSV, or HTML files for debugging purposes.
from botasaurus import bt
data = {"name": "pikachu", "power": 101}
bt.write_temp_json(data)
bt.write_temp_csv(data)
bt.write_temp_html("<html><body><h1>Hello, Mom!</h1></body></html>")- Data cleaning functions like
bt.extract_numbers,bt.extract_links,bt.remove_html_tags, and more.
text = "The price is $19.99 and the website is https://www.example.com"
numbers = bt.extract_numbers(text) # [19.99]
links = bt.extract_links(text) # ["https://www.example.com"]The Local Storage utility allows you to store and retrieve key-value pairs, which can be useful for maintaining state between scraper runs.
Here's how to use it:
from botasaurus.local_storage import LocalStorage
LocalStorage.set_item("credits_used", 100)
print(LocalStorage.get_item("credits_used", 0))The soupify utility creates a BeautifulSoup object from a Driver, Requests response, Driver Element, or HTML string.
from botasaurus.soupify import soupify
from botasaurus.request import request, Request
from botasaurus.browser import browser, Driver
@request
def get_heading_from_request(req: Request, data):
"""
Get the heading of a web page using the request object.
"""
response = req.get("https://www.example.com")
soup = soupify(response)
heading = soup.find("h1").text
print(f"Page Heading: {heading}")
@browser
def get_heading_from_driver(driver: Driver, data):
"""
Get the heading of a web page using the driver object.
"""
driver.get("https://www.example.com")
# Get the heading from the entire page
page_soup = soupify(driver)
page_heading = page_soup.find("h1").text
print(f"Heading from Driver's Soup: {page_heading}")
# Get the heading from the body element
body_soup = soupify(driver.select("body"))
body_heading = body_soup.find("h1").text
print(f"Heading from Element's Soup: {body_heading}")
# Call the functions
get_heading_from_request()
get_heading_from_driver()IP Utils provide functions to get information about the current IP address, such as the IP itself, country, ISP, and more:
from botasaurus.ip_utils import IPUtils
# Get the current IP address
current_ip = IPUtils.get_ip()
print(current_ip)
# Output: 47.31.226.180
# Get detailed information about the current IP address
ip_info = IPUtils.get_ip_info()
print(ip_info)
# Output: {
# "ip": "47.31.226.180",
# "country": "IN",
# "region": "Delhi",
# "city": "Delhi",
# "postal": "110001",
# "coordinates": "28.6519,77.2315",
# "latitude": "28.6519",
# "longitude": "77.2315",
# "timezone": "Asia/Kolkata",
# "org": "AS55836 Reliance Jio Infocomm Limited"
# }The Cache utility in Botasaurus allows you to manage cached data for your scraper. You can put, get, has, remove, and clear cache data.
Basic Usage
from botasaurus.task import task
from botasaurus.cache import Cache
# Example scraping function
@task
def scrape_data(data):
# Your scraping logic here
return {"processed": data}
# Sample data for scraping
input_data = {"key": "value"}
# Adding data to the cache
Cache.put('scrape_data', input_data, scrape_data(input_data))
# Checking if data is in the cache
if Cache.has('scrape_data', input_data):
# Retrieving data from the cache
cached_data = Cache.get('scrape_data', input_data)
print(f"Cached data: {cached_data}")
# Removing specific data from the cache
Cache.remove('scrape_data', input_data)
# Clearing the complete cache for the scrape_data function
Cache.clear('scrape_data')Advanced Usage for large-scale scraping projects
Count Cached Items
You can count the number of items cached for a particular function, which can serve as a scraping progress bar.
from botasaurus.cache import Cache
Cache.print_cached_items_count('scraping_function')Filter Cached/Uncached Items
You can filter items that have been cached or not cached for a particular function.
from botasaurus.cache import Cache
all_items = ['1', '2', '3', '4', '5']
# Get items that are cached
cached_items = Cache.filter_items_in_cache('scraping_function', all_items)
print(cached_items)
# Get items that are not cached
uncached_items = Cache.filter_items_not_in_cache('scraping_function', all_items)
print(uncached_items)Delete Cache
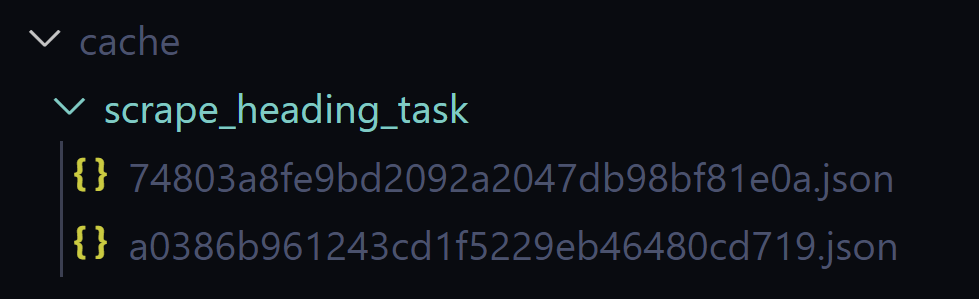
The cache for a function is stored in the cache/{your_scraping_function_name}/ folder. To delete the cache, simply delete that folder.
Delete Specific Items
You can delete specific items from the cache for a particular function.
from botasaurus.cache import Cache
all_items = ['1', '2', '3', '4', '5']
deleted_count = Cache.delete_items('scraping_function', all_items)
print(f"Deleted {deleted_count} items from the cache.")Delete Items by Filter
In some cases, you may want to delete specific items from the cache based on a condition. For example, if you encounter honeypots (mock HTML served to dupe web scrapers) while scraping a website, you may want to delete those items from the cache.
def should_delete_item(item, result):
if 'Honeypot Item' in result:
return True # Delete the item
return False # Don't delete the item
all_items = ['1', '2', '3', '4', '5']
# List of items to iterate over, it is fine if the list contains items which have not been cached, as they will be simply ignored.
Cache.delete_items_by_filter('scraping_function', all_items, should_delete_item)Importantly, be cautious and first use delete_items_by_filter on a small set of items which you want to be deleted. Here's an example:
from botasaurus import bt
from botasaurus.cache import Cache
def should_delete_item(item, result):
# TODO: Update the logic
if 'Honeypot Item' in result:
return True # Delete the item
return False # Don't delete the item
test_items = ['1', '2'] # TODO: update with target items
scraping_function_name = 'scraping_function' # TODO: update with target scraping function name
Cache.delete_items_by_filter(scraping_function_name, test_items, should_delete_item)
for item in test_items:
if Cache.has(scraping_function_name, item):
bt.prompt(f"Item {item} was not deleted. Please review the logic of the should_delete_item function.")In web scraping, it is a common use case to scrape product pages, blogs, etc. But before scraping these pages, you need to get the links to these pages.
Sadly, Many developers unnecessarily increase their work by writing code to visit each page one by one and scrape links, which they could have easily obtained by just looking at the Sitemap.
The Botasaurus Sitemap Module makes this process easy as cake by allowing you to get all links or sitemaps using:
- The homepage URL (e.g.,
https://www.omkar.cloud/) - A direct sitemap link (e.g.,
https://www.omkar.cloud/sitemap.xml) - A
.gzcompressed sitemap
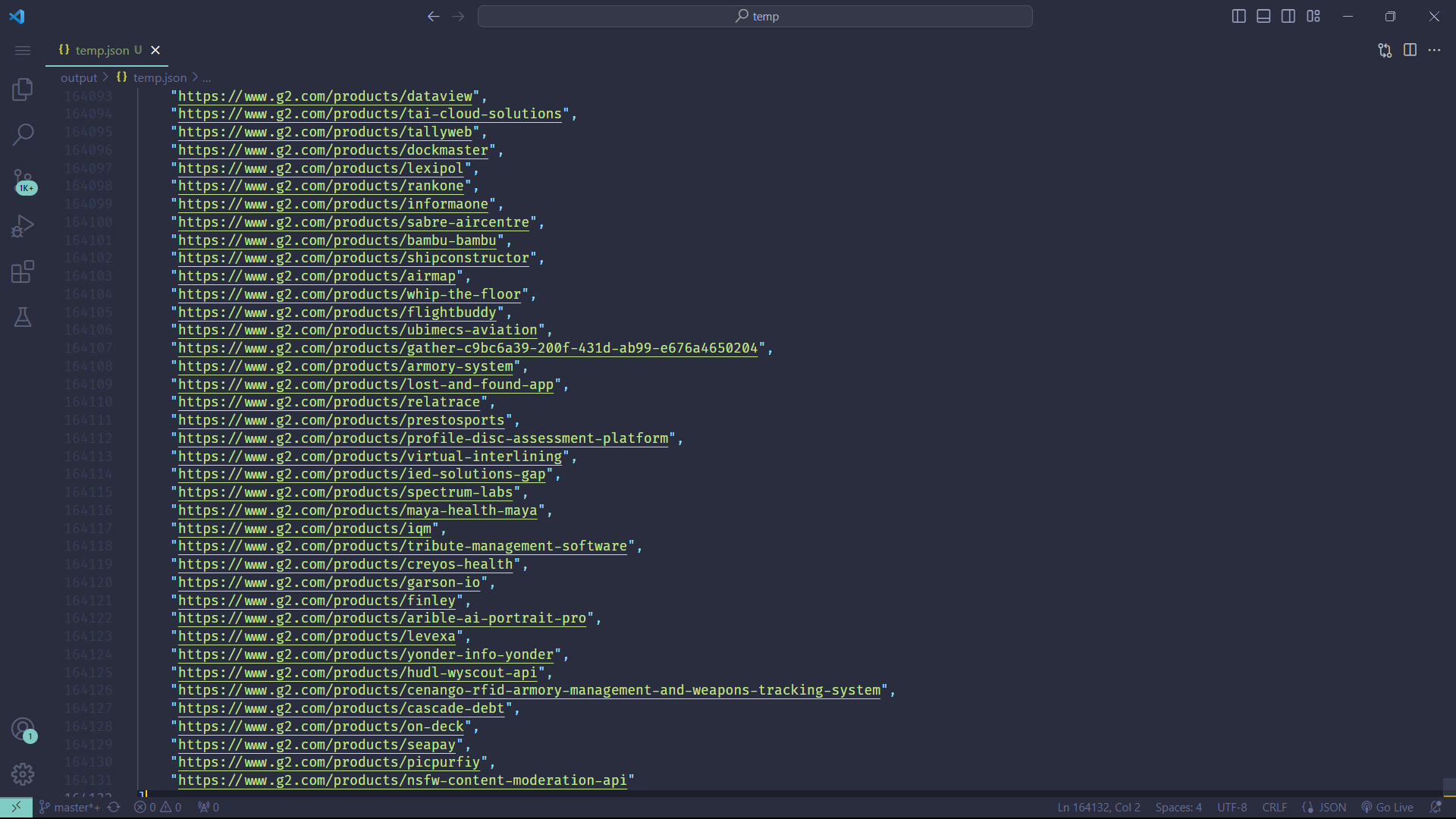
For example, if you're an Angel Investor seeking innovative tech startups to invest, G2 is an ideal platform to find such startups. You can run the following code to fetch over 160K+ product links from G2:
from botasaurus import bt
from botasaurus.sitemap import Sitemap, Filters, Extractors
links = (
