
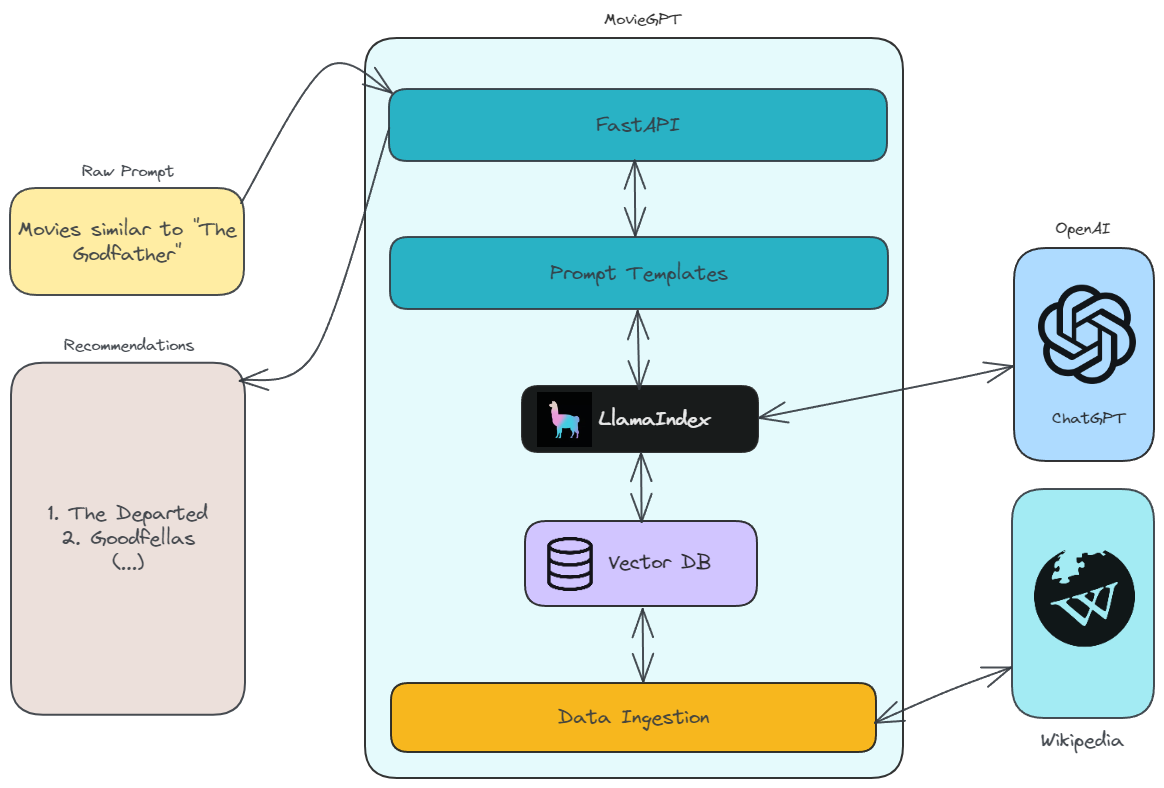
MovieGPT leverages the power of Generative AI in order to provide relevant movie recommendations based on user input. In order to achieve that, it relies on the following components:
📚 Open Source Data: we rely on movie data provided by Wikipedia, such as: movie summaries, genres, actor names and so on. This data is converted to embeddings for further indexing in a Vector Database.
🐕 Retrieval Augmented Generation (RAG): we use a Vector Database and semantic search in order to guarantee relevant results. This way, we limit the context that is provided to large language models when generating movie recommendations, hence reducing the risk of hallucinations in the process.
🤖 ChatGPT: we use ChatGPT for formatting the responses with movie recommendations in a human-like fashion.
The diagram below describes the architecture of MovieGPT in high level:
🤖 Set up your OpenAI API Token:
export OPENAI_API_TOKEN=#YOUR_TOKEN🐋 Build the Docker image:
make docker🏃♂️ Run the container:
make run __ __ _______ __ __ ___ _______ _______ _______ _______
| |_| || || | | || | | || || || |
| || _ || |_| || | | ___|| ___|| _ ||_ _|
| || | | || || | | |___ | | __ | |_| | | |
| || |_| || || | | ___|| || || ___| | |
| ||_|| || | | | | | | |___ | |_| || | | |
|_| |_||_______| |___| |___| |_______||_______||___| |___|
INFO:root:Starting web server...
INFO: Started server process [29]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)🕸️ Open the API docs and try it out: http://localhost:8000/docs
pyenv:
pyenv install 3.10.12
pyenv shell 3.10.2 #Voila!🏠 Install poetry:
pip install poetry🏗️ Activate the Poetry environment and install dependencies:
cd src && poetry shell && poetry install🎥 Run MovieGPT:
> poetry run moviegpt
Usage: moviegpt [OPTIONS] COMMAND [ARGS]...
Options:
--help Show this message and exit.
Commands:
data Downloads WikiData for movies.
index Creates a VectorDB Index based on Movie Metadata in JSON.
query Queries the VectorDB using Semantic Similarity and outputs movie...
web Runs our MovieGPT RAG App and exposes it through Fast API.🪜 Run the following steps:
poetry run moviegpt data && \
poetry run index && \
poetry run web🕸️ Open the API docs and try it out: http://localhost/docs
- CLI mode is also available. To run it, after you've installed dependencies, simply run:
moviegpt - If everything was installed correctly, you should be presented with the following welcome screen:
Usage: moviegpt [OPTIONS] COMMAND [ARGS]...
Options:
--help Show this message and exit.
Commands:
data Downloads WikiData for movies.
index Creates a VectorDB Index based on Movie Metadata in JSON.
query Queries the VectorDB using Semantic Similarity and outputs movie...
web Runs our MovieGPT RAG App and exposes it through Fast API.Running the Docker container or moviegpt web after ingesting the data and creating the vector index will expose moviegpt through a FastAPI web interface:

- Unit tests are run using
pytestandtox. - To run unit tests, simply run:
tox - For formatting:
tox -e fix - For linting:
tox -e lint
TODO