In a distributed system, data replication is needed for either fault-tolerance or latency optimization. Maintaining a consensus among all replications is crucial for the correctness and robustness of the distributed system. Various algorithms emerge to address this problem. Raft is an alternative designed to Paxos, aiming to be more understandable and to offer the same level of safety and robustness.

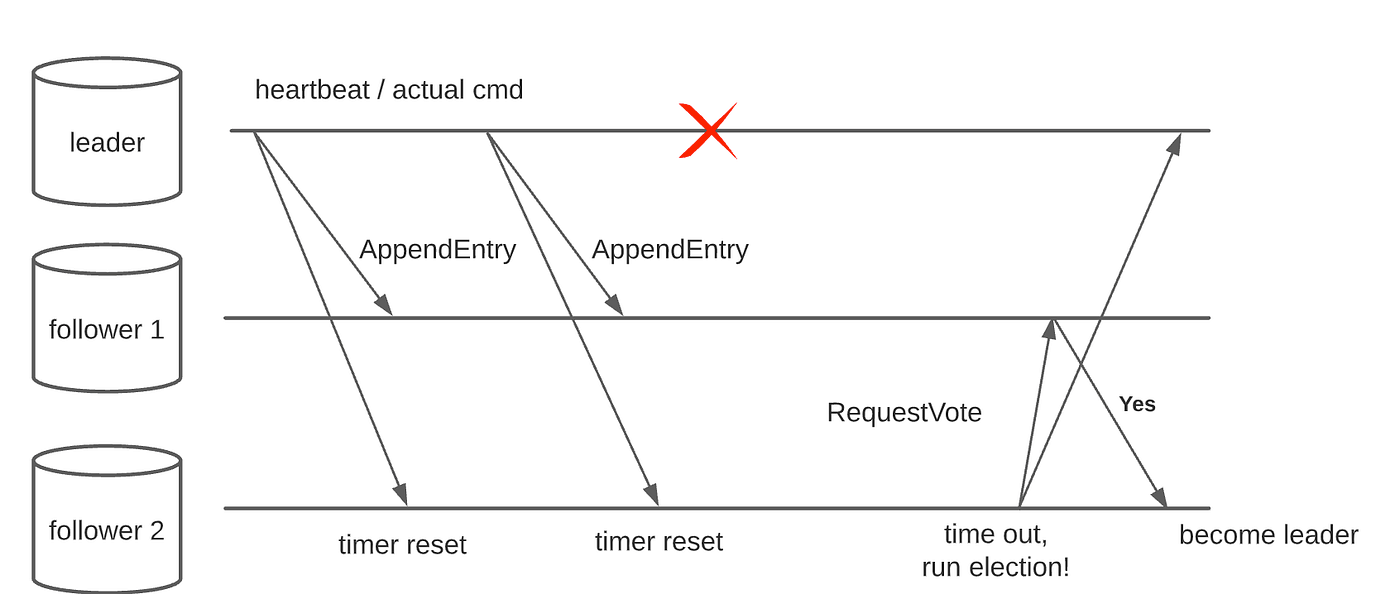
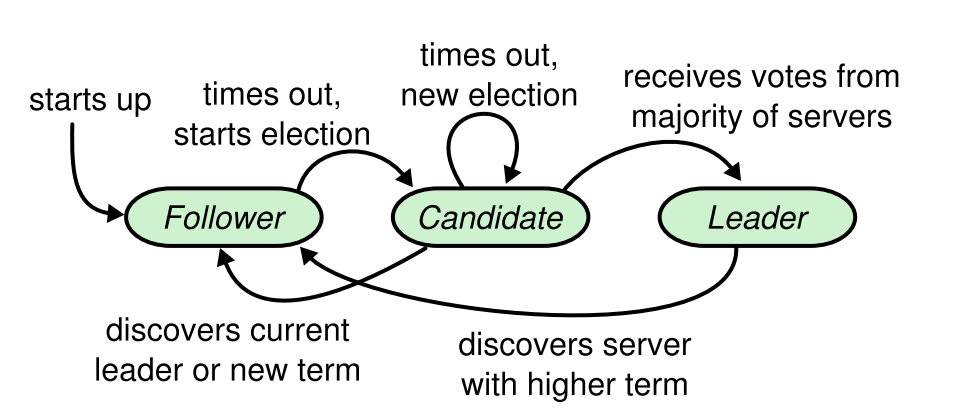
- The election starts when the current leader fails/disconnects or at the beginning of the algorithm. A new term starts in the system with a random period for the new leader to be elected. If the election successes with a single new leader winning, the term carries on and the new leader takes over to coordinate the normal operations. Otherwise, the term expires to yield another round of the election.