Sitemap("https://www.g2.com/sitemaps/sitemap_index.xml.gz")
.filter(Filters.first_segment_equals("products"))
.extract(Extractors.extract_link_upto_second_segment())
.write_links('g2-products')
)Output:
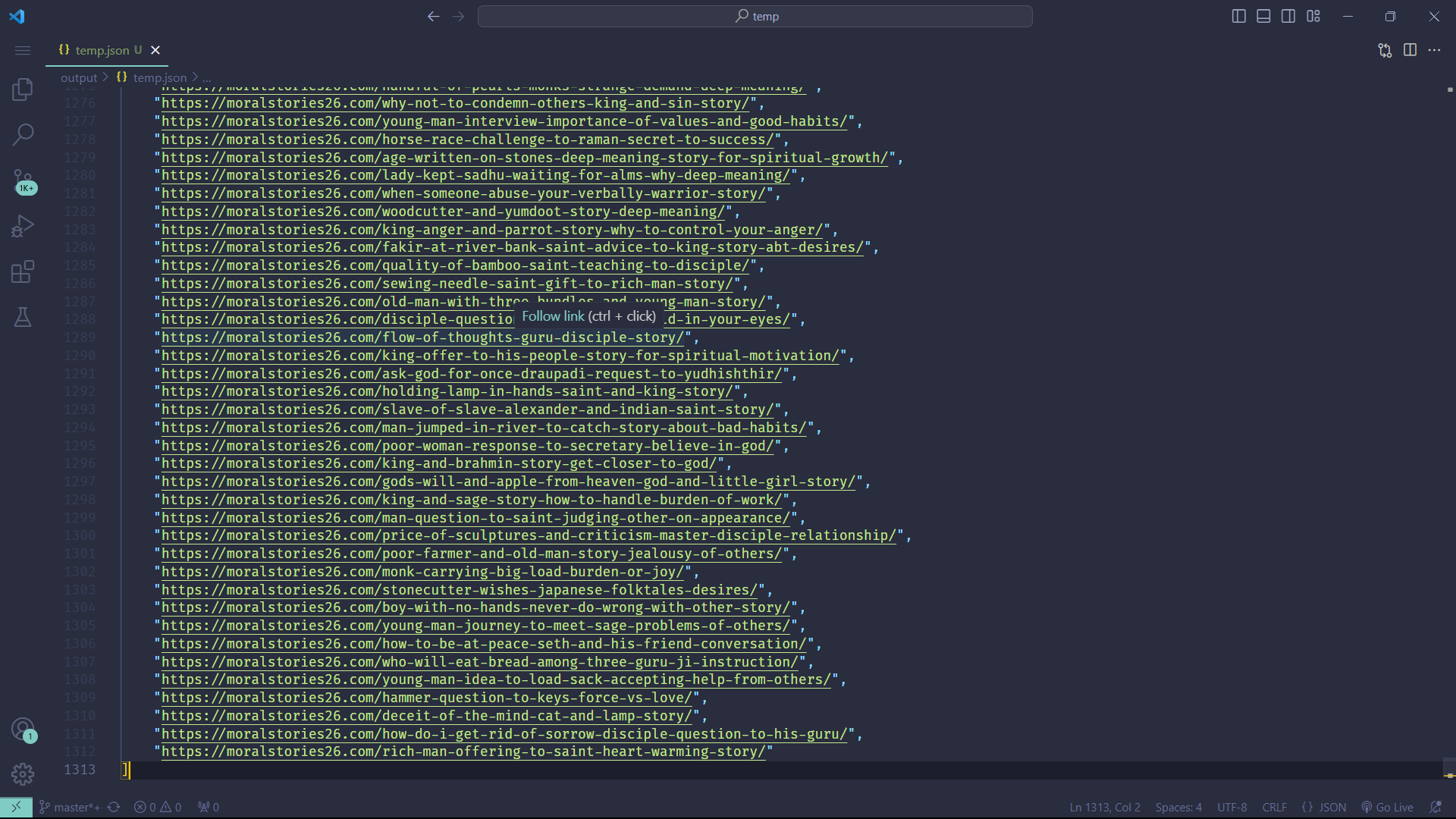
Or, let's say you're in the mood for some reading and looking for good stories. The following code will get you over 1000+ from moralstories26.com:
from botasaurus import bt
from botasaurus.sitemap import Sitemap, Filters
links = (
Sitemap("https://moralstories26.com/")
.filter(
Filters.has_exactly_1_segment(),
Filters.first_segment_not_equals(
["about", "privacy-policy", "akbar-birbal", "animal", "education", "fables", "facts", "family", "famous-personalities", "folktales", "friendship", "funny", "heartbreaking", "inspirational", "life", "love", "management", "motivational", "mythology", "nature", "quotes", "spiritual", "uncategorized", "zen"]
),
)
.write_links('moral-stories')
)Output:
Also, before scraping a site, it's useful to identify the available sitemaps. This can be easily done with the following code:
from botasaurus import bt
from botasaurus.sitemap import Sitemap
sitemaps = Sitemap("https://www.omkar.cloud/").write_sitemaps('omkar-sitemaps')Output:
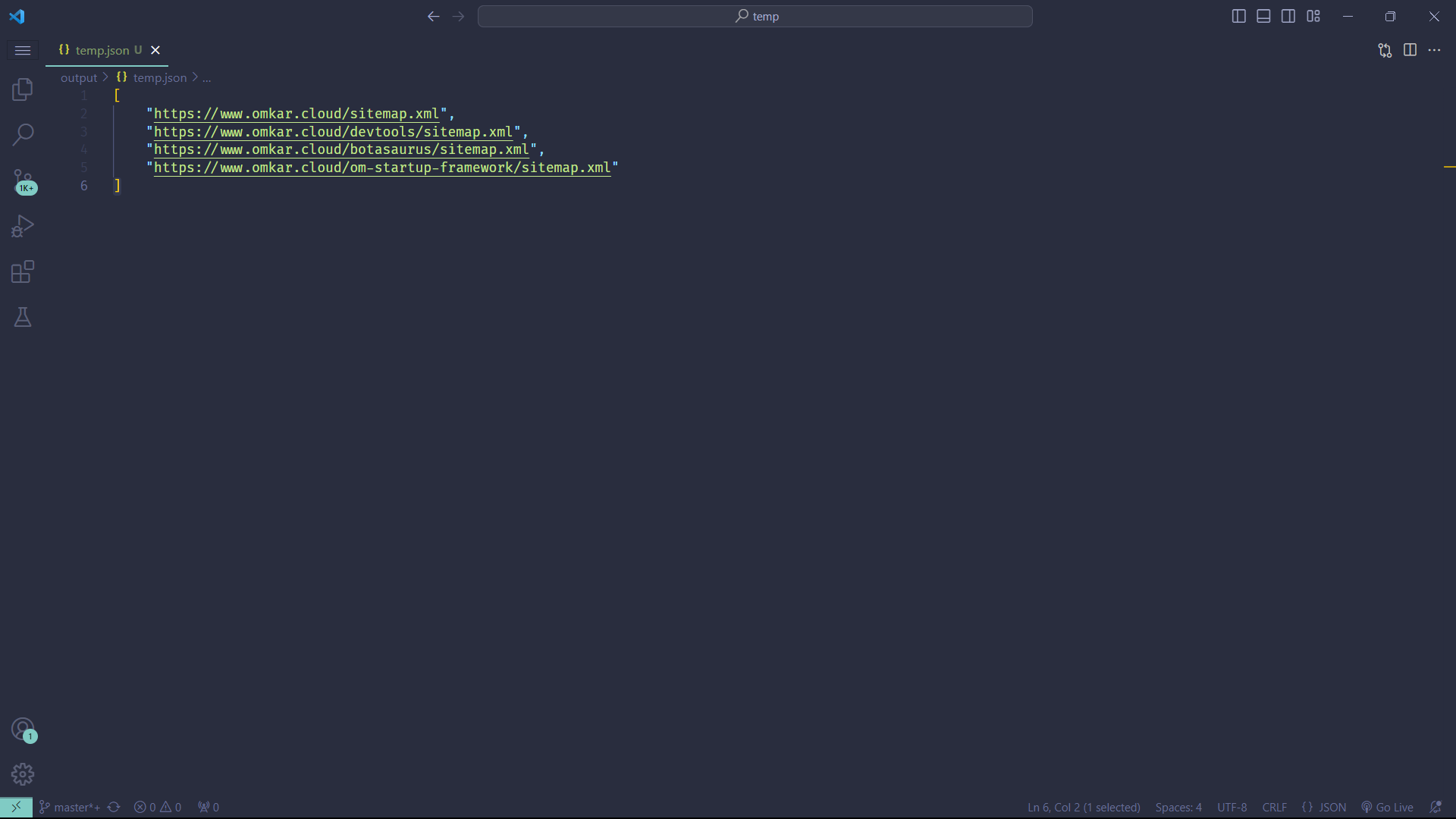
To ensure your scrapers run super fast, we cache the Sitemap, but you may want to periodically refresh the cache. To do so, pass the Cache.REFRESH parameter.
from botasaurus import bt
from botasaurus.sitemap import Sitemap, Filters, Extractors
from botasaurus.cache import Cache
links = (
Sitemap("https://www.g2.com/sitemaps/sitemap_index.xml.gz", cache=Cache.REFRESH) # Refresh the cache
.filter(Filters.first_segment_equals("products"))
.extract(Extractors.extract_link_upto_second_segment())
.write_links('g2-products')
)Filtering links from a webpage is a common requirement in web scraping. For example, you might want to filter out all non-product pages.
Botasaurus's Links module simplifies link filtering and extraction:
from botasaurus.links import Links, Filters, Extractors
# Sample list of links
links = [
"https://www.g2.com/categories/project-management",
"https://www.g2.com/categories/payroll",
"https://www.g2.com/products/jenkins/reviews",
"https://www.g2.com/products/redis-software/pricing"
]
# Filter and extract links
filtered_links = (
Links(links)
.filter(Filters.first_segment_equals("products"))
.extract(Extractors.extract_link_upto_second_segment())
.write('g2-products')
)Sadly, when using caching, most developers write a scraping function that scrapes the HTML and extracts the data from the HTML in the same function, like this:
from botasaurus.request import request, Request
from botasaurus.soupify import soupify
@request
def scrape_data(request: Request, data):
# Visit the Link
response = request.get(data)
# Create a BeautifulSoup object
soup = soupify(response)
# Retrieve the heading element's text
heading = soup.find('h1').get_text()
# Save the data as a JSON file in output/scrape_data.json
return {"heading": heading}
data_items = [
"https://www.omkar.cloud/",
"https://www.omkar.cloud/blog/",
"https://stackoverflow.com/",
]
scrape_data(data_items)Now, let's say, after 50% of the dataset has been scraped, what if:
- Your customer wants to add another data point (which is very likely), or
- One of your BeautifulSoup selectors happens to be flaky and needs to be updated (which is super likely)?
In such cases, you will have to scrape all the pages again, which is painful as it will take a lot of time and incur high proxy costs.
To resolve this issue, you can:
- Write a function that only scrapes and caches the HTML.
- Write a separate function that calls the HTML scraping function, extracts data using BeautifulSoup, and caches the result.
Here's a practical example:
from bs4 import BeautifulSoup
from botasaurus.task import task
from botasaurus.request import request, Request
from botasaurus.soupify import soupify
@request(cache=True)
def scrape_html(request: Request, link):
# Scrape the HTML and cache it
html = request.get(link).text
return html
def extract_data(soup: BeautifulSoup):
# Extract the heading from the HTML
heading = soup.find("h1").get_text()
return {"heading": heading}
# Cache the scrape_data task as well
@task(cache=True)
def scrape_data(link):
# Call the scrape_html function to get the cached HTML
html = scrape_html(link)
# Extract data from the HTML using the extract_data function
return extract_data(soupify(html))
data_items = [
"https://www.omkar.cloud/",
"https://www.omkar.cloud/blog/",
"https://stackoverflow.com/",
]
scrape_data(data_items)With this approach:
- If you need to add data points or fix BeautifulSoup bugs, delete the
cache/scrape_datafolder and re-run the scraper. - You only need to re-run the BeautifulSoup extraction, not the entire HTML scraping, saving time and proxy costs. Yahoo!
PRO TIP: This approach also makes your extract_data code easier and faster to test, like this:
from bs4 import BeautifulSoup
from botasaurus import bt
def extract_data(soup: BeautifulSoup):
heading = soup.find('h1').get_text()
return {"heading": heading}
if __name__ == '__main__':
# Will use the cached HTML and run the extract_data function again.
bt.write_temp_json(scrape_data("https://www.omkar.cloud/", cache=False))What are the recommended settings for each decorator to build a production-ready scraper in Botasaurus?
For websites with minimal protection, use the Request module.
Here's a template for creating production-ready datasets using the Request module:
from bs4 import BeautifulSoup
from botasaurus.task import task
from botasaurus.request import request, Request,NotFoundException
from botasaurus.soupify import soupify
@request(
# proxy='http://username:password@datacenter-proxy-domain:proxy-port', # Uncomment to use Proxy ONLY if you face IP blocking
cache=True,
max_retry=20, # Retry up to 20 times, which is a good default
output=None,
close_on_crash=True,
raise_exception=True,
create_error_logs=False,
)
def scrape_html(request: Request, link):
# Scrape the HTML and cache it
response = request.get(link)
if response.status_code == 404:
# A Special Exception to skip retrying this link
raise NotFoundException(link)
response.raise_for_status()
return response.text
def extract_data(soup: BeautifulSoup):
# Extract the heading from the HTML
heading = soup.find("h1").get_text()
return {"heading": heading}
# Cache the scrape_data task as well
@task(
cache=True,
close_on_crash=True,
create_error_logs=False,
parallel=40, # Run 40 requests in parallel, which is a good default
)
def scrape_data(link):
# Call the scrape_html function to get the cached HTML
html = scrape_html(link)
# Extract data from the HTML using the extract_data function
return extract_data(soupify(html))
data_items = [
"https://www.omkar.cloud/",
"https://www.omkar.cloud/blog/",
"https://stackoverflow.com/",
]
scrape_data(data_items)For visiting well protected websites, use the Browser module.
