This is a tool built for recognising emotions from speech using different ML and DL algorithms, But mainly focuses on LSTM(Long Short Term Memory) and CNN (Convolutional Neural Network) for predictions
python 3.7
Librosa library for extracting the features
Keras
Sci-kit learn
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS)
Description
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 7356 files (total size: 24.8 GB). The database contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions, and song contains calm, happy, sad, angry, and fearful emotions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. All conditions are available in three modality formats: Audio-only (16bit, 48kHz .wav), Audio-Video (720p H.264, AAC 48kHz, .mp4), and Video-only (no sound). Note, there are no song files for Actor_18.
Audio-only files
Audio-only files of all actors (01-24) are available as two separate zip files (~200 MB each):
Speech file (Audio_Speech_Actors_01-24.zip, 215 MB) contains 1440 files: 60 trials per actor x 24 actors = 1440.
Song file (Audio_Song_Actors_01-24.zip, 198 MB) contains 1012 files: 44 trials per actor x 23 actors = 1012.
Audio-Visual and Video-only files
Video files are provided as separate zip downloads for each actor (01-24, ~500 MB each), and are split into separate speech and song downloads:
Speech files (Video_Speech_Actor_01.zip to Video_Speech_Actor_24.zip) collectively contains 2880 files: 60 trials per actor x 2 modalities (AV, VO) x 24 actors = 2880.
Song files (Video_Song_Actor_01.zip to Video_Song_Actor_24.zip) collectively contains 2024 files: 44 trials per actor x 2 modalities (AV, VO) x 23 actors = 2024.
File Summary
In total, the RAVDESS collection includes 7356 files (2880+2024+1440+1012 files).
File naming convention
Each of the 7356 RAVDESS files has a unique filename. The filename consists of a 7-part numerical identifier (e.g., 02-01-06-01-02-01-12.mp4). These identifiers define the stimulus characteristics:
Filename identifiers
Modality (01 = full-AV, 02 = video-only, 03 = audio-only).
Vocal channel (01 = speech, 02 = song).
Emotion (01 = neutral, 02 = calm, 03 = happy, 04 = sad, 05 = angry, 06 = fearful, 07 = disgust, 08 = surprised).
Emotional intensity (01 = normal, 02 = strong). NOTE: There is no strong intensity for the 'neutral' emotion.
Statement (01 = "Kids are talking by the door", 02 = "Dogs are sitting by the door").
Repetition (01 = 1st repetition, 02 = 2nd repetition).
