Author: Omar Younis
DreamWorks is a animation studio which has a number of hit films. In the animation world, they are often compared to their Disney counterparts, Pixar. Because of this DreamWorks is looking to use targeting advertising to find Pixar fans and sway them to become DreamWorks fans. This project explores reddit comments in the DreamWorks and Pixar subreddits, to find language patterns to patterns to predict whether a person is a Pixar fan or a DreamWorks fan.
| Feature | Type | Description |
|---|---|---|
| subreddit_name | object | The name of the subbreddit that the comment came from. |
| body | object | The contents of the comment. |
| created_utc | int | The epoch time stamp of when the comment was created. |
| comment_length | int | How many characters the comment contains. |
| word_count | int | How many words the comment contains. |
To answer my problem statement, I first had to pull the comments from the two subreddits (Pixar and DreamWorks) in question. After gather all the comments, the data was stored locally in a csv file. This was to make it easier to work with the data. It was meant I won't keep using up resources from the api. I would go in, get what I needed (in this case the comment data from the subreddits) and get out.
After that I needed to clean up the data before I could vectorize it for natural language processing. The main things I did was to drop any rows which has comments of [removed] or [deleted]. These are comments that the user who wrote then deleted or comments that the admins of the subreddit deleted. As they provided no data on the contents of the comment, it made sense to drop these rows. Next I removed any white space to make sure I just had the comments. Finally I removed any URLs from the comments as this would not help us with our language processing.
After cleaning my data, I decided to add two more columns to my DataFrame that I thought would help with my exploratory data analysis. As mentioned in the Data Dictionary, I added a comment_length field and a word_count field; just to see if any patterns emerged.
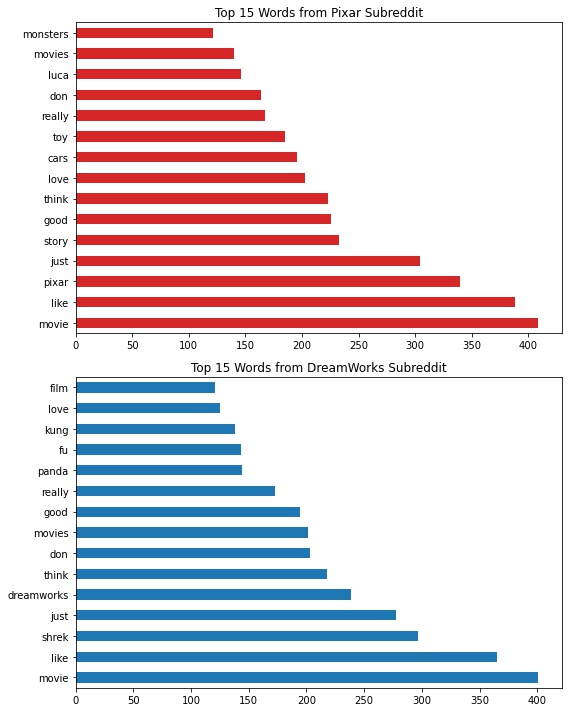
After that I CountVectorized() all the comments, excluding stop words. Stop words are words that aren't very useful when it comes to searching for data. You can learn more about them by clicking here. I then found the top 15 words used by each subreddit. Below is a graph showing these words:
After that, I created a few models to try and find one that would best predict whether a comment belonged to the DreamWorks subreddit or the Pixar subreddit. With the use of Pipeline and GridSearchCV the best model I could come up with was a pipeline model that used a CountVectorizer() and a MultinomialNB(). The best train and test scores I got were as follows:
| Category | Score |
|---|---|
| Train | 0.8686 |
| Test | 0.7682 |
My model was overfitting, but not as badly as my other models. Ideally for this model we want to make sure we have a high accuracy for it. We also want to maximize our model's precision over the other metrics. This way, we may accidentally assign a comment of not being in a subreddit when it is (i.e. say that it does not belong to Pixar when it actually does). But this way we will not assign a comment to the wrong subreddit (i.e say that a DreamWorks comment is a Pixar comment).
The precision value I got was 0.7520 which can definitely been improved. For a breakdown of my model's confusion matrix, see below:
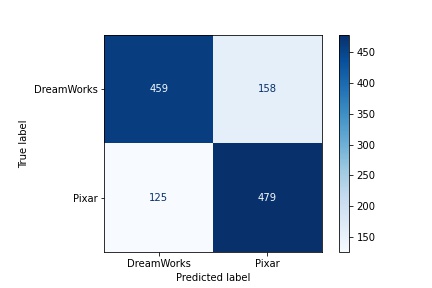
For our problem statement, I would deploy my Model 1: MultinomialNB(). With this, we can scrape a bunch of posts from other websites, such as Facebook and Twitter to predict which users might be Pixar fans. We can then run these posts through the predict method for my model.
pipe_1 = Pipeline([
('cv', CountVectorizer(min_df=2)),
('mnb', MultinomialNB())
])
pipe_1.fit(X_train, y_train)
pipe_1.predict([YOUR_COMMENT])By passing a list of user comments in the YOUR_COMMENT section shown above, it can give DreamWorks a prediction on whether or not that person could be a Pixar fan; and if so send them DreamWorks advertisements.
Going forward, I would like to use more grid searches to dry and improve my model's score as well as increase my precision score.