Here's a template for creating production-ready datasets using the Browser module:
from bs4 import BeautifulSoup
from botasaurus.task import task
from botasaurus.browser import browser, Driver, NotFoundException
from botasaurus.soupify import soupify
@browser(
# proxy='http://username:password@datacenter-proxy-domain:proxy-port', # Uncomment to use Proxy ONLY if you face IP blocking
# block_images_and_css=True, # Uncomment to block images and CSS, which can speed up scraping
# wait_for_complete_page_load=False, # Uncomment to proceed once the DOM (Document Object Model) is loaded, without waiting for all resources to finish loading. This is recommended for faster scraping of Server Side Rendered (HTML) pages. eg: https://www.g2.com/products/jenkins/reviews.html
cache=True,
max_retry=5, # Retry up to 5 times, which is a good default
reuse_driver= True, # Reuse the same driver for all tasks
output=None,
close_on_crash=True,
raise_exception=True,
create_error_logs=False,
)
def scrape_html(driver: Driver, link):
# Scrape the HTML and cache it
if driver.config.is_new:
driver.google_get(
link,
bypass_cloudflare=True, # delete this line if the website you're accessing is not protected by Cloudflare
)
response = driver.requests.get(link)
if response.status_code == 404:
# A Special Exception to skip retrying this link
raise NotFoundException(link)
response.raise_for_status()
html = response.text
return html
def extract_data(soup: BeautifulSoup):
# Extract the heading from the HTML
heading = soup.select_one('.product-head__title [itemprop="name"]').get_text()
return {"heading": heading}
# Cache the scrape_data task as well
@task(
cache=True,
close_on_crash=True,
create_error_logs=False,
)
def scrape_data(link):
# Call the scrape_html function to get the cached HTML
html = scrape_html(link)
# Extract data from the HTML using the extract_data function
return extract_data(soupify(html))
data_items = [
"https://www.g2.com/products/stack-overflow-for-teams/reviews?page=8",
"https://www.g2.com/products/jenkins/reviews?page=19",
]
scrape_data(data_items)- Use
google_get, usegoogle_get, and usegoogle_get! - Don't use
headlessmode, else you will surely be identified by Cloudflare, Datadome, Imperva. - Don't use Proxies, instead use your home Wi-Fi connection, even when scraping hundreds of thousands of pages.
While developing a scraper, multiple browser instances may remain open in the background (because of interrupting it with CTRL + C). This situation can cause your computer to hang.
To prevent your PC from hanging, you can run the following command to close all Chrome instances:
python -m close_chromeTo run a Scraper in Docker, use the Botasaurus Starter Template, which includes the necessary Dockerfile and Docker Compose configurations.
Use the following commands to clone the Botasaurus Starter Template, build a Docker image from it, and execute the scraper within a Docker environment.
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project
cd my-botasaurus-project
docker-compose build
docker-compose up
Running a scraper in Gitpod offers several benefits:
- Allows your scraper to use a powerful 8-core machine with 1000 Mbps internet speed
- Makes it easy to showcase your scraper to customers without them having to install anything, by simply sharing the Gitpod machine link
In this example, we will run the Botasaurus Starter template in Gitpod:
-
First, visit this link and sign up using your GitHub account.
-
Once signed up, open the starter project in Gitpod.
-
In the terminal, run the following command:
python run.py
-
You will see a popup notification with the heading "A service is available on port 3000". In the popup notification, click the "Open Browser" button to open the UI Dashboard in your browser
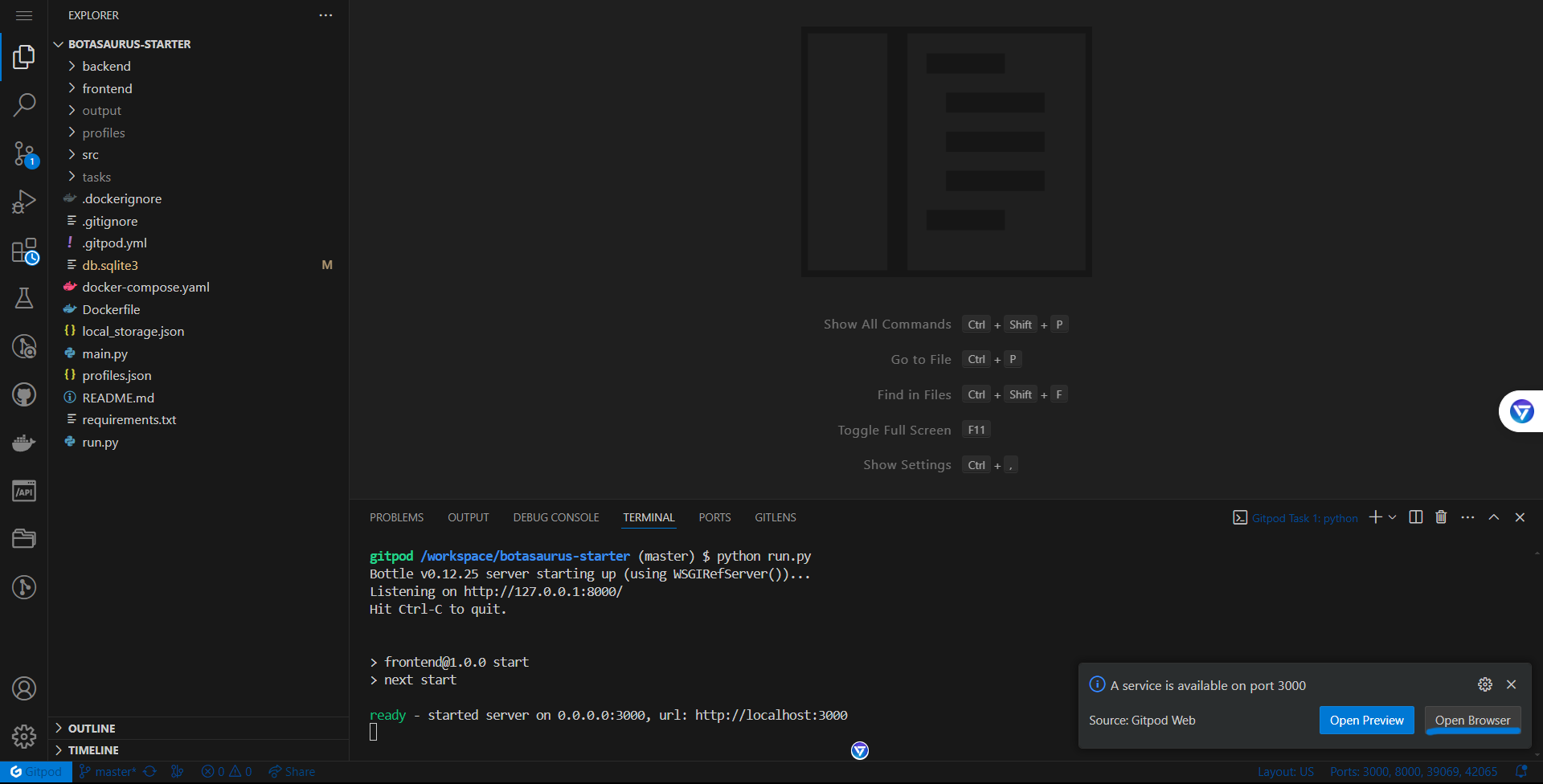
-
Now, you can press the
Runbutton to get the results.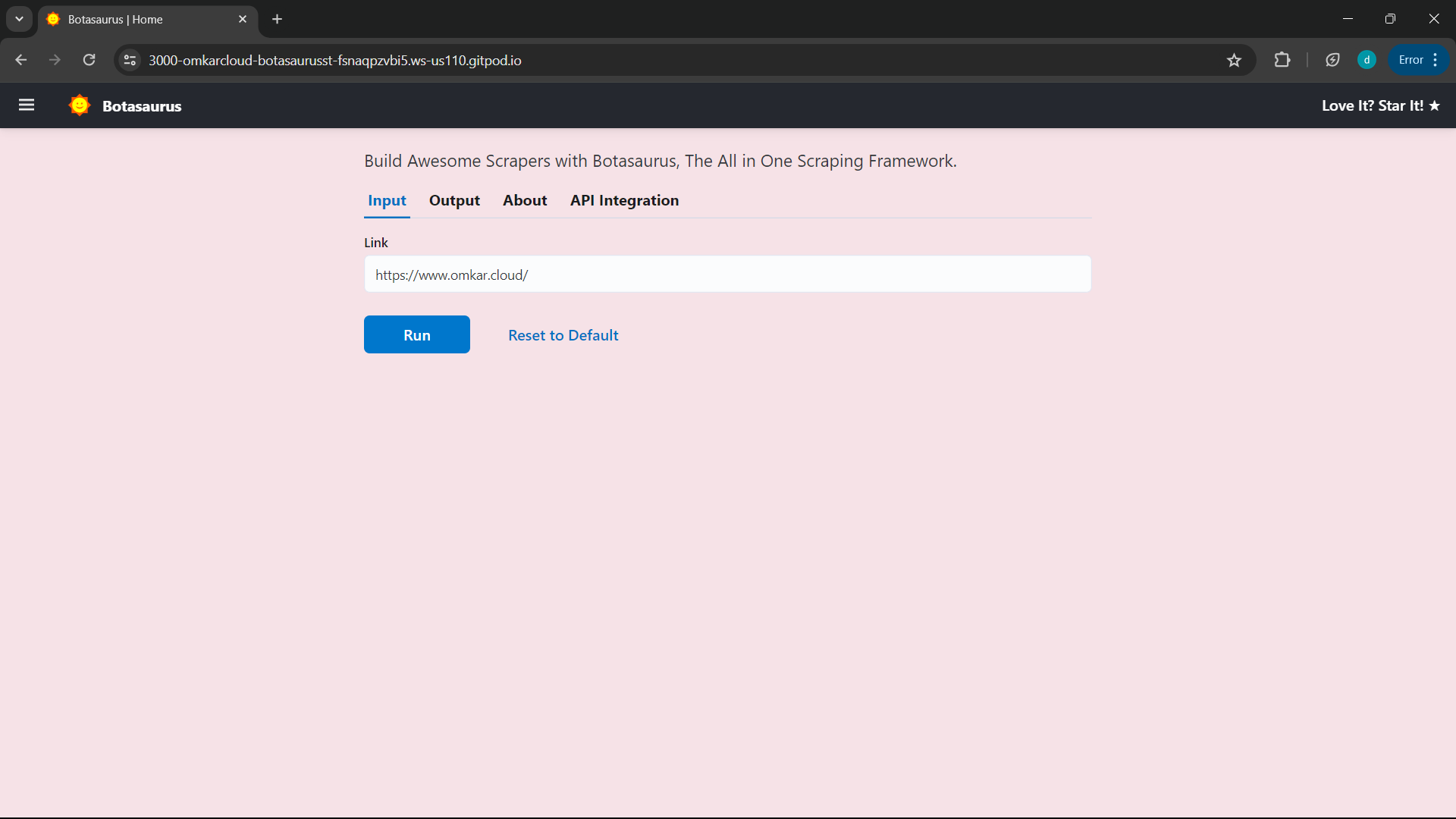
Note: Gitpod is not suitable for long-running tasks, as the environment will automatically shut down after a short period of inactivity. Use your local machine or a cloud VM for long-running scrapers.
To run your scraper in a Virtual Machine, we will:
- Create a static IP
- Create a VM with that IP
- SSH into the VM
- Install the scraper
Now, follow these steps to run your scraper in a Virtual Machine:
-
- If you don't already have one, create a Google Cloud Account. You'll receive a $300 credit to use over 3 months.
- If you don't already have one, create a Google Cloud Account. You'll receive a $300 credit to use over 3 months.
-
Visit the Google Cloud Console and click the Cloud Shell button. A terminal will open up.
-
Run the following commands in the terminal:
python -m pip install bota python -m bota create-ip
You will be asked for a VM name. Enter any name you like, such as "pikachu".