- An election is started with one or more node assumes candidacy, which is the result of not receiving any communication from the leader over a certain amount of timeout. Timeout is randomized to minimize the impact of the split vote. Each server vote once per term, on a first-come-first-served basis. Candidate votes for itself and request voting to other nodes. If a candidate receives a request from another candidate with a higher term, it will update its term and vote positively to that request, otherwise, if the request is from a lower or equal term candidate, the received request will be discarded. When the majority votes for a candidate, that candidate wins the election.

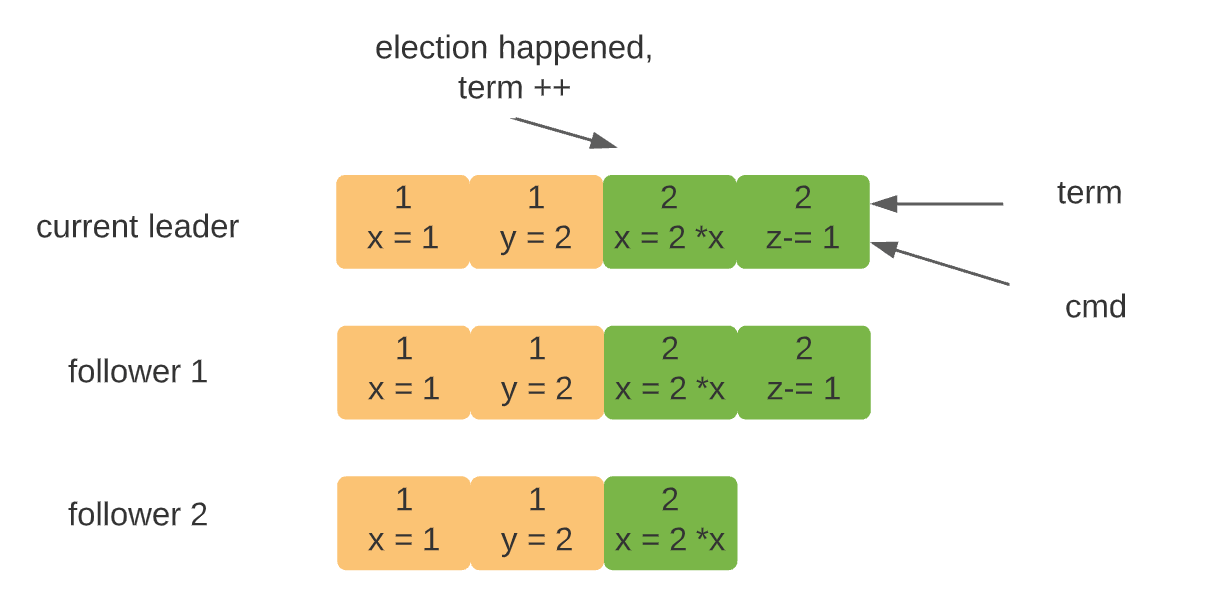
- Log replication is managed by the leader. Clients requests are handled by the leader, which consist of a command to be executed by the replicated state machines in the system. The leader first logs this locally and spreads the messages to all the follower about the updated entry. Followers log the updates in the message, and feedback to the leader as a consent to the update. Once the majority consents to the update, the leader will then "commit" this transaction to its local state machine and respond to the client about the success. Messages to inform all the followers to commit their replicates are sent at the meantime. The "commit" actions to transact all the previous staged logs if any was left undone.