Actor (01 to 24. Odd numbered actors are male, even numbered actors are female).
Filename example: 02-01-06-01-02-01-12.mp4
Video-only (02)
Speech (01)
Fearful (06)
Normal intensity (01)
Statement "dogs" (02)
1st Repetition (01)
12th Actor (12)
Female, as the actor ID number is even.
Install the required dependencies by running 'pip install -r requirements.txt'
To run the tool just type Python3 main.py
You can change or play with the code to increase the Accuracy path for the script can be changed inside the main.py script
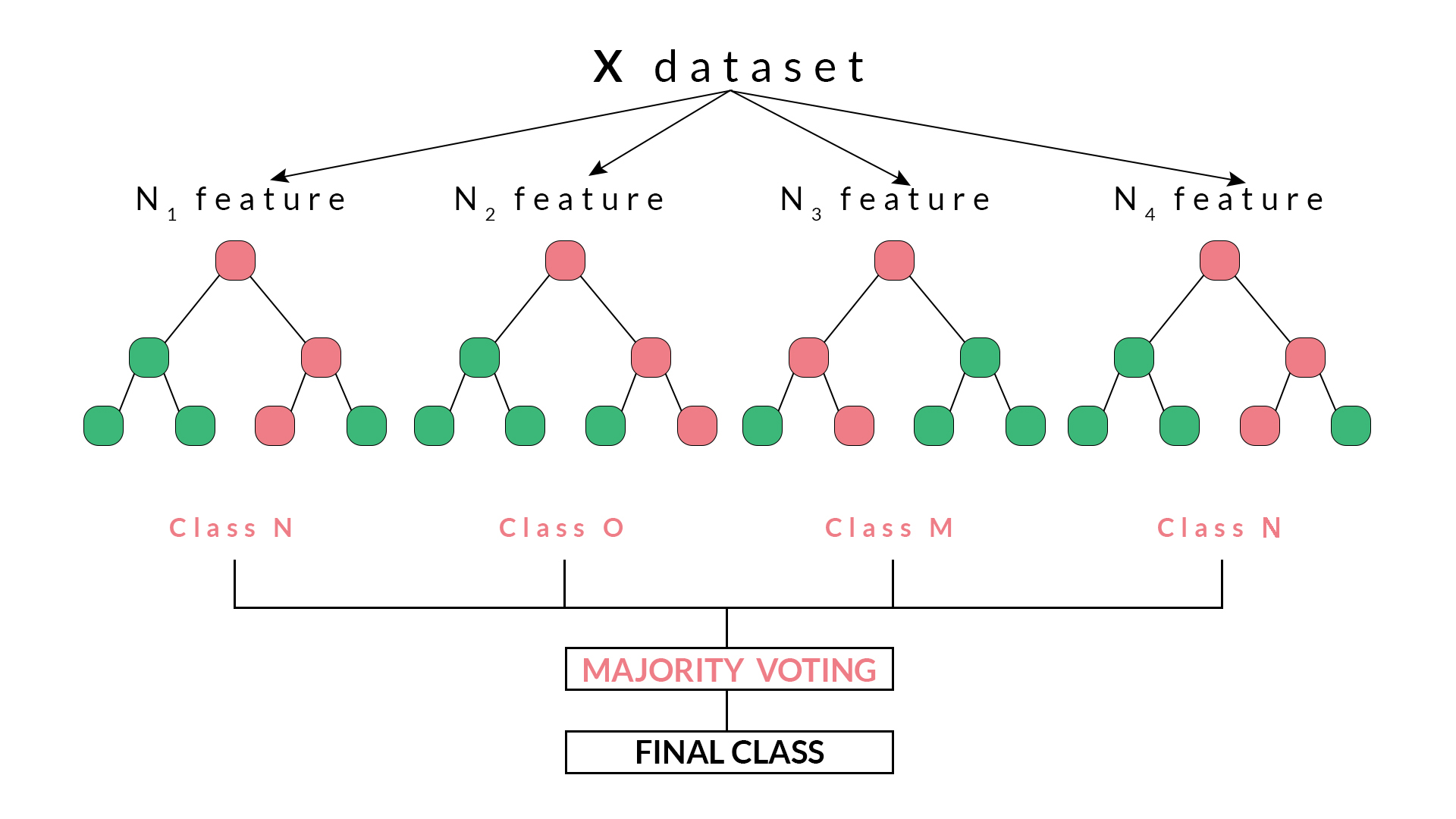
Mainly 6 methods have been used to classify the data
[1]Random Forest Classifier
[2]Decision Tree Classifier
[3]Support Vector Machine
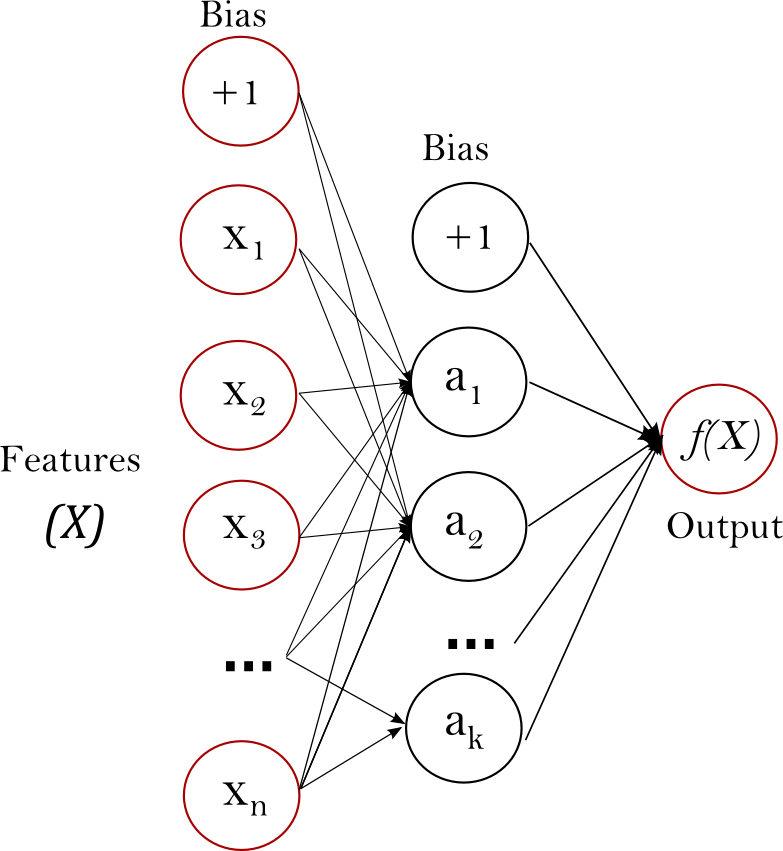
[4]Multi Layer Perceptron
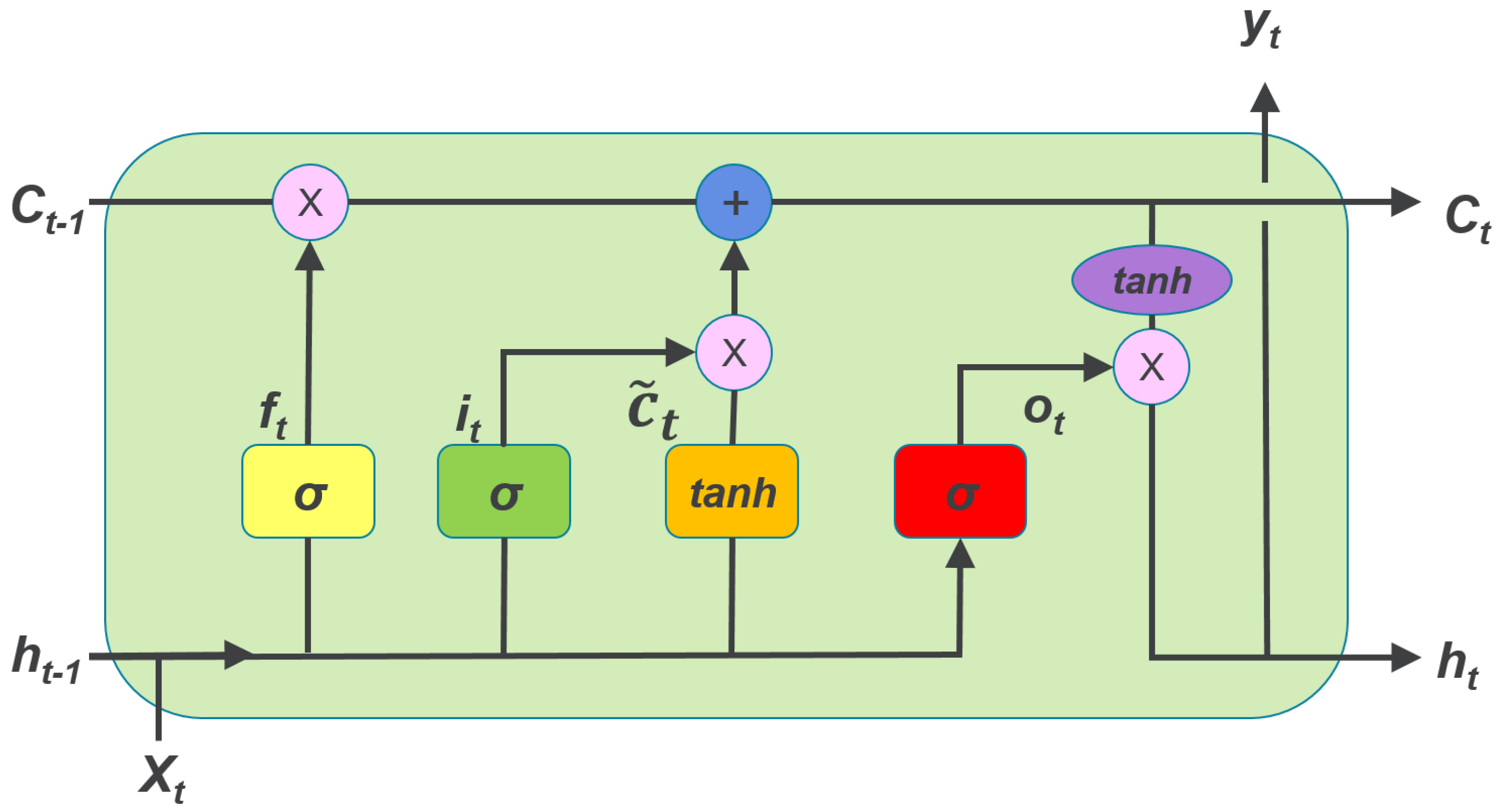
[5]Long Short-term Memory
[6]Convolutional Neural Network


{kind=link}
Options for running KFold cross validation and Data preprocessing has also been included in the menu
https://github.com/xuanjihe/speech-emotion-recognition
https://github.com/RayanWang/Speech_emotion_recognition_BLSTM
https://github.com/harry-7/speech-emotion-recognition
https://github.com/x4nth055/emotion-recognition-using-speech