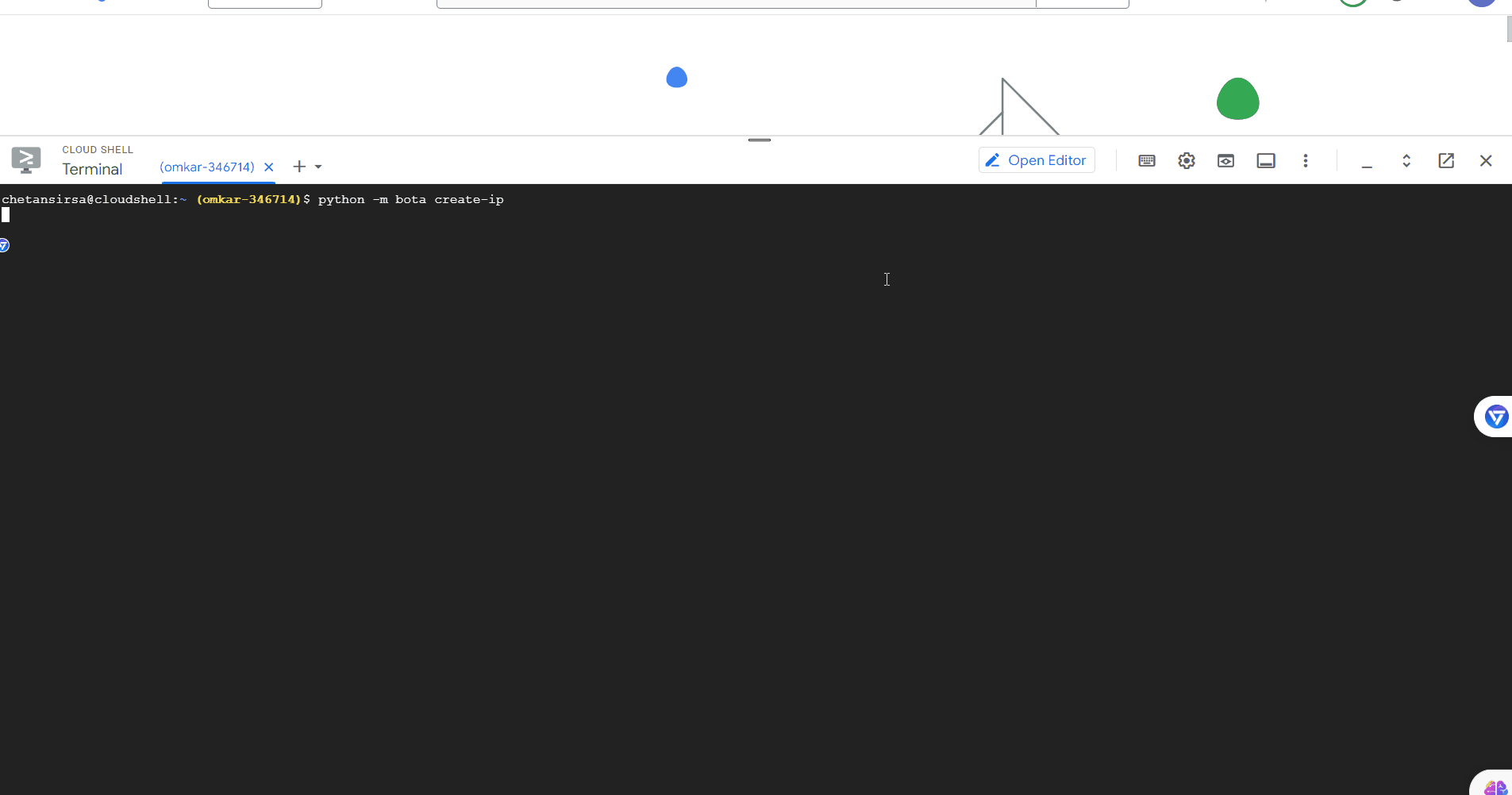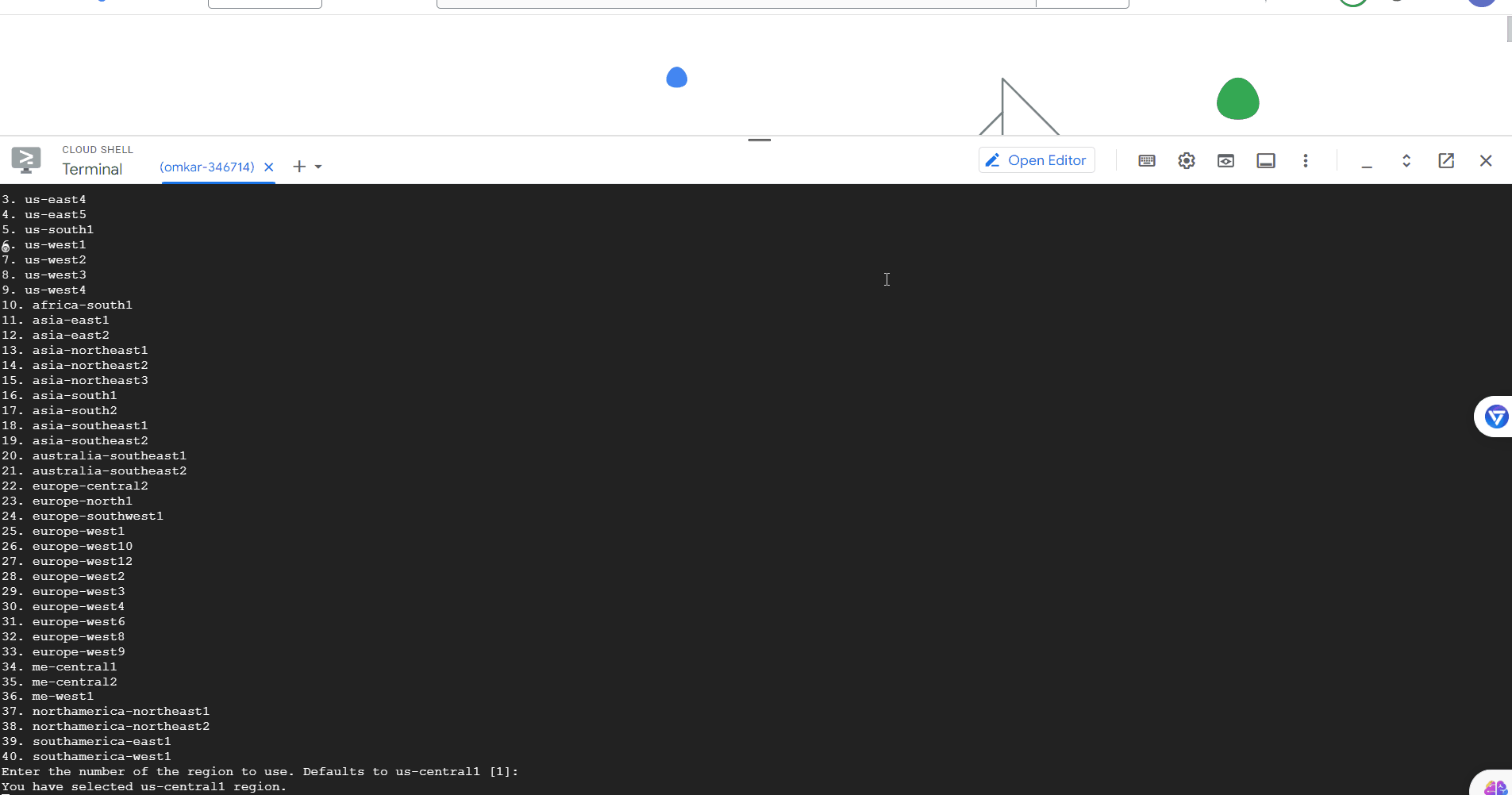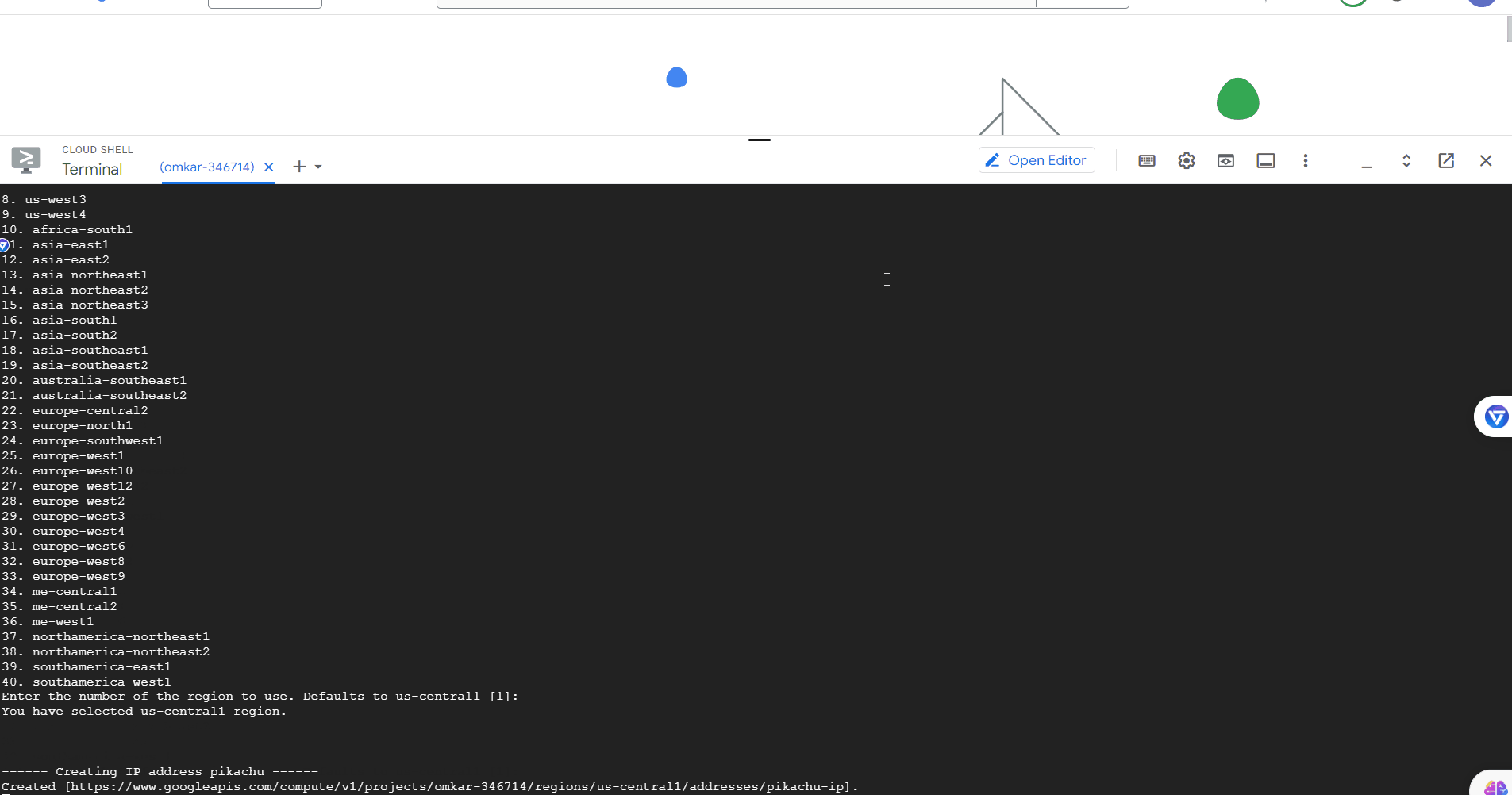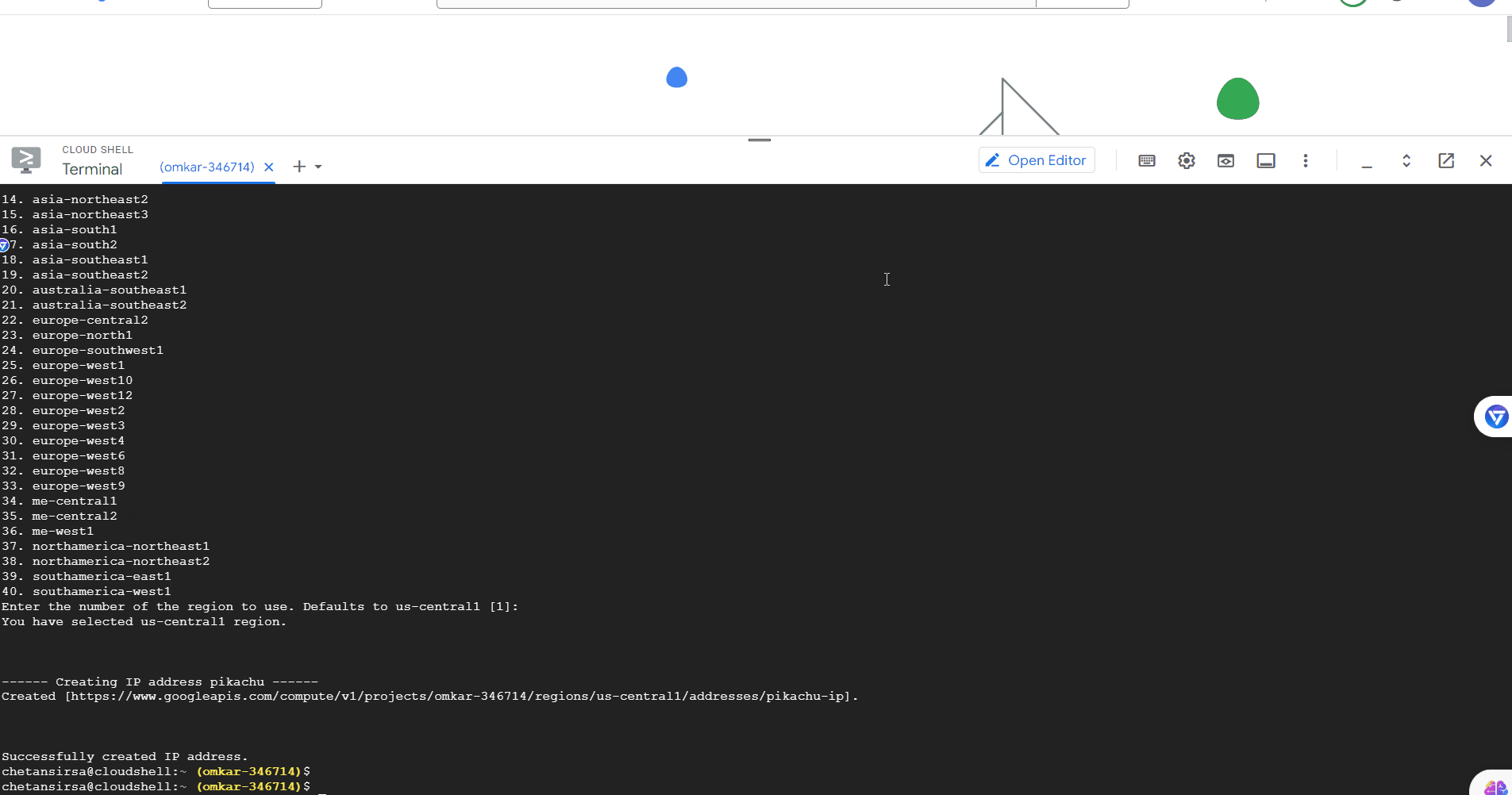
Name: pikachu
Then, you will be asked for the region for the scraper. Press Enter to go with the default, which is "us-central1", as most global companies host their websites in the US.