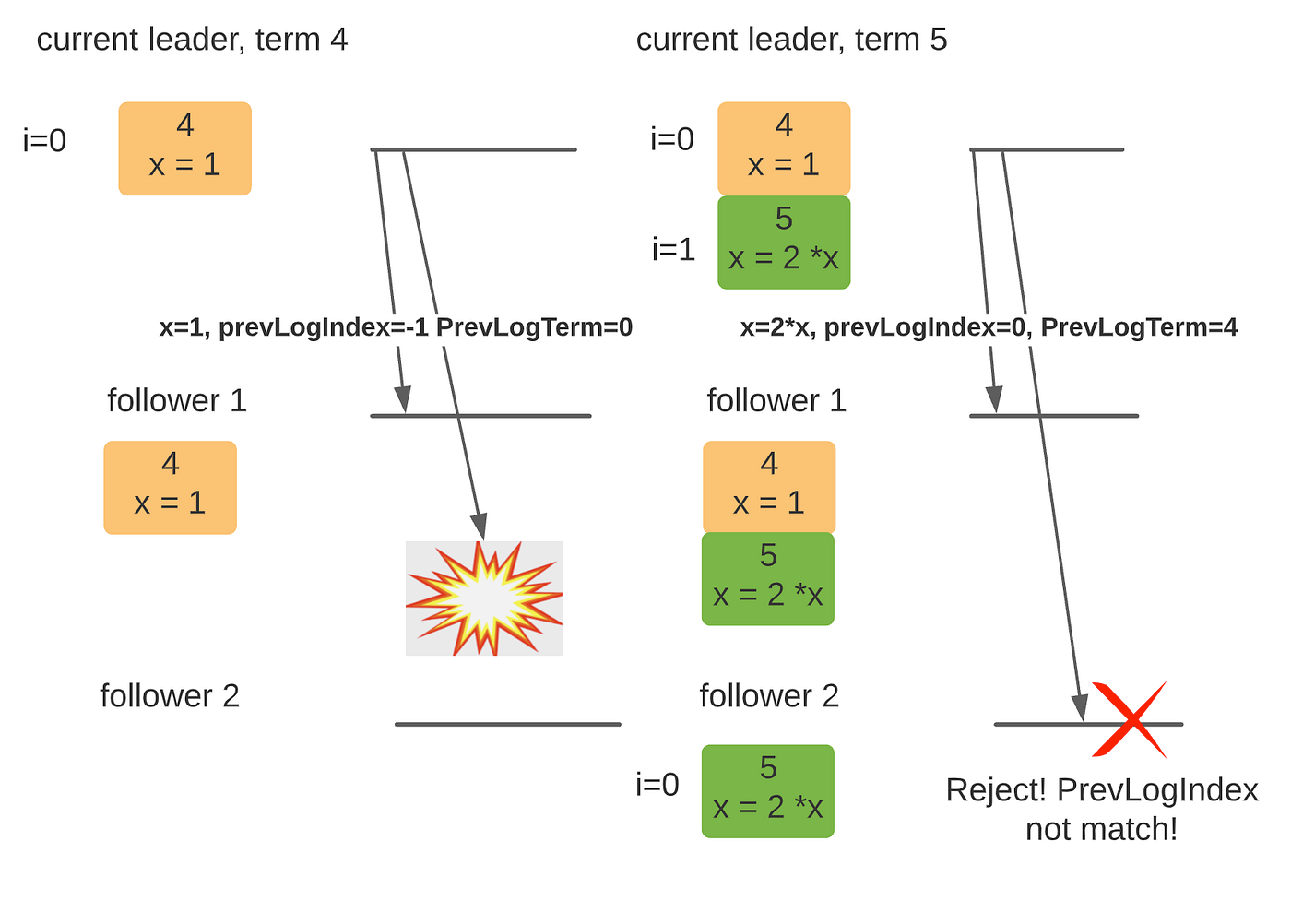
- Logs could be inconsistent in the case of leader crash, where some previous logs are not fully replicated to all its followers. In such cases, the new leader will request the followers to update their logs to reach consensus with the leader's state