This project is the implementation of ERA: Efficient Serial and Parallel Suffix Tree Construction for Very Long Strings algorithm. We optimized the vertical partition algorithm for best parallelism. This project is also a problem in The third term Cloud Computing Contest [Sildes]
This project build by maven, just open the project in Intellij Idea and compile&package into jar.
e.g. spark-submit --master spark://master:7077 --class GST.Main --executor-memory 6G --driver-memory 20G suffixtree-1.0-SNAPSHOT.jar "hdfs://master:9000/input/5000 1000" "hdfs://master:9000/output/5000 1000"
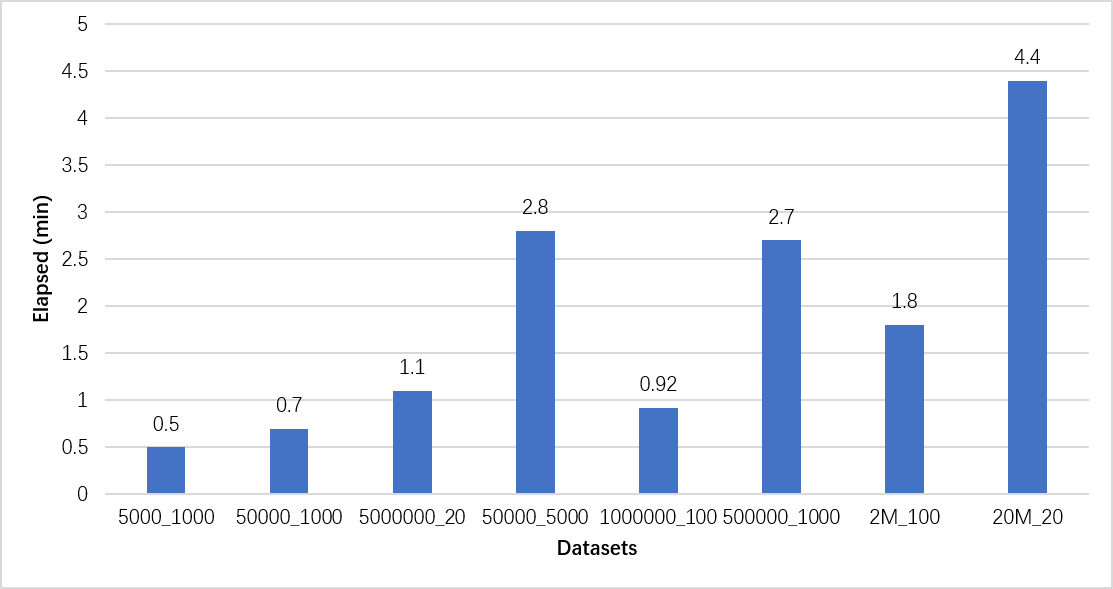
The code write in Java and run on Apache Spark. We tested on 20GB memory 48 cores cluster, for 400MB gene dataset this program build suffix tree and save result only consumed 4.4 min.
Note:
AAA_BBB means, dataset is composed by 'BBB' strings, the longest string no more than 'AAA' characters.
The first one contains 6 folders. The folder name consists of the length of string and the number of files e.g. "5000000 20". "5000000" means the length of the longest string no more than 5000000 characters. "20" means there are 20 text files in the folder.
The second one is dataset for checking the correctness of the program, which contains input dataset and output result. The result like :
4 3819.txt:284
4 3819.txt:679
3 3819.txt:350
3 3439.txt:913
4 3439.txt:826
4 3439.txt:867
3 3439.txt:805
Each line of contains three parts e.g. "4 3819.txt:284". "4" means the depth of the leaf node in the suffix tree. "3819.txt" is the file name. "284" means the start index of the leaf node in the file "3819.txt"