Region: Default
-
Now, visit this link and create a deployment from Google Click to Deploy with the following settings:
zone: us-central1-a # Use the zone from the region you selected in the previous step. Series: N1 Machine Type: n1-standard-2 (2 vCPU, 1 core, 7.5 GB memory) Network Interface [External IP]: pikachu-ip # Use the IP name you created in the previous step.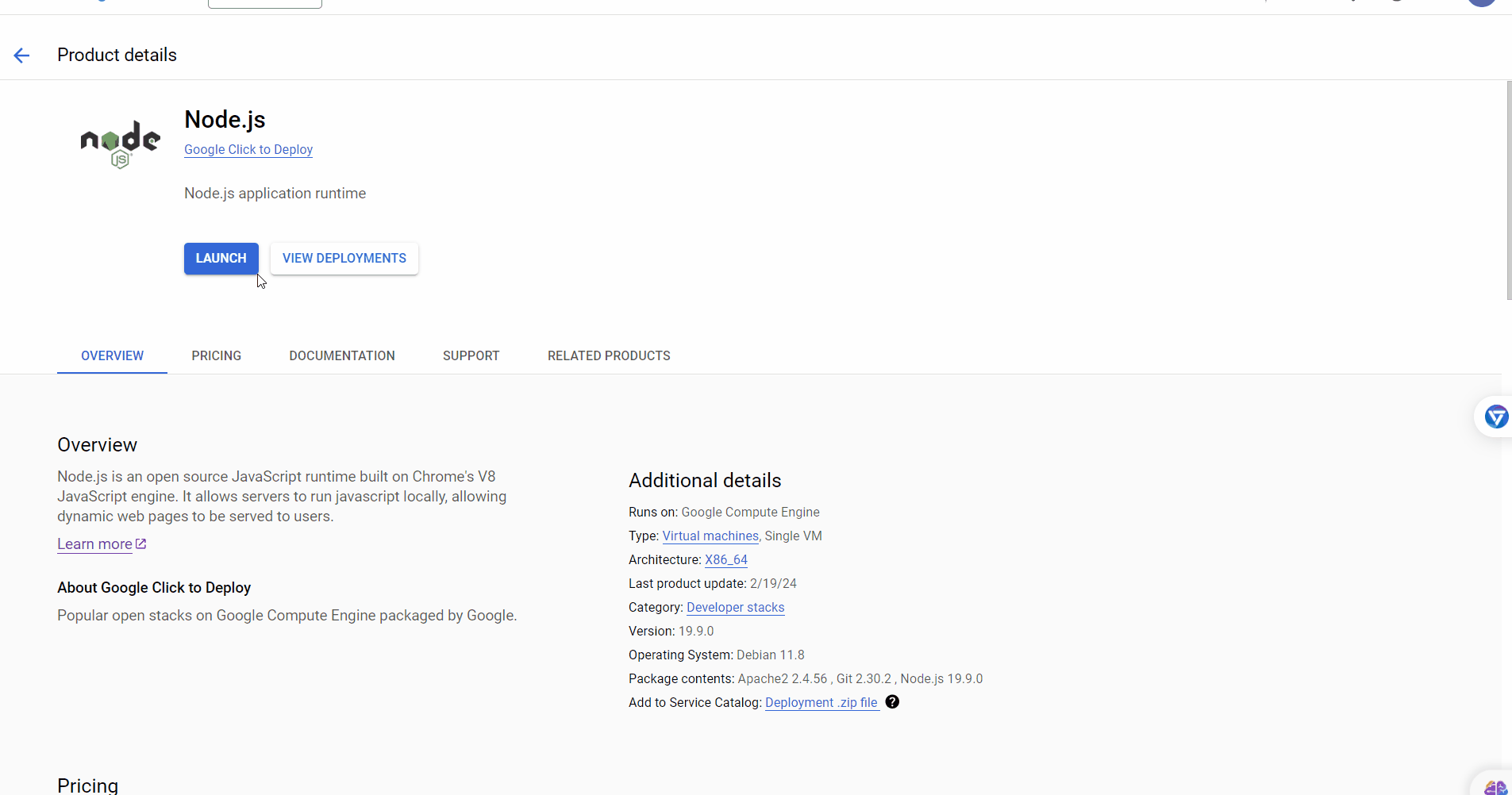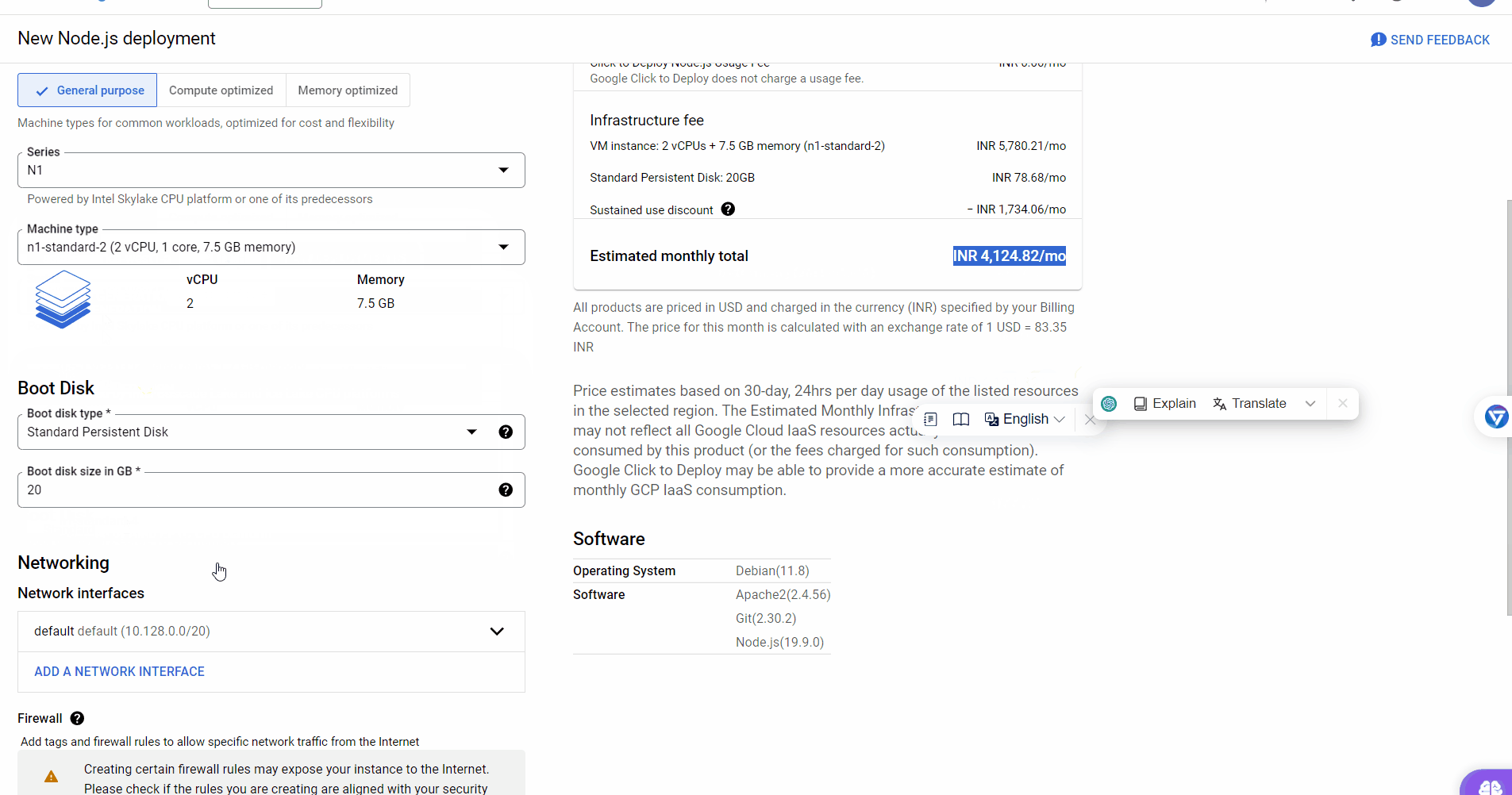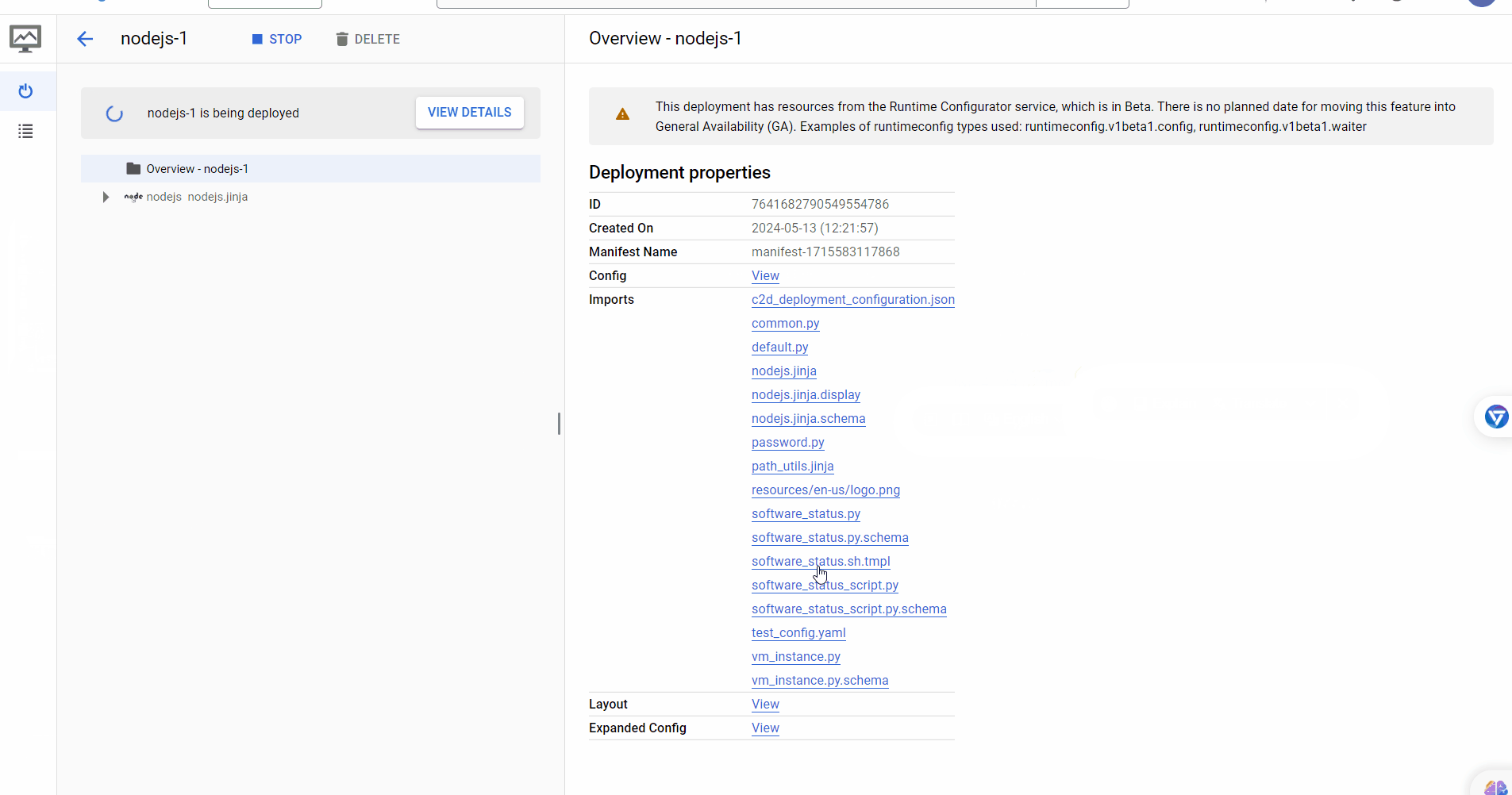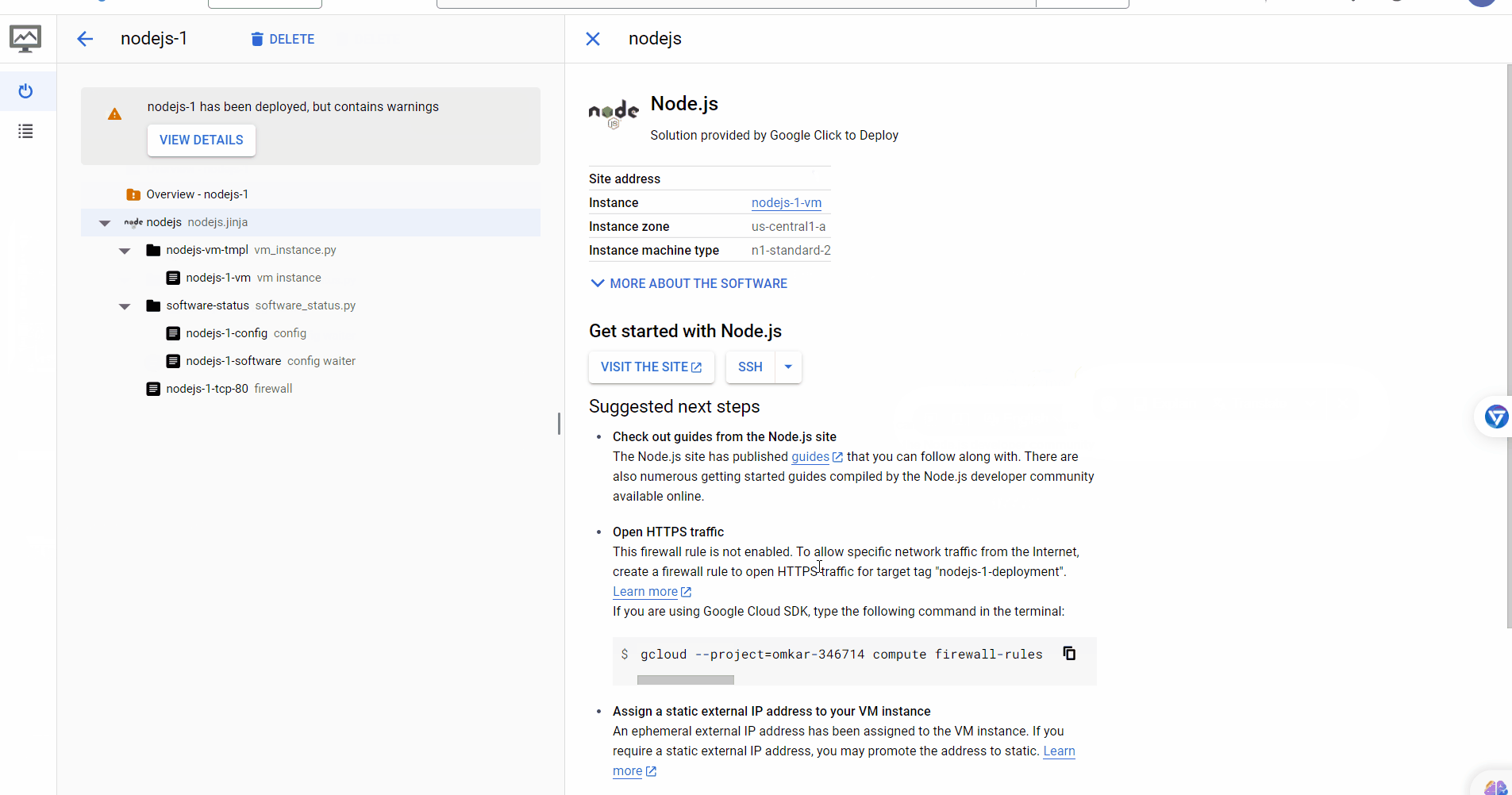
-
Visit this link and click the SSH button to SSH into the VM.
-
Now, run the following commands in the terminal, then wait for 5 minutes for the installation to complete:
curl -sL https://raw.githubusercontent.com/omkarcloud/botasaurus/master/vm-scripts/install-scraper.sh | bash -s -- https://github.com/omkarcloud/botasaurus-starter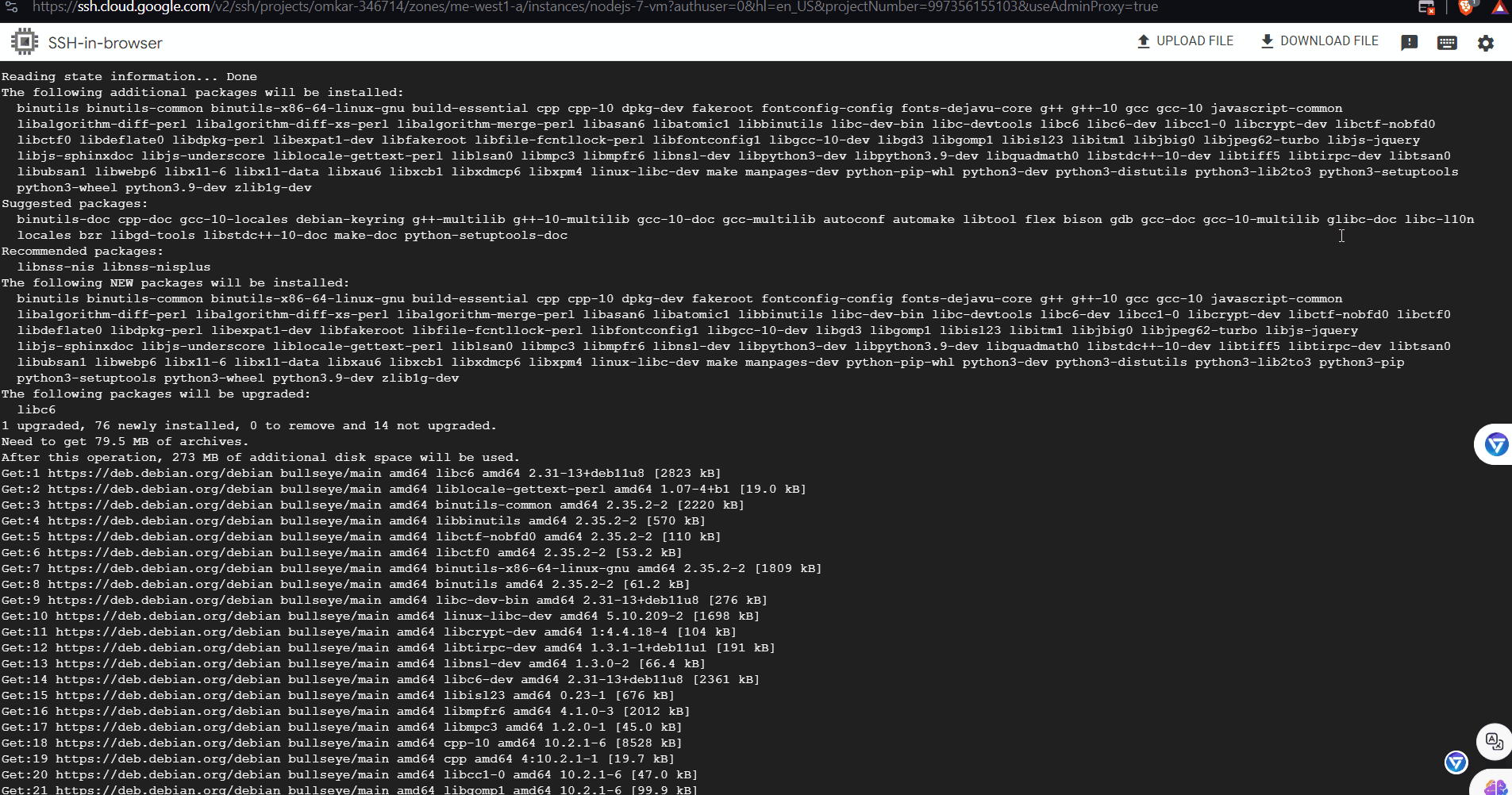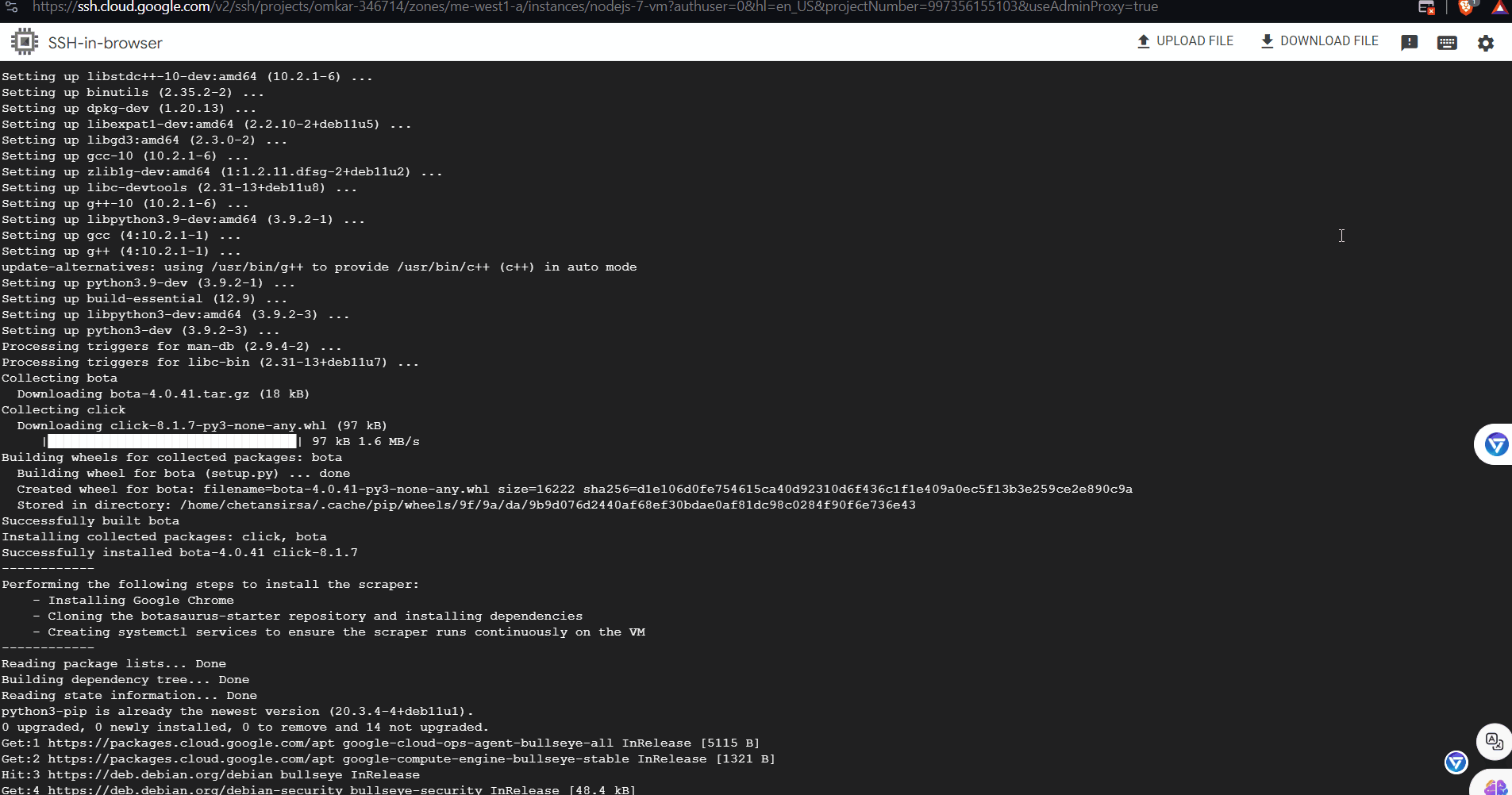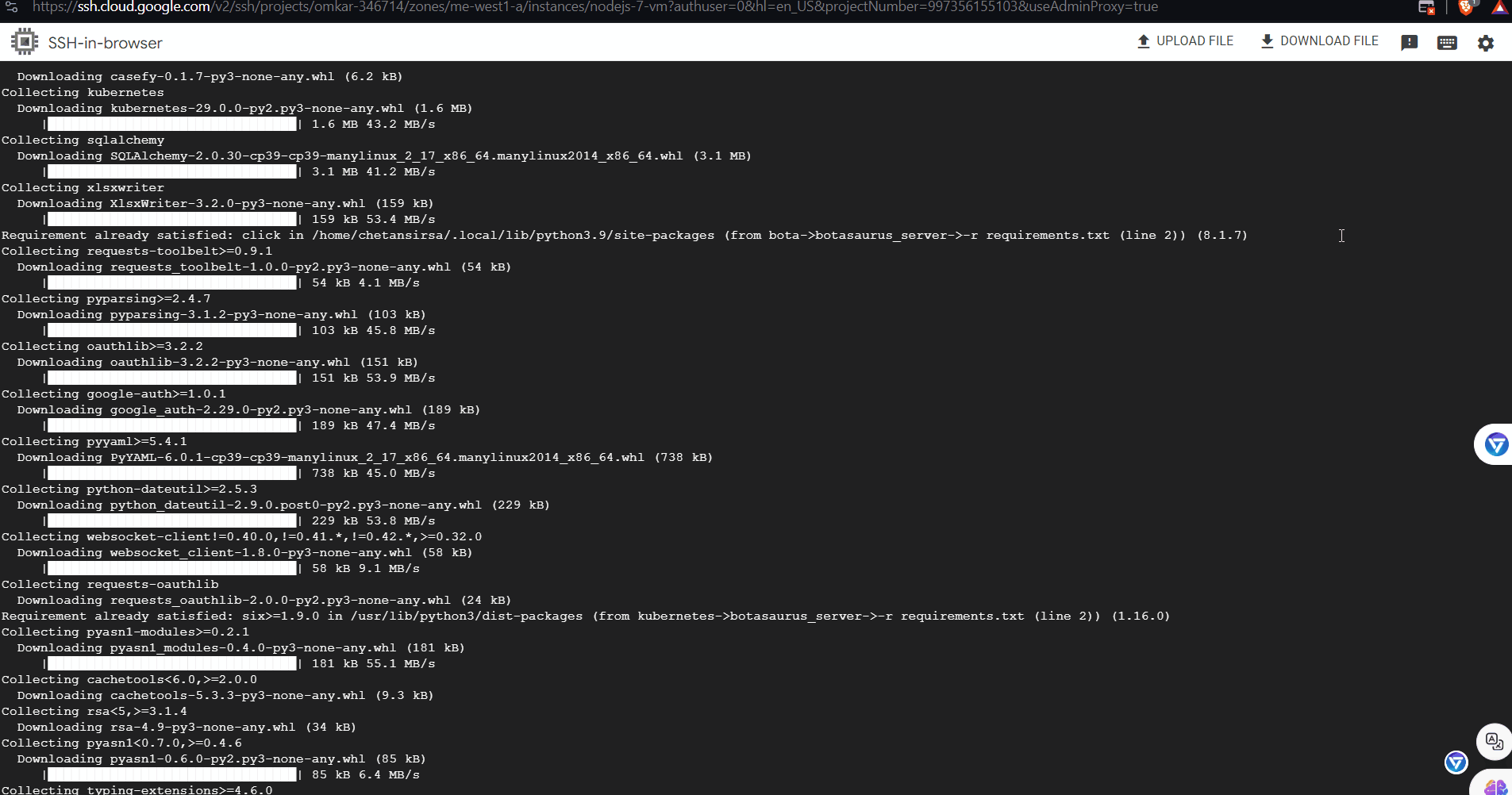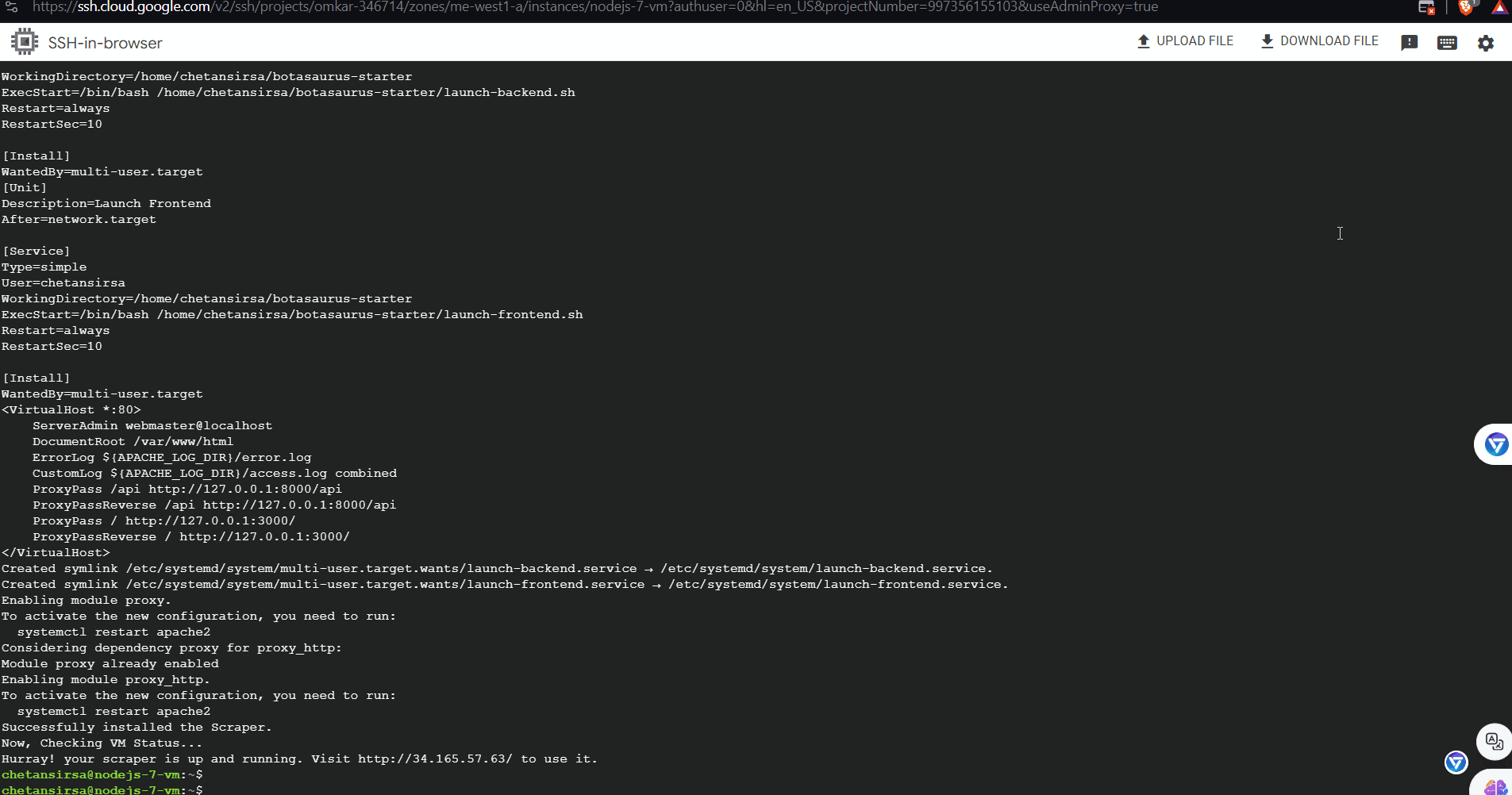 Note: If you are using a different repo, replace
