{kind=link}
Bioinformatic pipeline streamlining analysis of target enrichment sequencing data.
Please cite the following paper when using CaptureAl in published work:
- Download/Clone the CaptureAl repository
- Follow the installation instructions.
- Determine how to implement parallel computing in your computing environment (GNU parallel or bsub)
Once the installation is complete, follow the tutorial step by step. You can also skip preprocessing of reads and jump-start to CaptureAl STEP 1 (parallel or bsub) if your reads are already quality-trimmed.
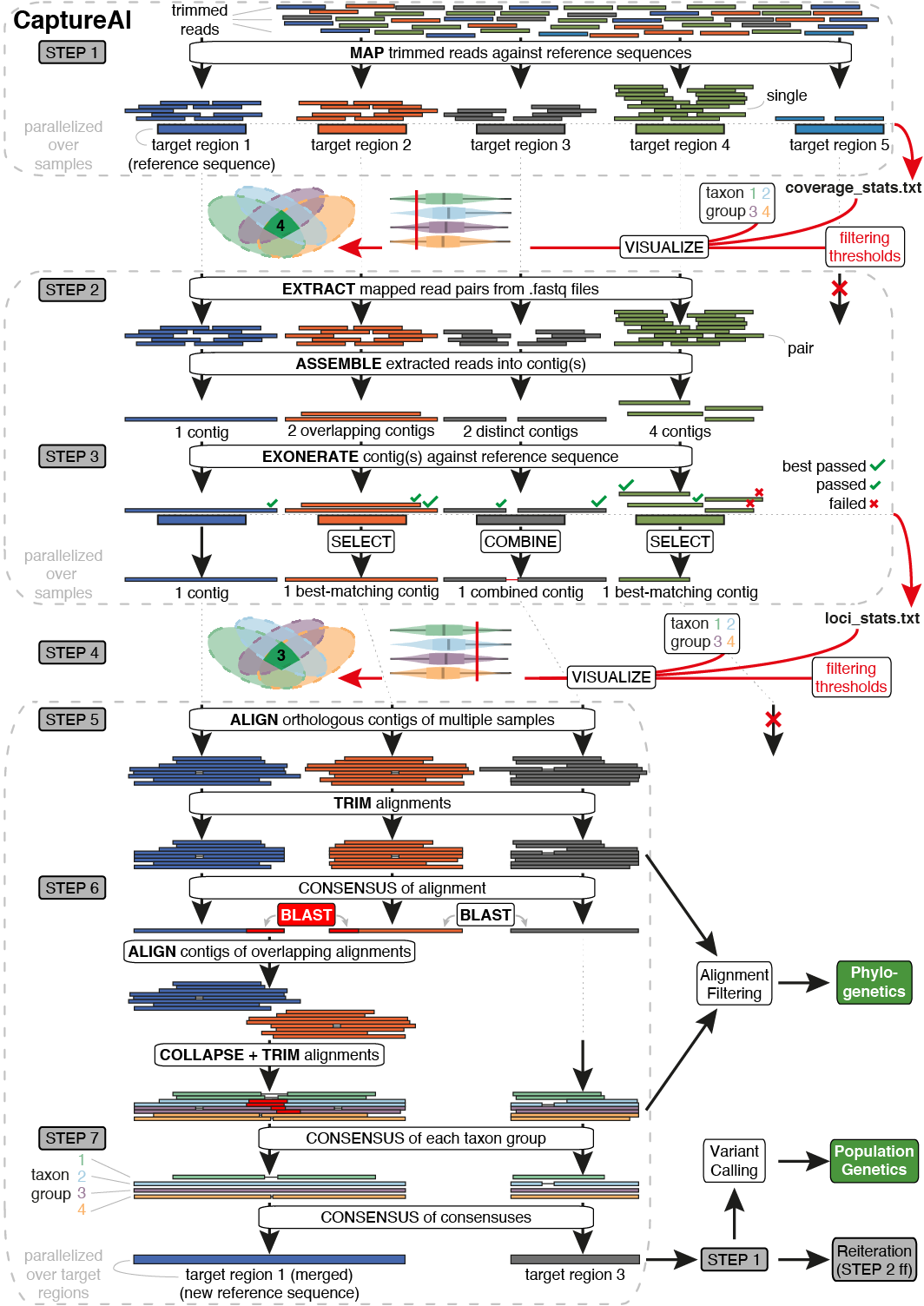
The pipeline is divided into seven steps, shown below. For each step, there is a limited number of scripts that have to be executed, and these scripts often execute other scripts located in the repository. Parts of these graph are also in the tutorial pages.
Simon Crameri & Stefan Zoller