Note: If you are using a different repo, replace https://github.com/omkarcloud/botasaurus-starterwith your repo URL. That's it! You have successfully launched the Scraper in a Virtual Machine. When the previous commands are done, you will see a link to your scraper. Visit it to run your scraper.
If you are deleting a custom scraper you deployed, please ensure you have downloaded the results from it.
Next, follow these steps to delete the scraper:
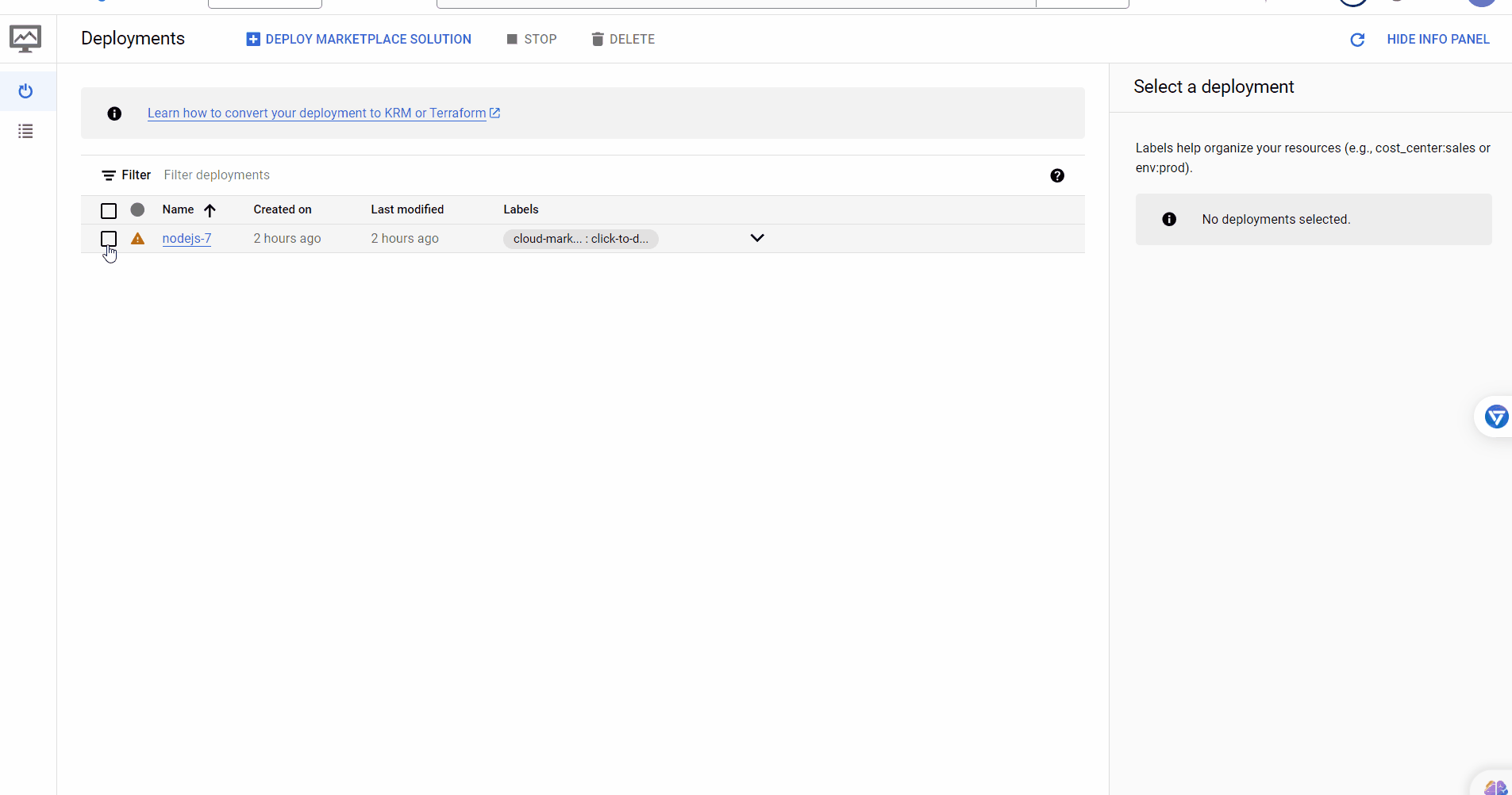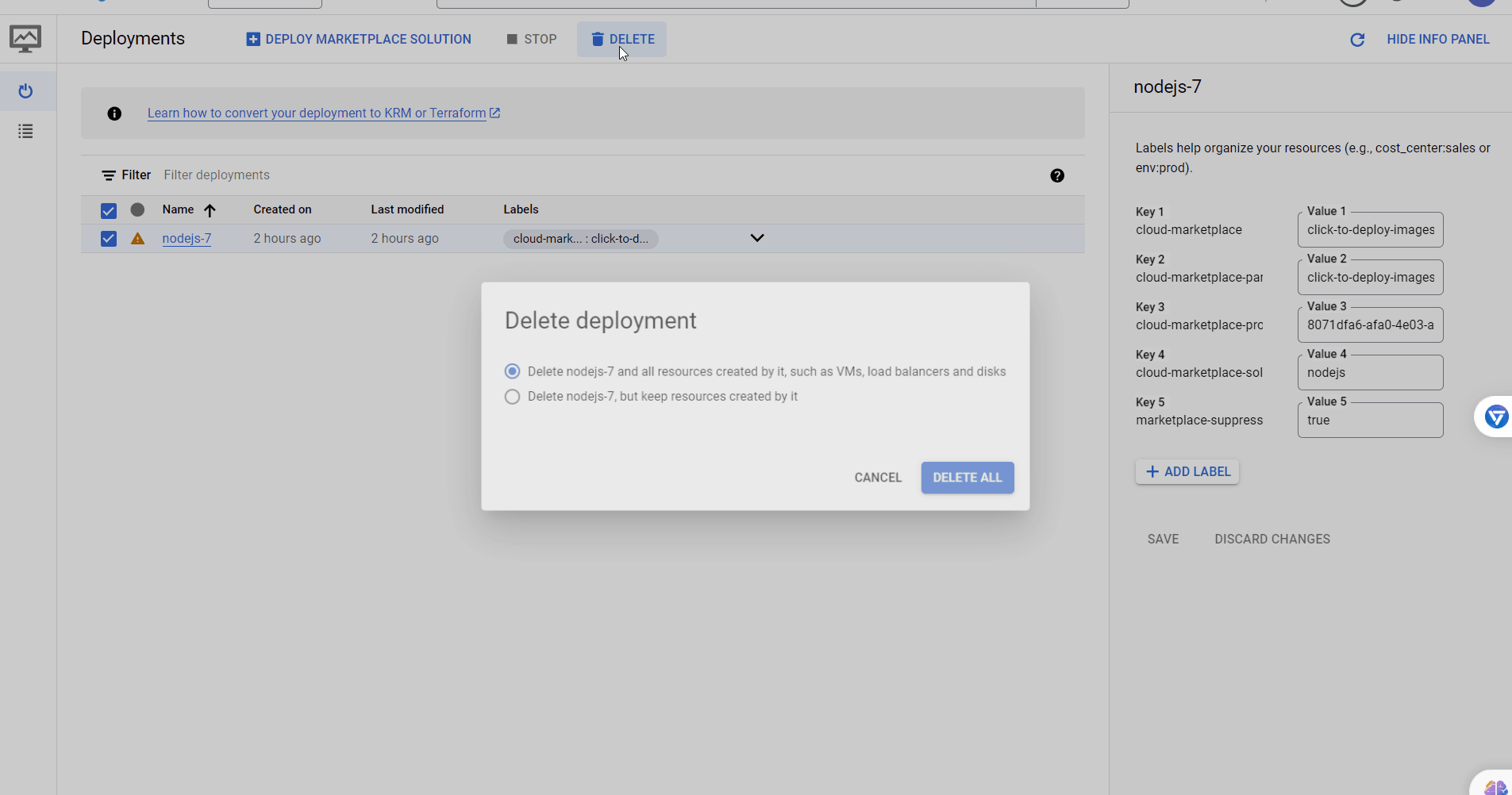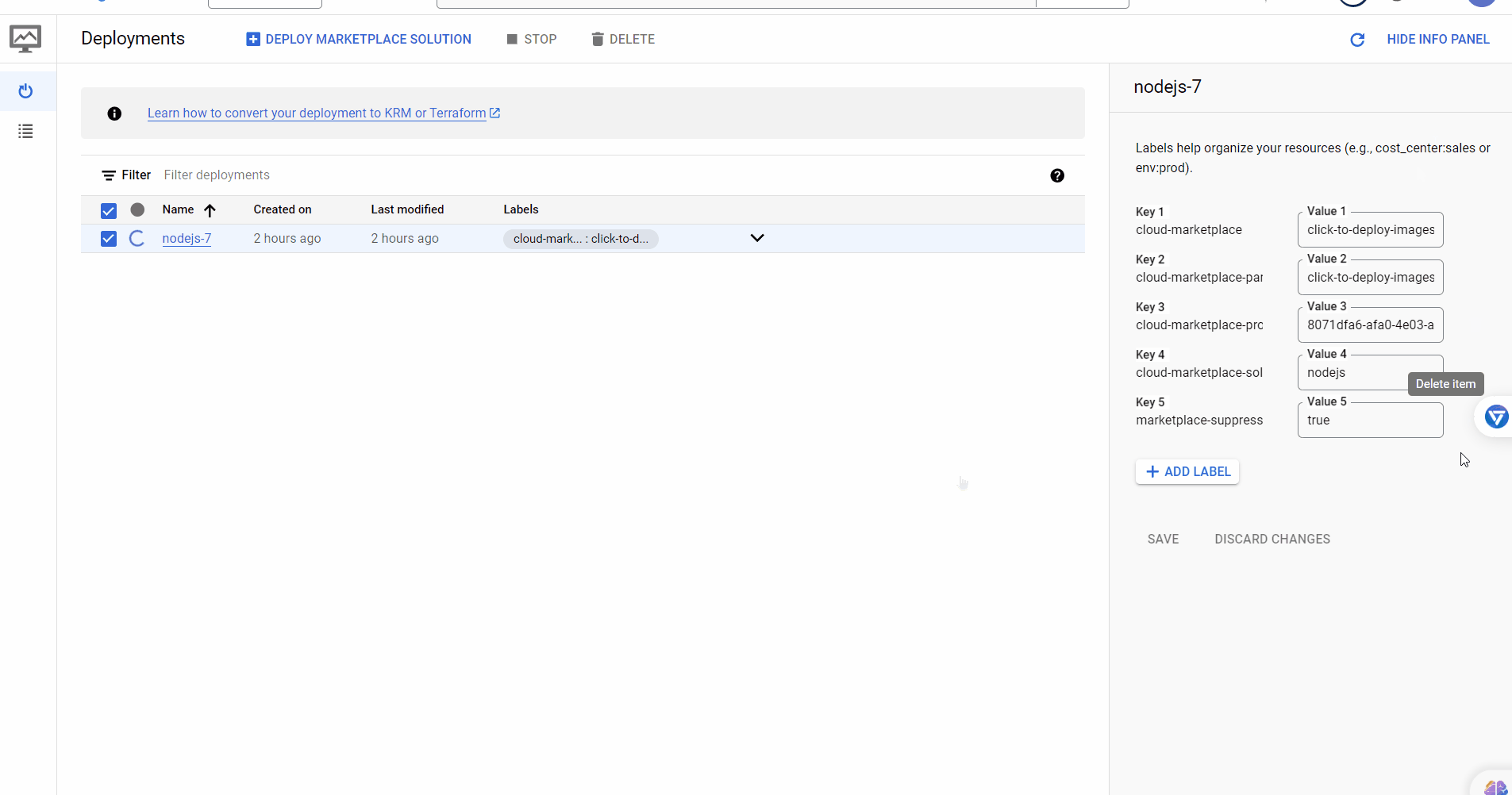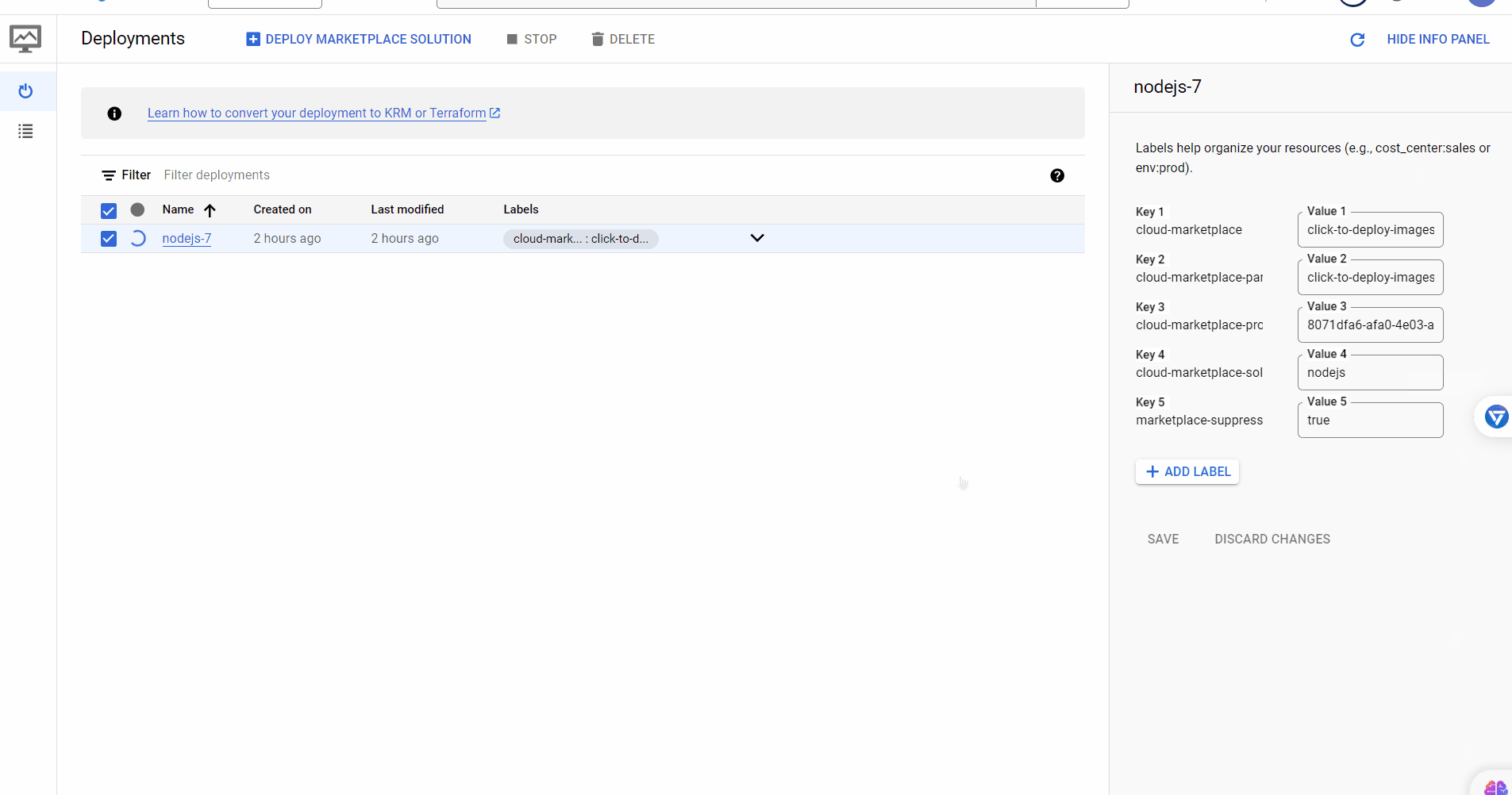
-
Delete the static IP by running the following command:
python -m bota delete-ip
You will be asked for the name of the VM you created in the first step. Enter the name and press Enter.

Note: If you forgot the name of the IP, you can also delete all the IPs by running
python -m bota delete-all-ips. -
Go to Deployment Manager and delete your deployment.
That's it! You have successfully deleted the scraper, and you will not incur any furthur charges.
Visit this link to learn how to run scraper at scale using Kubernetes.
We'd love hear it! Share them on GitHub Discussions.

Congratulations on completing the Botasaurus Documentation! Now, you have all the knowledge needed to effectively use Botasaurus.
You may choose to read the following questions based on your interests:
-
How to control the maximum number of browsers and requests running at any point of time?
-
How do I change the title, header title, and description of the scraper?
-
Which PostgreSQL provider should I choose among Supabase, Google Cloud SQL, Heroku, and Amazon RDS?
-
I am a Youtuber, Should I create YouTube videos about Botasaurus? If so, how can you help me?
- To That, who has given me a sufficiently intelligent mind to create Botasaurus and do a lot of good.
- I made Botasaurus because I would be really happy if you could use it to successfully complete your project. So, a Gigantic Thank you for using Botasaurus!
- Kudos to the Apify Team for creating the
proxy-chainlibrary. The implementation of SSL-based Proxy Authentication wouldn't have been possible without their groundbreaking work onproxy-chain. - Shout out to ultrafunkamsterdam for creating
nodriver, which inspired the creation of Botasaurus Driver. - A big thank you to daijro for creating hrequest, which inspired the creation of botasaurus-requests.
- A humongous thank you to Cloudflare, DataDome, Imperva, and all bot recognition systems. Had you not been there, we wouldn't be either 😅.
Now, what are you waiting for? 🤔 Go and make something mastastic! 🚀
Love It? Star It! ⭐
Become one of our amazing stargazers by giving us a star ⭐ on GitHub!
It's just one click, but it means the world to me.
By using Botasaurus, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Botasaurus are not responsible for any misuse of this software. It is the sole responsibility of the user to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Botasaurus in an ethical and legal manner.
We take the concerns of the Botasaurus Project very seriously. For any inquiries or issues, please contact Chetan Jain at chetan@omkar.cloud. We will take prompt and necessary action in response to your emails.